INT v.s. FP: A Comprehensive Study of Fine-Grained Low-bit Quantization Formats
Abstract: Modern AI hardware, such as Nvidia's Blackwell architecture, is increasingly embracing low-precision floating-point (FP) formats to handle the pervasive activation outliers in LLMs. Despite this industry trend, a unified comparison of FP and integer (INT) quantization across varying granularities has been missing, leaving algorithm and hardware co-design without clear guidance. This paper fills that gap by systematically investigating the trade-offs between FP and INT formats. We reveal a critical performance crossover: while FP excels in coarse-grained quantization, the comparison at fine-grained (block-wise) levels is more nuanced. Our comprehensive comparison demonstrates that for popular 8-bit fine-grained formats (e.g., MX with block size 32), MXINT8 is superior to its FP counterpart in both algorithmic accuracy and hardware efficiency. However, for 4-bit formats, FP (e.g., MXFP4, NVFP4) often holds an accuracy advantage , though we show that NVINT4 can surpass NVFP4 when outlier-mitigation techniques like Hadamard rotation are applied. We also introduce a symmetric clipping method that resolves gradient bias in fine-grained low-bit INT training, enabling nearly lossless performance for MXINT8 training. These findings challenge the current hardware trajectory, demonstrating that a one-size-fits-all FP approach is suboptimal and advocating that fine-grained INT formats, particularly MXINT8, offer a better balance of accuracy, power, and efficiency for future AI accelerators.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to make large AI models (like chatbots) run faster and use less memory by storing their numbers with fewer bits. It compares two ways to do this “low-bit quantization”:
- Floating point (FP): numbers with a sign, an exponent, and a mantissa (like scientific notation).
- Integer (INT): whole numbers scaled by a shared “volume knob” (a scale factor).
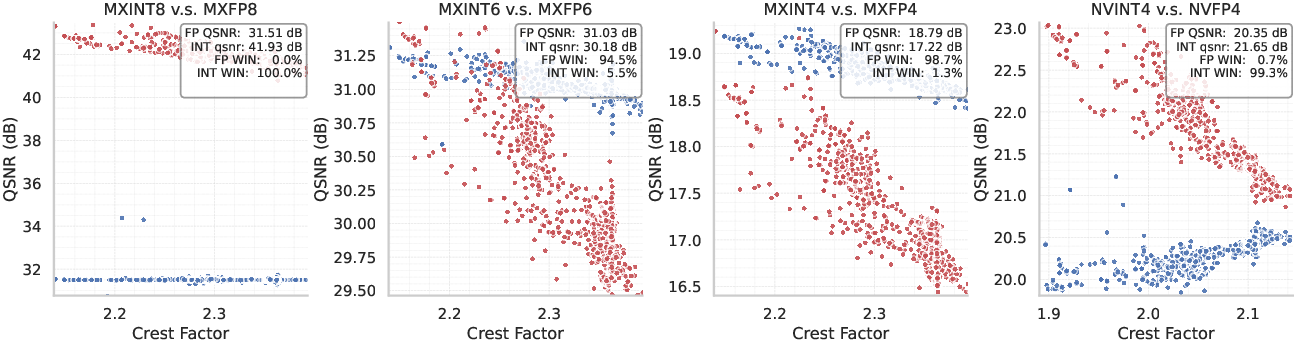
The big idea: while FP is often thought to be better (especially for handling rare, very large values called outliers), the paper shows that at a finer, more detailed level (small blocks of numbers), integers can actually work better—especially in 8-bit formats.
What questions did the researchers ask?
To make the comparison clear and fair, the paper asks simple, practical questions:
- When we quantize in larger groups (coarse) vs smaller groups (fine), which format—FP or INT—keeps the numbers more accurate?
- For different bit-widths (8-bit, 6-bit, 4-bit), which format performs best?
- Can we fix known problems in INT training (like a tiny bias in gradients) to make it as good as FP?
