- The paper presents an infrastructure-agnostic evaluation of reasoning in 15 foundation models across HPC, cloud, and university clusters.
- It introduces a dual-metric approach assessing both final answer correctness and stepwise reasoning accuracy to expose a parameter efficiency paradox and transparency-correctness trade-off.
- Findings highlight domain-specific trends, with calculus and economics being more tractable, challenging scaling laws and suggesting the need for architectural innovation.
Introduction
The paper "Cross-Platform Evaluation of Reasoning Capabilities in Foundation Models" (2510.26732) presents a systematic, infrastructure-agnostic evaluation of reasoning in contemporary foundation models. The study spans 15 models, three computational infrastructures (HPC supercomputing, cloud, and university clusters), and a benchmark of 79 problems across eight academic domains. The work introduces a dual-metric evaluation—final answer correctness and stepwise reasoning accuracy—enabling nuanced analysis of both outcome and process. The findings challenge prevailing scaling laws, highlight a transparency-correctness trade-off, and provide actionable insights for model selection and future research.
Benchmark Design and Dataset Schema
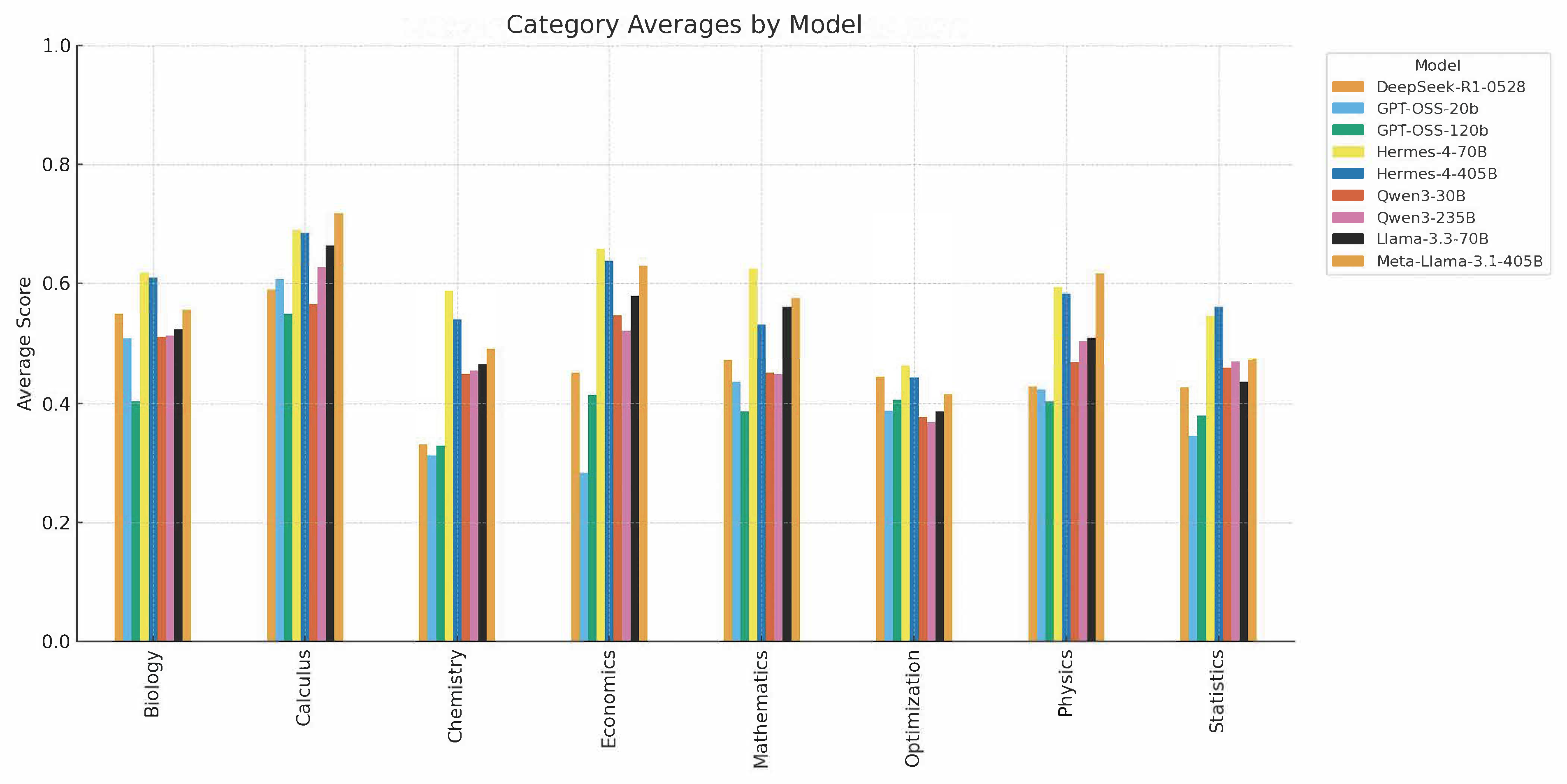
The evaluation framework is grounded in a standardized, multi-domain benchmark. Each problem is annotated with a problem statement, a final result, and a step-by-step solution, stratified by difficulty (Easy, Medium, Hard) and distributed across Physics, Mathematics, Chemistry, Economics, Biology, Statistics, Calculus, and Optimization.
