VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Abstract: Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
VFXMaster: A simple guide to how it works and why it matters
What is this paper about?
This paper introduces VFXMaster, an AI tool that can add movie-like visual effects (VFX) to videos. Think of VFX like glowing magic, explosions, shape-shifting, or sparkly transformations. VFXMaster learns how an effect looks and moves from a short example video, then applies that same effect to a new picture to create a new video.
What questions does the paper try to answer?
The researchers focus on three main questions:
- How can we teach one AI model to handle many different effects without training a separate model for each effect?
- How can the model learn the “essence” of an effect (its look, motion, and timing) from an example and apply it to new content without copying unrelated stuff like the background or characters?
- How can the model quickly adapt to brand-new effects it has never seen before using just one example?
How does VFXMaster work? (Explained with simple ideas)
Here’s the approach, step by step. Along the way, we’ll explain key terms with everyday comparisons.
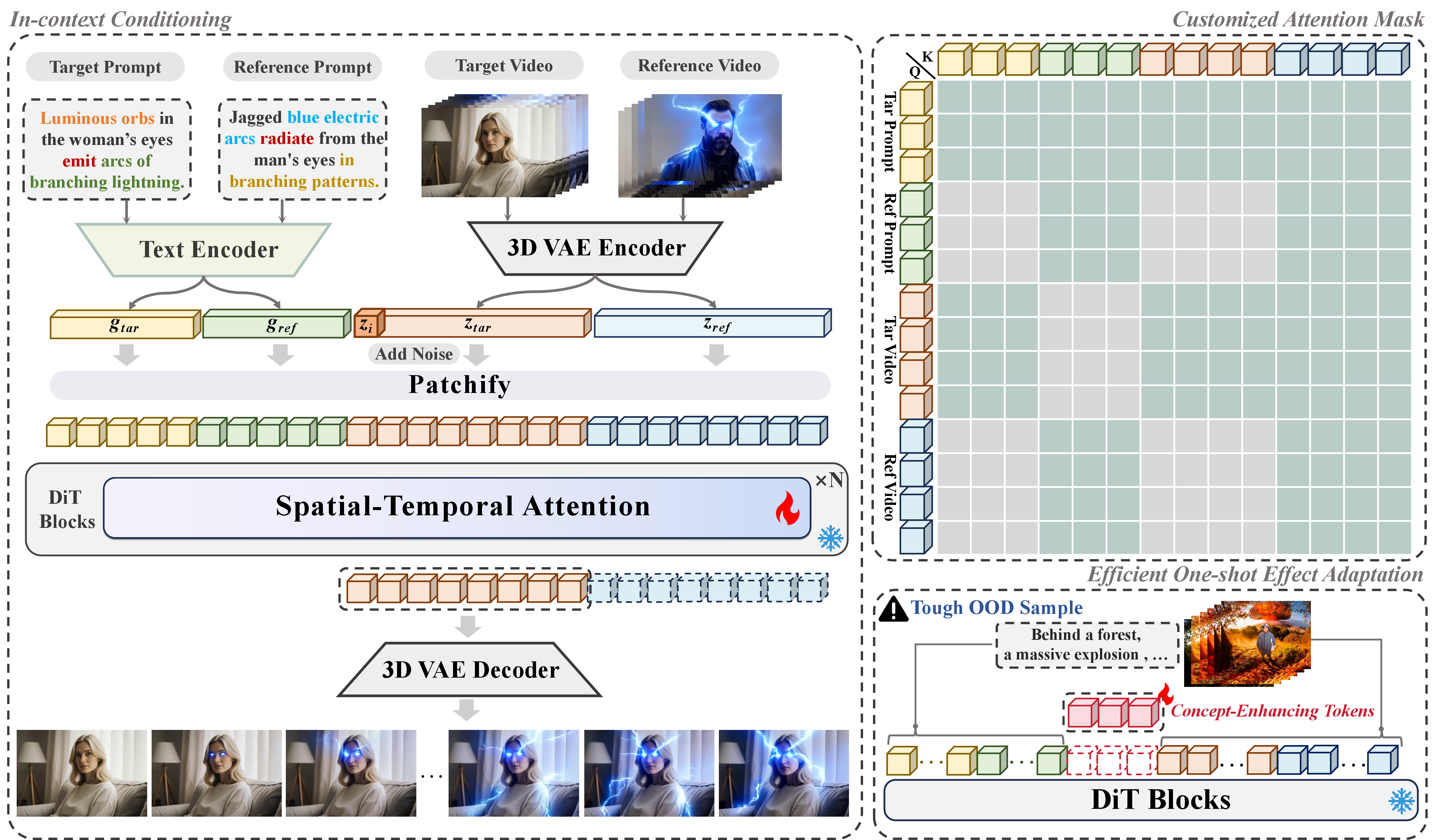
- Learning by example (in-context learning)
- Idea: Show the model a “reference” example (a prompt plus a video) and ask it to apply the same effect to a new “target” image and prompt.
