EBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilities
Abstract: Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to teach robots to act called EBT-Policy. Instead of slowly “cleaning up” noisy guesses like diffusion models do, EBT-Policy uses an “energy” score to quickly find good action plans and avoid bad ones. The big idea is that energy acts like a confidence meter: low energy means the plan looks right, high energy means it probably won’t work. Using this energy, the robot can make faster, more reliable decisions—and even figure out when to retry after a mistake.
Key Objectives
The paper focuses on simple, practical questions:
- Can robots learn from human demonstrations in a way that is faster and more reliable than current methods?
- Can an energy-based approach reduce common problems like error snowballing (small mistakes that grow bigger) and slow inference (needing many steps to get an action)?
- Can robots learn to “retry” on their own—without being taught that behavior—just by using the energy signal to guide their actions?
- Does this approach work in both computer simulations and the real world?
Methods Explained Simply
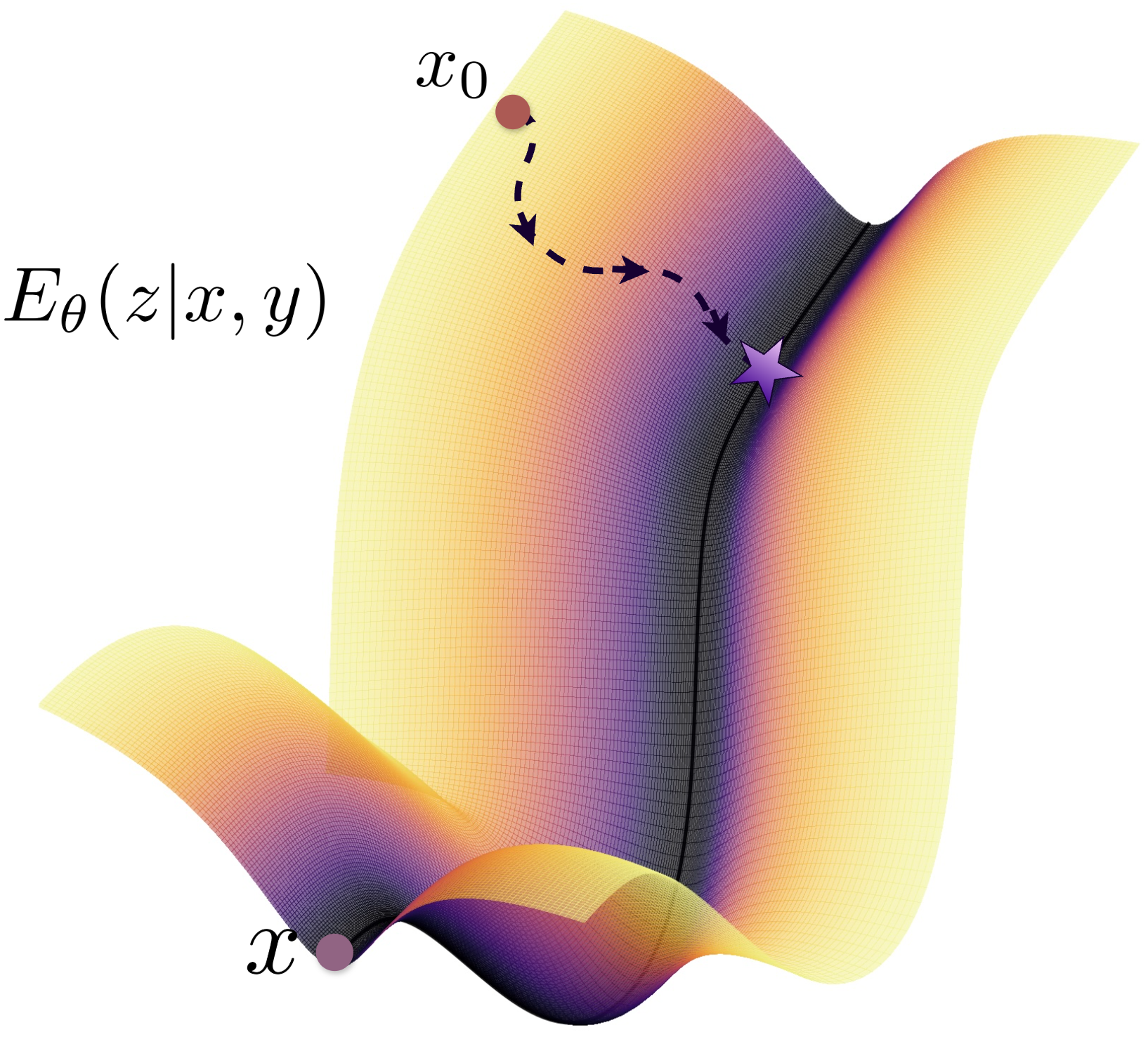
Think of planning robot actions like finding the lowest point in a valley:
- The “energy landscape” is like a map of hills and valleys. Each possible action plan has an energy score. Good plans sit in valleys (low energy). Bad plans are up on the hills (high energy).