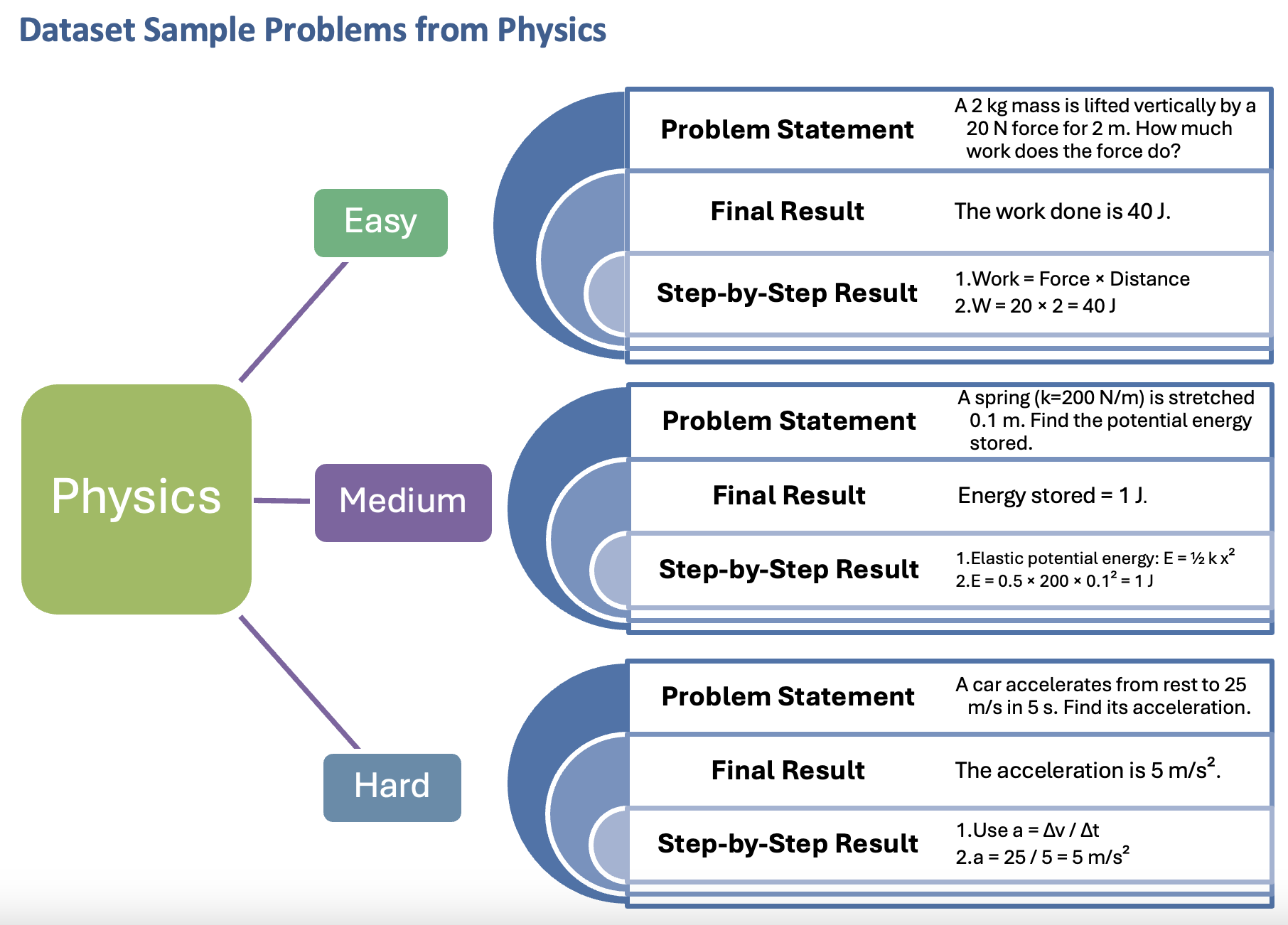
Figure 1: Each problem is structured with a statement, final result, and stepwise solution, enabling process-level scoring across domains and difficulty tiers.