- Which format is cheaper for hardware (in area and energy) while keeping the same speed?
How did they study it?
They combined math, measurements, and experiments:
- Theory with QSNR: They built a model using “Quantization Signal-to-Noise Ratio” (QSNR). Think of QSNR like photo clarity: higher QSNR means the quantized version looks closer to the original. It helped predict when FP beats INT and when INT wins.
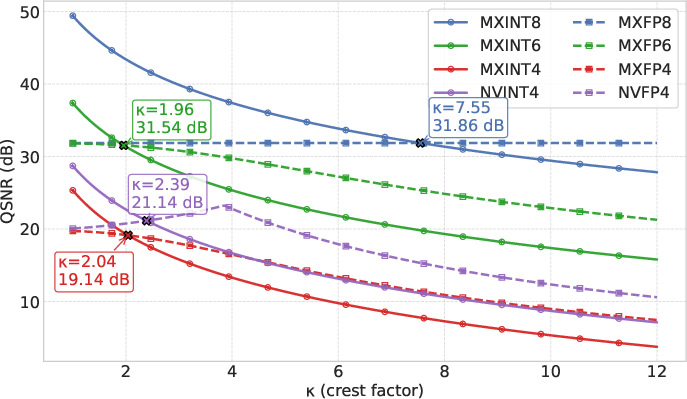
- Crest factor: They studied the “crest factor,” which is how big the biggest value is compared to the typical size in a group. Analogy: imagine one person in a class is extremely tall (an outlier); the crest factor measures how extreme that height is. Smaller blocks reduce crest factor because extreme values get grouped with fewer neighbors, making scaling more effective.
- Real tensors from LLMs: They captured data from 10,752 intermediate tensors inside a popular model (Llama-3.1-8B) during forward and backward passes to measure crest factors and QSNR in practice.
- Many models for inference: They tested 12 different LLMs (from small to huge) by quantizing only the forward pass to see how predictions shift compared to the original model.
- Training tests: They trained 1B and 3B-parameter models in 8 bits to check whether low-bit training can be “nearly lossless,” meaning results are almost the same as full precision.
- Hardware cost analysis: They estimated how much chip area and energy different formats would need at the same throughput (speed).
They also used two helpful tricks:
- Fine-grained block formats: Microscaling (MX) uses blocks of 32 values with a shared scale; NVIDIA’s NV uses blocks of 16 with a slightly different scaling scheme. Smaller blocks usually help accuracy.
- Hadamard rotation: A simple, fast math transform that “mixes” values to spread out outliers, making data more balanced for quantization.
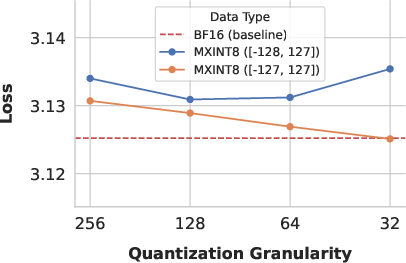
- Symmetric clipping for INT: A small fix to make the range of integers perfectly balanced around zero, removing a tiny negative bias that can hurt training.
What did they find, and why is it important?