- EBT-Policy starts with a rough plan (like dropping a ball somewhere on the map) and then “rolls downhill” by following the steepest direction to reach a valley (a good plan).
- Sometimes the ball can get stuck in a small pit that isn’t the best valley. To avoid that, the method adds a tiny “shake” (random noise), so the ball can hop out and keep searching.
- The robot keeps rolling downhill until the energy stops changing much. If it gets to a low energy quickly, it stops early; if the energy is high (uncertain), it spends more time thinking. This means the robot uses more compute only when it needs to.
To make learning stable and smooth, the authors add practical training tricks:
- Adjust step sizes based on energy (big steps when far from a good plan, small steps when close).
- Normalize action inputs so numbers don’t blow up.
- Clip very large gradients (to prevent wild updates).
- Use momentum-like acceleration (Nesterov) to move more smoothly across the landscape.
They test two versions:
- EBT-Policy-S: a smaller model for fair comparisons in simulation.
- EBT-Policy-R: a larger, multimodal model with vision and (optionally) language for real robots.
Main Findings and Why They Matter
Here’s what they found:
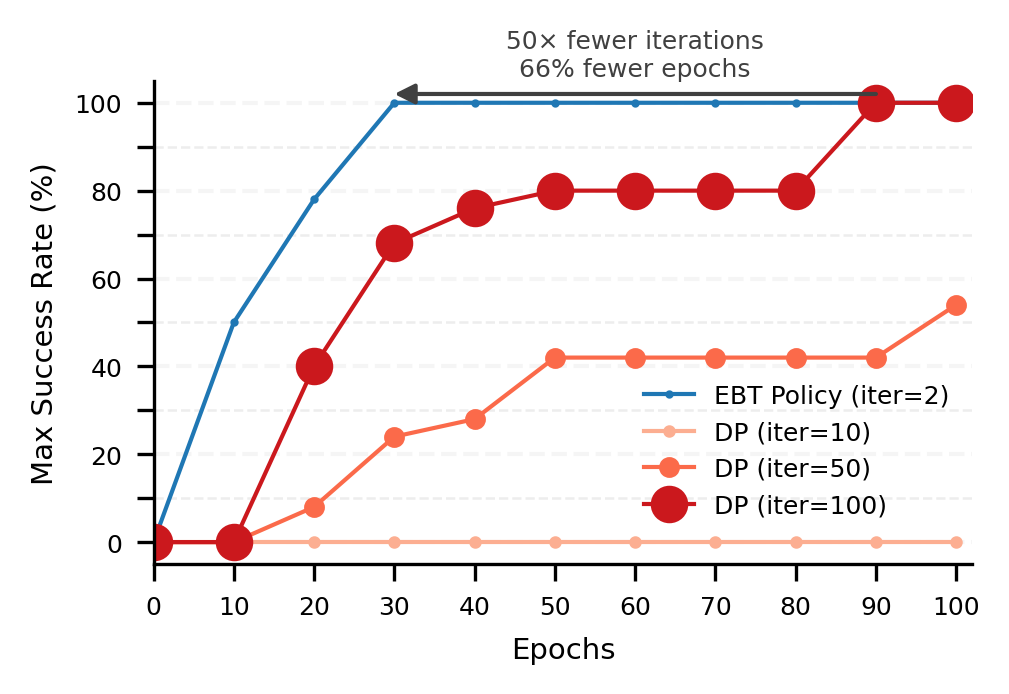
- Much faster inference: EBT-Policy often needs only 2 steps to produce a good action plan, compared to 100 steps for diffusion models. That’s about 50× fewer steps.
- Better success rates: In both simulation (tasks like Lift, Can, Square, Tool Hang) and the real world (Fold Towel, Place Pan, Pick and Place), EBT-Policy beats diffusion-based policies of similar size.
- Example real-world success rates (%): Fold Towel—EBT 86 vs Diffusion 10; Place Pan—EBT 75 vs Diffusion 65; Pick and Place—EBT 92 vs Diffusion 90.