- Analogy: It’s like showing a makeup artist a short clip of glowing purple eye makeup, then asking them to apply that same style to a new face photo.
- Keeping the right information, blocking the wrong information (attention mask)
- Problem: The reference video includes more than just the effect—there’s also the person, the background, the colors, etc. If the AI learns all of it, it might accidentally copy the reference person or scene instead of only the effect.
- Solution: The model uses an attention mask, which is like noise-canceling headphones for the AI’s “attention.” It lets through the effect details (how sparks move, what glow looks like) and blocks unrelated details (who the person is, the background).
- Result: The model transfers only the effect, not the identity or scenery.
- Fast learning from one example (one-shot effect adaptation)
- Problem: Some effects are totally new or weird (out-of-domain). Even a smart model might struggle.
- Solution: The model adds a small set of special “concept-enhancing tokens.”
- Analogy: Imagine sticky notes with reminders that say, “Make the glow bloom and fade this way” or “Particles should swirl like this.” The model learns these notes from one user-provided example video. It keeps the main model frozen and only learns the notes—fast and lightweight.
- The engine under the hood (but in simple terms)
- VFXMaster builds on a powerful video-making AI (a diffusion model with a transformer). Diffusion models create videos by cleaning up noisy frames step by step until a clear video appears.
- “Latent space” is like a secret, compact code that represents the video’s content. The model mixes information from the reference and target in this code space and uses its attention system (with that attention mask) to focus on the effect.
Key terms in plain language:
- Diffusion model: An AI that starts with “TV static” and gradually turns it into a clear picture or video.
- Transformer and attention: A way for the AI to “pay attention” to the most important parts of the data—like focusing on moving sparks instead of the background wall.
- In-context learning: Learning from the example you just showed it, without retraining the whole model—like copying a style right after seeing it.
- One-shot adaptation: Learning a new effect from just one example, quickly.
What did the researchers find?
After training on about 10,000 effect videos across 200 types of effects, VFXMaster showed:
- Strong effect transfer on known effects:
- It added effects like “explode,” “dissolve,” “inflate,” or stylized makeups more cleanly and consistently than other methods.
- It kept motion smooth across frames and captured fine details (like particles and glows).
- Better generalization to new, unseen effects:
- Even without extra help, the in-context setup gave it some ability to handle new effects.
- With the one-shot adaptation tokens, it got much better at new effects—capturing their look and motion more accurately while avoiding copying unrelated content.
- Less “content leakage”:
- Thanks to the attention mask, the model rarely copied the reference character or background into the new video. It transferred the effect, not the scene.
- Human preference:
- In user studies, people preferred VFXMaster’s videos over other methods for both effect consistency and overall look.
- Data helps:
- Training on more varied effects improved both quality and generalization. The more examples it sees, the better it learns the “rules” of how effects behave.
Why these results matter:
- Previous approaches often needed a separate mini-model (LoRA) for each effect, which is slow, expensive, and doesn’t generalize well.
- VFXMaster uses one unified model that can learn new effects quickly from a single example, saving time and effort.
So what’s the big impact?
- For creators: Filmmakers, game designers, and social media creators can quickly apply complex effects to their own images and videos—without advanced VFX skills.
- For AI research: It shows how in-context learning plus careful attention control and one-shot adaptation can make models more flexible and general.
- For the future: The team plans to release code, models, and a dataset, which could speed up progress in creative video tools, education, and accessible content creation.