Here are the key results and their meaning:
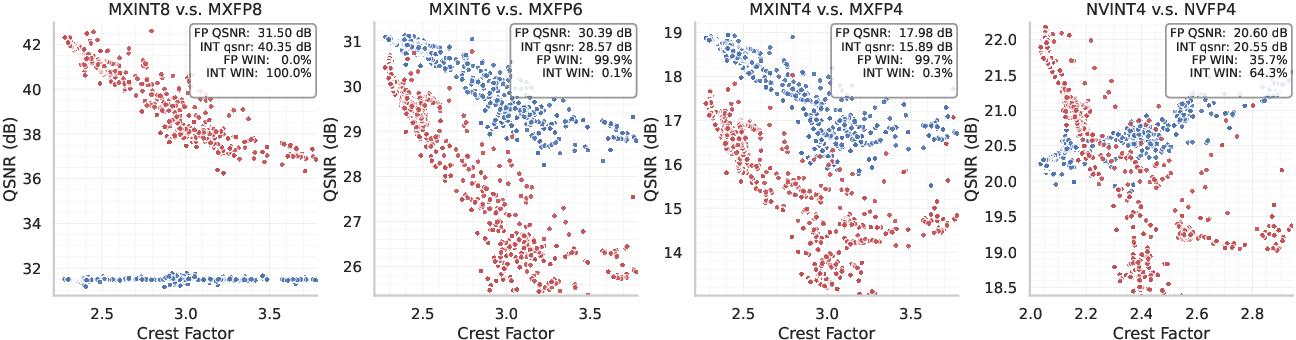
- INT8 beats FP8 at fine granularity: In popular 8-bit formats with small blocks (like MX, block size 32), MXINT8 consistently has better accuracy than MXFP8 and is more efficient on hardware. This is opposite to the common belief that FP8 is always best.
- FP often wins at 4 bits—but not always: For 4-bit formats, FP (MXFP4, NVFP4) usually has an accuracy edge. However, if you use Hadamard rotation to tame outliers, NVINT4 can outperform NVFP4.
- The “crossover” depends on crest factor: FP is stronger when the crest factor is high (lots of extreme outliers). As you use smaller blocks, the crest factor drops, making INT more competitive or even better. In other words, the best choice depends on how “spiky” your data is and how finely you quantize.
- Nearly lossless 8-bit training with INT: With the symmetric clipping fix, MXINT8 training matches or very slightly improves over MXFP8 and stays close to full precision (BF16). That means you can train in INT8 without sacrificing performance.
- Hardware efficiency: At the same speed, INT pipelines use less energy and chip area than FP pipelines. In their estimates, pairing MXINT8 + NVINT4 saves roughly 25% energy and 34% area compared to MXFP8 + NVFP4. That’s a big deal for future AI accelerators.
What does this mean for the future?
This paper challenges the trend of pushing only low-precision FP formats in new AI chips. It shows there isn’t a one-size-fits-all answer:
- For fine-grained 8-bit quantization, INT (especially MXINT8) is a great choice: accurate, power-efficient, and hardware-friendly.
- For 4-bit quantization, FP often wins—but with smart tricks like Hadamard rotation, INT can compete or win.
- Designers of AI algorithms and hardware should co-design together, picking formats based on data behavior (crest factor) and block size, not just defaulting to FP.
Bottom line: picking the right number format—and the right granularity—can make AI models faster, cheaper, and greener without hurting accuracy. This helps big models run better on real devices, from servers to edge hardware.
Knowledge Gaps
Below is a consolidated list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to be concrete and actionable for future research.
- Theoretical assumptions and validation
- The QSNR analysis assumes i.i.d. Gaussian block entries; it does not cover heavy-tailed or skewed activation distributions observed in LLMs. Quantify crossover sensitivity under non-Gaussian (e.g., Laplace, Student-t) and correlated distributions.
- The crest-factor modeling is tied to RMS and AbsMax scaling; provide sensitivity analysis when RMS is unstable (heavy tails) or for alternative scale estimators.
- The choice of UE8M0 scale overhead parameter ρ=1.5 is heuristic; measure and model ρ empirically across layers, models, and hardware implementations.
- Provide a mathematical proof or formal analysis that symmetric clipping removes gradient bias across training dynamics, including optimizer interactions and accumulation effects.
- Establish a quantitative mapping between tensor-level QSNR and end-task accuracy or KL divergence to predict model-level performance from QSNR, including confidence intervals.
- Quantization granularity and format space
- Explore block sizes beyond 16 and 32 (e.g., 8, 64, adaptive block sizes) and quantify how crossovers shift with granularity under realistic workloads.