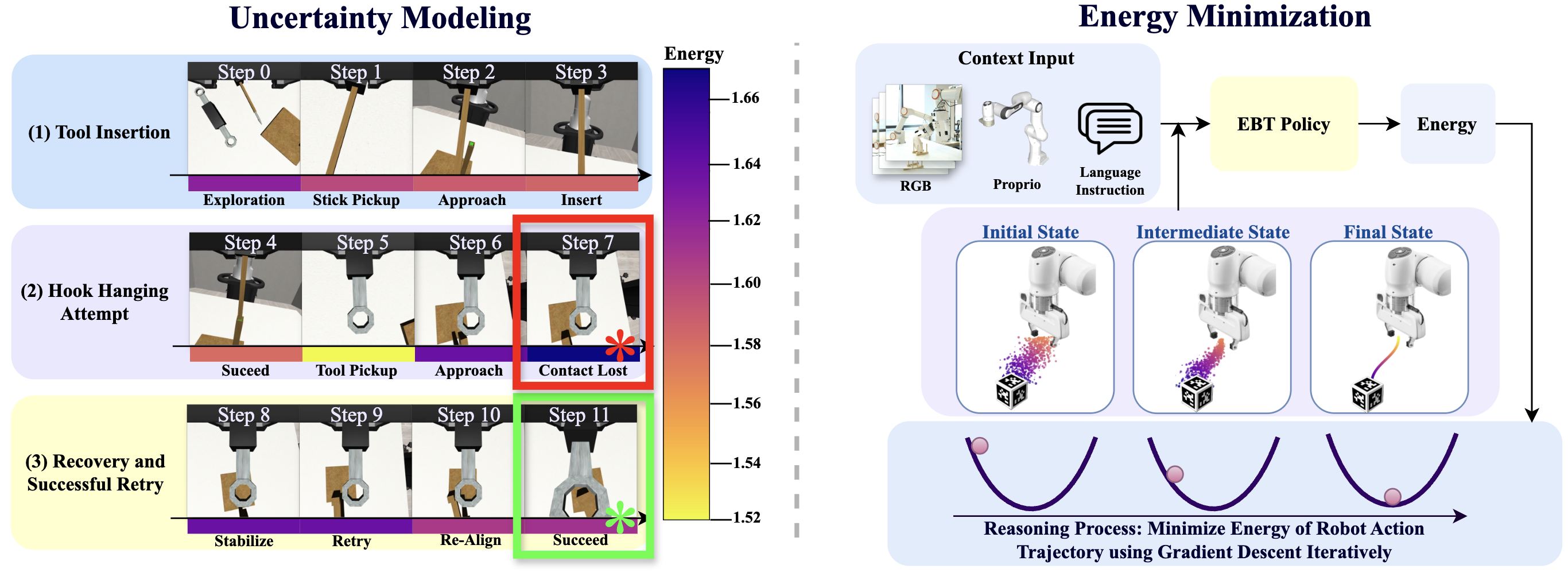
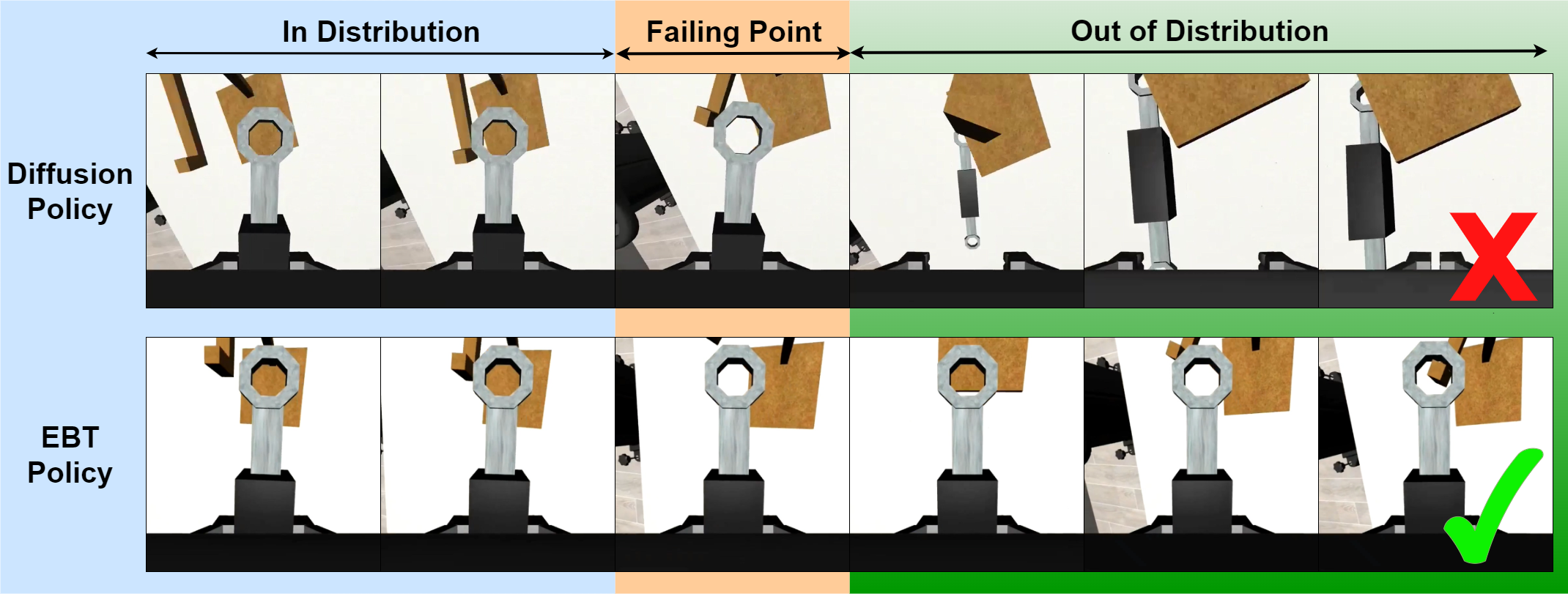
- Emergent retry behavior: When the robot makes a mistake (like missing a hook), EBT-Policy can detect high energy (low confidence), adjust, and try again—without being explicitly trained to retry. This is rare for plain behavior cloning.