In short
VFXMaster is like a skilled digital artist that watches a short example of an effect and then recreates that effect on your own image—cleanly, quickly, and without accidentally copying things you didn’t want. It works well on known effects and can learn new ones from just one example. This could make high-quality video effects much easier and more accessible for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, uncertainties, and missing explorations that future research could address to strengthen and extend VFXMaster.
- Dataset curation and labeling details are under-specified:
- How “same VFX” categories were defined, annotated, and validated; inter-annotator agreement and labeling criteria are missing.
- Category balance, long-tail distribution, and potential duplicates or near-duplicates are not reported.
- Licensing/consent status of commercial and online sources (Higgsfield, PixVerse) and implications for open release and re-use are unclear.
- OOD benchmark construction lacks transparency:
- Exact OOD selection criteria, effect taxonomy, and distance measures (semantic or visual) used to deem samples “unseen” are not described.
- Potential overlap with training effects or weak OOD definitions could bias generalization claims.
- Evaluation metrics require validation:
- The VLM-based VFX-Cons. (EOS, EFS, CLS) needs reliability testing (agreement with human judgments, calibration, sensitivity to prompt wording).
- Metric robustness across effect types (particle-like vs. style-like) and across different VLMs is not assessed.
- No identity preservation metric (e.g., face-ID similarity) or content integrity metrics are reported, despite claims of better identity retention.
- Lack of statistical rigor in reported results:
- No confidence intervals, variance, or statistical significance tests are provided for quantitative metrics or the user study.
- User study design details (stimulus selection, randomization, blinding, power analysis) and per-category performance are missing.
- In-context attention mask mechanics are unclear:
- Precise construction of the mask (per-head, per-layer, learned vs. fixed), gating thresholds, and the algorithm for “semantic similarity amplification” are not specified.
- Sensitivity analyses on mask design choices and failure modes (when mask under-suppresses leakage or over-suppresses effect cues) are absent.
- No exploration of learning the mask (e.g., via differentiable gating or supervision) versus hand-crafted masking patterns.
- Concept-enhancing tokens (one-shot adaptation) need deeper characterization:
- How many tokens are optimal, their positional encoding, initialization strategies, and ablations on token count/shape are missing.
- Generality across targets: do tokens trained on one reference effect transfer well to new subjects/scenes without re-tuning?
- Management of a token library: composition of multiple effects, conflict resolution when loading multiple token sets, and memory organization remain unexplored.
- Quantitative time/compute cost for one-shot adaptation (steps, GPU time) is not reported.
- Scope and controls of effect transfer are limited:
- No user-controllable knobs for effect intensity, spatial locality, duration, timing (start/end frames), or selective partial transfer.
- No mechanism to prevent effect placement at semantically incorrect locations (e.g., aligning a “beam” to a hand) when the target image lacks geometry cues.
- Integration with spatial/temporal controls (keypoints, masks, motion trajectories) to achieve precise compositing is not explored.
- Robustness to reference quality and domain shifts is not tested:
- Performance under low-resolution, compressed, noisy, or heavily edited reference videos, and across diverse styles (anime, line art, photoreal, minimalistic) is unknown.
- Robustness to extreme camera motion, occlusion, cluttered backgrounds, and fast/nonlinear dynamics is not characterized.
- Temporal scalability and long-duration generation are unaddressed:
- Training/inference is limited to 49 frames at 8 fps; behavior on longer sequences, higher frame rates, and temporal consistency over minutes remains unknown.
- Accumulation of artifacts (flicker, ghosting, temporal drift) over longer videos is not measured.
- Generalization beyond CogVideoX-5B:
- Portability to other backbones (e.g., HunyuanVideo, LTX-Video) and to different architectures (UNet-based diffusion) is not evaluated.
- The extent to which fine-tuning only spatial-temporal attention layers suffices across models and scales is unclear.
- Comparative baselines are limited:
- OOD generalization comparisons only include internal variants; external adaptation methods (e.g., LoRA, adapters, ControlNet-like video controls) are missing.
- No comparisons against reference-based video stylization/transfer systems or motion transfer frameworks that could baseline effect imitation.