- Investigate multi-level scaling for INT formats analogous to NVFP4’s two-level scales; determine whether multi-level INT scales can recoup dynamic range without FP overhead.
- Evaluate alternative scale estimators (percentile, L2/RMS, learned scales) within blocks for both INT and FP, and quantify their impact on crest factor and crossover points.
- Consider per-group or hybrid granularity schemes (e.g., per-channel + block) and derive crossover behavior in mixed-granularity pipelines.
- Study learned rotations and other outlier mitigation strategies (e.g., SmoothQuant, PrefixQuant, SpinQuant), not just random Hadamard rotation, and compare their efficacy for INT vs FP at 4-bit.
- Coverage of precisions and training regimes
- Extend training experiments beyond MXINT8/MXFP8 to 6-bit and 4-bit regimes (MXINT6/MXFP6, MXINT4/MXFP4, NVINT4/NVFP4), including assessing whether rotation or multi-level scales enable nearly-lossless training at lower bits.
- Validate MXINT8 training on larger models (≥8B, ≥70B) and longer training horizons, with multiple seeds, to assess stability, reproducibility, and generalization.
- Quantify the impact of symmetric clipping on 6-bit and 4-bit training, especially under two’s complement hardware constraints and subnormal handling.
- Evaluate full-pipeline low-bit training beyond GEMMs (attention softmax, layernorms, residual adds, activation functions), and quantify which non-GEMM ops become accuracy bottlenecks for INT.
- Investigate low-bit quantization of optimizer states and gradients (e.g., Adam moments) and the feasibility of integer formats for optimizer storage and updates.
- Inference evaluation breadth and metrics
- Expand inference evaluation beyond WikiText2 KL divergence to diverse benchmarks (reasoning, coding, multilingual, long-context) and open-ended generation metrics (toxicity, coherence, factuality).
- Report absolute task performance alongside ranking/KL metrics to contextualize practical impact; analyze cases where INT loses despite similar average QSNR due to worst-case layer effects.
- Quantify the end-to-end latency and throughput impact of rotations (e.g., Hadamard) in inference, including memory traffic and kernel fusion constraints.
- Tensor-wise and pipeline-level analyses
- Provide layer-wise breakdowns of crest factor and QSNR across different tensor types (X, W, dY, etc.) for multiple models, and identify systematic hotspots where FP retains advantages.
- Study axis choice interactions (quantizing along different GEMM reduction dimensions) and whether co-optimizing axes/scales across forward/backward reduces cumulative noise.
- Analyze accumulation and rounding modes (e.g., stochastic rounding, RNNE vs RNE) and their interaction with block scales, especially for INT accumulators in mixed-precision GEMMs.
- Hardware modeling and deployability
- The energy/area analysis excludes memory hierarchy and data movement (DRAM, HBM, SRAM, interconnect); incorporate these costs, including scale-fetch/storage and rotation overhead.
- Validate area/energy projections with synthesis or reference designs; include costs for subnormal detection/handling in FP, symmetric clipping logic in INT, and two-level scaling control.
- Assess scheduling and ISA implications of INT formats (e.g., scale reuse, pipeline hazards) and propose concrete microarchitectural designs for MXINT8/NVINT4 support.
- Quantify the throughput and energy impact of integrating rotation in hardware (approximate/learned rotations, precomputed Hadamard tables), including on-chip memory and routing overhead.
- Compare end-to-end system-level efficiency under realistic batching, KV-cache management, and long-context inference, not just per-MMU arithmetic costs.
- Scope and generality across models and tasks
- Extend tensor-wise crest factor/QSNR measurements beyond Llama-3.1-8B to MoE models (where gating can induce outliers), vision-LLMs, and RNN-free non-Transformer architectures.
- Analyze how MoE routing and expert heterogeneity affect crest factors and whether INT crossovers vary per expert or routing stage.
- Study sequence-length and prompt-dependent variability in crest factors; determine whether adaptive granularity or rotation policies per sequence/time-step improve INT performance.