- Uncertainty-aware compute: If the situation is tricky, energy stays high and the model takes more steps; if it’s easy, it stops sooner. This makes it both smart and efficient.
Why this matters:
- Robots that act faster and more reliably are crucial for real-world work, like factories, homes, and hospitals.
- The ability to recover from mistakes without special training makes robots more robust in changing environments.
- Using energy as a confidence signal makes robot decisions more interpretable—you can see when and why the robot hesitates or retries.
Implications and Impact
EBT-Policy suggests a promising direction for building robots that:
- Think in continuous, sensor-based spaces (what they actually see and feel), not just in text or tokens.
- Adjust their effort based on internal confidence—spending time only when needed.
- Gain “reasoning-like” abilities (such as retrying intelligently) from a simple energy-minimization process, rather than complex planning modules.
If developed further—through larger models, better tuning, and more diverse data—this energy-based approach could become a foundation for safer, more general, and more capable robot behavior in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following unresolved issues that future work could address:
- Missing statistical rigor: no report of seeds, confidence intervals, or significance tests for success rates in simulation and real-world trials; quantify variance across runs and hardware resets.
- Unclear real-world trial protocols: number of trials per task, success definitions, and environmental randomizations (e.g., object placements) are not specified; standardize and publish evaluation protocols.
- Fairness of baselines: Diffusion Policy hyperparameters and compute budgets may not be equivalently tuned; report wall-clock time, FLOPs, GPU-hours, and latency per control step for both methods under matched accuracy.
- Per-step cost vs. step count: “50× fewer steps” is cited without per-step compute comparisons; profile end-to-end control latency at various control frequencies (e.g., 10–100 Hz).
- Ablations of “EBT-Policy ingredients”: no quantitative ablations for energy-scaled step sizes, RMSNorm, Nesterov momentum, scaled Langevin noise, step randomization, and gradient clipping; report each component’s contribution and interactions.
- Hyperparameter sensitivity: robustness to base step size, noise schedule (σmin/σmax), gradient clip norm, and termination threshold τ is unmeasured; provide sensitivity curves and automatic tuning strategies.
- Convergence and stability theory: no guarantees for convergence of energy descent with exp(E)-scaled step sizes and Nesterov acceleration; analyze conditions for monotonic energy decrease and bounded updates.
- MCMC correctness vs. optimization: Langevin updates are used without Metropolis–Hastings correction; clarify whether the goal is proper sampling or optimization and quantify the bias this introduces.
- Energy calibration as uncertainty: how well energy correlates with failure probability, task difficulty, or OOD degree remains uncalibrated; evaluate using calibration curves, AUROC for OOD detection, and Brier/Expected Calibration Error.
- Cross-context comparability of energy: unnormalized energies may not be comparable across tasks or scenes; investigate temperature/affine calibration or learned per-context normalizers to enable thresholding and compute allocation.
- Dynamic termination criterion: the choice and adaptation of gradient-norm threshold τ is unspecified; study adaptive stopping rules tied to calibrated uncertainty vs. fixed τ.
- Initialization and mode bias: starting from a single random initialization may bias solutions toward one mode; evaluate multi-start inference, diversity metrics, and top-K candidates with energy-based selection.
- Multimodality coverage: while claiming multimodal capabilities, there is no quantitative assessment (e.g., mode coverage, CRPS, minADE/FDE under multi-hypothesis, entropy/diversity metrics).
- Retry behavior generality: emergent retry is shown qualitatively on one task; measure frequency, success rate after failure, and triggers across tasks, seeds, and robots; compare to explicit retry planners.
- Long-horizon reasoning: experiments focus on short to moderate horizons; test extended-horizon, multi-stage tasks requiring memory and subgoal discovery; analyze horizon scaling and error accumulation.