This schema supports semantic similarity-based scoring for both final answers and intermediate reasoning steps, facilitating robust, process-aware evaluation.
Methodology and Infrastructure-Agnostic Validation
The evaluation pipeline employs SentenceTransformer-based semantic similarity for both final and stepwise outputs, with three independent runs per problem to quantify consistency. The tri-infrastructure design—MareNostrum 5 (HPC), Nebius AI Studio (cloud), and a university H200 GPU cluster—enables direct assessment of infrastructure effects.
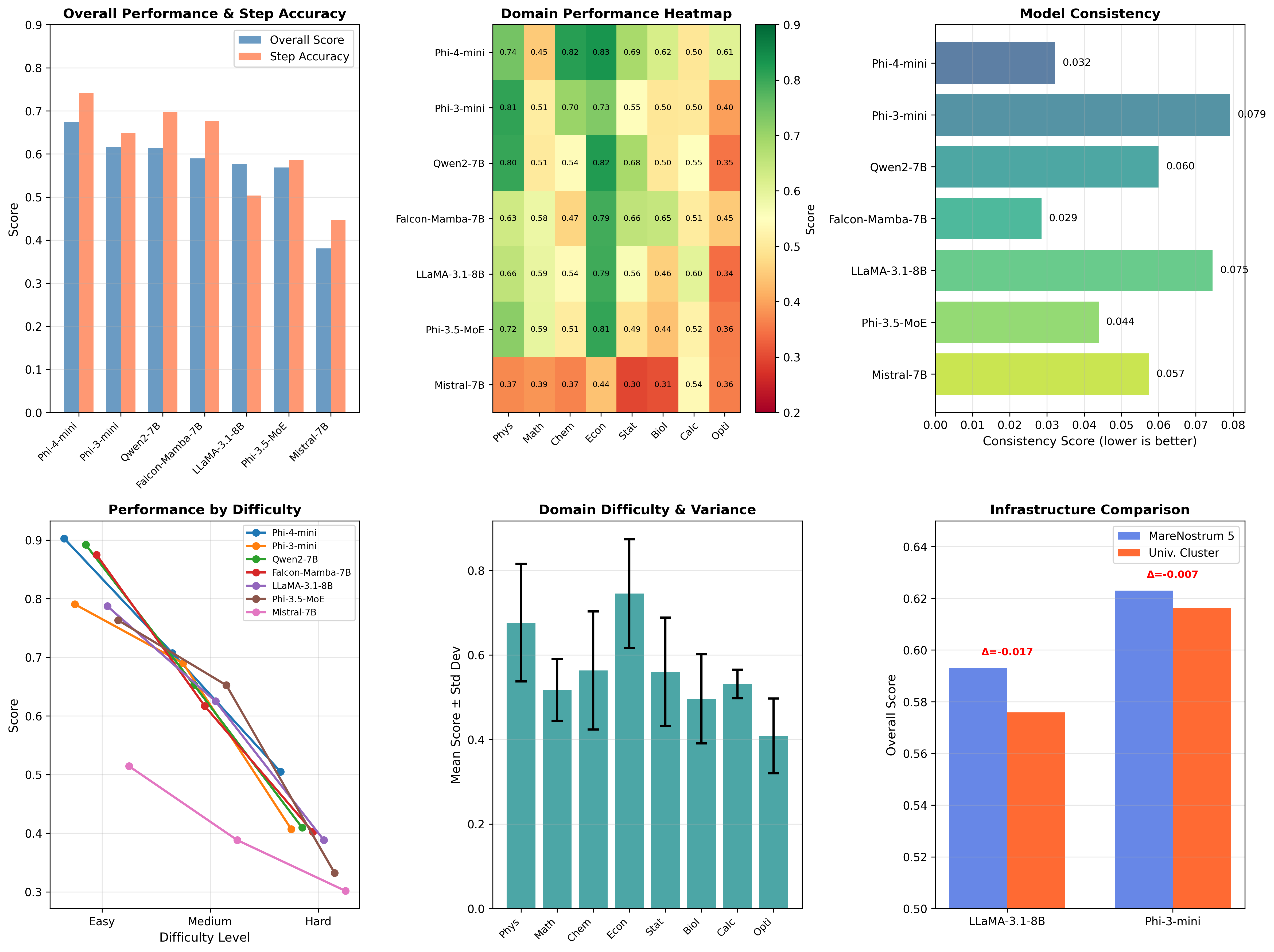
Figure 2: Multi-faceted analysis of model performance, domain strengths, consistency, and infrastructure validation, demonstrating that reasoning quality is model-intrinsic and not hardware-dependent.