- Scale computation and quantizer design
- Compare rounding-up UE8M0 scale to alternative rounding policies (round-to-nearest, stochastic rounding) and quantify their effect on clipping, subnormal rates, and QSNR.
- Explore INT formats with microexponents or logarithmic quantization to combine INT hardware efficiency with improved dynamic range; derive QSNR and hardware trade-offs.
- Investigate quantizer calibration strategies (e.g., per-layer learned scales, temperature scaling for logits) that minimize worst-case block crest factors without rotation.
- Robustness, reliability, and safety
- Examine robustness of INT vs FP under distribution shifts, adversarial perturbations, and noisy inputs; test whether INT formats exacerbate rare catastrophic errors.
- Evaluate the impact of quantization on safety metrics (toxicity, bias) and whether INT/FP differences change safety profiles in deployment.
- Reproducibility and open-sourcing
- Provide complete details of the hardware cost model (parameters, circuit assumptions) and release scripts to reproduce energy/area estimates under varying throughput/precision mixes.
- Release comprehensive per-model inference results (not only summaries), including layer-wise QSNR/crest factors and failure cases to facilitate community benchmarking.
Practical Applications
Immediate Applications
The following are practical, deployable use cases that leverage the paper’s findings in current systems and workflows. Each bullet includes the relevant sector(s), potential tools/products/workflows, and key assumptions or dependencies.
- LLM inference stacks: switch FP8 to MXINT8 at block size 32
- Sectors: software, cloud/AI platforms, energy, finance
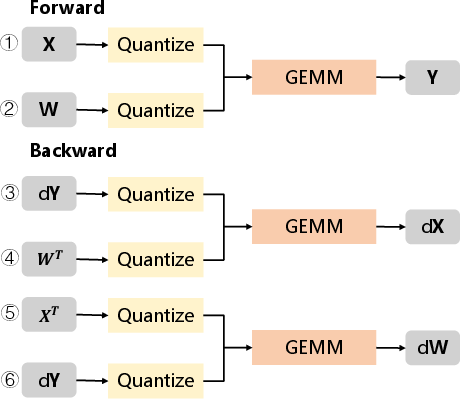
- What to do: replace MXFP8 with MXINT8 for block-wise quantization (k=32) in GEMM kernels; apply UE8M0 scale rounding-up; use symmetric integer clipping to avoid gradient bias where applicable; adopt KL-divergence monitoring for behavioral stability
- Tools/workflows: TensorRT quantized types; PyTorch/Triton kernels; serving frameworks (vLLM, TGI) with MXINT8 backends; the paper’s code repo for recipes
- Benefits: higher accuracy vs FP8 in direct-cast inference; area/energy savings (~37% energy reduction vs MXFP8 at matched throughput); reduced serving costs and carbon footprint
- Assumptions/dependencies: hardware/compilers support MX formats or custom kernels; AbsMax scaling available; model tensors align with k=32 block quantization; crest factors similar to tested LLMs
- On Blackwell-class GPUs, deploy NVINT4 with Hadamard rotation for 4-bit inference
- Sectors: software, cloud/AI platforms, mobile/edge
- What to do: integrate random Hadamard rotation (block size 16) into pre-GEMM activation/weight paths; quantize to NVINT4 with E4M3 scale and per-tensor scale; use crest-factor monitoring to gate rotation
- Tools/workflows: TensorRT/NVIDIA APIs; fused Hadamard-GEMM kernels; runtime toggle based on crest-factor thresholds
- Benefits: NVINT4 can surpass NVFP4 accuracy post-rotation; better energy/area efficiency than FP4 at matched throughput
- Assumptions/dependencies: rotation overhead fits latency budgets; dimensions permit block-size alignment; crest-factor reduction observed on target models
- Nearly lossless training with MXINT8 as a drop-in alternative to FP8
- Sectors: software, education, healthcare (privacy-preserving fine-tuning), robotics
- What to do: adopt MXINT8 for forward and backward GEMMs; use symmetric clipping to remove INT8 gradient bias; keep scales in UE8M0 with rounding-up; follow paper’s training recipe for 1B–3B models
- Tools/workflows: PyTorch FP8 pipelines adapted to MXINT8; quantization-aware training recipes; evaluation with lm_eval and loss monitoring
- Benefits: training loss and task accuracy match BF16 and FP8; slight loss improvements (~0.001) vs FP8; reduced training power/cost
