- The paper introduces the PIPE attack and demonstrates that defenses such as Facial-FE and MRP are highly vulnerable under full leakage, with attack success rates often exceeding 89%.
- The study employs formal threat modeling and empirical evaluations using metrics like ASR, LPIPS, and FID to rigorously assess the strengths and weaknesses of existing post-processing schemes.
- The proposed L2FE-Hash, a lattice-based fuzzy extractor, offers strong cryptographic security with practical authentication accuracy, setting a new standard for privacy-preserving ML systems.
Introduction and Motivation
This paper addresses the persistent vulnerability of ML systems to model inversion attacks, particularly in privacy-sensitive applications such as face authentication. Embedding vectors generated by deep models (e.g., Facenet, ArcFace) are commonly stored for authentication purposes. If these embeddings are leaked, adversaries can reconstruct the original input (e.g., face images) with high fidelity, posing severe privacy risks. The work formalizes the requirements for a robust, attack-agnostic defense and establishes a connection to the cryptographic primitive of fuzzy extractors, specifically in the context of Euclidean (ℓ2) distance comparators.
The paper considers a full-leakage threat model, analogous to password database breaches, where all persistently stored data—including protected embeddings and any auxiliary randomness—is compromised. The adversary is assumed to have black-box access to the target ML model and public datasets representative of the input distribution. The central challenge is to design a post-processing defense that:
- Tolerates noise (i.e., allows authentication with slightly different inputs),
- Remains secure even if all stored data is leaked,
- Preserves sufficient entropy for utility (i.e., avoids trivial compression).
Existing Post-Processing Defenses and Their Limitations
Two prominent post-processing schemes are analyzed:
- Facial-Fuzzy Extractor (Facial-FE): A lattice-based fuzzy extractor designed for approximate ℓ2 correction. It uses deterministic decoding, which leaks significant information about the original embedding via the helper string. This makes it vulnerable to inversion attacks.
- Multispace Random Projection (MRP): Projects embeddings onto a lower-dimensional random subspace. While non-invertible in theory, it is susceptible to approximate recovery when both the projection matrix and projected vector are leaked.
Empirical evaluation demonstrates that both schemes are highly vulnerable under full-leakage. Attack success rates (ASR) exceed 89% in most cases, indicating that these defenses do not provide cryptographically strong protection.
The PIPE Attack: Adaptive Model Inversion
The paper introduces the PIPE (Post-leakage Inversion of Protected Embeddings) attack, which exploits the weaknesses of existing post-processing schemes. PIPE operates in two stages:
- Surrogate Embedding Recovery: For Facial-FE, the helper string is used directly as a surrogate for the original embedding. For MRP, the Moore-Penrose pseudo-inverse of the projection matrix is used to recover an approximate embedding.
- Image Reconstruction: A diffusion model, conditioned on the surrogate embedding, is trained to reconstruct images close to the original input.
Empirical results show that PIPE achieves ASR above 89% for Facial-FE and above 47% for MRP, far exceeding random guessing baselines.
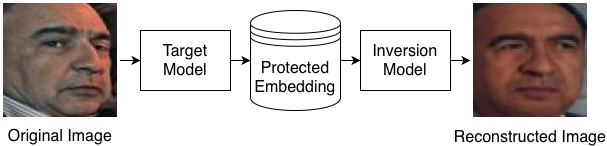
Figure 1: An example inverting the FacialFE-protected embedding vector to obtain a face image similar to the original using PIPE.
The paper formalizes the requirements for an ideal post-processing primitive, termed a fuzzy one-way hash (FOWH), which must satisfy:
- Correctness: Noise tolerance for authentication.
- Security: Fuzzy one-wayness—hardness of recovering any input close to the original, even with full leakage.
- Utility: Output entropy comparable to input entropy.
It is shown that a fuzzy extractor for ℓ2 distance satisfies these properties, provided the input distribution is well-behaved (e.g., high min-entropy, bounded support).
The paper proposes L2FE-Hash, a lattice-based fuzzy extractor supporting ℓ2 distance comparators. The construction uses random q-ary lattices and Babai's Nearest Plane (BNP) algorithm for error correction. The secret is hashed before storage, ensuring security under full leakage.
Theoretical analysis demonstrates that L2FE-Hash is computationally secure under the assumption that the input distribution is uniform over a union of disjoint ϵ-balls (representing user clusters). The number of secure output bits is a function of the input entropy and lattice parameters.
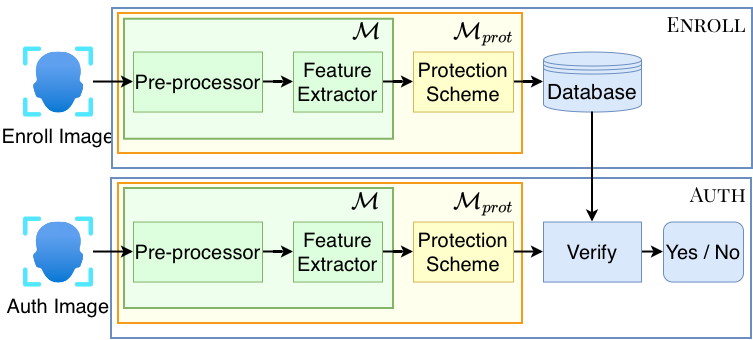
Figure 2: A face authentication system with Enroll and Auth functions. M represents models that output unprotected embeddings and Mprot represents models with post-processing protection mechanisms that output protected embeddings.
Empirical Evaluation of L2FE-Hash
L2FE-Hash is evaluated against PIPE and prior inversion attacks (Bob, KED-MI, GMI) using state-of-the-art face recognition models and multiple datasets (Celeb-A, LFW, CASIA-Webface). Key findings:
Comparative Analysis and Metrics
Visual similarity metrics (LPIPS, FID) confirm that PIPE reconstructions are perceptually close to originals for vulnerable schemes, but L2FE-Hash reconstructions are not, indicating effective privacy protection. Cross-model evaluation shows that PIPE reconstructions generalize across different feature extractors, underscoring the severity of the privacy risk.
Theoretical and Practical Implications
The work establishes that:
- Partial defenses (Facial-FE, MRP) are insufficient under realistic threat models.
- Fuzzy extractors, specifically L2FE-Hash, provide attack-agnostic, model-agnostic security for embedding-based authentication, without requiring model retraining.
- Security guarantees are formalized and empirically validated for real-world face distributions.
The approach generalizes to other modalities (audio, text) and security applications (copyright, CSAM detection) where embedding vectors are used.
Future Directions
Open problems include:
- Characterizing real-world input distributions to tighten theoretical security bounds.
- Extending fuzzy extractor constructions to other distance metrics and modalities.
- Optimizing authentication accuracy for practical deployment, possibly via ensemble methods or adaptive parameter tuning.
Conclusion
This paper provides a rigorous formalization and empirical validation of cryptographic fuzzy extractors as a defense against model inversion attacks in ML-based authentication systems. The proposed L2FE-Hash construction achieves strong security and practical utility, marking a significant advance in privacy-preserving ML system design. The results highlight the necessity of cryptographically principled post-processing defenses and set a foundation for future research in secure ML deployments.