- Effect compositionality is not demonstrated:
- Support for combining multiple reference effects, layering/compositing, and interaction effects (e.g., fire + smoke + lens flare) is absent.
- Mechanisms to compose learned tokens (multi-effect stacks) or mix effects at different strengths are not explored.
- Content leakage mitigation remains partial:
- While CLS improves, rigorous tests for leakage across varied backgrounds/subjects (e.g., colors, identities, objects) are sparse.
- Strategies to enforce disentanglement (e.g., adversarial objectives, orthogonality constraints, causal masking) are not investigated.
- Semantic grounding and autoprompting are open:
- Obtaining high-quality reference prompts is non-trivial; automatic prompt extraction from reference videos (effect recognition, descriptors) is not addressed.
- Alignment between textual effect semantics and visual effect attributes (ontology, concept taxonomy) is not formalized.
- Physical plausibility and safety considerations are missing:
- Modeling or controlling physically coherent effects (fluids, smoke, lighting) and avoiding harmful artifacts (e.g., seizure-inducing flicker) are not discussed.
- Ethical guidelines for effect insertion (e.g., misleading media, weapon-like effects) and content moderation hooks are absent.
- Failure case analysis is minimal:
- Representative failure modes (e.g., mode collapse to texture overlays, identity distortion, misplaced effects, timing mismatch) are not catalogued nor quantified.
- Diagnostics for when the model should recommend one-shot adaptation (vs. baseline in-context) are not provided.
- Data scaling and sample efficiency remain open:
- Beyond showing monotonic gains to 10k samples, saturation points, diminishing returns, and strategies for active/curated data acquisition are unknown.
- Few-shot generalization without one-shot adaptation, and leveraging weak labels or self-supervised clustering, could be explored.
- Production integration questions:
- How outputs integrate with professional pipelines (color spaces, tone mapping, motion blur, camera tracking, 3D compositing) is not specified.
- Latency, memory footprint, and deployment feasibility on creator hardware are not reported.
- Parameterization and hyperparameters:
- Training only “3D full-attention layers” is stated, but the exact layers, number of heads, depth range, and fine-tuning schedule are not enumerated.
- Sensitivity to 3D RoPE configurations and alternative positional encodings is untested.
- Identity preservation and content protection:
- No explicit identity preservation mechanism (ID/appearance locks) or metrics; trade-offs between effect strength and subject fidelity are not quantified.
- Mechanisms to prevent altering protected attributes (e.g., logos, faces) when transferring effects are not provided.
- Reproducibility and open release:
- Code, models, dataset, and metric are promised but not yet available; without them, independent verification and community benchmarking remain blocked.
- Clear documentation for dataset splits, preprocessing, and multi-resolution padding/alignment is needed for reproducibility.
- Energy and compute footprint:
- Training (40k steps on A800s) and inference costs, energy use, and environmental footprint are not provided; efficiency improvements and distillation pathways are open.
- Theoretical framing:
- No formal analysis of why in-context concatenation + masking yields generalizable effect imitation; a theoretical framework (e.g., information flow or causal transfer) could guide design and guarantees.
- Extending beyond single-frame queries:
- The approach uses the first target frame; using multi-frame queries to preserve pre-existing motion or ensure tighter alignment with target dynamics is not studied.
- Security and adversarial robustness:
- Susceptibility to adversarial or malicious reference prompts/videos (e.g., triggering leakage or content injection) and safeguards are not explored.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, mapped to sectors with suggested tools or workflows and key assumptions.