- Assumptions/dependencies: tested on 1B/3B Llama-style models; larger scales likely but require validation; kernel support for low-bit training path
- Crest-factor–aware quantization selection in serving pipelines
- Sectors: software, cloud/AI platforms
- What to do: measure per-layer crest factor at runtime or during calibration; auto-select formats: MXINT8 for block-32; NVINT4+rotation when crest factor permits; fall back to FP for high crest-factor tensors
- Tools/workflows: a “Quantization Selector” module using QSNR-based heuristics; layer-wise profilings; deployment config generator
- Benefits: maximizes accuracy and efficiency adaptively; reduces worst-case behavior under high crest factors
- Assumptions/dependencies: lightweight crest-factor estimation; deterministic behavior under format switching; kernel availability for all formats
- Cost and energy optimization for AI model hosting
- Sectors: finance, energy, cloud/AI platforms, policy
- What to do: migrate FP-centric services to INT-first where feasible (MXINT8/NVINT4+rotation); update cost calculators and SLOs; track energy savings and carbon metrics in dashboards
- Tools/workflows: TCO models incorporating area/energy reductions from the paper; energy telemetry integrated into MLPerf-like benchmarks; procurement playbooks
- Benefits: lower operational expenditure and improved sustainability reporting
- Assumptions/dependencies: energy/area figures are model-based; actual gains depend on hardware implementation quality
- On-device LLMs and edge AI upgrades
- Sectors: mobile/edge, consumer electronics, healthcare
- What to do: Quantize assistants to MXINT8 (k=32) for smartphones, AR/VR headsets, and IoT; use NVINT4+rotation when memory is tight; preserve privacy with on-device inference
- Tools/workflows: mobile NN libraries with INT8/NVINT4 kernels; edge runtimes with crest-factor profiling
- Benefits: lower latency, longer battery life, and improved offline capabilities
- Assumptions/dependencies: device supports low-bit accelerations; memory layout and block size constraints met
- Robotics and real-time systems
- Sectors: robotics, manufacturing, autonomous systems
- What to do: quantize language/planning modules to MXINT8; use crest-factor monitoring to maintain control accuracy; optionally integrate NVINT4+rotation for ultra-low-power platforms
- Tools/workflows: ROS2 modules with INT kernels; real-time profiling; safety validation via KL divergence and task metrics
- Benefits: improved throughput and energy efficiency without accuracy degradation
- Assumptions/dependencies: predictable crest-factor profiles; safety envelopes for quantized behavior
- Academic reproducibility and benchmarking
- Sectors: academia
- What to do: adopt the QSNR framework to compare formats; share crest-factor distributions for new model families; publish format-selection ablation studies; integrate symmetric clipping in training baselines
- Tools/workflows: open-source repo; curriculum material for low-bit quantization; reproducible notebooks
- Benefits: standardized, theory-grounded comparisons; faster iteration on quantization research
- Assumptions/dependencies: community consensus on QSNR/crest-factor reporting; availability of datasets/models
- Policy-aligned “Green AI” deployments
- Sectors: policy, public sector, energy
- What to do: include INT-first quantization strategies in energy-efficiency programs and AI procurement guidelines; require energy and KL-stability reporting for public AI services
- Tools/workflows: benchmark protocols that track energy vs accuracy; compliance templates
- Benefits: direct alignment with sustainability and responsible AI goals
- Assumptions/dependencies: policy bodies accept QSNR/KL metrics; transparent access to telemetry
Long-Term Applications
These applications likely require further research, scaling, hardware support, or standardization before broad deployment.