Key findings from infrastructure validation include:
- Minimal cross-infrastructure variance (<3% for identical models), confirming that reasoning performance is model-intrinsic.
- Competitive performance of non-transformer architectures (e.g., Falcon-Mamba state-space model matches LLaMA-3.1-8B).
- Dense, smaller models (e.g., Phi-4-mini, 14B) outperforming larger MoE architectures (Phi-3.5-MoE, 42B), challenging scaling assumptions.
Parameter Efficiency and Scaling Paradox
A central result is the parameter efficiency paradox: Hermes-4-70B (70B parameters) achieves the highest score (0.598) among extended models, outperforming both its 405B counterpart (0.573) and Meta's LLaMA 3.1-405B (0.560). This contradicts the expectation of monotonic improvement with scale and underscores the primacy of training data quality and architectural design over raw parameter count.
Transparency-Correctness Trade-Off
The study reveals a fundamental trade-off between reasoning transparency and final correctness. Models such as DeepSeek-R1 achieve the highest step-accuracy (0.716) but only moderate final scores (0.457), while Qwen3 models exhibit high final accuracy with low correlation to stepwise reasoning quality, indicative of "shortcut learning."
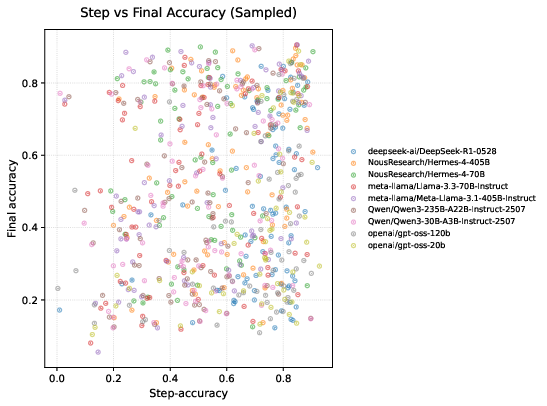
Figure 3: The relationship between step-accuracy and final correctness varies across models, highlighting the transparency-correctness trade-off.
This dichotomy has direct implications for deployment: models with high step-fidelity are preferable for educational and safety-critical applications, while those with high final accuracy and consistency are suited for production environments.
Domain-Specific and Difficulty-Stratified Analysis
Performance varies systematically by domain and difficulty:
Performance degrades monotonically with increasing problem complexity, with a typical 20% drop per difficulty tier.