- Closed-loop execution details: clarify action chunk size, re-planning frequency, and how dynamic inference latency interacts with control loops; test robustness under actuation delays and dropped frames.
- Safety and constraint handling: no mechanism for hard constraints (joint limits, velocity/jerk bounds, collision avoidance); integrate constrained optimization or safety shields and quantify safety metrics.
- Physical interaction and force control: evaluate under contact-rich tasks requiring force/impedance control; study how energy descent interacts with low-level controllers to avoid oscillations or chatter.
- Robustness to systematic shifts: provide controlled OOD sweeps (lighting, camera pose, occlusions, object textures/masses, friction) and report performance vs. shift magnitude.
- Data efficiency and scaling laws: no analysis of performance vs. number of demonstrations; plot scaling with data size, model size, and action dimensionality; compare to diffusion scaling.
- Generalization beyond domains tested: assess transfer across robots (different DOFs, grippers), environments, and unseen task families; quantify sim-to-real robustness if applicable.
- Baseline coverage: compare against additional strong BC/offline-RL baselines (e.g., Flow/EDP/RDT/IBC variants, flow matching, conservative Q-learning) under matched parameter and data budgets.
- Real-time feasibility: dynamic compute can introduce variable latency; measure worst-case and tail latencies, jitter, and their impact on tracking and safety at required control rates.
- Energy landscape analysis: no characterization of learned landscape geometry (smoothness, curvature, local minima density); visualize trajectories in reduced subspaces and relate geometry to failures/retries.
- Objective justification: the training loss (MSE to demonstration at each step) lacks a formal derivation linking it to consistent EBM likelihood learning; establish theoretical grounding or compare with contrastive/score-matching EBMs.
- Partition function and temperature: without Z or temperature control, energy scales can drift; explore temperature learning, energy normalization, or hybrid score–energy training for stable, comparable energies.
- Multi-agent/dual-arm scaling: dual-arm tasks are included, but there is no analysis of coordination scalability as action dimensionality grows; study factorized energies or coordination priors.
- Language grounding: real-world variant uses T5, but the effect of ambiguous or compositional instructions is not evaluated; test instruction robustness, paraphrase generalization, and language-conditioned OOD shifts.
- Reproducibility: code, weights, exact datasets (counts, splits), and hardware details are not provided; release artifacts and a reproducible benchmark suite with scripts for fair comparisons.
- Failure case taxonomy: identify where EBT-Policy underperforms (e.g., highly multimodal, deceptive distractors, tight tolerances); categorize errors and connect them to energy dynamics or optimization failures.
- Integration with RL or planning: investigate augmenting EBT-Policy with reward-based fine-tuning, model-predictive control, or hierarchical planners; study when energy-based verification complements planning.
- Multiple candidate selection and risk control: evaluate generating N candidate trajectories with energy- and risk-aware selection, deferral (ask-for-help), or fallback to safe behaviors under high energy.
Practical Applications
Immediate Applications
The following items can be deployed with current tooling, data regimes, and off-the-shelf hardware comparable to the setups described in the paper (e.g., RGB cameras, robot arms, ROS/MoveIt stacks, edge GPUs).
- Bold: Drop‑in replacement for diffusion policies in manipulation labs (Robotics; Academia)
- What: Swap Diffusion Policy baselines with EBT-Policy for bench tasks (lift, can, square, tool-hang) and real robot tasks (towel folding, pick-and-place, pan placement), achieving similar or better success with 10–50× fewer inference steps.
- Tools/workflows: ROS/MoveIt integration; Isaac Sim/robomimic pipelines; EBT-Policy-S for simulation A/B tests and EBT-Policy-R for real robots; Jupyter-based evaluation with success-rate and latency dashboards.
- Assumptions/Dependencies: Access to demonstration data of comparable quality to baselines; GPU for training; embedded GPU or CPU with vectorization for fast MCMC steps; camera calibration and synchronized proprioception.
- Bold: Assembly, bin-picking, and insertion with automatic retry (Manufacturing/Industrial Robotics)
- What: Use the energy scalar as a confidence/uncertainty signal to trigger immediate retries after contact failures (e.g., peg-in-hole, tool hanging), reducing downtime from compounding errors typical in diffusion/flow policies.
- Tools/products: “Energy-gated controller” node that re-issues refined actions when energy remains high; skill server exposing low-energy trajectories; operator HMI showing energy traces.
- Assumptions/Dependencies: Safety-certified cobots; force/torque sensing improves reliability but is not required; validated energy thresholds per task; guarded moves when energy spikes.
- Bold: Warehouse pick-and-place under layout and object variability (Logistics/E-commerce)
- What: Improved OOD robustness to changing bin contents/poses via equilibrium dynamics and energy-based verification; adaptive compute reduces cycle times for easy picks.