- INT-first accelerator designs with mixed-format pipelines
- Sectors: hardware/semiconductors, energy
- What to build: MMUs prioritizing MXINT8 and NVINT4 with shared integer datapaths; fused Hadamard rotation units; efficient scale handling (UE8M0/E4M3)
- Benefits: modeled area/energy gains (e.g., 34% area reduction for mixed-format INT vs FP at matched throughput)
- Dependencies: ASIC design and verification; co-optimization of memory hierarchy; vendor support and software toolchains
- Adaptive per-tensor format switching at runtime
- Sectors: software, cloud/AI platforms
- What to build: compilers/runtimes that measure crest factor online and switch among MXINT8, NVINT4+rotation, and FP formats per kernel
- Benefits: closes performance/accuracy gaps under nonstationary workloads
- Dependencies: robust heuristics; low overhead measurements; correctness guarantees and reproducible behavior
- Standardization of symmetric integer ranges and block-scale specifications
- Sectors: industry consortia, standards
- What to build: OCP/MLPerf profiles that mandate symmetric clipping for INT training; block size and scale semantics (UE8M0 rounding-up, E4M3 rules)
- Benefits: reduces gradient bias and fragmentation across toolchains
- Dependencies: multi-vendor alignment; updates to documentation and compliance tests
- Hardware-level crest-factor reduction modules
- Sectors: hardware/semiconductors
- What to build: lightweight transform blocks (e.g., Hadamard) that interleave with GEMM to suppress outliers on demand
- Benefits: unlocks NVINT4 accuracy consistently without large software overhead
- Dependencies: careful latency/area trade-offs; fusion with memory and scheduling
- Fully INT8 training pipelines at scale (10B–100B+ models)
- Sectors: software, cloud/AI platforms
- What to build: end-to-end training toolchains using MXINT8 for forward/backward, with symmetric clipping and crest-factor-aware scheduling; extend optimizer/activation handling
- Benefits: training cost and energy reductions without loss of accuracy
- Dependencies: validation on larger models and diverse architectures; optimizer stability; improved kernel coverage
- Edge/SoC architectures optimized for fine-grained INT formats
- Sectors: mobile/edge, consumer electronics
- What to build: smartphone/AR/IoT SoCs with native block-32 MXINT8 and block-16 NVINT4 support, including transform units and scale caches
- Benefits: robust on-device AI with low power
- Dependencies: silicon roadmaps; OS/runtime integration; developer ecosystem support
- Compiler autotuning for quantization (crest-factor–aware scheduling)
- Sectors: software
- What to build: ML compilers that co-optimize tiling, layout, and quantization format per layer based on QSNR predictions and empirical crest-factor profiles
- Benefits: better end-to-end latency/accuracy trade-offs
- Dependencies: accurate cost models; large-scale benchmarking
- Green AI policy frameworks tied to quantization efficiency
- Sectors: policy, public sector, energy
- What to build: incentives/carbon credits for INT-first deployments; standardized reporting (energy, KL stability, QSNR) for public AI procurement
- Benefits: pushes market toward efficient formats
- Dependencies: consensus on metrics; third-party auditing; interoperability across vendors
- Safety/robustness audits for quantized models
- Sectors: safety, compliance
- What to build: audit suites that track distributional shifts (KL divergence), task robustness, and failure cases introduced by format choices; guardrails for format switching
- Benefits: mitigates behavioral risks from aggressive quantization
- Dependencies: standardized tests; clear thresholds; access to operational telemetry
- Cross-domain extension beyond LLMs
- Sectors: vision, speech, multimodal, robotics
- What to build: apply crest-factor/QSNR framework to CNNs/ViTs, ASR/TTS, and multimodal models; evaluate where INT8/INT4 with rotation beats FP at fine granularity
- Benefits: broader adoption of efficient quantization strategies
- Dependencies: domain-specific crest-factor characteristics; kernel/library support
Key Assumptions and Dependencies (applies across items)
- Hardware/software support for MX and NV block formats, and availability of efficient kernels.