- Film/TV post-production: rapid VFX prototyping and shot-level effect transfer
- Sector: media/entertainment
- Tool/workflow: a “VFX Transfer” plugin for Adobe After Effects, DaVinci Resolve, Nuke; editors select a reference effect clip and a target plate (first frame image), run in-context transfer, iterate with prompt edits
- Assumptions/dependencies: access to VFXMaster weights; GPU acceleration on workstations or cloud; rights to use the reference effect sample; integration with standard color spaces and timelines
- Game studios: style-consistent effect ideation from a single exemplar
- Sector: gaming/software
- Tool/workflow: internal tool to derive particle/magic/impact effects for concept reels from one reference sequence, reducing per-effect LoRA training costs
- Assumptions/dependencies: acceptable inference times for 49-frame outputs; dataset coverage similar to game art style; no need for real-time performance yet
- Advertising and social campaigns: quickly apply brand-themed effects across diverse assets
- Sector: advertising/marketing
- Tool/workflow: cloud API for “effect cloning” across product shots; batch pipeline: reference clip → prompt scaffold → effect QA via VFX-Cons (EOS/EFS/CLS) → export
- Assumptions/dependencies: prompt quality matters; brand safety review; reference effect licensed for derivative use
- Creator platforms: effect templates in UGC editors (e.g., CapCut, TikTok, Instagram Reels)
- Sector: social media/consumer software
- Tool/workflow: curated “effect packs” as reference videos; one-click transfer to user images for short clips; in-app slider to tune effect intensity guided by attention masks
- Assumptions/dependencies: mobile/cloud inference trade-off; clear user labeling as AI-generated; moderation for harmful or misleading content
- AR filters and short-form content: non-physically plausible effects for stylized clips
- Sector: AR/VR/consumer apps
- Tool/workflow: server-side generation of 1–2 second stylized sequences applied to selfies or product shots; use CLS to prevent background leakage
- Assumptions/dependencies: latency constraints; users provide clear target images; consistent identity preservation for faces
- E-commerce product highlights: dynamic reveal, sparkle, dissolve effects for catalogs
- Sector: retail/e-commerce
- Tool/workflow: batch pipeline integrating SKUs → select effect reference → generate product hero animations → A/B test conversions
- Assumptions/dependencies: neutral backgrounds improve fidelity; compliance and accessibility (avoid seizure-inducing dynamics)
- Virtual production and previz: effect visualization without full simulation
- Sector: media/virtual production
- Tool/workflow: quick previz overlays using reference energy beams or weather transitions; export as animatics for director review
- Assumptions/dependencies: alignment with camera metadata; final shots still need high-end simulation for physics-critical scenes
- Educational media and courses: teaching VFX principles via in-context examples
- Sector: education
- Tool/workflow: classroom exercises: “clone this effect” across student assets; analyze attention mask impact on leakage
- Assumptions/dependencies: open release of code/dataset; policy-compliant materials
- Research and benchmarking: adopt VFX-Cons metric for effect quality audits
- Sector: academia/AI evaluation
- Tool/workflow: integrate EOS/EFS/CLS into lab evaluation suites; compare in-context vs. LoRA-MoE baselines on OOD sets
- Assumptions/dependencies: consistent VLM for scoring; transparent metric definitions; reproducible test sets
- Post-production QA: automated detection of content leakage
- Sector: media/quality assurance
- Tool/workflow: run CLS checks to flag unintended transfer of subject/background from reference prompts; gate releases
- Assumptions/dependencies: access to prompts/reference metadata; threshold calibration to minimize false positives
- SMB marketing kits: small businesses apply cinematic transitions to promos
- Sector: small business/marketing
- Tool/workflow: web app offering “dissolve,” “explode reveal,” “ta-da” effect templates; guided prompt builder
- Assumptions/dependencies: simple UX; cloud costs covered by subscription; licensing of reference libraries
- Accessibility and safety review: motion intensity controls for sensitive audiences
- Sector: policy/compliance
- Tool/workflow: integrate Dynamic Degree with content policies; auto-downgrade high-intensity patterns
- Assumptions/dependencies: organizational policies; regulator-aligned thresholds
Long-Term Applications
The following use cases require further research, scaling, or development (e.g., real-time performance, broader OOD generalization, policy standards).