- Tools/workflows: Bin-picking workcells with vision pipelines; “dynamic step budget” inference to meet SLA latency; failure segmentation via high-energy episodes for auto-relabelling and active learning.
- Assumptions/Dependencies: Stable lighting or robust vision encoders (e.g., DINOv3); representative demos for target SKUs; calibrated gripper and camera frames.
- Bold: Home/service robotics skills with confidence-aware execution (Consumer Robotics)
- What: Deploy skills like folding towels, clearing surfaces, simple kitchen placement, where the policy’s energy triggers retry, slow-down, or ask-for-help behaviors.
- Tools/products: On-device skills library; mobile-app UI that surfaces confidence (energy bands) and lets users approve retries; multimodal instruction via language prompts.
- Assumptions/Dependencies: Safe operation near people (speed/force limits); curated demo library matching household variation; simple, robust camera setup.
- Bold: Field inspection and light intervention with OOD-aware control (Energy/Utilities; Field Robotics)
- What: Manipulators for toggling valves, placing hooks, or manipulating tools on uneven fixtures; high energy auto-initiates regrasp/retry routines rather than aborting.
- Tools/workflows: Truck/UGV-mounted arms; confidence-to-teleop handoff when energy stays high; offline analysis of high-energy logs to improve coverage.
- Assumptions/Dependencies: Ruggedized hardware; domain-specific demos (fixtures, tools); weather and illumination robustness; connectivity for human-in-the-loop fallback.
- Bold: Confidence overlays and safety gating for teleoperation (Cross-sector; HRI)
- What: Use the energy scalar as a real-time overlay to assist human operators; pause or damp motion when energy exceeds a threshold; auto-suggest corrective grasps.
- Tools/workflows: Teleop UI widget showing energy trendlines; “energy watchdog” ROS node that vetoes low-confidence commands.
- Assumptions/Dependencies: Reliable calibration between policy action space and robot controller; agreed-upon intervention thresholds; latency budgets that preserve operator feel.
- Bold: Energy-based verifier wrapper for existing controllers (Software/Robotics Platforms)
- What: Train an EBT energy function as a learned discriminator over candidate actions from legacy heuristics or diffusion policies and reject/repair high-energy actions.
- Tools/workflows: “Verifier API” that returns energy for proposed trajectories; fallback to safe primitives when energy is high.
- Assumptions/Dependencies: Joint training data or logged trajectories that cover both good/bad actions; careful thresholding—energy is task- and distribution-specific.
- Bold: Compute-aware scheduling on edge devices (MLOps/Systems)
- What: Exploit dynamic inference (terminate when gradient norm falls below τ) to meet hard real-time deadlines without hand-tuned step counts.
- Tools/workflows: Runtime that sets per-skill latency budgets; adaptive step-size and noise scaling; telemetry to correlate latency vs. success.
- Assumptions/Dependencies: Monitoring to prevent pathological long descent on rare states; guardrails on max steps.
- Bold: Dataset diagnostics and active data collection (Academia/ML Ops)
- What: Use persistent high-energy regions encountered during rollouts as signals of data deficit and target new demonstrations where the model is uncertain.
- Tools/workflows: Energy histograms and heatmaps over state space; auto-annotation cues; prioritized teleop collection.
- Assumptions/Dependencies: Logging pipeline; consistent sensor setup between training and deployment; human availability for targeted data capture.
- Bold: Language-conditioned skills in lab/enterprise settings (Education/Enterprise Robotics)
- What: Condition policies on concise natural-language prompts (EBT-Policy-R with T5) to select/manipulate objects, with energy as a guard against misinterpretations.
- Tools/workflows: Prompt templates; operator confirmation when energy remains high; task catalogs mapped to prompts.
- Assumptions/Dependencies: Narrow, well-specified vocabularies; representative language-demo coverage; alignment checks to avoid ambiguous intents.
Long-Term Applications
These opportunities require additional validation, scaling, and in some cases standards/safety certifications before broad deployment.
- Bold: Generalist embodied world models with native continuous reasoning (Robotics Foundation Models)
- What: Scale EBT-Policy into a unified energy-based world model that scores consistency across vision, language, actions, and dynamics, enabling broad skill repertoires and zero-shot transfer.
- Potential products: “Energy World Model” API for planning and control; skill composition by energy minimization.
- Dependencies: Large, diverse multi-task datasets; robust optimization for highly multimodal action spaces; tool-use and long-horizon credit assignment.
- Bold: Multi-robot coordination via shared energy landscapes (Manufacturing/Logistics)
- What: Coordinate teams of manipulators by minimizing a joint energy that captures interference, task allocation, and shared goals; emergent negotiation via gradients.
- Potential workflows: Distributed MCMC with communication-efficient gradient sharing; centralized arbitration using energy budgets.