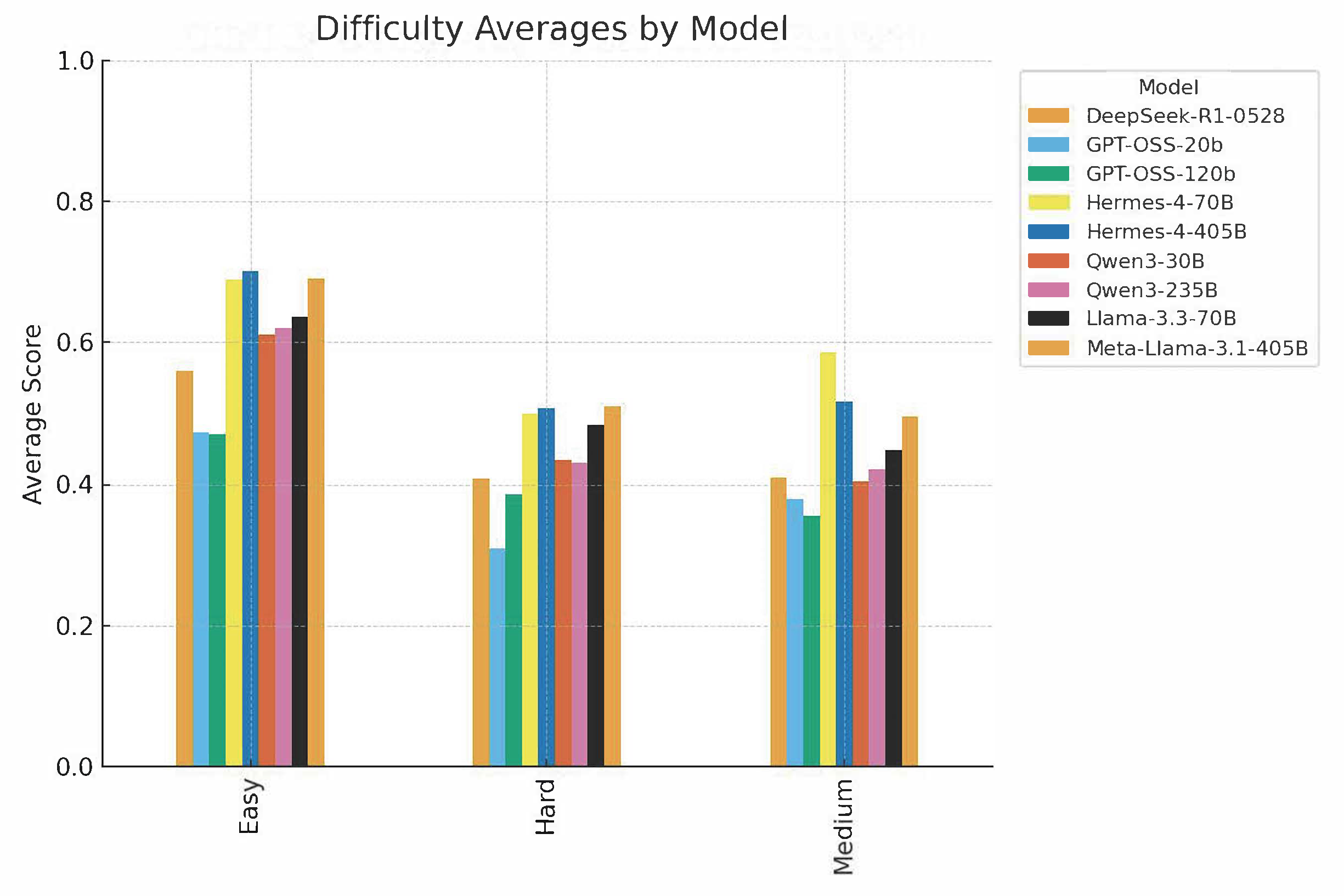
Figure 5: Model accuracy stratified by difficulty, highlighting resilience of Hermes-4 and Meta-Llama families on hard problems.
Consistency and Architectural Diversity
Consistency analysis demonstrates that Qwen3 models achieve the lowest output variance (0.013), three times better than alternatives, making them attractive for applications requiring stable outputs.