- Real-time live streaming effects with on-the-fly reference cloning
- Sector: social media/live streaming
- Potential product: “Live VFX Clone” engine running on edge GPUs; adaptive attention masks to prevent leakage mid-stream
- Dependencies: optimized DiT variants; low-latency 3D VAE; hardware acceleration on mobile/edge; safety filtering
- On-device AR glasses rendering of complex non-physical effects
- Sector: AR/VR/hardware
- Potential product: lightweight VFXMaster variants using distillation/quantization; token caching for effect packs
- Dependencies: model compression; energy constraints; thermal budgets; fast concept token loading
- Marketplace for “Effect Token Packs” (one-shot adapted concepts)
- Sector: creator economy/platforms
- Potential product: curated OOD token packs sold/licensed; creators upload single-shot references, platform fine-tunes tokens
- Dependencies: IP ownership and provenance; secure token distribution; misuse prevention
- End-to-end co-creative agents: effect planning, retrieval, and quality assurance
- Sector: software/AI agents
- Potential product: agent that searches reference libraries, drafts prompts, runs transfer, evaluates via VFX-Cons, and iterates
- Dependencies: robust effect retrieval; multi-agent orchestration; human-in-the-loop interfaces
- Studio-scale pipelines: unified VFX transfer across episodes/franchises for style consistency
- Sector: media/entertainment
- Potential product: “Style Bible” effect library with in-context policies; per-franchise tokens ensuring continuity
- Dependencies: dataset scale; asset management integrations; editorial governance
- Realistic training simulations enhanced by stylized effects (for communication/training)
- Sector: public safety/education
- Potential product: scenario visualizations that convey hazard cues via abstract effects; instructional videos
- Dependencies: human factors research; appropriateness standards; avoidance of misleading realism
- Cross-modal effect retrieval and generation (text+audio+motion)
- Sector: multimedia/AI research
- Potential product: multi-modal reference that uses audio cues for effect timing; motion trajectories as control signals
- Dependencies: extended conditioning beyond text/video; alignment of control streams; dataset expansion
- Standardization of VFX quality metrics and disclosure norms
- Sector: policy/standards
- Potential product: industry-wide adoption of EOS/EFS/CLS; guidance for labeling AI-generated effects; watermarking integration
- Dependencies: cross-industry consensus; regulator engagement; interoperable metadata formats
- Provenance and IP protection for reference-based VFX
- Sector: policy/legal/rights management
- Potential product: effect provenance tracing; consent and license verification APIs; automatic non-leakage audits prior to release
- Dependencies: cryptographic watermarking; rights databases; platform-level enforcement
- Broad OOD generalization via larger, diverse datasets and token learning
- Sector: academia/AI foundation models
- Potential product: next-gen unified VFX foundation model trained on millions of effects; improved in-context masks
- Dependencies: large-scale curated VFX datasets; compute budgets; ethical sourcing and licensing
- Enterprise content governance: automated checks against harmful or deceptive effects
- Sector: compliance/governance
- Potential product: policy engines that block certain surreal effects in regulated contexts; adaptive CLS thresholds
- Dependencies: domain-specific policies; risk assessment frameworks; audit logs
- Consumer-grade mobile apps with privacy/identity controls
- Sector: daily life/consumer apps
- Potential product: face-lock features to prevent identity alteration; parental controls for intensity and content type
- Dependencies: reliable identity preservation modules; age gating; transparent UX
Common Assumptions and Dependencies Across Applications
- Model availability and licensing: open release of code/models/dataset as stated; legal use of reference videos and prompts.
- Compute and latency: GPUs or efficient on-device inference for acceptable turnaround, especially for live or mobile scenarios.
- Quality of inputs: high-quality reference videos and well-formed prompts; multi-resolution handling as in the paper.
- Generalization limits: OOD performance improves with dataset scale and one-shot adaptation; some niche effects may still need additional tuning.
- Safety and compliance: mechanisms to prevent content leakage, misleading outputs, or harmful dynamics; adoption of VFX-Cons and watermarking.
- Integration: compatibility with existing NLE tools, asset pipelines, cloud orchestration, and data governance.
Glossary
- 3D control signals: Explicit 3D guidance inputs used to manipulate motion, positions, and camera in generation models. "Several studies~\cite{bai2025recammaster,bai2024syncammaster, xing2025motioncanvas} introduce 3D control signals to manipulate object positions, motion trajectories, and camera perspectives within the 3D scene."
- 3D full attention: Attention that jointly attends over spatial and temporal dimensions to maintain consistency in video models. "Based on DiT, CogVideoX~\cite{yang2024cogvideox} utilizes 3D full attention to ensure spatialâtemporal consistency."
- 3D full-attention layers: The attention layers operating over spatiotemporal tokens in DiT that are specifically updated for this task. "For training, we update only the 3D full-attention layers within the DiT blocks using the Adam optimizer with a learning rate of 1e-4."