- Dependencies: Communication latency management; scalable training across agents; safety guarantees for coupled control.
- Bold: Safety-critical surgical/medical manipulation with introspective control (Healthcare Robotics)
- What: Use energy as calibrated uncertainty to gate delicate actions, pause for human confirmation, or switch to safer primitives during high-risk maneuvers.
- Potential products: Surgical-assist co-bots with energy-gated autonomy and explainable retry logic.
- Dependencies: Regulatory approval; rigorous calibration/validation of energy-to-risk mapping; haptic/force feedback integration; sterile and fail-safe design.
- Bold: Mobile manipulation and autonomous driving planners with energy verification (Mobility)
- What: Extend energy-based optimization to trajectory generation in dynamic scenes, using energy as a verifier for OOD hazards and to adapt compute to scene complexity.
- Potential tools: Energy-verified motion planners; fallback and emergency behaviors cued by energy spikes.
- Dependencies: New datasets (traffic, mobile manipulation); real-time guarantees; formal safety envelopes and verification.
- Bold: Standards and certification built around introspective uncertainty (Policy/Regulation)
- What: Develop procurement and safety standards that require introspective measures (e.g., energy thresholds, convergence criteria) for autonomy in shared spaces.
- Potential outcomes: Test protocols that stress OOD conditions; requirements for “ask-for-help” triggers and logging of high-energy events.
- Dependencies: Cross-industry consensus; third-party testbeds; evidence that energy reliably correlates with task risk across domains.
- Bold: Lifelong learning and on-the-fly adaptation via energy-guided data selection (Robotics/ML)
- What: Use the energy landscape to select informative experiences online (DAgger-style) and update policies incrementally without catastrophic drift.
- Potential workflows: Continual learning pipelines with energy-based replay and regularization.
- Dependencies: Safe online learning infrastructure; drift detection; robust optimization in the presence of non-stationarity.
- Bold: Deformable-object manipulation at scale (Manufacturing/Textiles/Agriculture)
- What: Extend observed towel-folding success to cables, garments, nets, and crops, with energy-guided retries and dynamic compute for challenging contact dynamics.
- Potential tools: Libraries of deformable skills; energy-informed tactile exploration.
- Dependencies: Rich demos with varied materials; tactile sensing; simulation advances for deformables to seed pretraining.
- Bold: Energy-aware edge–cloud co-compute (Systems)
- What: Offload hard states (persistent high energy) to cloud solvers or high-fidelity planners, while handling easy states on-device for latency/availability.
- Potential products: Runtime schedulers that route frames by energy thresholds.
- Dependencies: Reliable connectivity; privacy/latency SLAs; graceful degradation strategies.
- Bold: Skill marketplaces with energy-based composition and verification (Software/Platforms)
- What: Publish skills as energy functions that can be composed (sum/min) and verified jointly, enabling modularity and robust reuse across tasks/robots.
- Potential products: “Energy API” standard for third-party skills; composer tooling to build complex behaviors from primitives.
- Dependencies: Interoperable representations; common training/evaluation protocols; IP/licensing for pretrained encoders.
- Bold: LLM–EBT hybrids for plan+act with verification (Enterprise/General Robotics)
- What: Use LLMs for high-level decomposition and EBT-Policy to verify and execute each step, retrying or replanning when energy remains high.
- Potential workflows: Task graphs where each edge is energy-minimized; automatic replanning loops triggered by verification failures.
- Dependencies: Robust grounding from language to continuous actions; guardrails to avoid hallucinated subgoals; datasets pairing plans and demonstrations.
Cross-cutting assumptions and dependencies
- Calibration: Energy must be validated as a reliable proxy for uncertainty/risk per task and sensor setup; thresholds are not universal.
- Data: Performance hinges on demonstration coverage and quality; OOD robustness is improved but not unlimited.
- Safety: Additional sensing (force/torque, tactile) and conservative control policies are recommended for human-proximate tasks.
- Compute: Training typically requires GPUs; inference is lightweight compared to diffusion but still benefits from embedded accelerators.
- Integration: Consistent camera/proprioceptive calibration and time sync; ROS/MoveIt or equivalent control stacks.
- Legal/Compliance: Safety standards (e.g., ISO 10218/13482) and domain regulations (especially healthcare) require extensive validation before autonomy is enabled.
Glossary
- Behavior Cloning (BC): Supervised imitation learning where a policy maps observations to actions using demonstration data. "Within Behavior Cloning (BC), however, Diffusion-based generative policies"
- Boltzmann distribution: A probability distribution proportional to the exponential of negative energy, often used to define EBM densities. "parametrized in the form of a Boltzmann distribution"
- Cartesian space: A task or action representation in 3D position/orientation coordinates rather than joint angles. "searching for a low energy action trajectory in cartesian or joint space ()"
- Covariate shift: A change in the input distribution between training and deployment that can degrade performance. "after encountering a failure causing covariate shift."