- Crest-factor profiles of target models resemble those measured for contemporary LLMs; different distributions may shift the FP–INT crossover points.
- Hadamard rotation overhead is acceptable for latency/SLA constraints and dimensionally compatible (block sizes 16/32).
- Energy/area gains are based on modeled hardware; realized benefits depend on specific implementations and manufacturing nodes.
- Training results (nearly lossless MXINT8) are validated for 1B–3B Llama-style models; larger scales and diverse architectures need further confirmation.
- Quantization pipeline relies on AbsMax scaling; deviations in data distributions or alternative scaling methods may require recalibration.
Glossary
BFloat16: A 16-bit floating-point format that provides wider dynamic range than IEEE 754 single precision but with reduced precision. "We compute all accuracies with lm_eval through 5-shot evaluation."
Crest Factor (): The ratio of the peak of the signal to its RMS value, which affects quantization error. "We consider block vectors with i.i.d. entries . The block root-mean-square (RMS) equals , and the crest factor is ."
E4M3: A floating-point format having 4 exponent bits and 3 mantissa bits. "MXFP8 consistently outperforms its FP counterpart in both accuracy and hardware efficiency."
Gradient Bias: An ongoing deviation in gradient computation, often caused by asymmetric data representation in low-bit integer formats. "Symmetric Clipping method resolves a gradient bias, enabling nearly lossless MXINT8 low-bit training."
Hadamard Rotation: A mathematical technique used to suppress outliers in data distributions. "We demonstrate that NVINT4 can surpass NVFP4 when combined with Hadamard rotation."
INT8: An 8-bit integer format used for quantization in neural networks to achieve efficient computation. "MXINT8 consistently outperforms MXFP8 in direct-cast inference and low-bit training."
Lossless Performance: A situation where the quantized model retains almost the same performance as the high-precision model. "Enabling nearly lossless performance for MXINT8 training."
Low-Bit Quantization: The process of converting high-bit precision to lower-bit precision to reduce computational demands. "Quantization maps a high-precision tensor to a lower bit-width."
Low-Precision Floating-Point Formats: Floating-point formats with reduced precision to optimize for hardware efficiency in AI computations. "FP8 and FP4 formats are increasingly embraced by modern AI hardware."
Microscaling (MX) Format: A quantization format that uses a shared scale factor for blocks of elements to improve low-bit accuracy. "Microscaling (MX) format uses a shared UE8M0 scale for each block of 32 elements."
Outlier-Mitigation Techniques: Strategies used to address significant deviations in data distributions that can impact model performance. "We show that NVINT4 can surpass NVFP4 when outlier-mitigation techniques like Hadamard rotation are applied."
QSNR (Quantization Signal-to-Noise Ratio): A metric for measuring the fidelity of quantization by comparing signal power to noise power. "A theoretical framework that models the quantization signal-to-noise ratio (QSNR) for both INT and FP formats."
Symmetric Clipping: A method to ensure symmetry in the representation of integer values during quantization to avoid bias. "We use a symmetric integer range for all INT quantizers as shown in Table 1."
UE8M0: An 8-bit unsigned floating-point format with eight exponent bits and zero mantissa bits. "OCP proposes the Microscaling (MX) format, which uses a shared UE8M0 scale for each block."
NVFP4: NVidia's 4-bit floating-point format which reduces block size to improve performance and accuracy. "NVIDIA proposes NVFP4, which enhances MXFP4 by reducing the block size from 32 to 16."
Block- Quantization: Partitioning a tensor into blocks, assigning a scale to each, to increase precision and reduce quantization error. "Block quantization is a key technique for improving accuracy at low precision."
Collections
Sign up for free to add this paper to one or more collections.