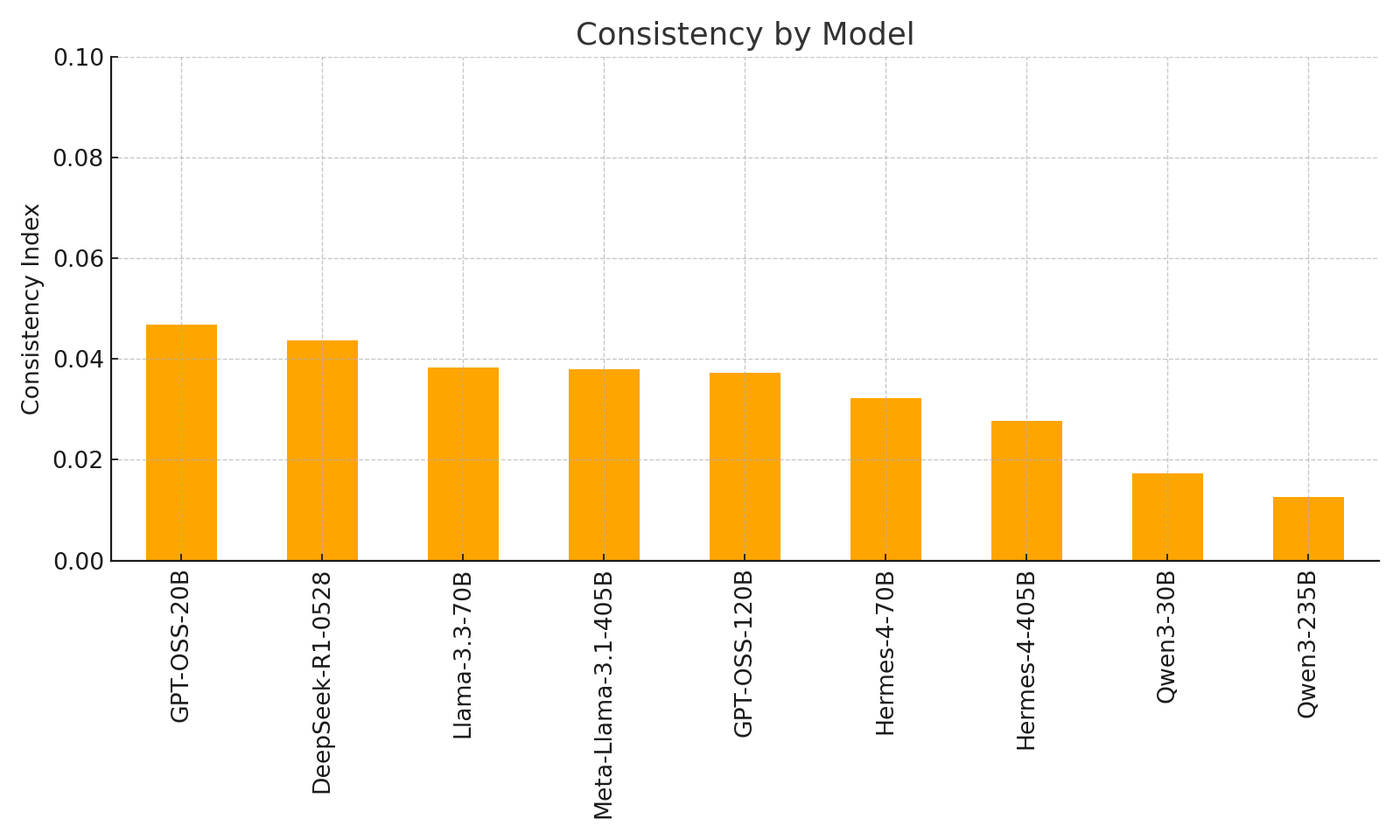
Figure 6: Consistency index by model, with Qwen3 and Hermes models achieving the highest stability.
The inclusion of state-space (Mamba) and MoE architectures reveals that non-transformer models can match or exceed transformer baselines in both accuracy and consistency, suggesting that architectural diversity is viable for reasoning-centric tasks.
Interactive Analysis and Reproducibility
The authors provide an interactive visualization tool for dynamic exploration of results, supporting filtering by model, domain, and difficulty, and enabling community-driven analysis.