- Cosine annealing: A schedule that smoothly decays a parameter (e.g., noise) following a cosine curve over iterations. "The magnitude of the injected noise follows a cosine Langevin Dynamics annealing schedule"
- Denoising score matching: Training objective where a model learns the score (gradient of log-density) by reversing a noise process. "Through denoising score matching, this network implicitly estimates the gradient of the conditional log-likelihood"
- Diffusion Policy: A visuomotor policy that generates actions via a learned reverse-diffusion (denoising) process. "Implicit policies parameterized by generative models, such as Diffusion Policy~\cite{dp}, have become the standard"
- Distribution shift: Mismatch between training and test distributions that can cause model divergence. "divergence under distribution shifts."
- Energy-Based Models (EBMs): Models that assign a scalar energy to configurations; lower energy implies higher compatibility or likelihood. "Energy-Based Models (EBMs)~\cite{ebm-tutorial} address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics"
- Energy-Based Transformers (EBTs): Transformer architectures trained as EBMs that learn scalable energy functions for high-dimensional data. "Recent work on Energy-Based Transformers (EBTs)~\cite{ebt} demonstrates the scalability of EBMs to high-dimensional spaces"
- Energy landscape: The scalar field over configurations (e.g., actions) whose minima correspond to plausible or likely solutions. "represent complex, multi-modal, action distributions through an energy landscape spanning the action space"
- Energy-scaled step sizes: Update magnitudes that adapt based on the current energy value to stabilize optimization/sampling. "we employ energy-scaled step sizes, defined as:"
- Equilibrium dynamics: Inference behavior that seeks steady states (energy minima), often yielding stable corrections during sampling. "modeling equilibrium dynamics, offering improved robustness and reduced exposure bias"
- Exposure bias: Training–inference mismatch where errors compound during sequential generation. "Another critical issue is exposure bias"
- Flow-based policies: Generative policies that transform noise into data via invertible flows. "Diffusion and flow-based policies, however, suffer from several practical challenges."
- Gradient clipping: Technique that bounds gradient norms to prevent exploding updates during training. "we apply gradient clipping \cite{grad-clip}, constraining the global gradient norm to a maximum value of 1.0."
- Implicit policy: A policy defined indirectly via optimization (e.g., energy minimization) rather than an explicit action mapping. "Implicit Policies parametrized through EBMs have failed to become a standard for policy learning"
- Langevin Dynamics: A stochastic gradient-based MCMC method that adds noise during energy descent for sampling. "known as Langevin Dynamics"
- Markov Chain Monte Carlo (MCMC): Sampling methods that construct a Markov chain to draw from complex distributions. "By sampling with Markov Chain Monte Carlo (MCMC) guided by the energy"
- Nesterov acceleration: A momentum-based optimization technique that can speed convergence and escape shallow minima. "we employ Nesterovâs accelerated gradients \cite{nesterov1983}"
- Noise scheduler: A predefined schedule controlling the noise level during diffusion training or inference. "reliance on an externally defined noise scheduler to model data distributions"
- ODE solvers: Numerical integrators for ordinary differential equations used in some generative inference procedures. "the non-reliance on a noise schedule, time-variance, and ODE solvers"
- Out-of-distribution (OOD): Inputs that differ from those seen during training, often leading to failures. "out-of-distribution (OOD) perturbations"
- Partition function: The normalizing constant in energy-based models that sums over all configurations, often intractable. "the intractable partition function "
- Proprioception: A robot’s internal sensing of its own joint states or body configuration. "inputs (RGB frames, robotic proprioception, and language instructions)"
- RMSNorm: A normalization method that rescales inputs by their root mean square, stabilizing training. "For this paper, we use RMSNorm for pre-sample normalization"
- Score-based models: Models that learn the gradient of the log-density (score) instead of the density itself. "DPs are score-based models that represent the data distribution via a stochastic denoising process"
- System 2 reasoning: Deliberative, stepwise reasoning associated with controlled, effortful cognition. "a unified computational framework for embodied System 2 reasoning in robots"
- Teacher forcing: Training strategy that feeds ground-truth previous outputs to a model, potentially causing exposure bias. "enabling multimodality without teacher forcing"
- Teleoperation: Human-controlled operation of a robotic system for data collection or task execution. "Real-world data is collected by us via a teleoperation system"
- Vision–Language–Action (VLA): Models that integrate visual inputs, language instructions, and action outputs for control. "VisionâLanguageâAction (VLA) models~\cite{openvla} in robotics"
- World models: Models that capture environment dynamics for prediction, planning, or control. "world models for robot manipulation"
Collections
Sign up for free to add this paper to one or more collections.