- 3D Rotary Position Embedding (RoPE): A positional encoding technique extended to 3D to encode spatial-temporal positions for attention. "We apply identical 3D Rotary Position Embedding (RoPE)~\citep{su2024roformer} to both target and reference video, explicitly promoting the model to perceive the relative spatial-temporal relationships during contextual interaction."
- 3D Variational Autoencoder (VAE): A generative encoder-decoder that compresses videos into latent representations across time and space. "We adopt CogVideoX-5B-I2V~\citep{yang2024cogvideox} as our basic image-to-video model, which is built upon a 3D Variational Autoencoder (VAE)~\citep{kingma2013auto}."
- Compositing: The process of combining rendered and live-action elements into a final image or video. "Traditional VFX production ... demands specialized skills across multiple stages, including modeling, rigging, animation, rendering, and compositing~\cite{du2021diffpd}."
- Concept-enhancing tokens: Learnable tokens added to the model’s token sequence to capture fine-grained effect attributes from one example. "Specifically, we freeze the base model and introduce a small set of learnable concept-enhancing tokens , which are concatenated with the unified token sequence along the token dimension."
- Content Leakage Score (CLS): A metric that measures how much unrelated content from the reference is undesirably transferred into the generated video. "while CLS evaluates whether non-effect-related attributes from the reference video are undesirably transferred to the generated video."
- ControlNet: A technique that enables controllable generation by duplicating layers from a pretrained model and linking with zero-initialized convolutions. "ControlNet~\cite{zhang2023adding} facilitates image generation through control signals by replicating designated layers from pre-trained models and connecting them with zero convolutions."
- DiT blocks: The sequence of Diffusion Transformer layers that process token sequences during denoising. "We concatenate them along the token dimension as a unified token sequence and feed into the DiT blocks."
- Diffusion Transformer (DiT): A Transformer-based architecture for diffusion models that captures long-range dependencies for video generation. "the Diffusion Transformer (DiT)~\cite{peebles2023scalable} leverages Transformer architectures to effectively capture long-range dependencies, thereby improving temporal coherence and dynamics."
- Dynamic Degree: An evaluation metric quantifying the motion intensity or dynamics in video generation. "we evaluate our method using two established metrics: Fréchet Video Distance~(FVD)~\citep{unterthiner2018towards} and Dynamic Degree~\citep{huang2024vbench}."
- Effect Fidelity Score (EFS): A metric assessing how closely the generated effect matches the effect in the reference video. "Building upon EOS, EFS assesses whether the generated effects are consistent with those in the reference video."
- Effect Occurrence Score (EOS): A metric indicating whether the intended visual effect appears in the generated video. "EOS measures whether visual effects occur in the generated video."
- Fréchet Video Distance (FVD): A distributional distance metric evaluating realism and quality of generated videos. "we evaluate our method using two established metrics: Fréchet Video Distance~(FVD)~\citep{unterthiner2018towards} and Dynamic Degree~\citep{huang2024vbench}."
- ID-to-video generation: Generating videos that preserve a given identity, integrating identity conditioning into video synthesis. "VACE~\cite{jiang2025vace} integrates ID-to-video generation, video-to-video editing, and mask-based editing into a unified model, enabling efficient video generation and editing."
- Image-to-Video (I2V): Generating a temporal sequence (video) from a single input image, often conditioned on text. "we present VFXMaster, the first reference-based framework that evolves image-to-video~(I2V) generation for this task through in-context learning."
- In-context attention mask: A masking mechanism in attention that restricts information flow to prevent leakage and focus on effect attributes. "we introduce an in-context attention mask to manage information flow, as shown in Fig.~\ref{fig:pipeline}."
- In-context conditioning: Conditioning the model by providing a reference example within the input context to guide generation. "we introduce an in-context conditioning strategy that prompts the model with a reference example."
- In-context learning: Learning behavior where a model leverages provided examples in its input to perform tasks without explicit parameter updates. "It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content."
- Latent code: The compressed representation (tokens) produced by a VAE that the diffusion model operates on. "the reference video and target video are encoded as latent codes and by the 3D VAE, where is noised."