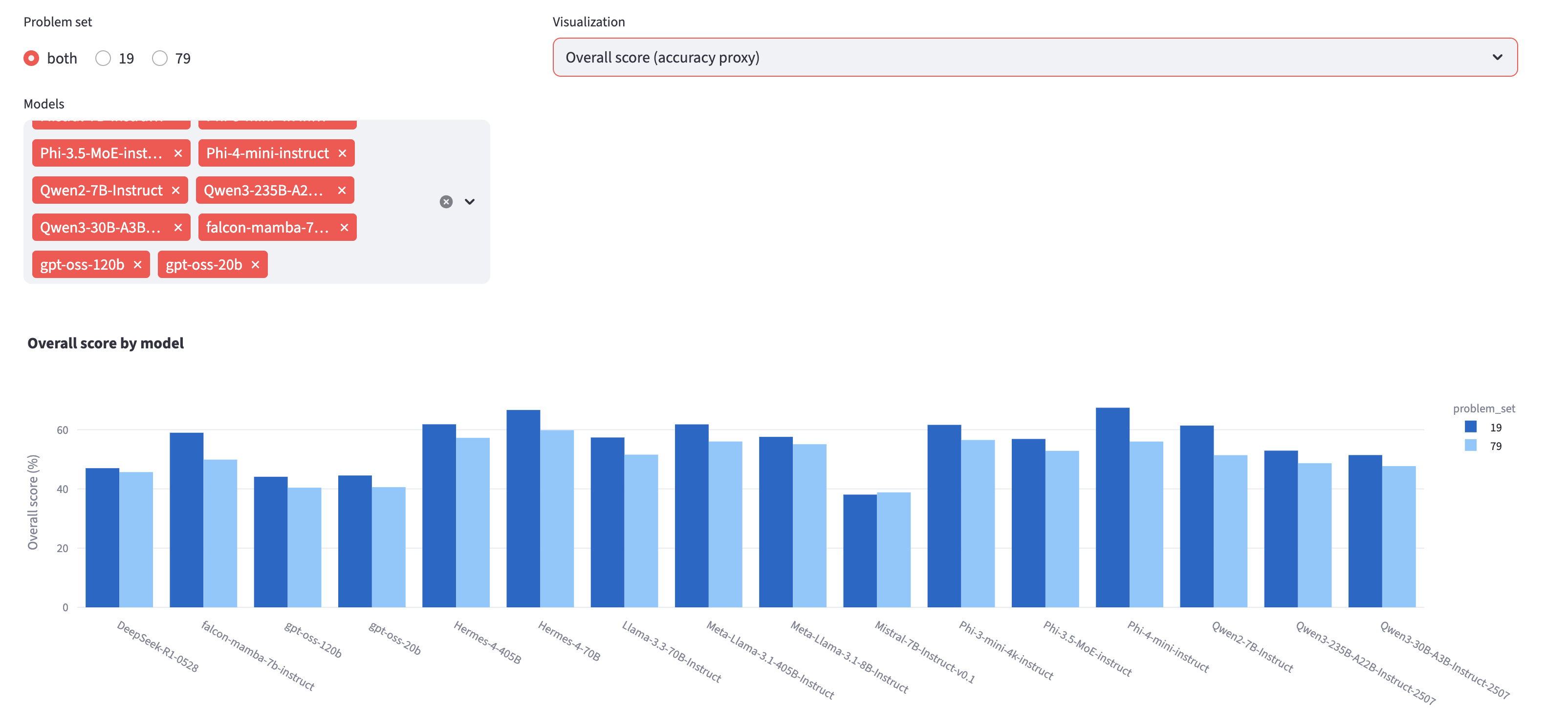
Figure 7: Web-based interface for cross-platform LLM reasoning evaluation, supporting public data exploration and reproducibility.
All data, code, and evaluation scripts are publicly available, ensuring full reproducibility and extensibility.
Implications and Future Directions
The findings have several practical and theoretical implications:
- Scaling laws for reasoning have plateaued: Beyond ~70B parameters, further scaling yields diminishing returns for reasoning tasks.
- Training data quality and process supervision are now the primary levers for improving reasoning, rather than parameter count.
- Transparency-correctness duality mirrors dual-process theories of human cognition (System 1 vs. System 2), suggesting that future models should adaptively balance heuristic and deliberative reasoning.
- Architectural innovation (state-space, MoE, dense transformers) remains a promising direction, especially for applications prioritizing consistency or transparency.
- Benchmarking must report both final correctness and process fidelity to avoid misleading conclusions about model capabilities.
Future work should extend to multi-modal reasoning, code execution, and hybrid neuro-symbolic architectures, and incorporate human expert calibration for interpretability.
Conclusion
This study establishes a robust, infrastructure-agnostic framework for evaluating reasoning in foundation models, revealing that reasoning quality is model-intrinsic and not hardware-dependent. The parameter efficiency paradox, transparency-correctness trade-off, and domain-specific performance patterns challenge prevailing assumptions about scaling and model selection. The dual-metric evaluation and public release of data and tools set a new standard for reproducible, fine-grained analysis of reasoning in LLMs. Progress in reasoning will increasingly depend on data quality, process supervision, and architectural innovation rather than brute-force scaling.