- Latent space: The representational space where latent codes reside and interact during generation. "By sharing the same 3D VAE and text encoder, the reference part and the target part are landed into the same latent space."
- LoRA (Low-Rank Adapters): A parameter-efficient fine-tuning method that adds low-rank matrices to certain layers to adapt models. "Several recent works have achieved preliminary visual effect generation by finetuning Low-Rank Adapters (LoRA) on pretrained models~\cite{hu2022lora,liu2025vfx}."
- LoRA-MoE: An architecture combining Low-Rank Adapters with a Mixture-of-Experts approach to jointly learn multiple effects. "Recently, \citet{mao2025omni} has made initial attempts using the LoRA-MoE architecture for learning the effects in the training set jointly, but they still cannot generalize to unseen effects."
- Mask-based editing: Editing technique where modifications are restricted to regions specified by masks. "VACE~\cite{jiang2025vace} integrates ID-to-video generation, video-to-video editing, and mask-based editing into a unified model."
- Modeling: Creating 3D geometric representations of objects for use in rendering and animation. "including modeling, rigging, animation, rendering, and compositing~\cite{du2021diffpd}."
- One-shot effect adaptation: Rapidly adapting a model to a new effect using only a single example. "we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly."
- Out-of-Domain (OOD): Data or effects not present in the training distribution, posing generalization challenges. "Furthermore, to enhance generalization to Out-of-Domain (OOD) effects, we design an efficient one-shot effect adaptation strategy..."
- Reference prompt: The textual description paired with the reference video that semantically anchors the effect. "The reference prompt and target prompt are encoded as word embeddings $\textsl{g}_{target}$ and $\textsl{g}_{ref}$ by the text encoder."
- Reference-target data pair: A pair of videos sharing the same effect, used as example-query context for in-context learning. "we observe that videos sharing the same VFX differ only in subjects and backgrounds, but maintain similar dynamics and transformation process. This observation inspires us to regard two videos with the same VFX as a reference-target data pair for in-context learning."
- Rendering: Computing the final image or frames from a scene description, including lighting and shading. "including modeling, rigging, animation, rendering, and compositing~\cite{du2021diffpd}."
- Rigging: Building the skeletal structure and controls that enable animation of 3D models. "including modeling, rigging, animation, rendering, and compositing~\cite{du2021diffpd}."
- Spatial-temporal attention: Attention mechanism that jointly models spatial and temporal relationships in video tokens. "Thus, we only need to finetune the spatial-temporal attention to learn the VFX imitation process between these tokens..."
- T5 encoder: A text encoder from the T5 model family used to embed prompts for conditioning video generation. "which is built upon a 3D Variational Autoencoder (VAE)~\citep{kingma2013auto}, a Diffusion Transformer (DiT) architecture and the T5 encoder~\citep{raffel2020exploring}."
- Temporal coherence: Consistency of content and motion across frames in a generated video. "thereby improving temporal coherence and dynamics."
- Token finetuning: Parameter-efficient training that optimizes newly introduced tokens instead of full model weights. "With a low-cost token finetuning, the model can rapidly improve the generalization capability on tough OOD samples."
- Two-Alternative Forced Choice (2AFC): A psychophysics evaluation paradigm where participants choose between two options. "we conduct a user study following the Two-Alternative Forced Choice (2AFC) paradigm, a gold standard in psychophysics."
- VFX-Comprehensive Assessment Score (VFX-Cons.): A composite evaluation framework assessing occurrence, fidelity, and leakage of effects. "we introduce a new evaluation framework, the VFX-Comprehensive Assessment Score~(VFX-Cons.)."
- Visual LLM (VLM): A multimodal model that processes both visual and text inputs for evaluation or control. "VFX-Cons. leverages the reference video and prompts Visual LLM~(VLM)~\citep{comanici2025gemini} to evaluate visual effects quality..."
- Video-to-video editing: Transforming one video into another conditioned on various signals or masks. "integrates ID-to-video generation, video-to-video editing, and mask-based editing into a unified model."
- Zero convolutions: Convolution layers initialized to zero to safely inject control signals without affecting the base model initially. "connecting them with zero convolutions."
Collections
Sign up for free to add this paper to one or more collections.

