Instance-Level Composed Image Retrieval
Abstract: The progress of composed image retrieval (CIR), a popular research direction in image retrieval, where a combined visual and textual query is used, is held back by the absence of high-quality training and evaluation data. We introduce a new evaluation dataset, i-CIR, which, unlike existing datasets, focuses on an instance-level class definition. The goal is to retrieve images that contain the same particular object as the visual query, presented under a variety of modifications defined by textual queries. Its design and curation process keep the dataset compact to facilitate future research, while maintaining its challenge-comparable to retrieval among more than 40M random distractors-through a semi-automated selection of hard negatives. To overcome the challenge of obtaining clean, diverse, and suitable training data, we leverage pre-trained vision-and-LLMs (VLMs) in a training-free approach called BASIC. The method separately estimates query-image-to-image and query-text-to-image similarities, performing late fusion to upweight images that satisfy both queries, while down-weighting those that exhibit high similarity with only one of the two. Each individual similarity is further improved by a set of components that are simple and intuitive. BASIC sets a new state of the art on i-CIR but also on existing CIR datasets that follow a semantic-level class definition. Project page: https://vrg.fel.cvut.cz/icir/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes notable contributions but leaves several concrete issues unresolved that future work can address:
- [Dataset] Lack of a global, shared retrieval index: evaluation uses a separate database per instance, avoiding cross-instance distractors and not reflecting real-world, single-pool retrieval at scale. An open need is a unified benchmark where all instances share one large index to measure cross-instance confusion and scalability.
- [Dataset] Potential CLIP-induced curation bias: hard negatives and candidate pools are mined with CLIP, which can bias the dataset toward CLIP’s embedding geometry and failure modes. It remains unclear how methods not aligned with CLIP are affected. A CLIP-agnostic negative-mining pipeline and bias analysis are needed.
- [Dataset] Limited modification diversity per instance: each instance has only 1–5 text modifications (median 2), constraining linguistic and compositional variety. There is a gap in broader, fine-grained, and combinatorial modifications (e.g., multi-step edits, relational constraints, negations like “without people,” spatial constraints), and measuring performance under such richer queries.
- [Dataset] Ambiguity and consistency of “same instance” labeling: the paper provides no inter-annotator agreement, adjudication protocol, or ambiguity analysis—especially for fictional characters or mass-produced products where “visually indistinguishable” is subjective. A formal definition, annotation guidelines, and reliability studies are missing.
- [Dataset] False-negative risk from “unmarked = negative”: unselected images in the candidate pool are treated as negatives, which risks missing positives (or near-positives) and inflating precision. Quantifying and reducing residual false negatives is an open task.
- [Dataset] Generalization beyond LAION: all images come from LAION, which is known to carry sampling, geographic, and content biases. The dataset’s representativeness, fairness, and robustness beyond LAION are not assessed. Cross-source validation and bias audits are needed.
- [Dataset] Minimal coverage analysis: while the paper lists broad categories (landmarks, products, fictional, etc.), it lacks a principled analysis of category balance, geographic/cultural diversity, and long-tail coverage. Guidance on expansion to underrepresented instances and contexts is missing.
- [Dataset] Overlap and leakage across instances: with per-instance databases, it is unclear whether near-duplicate images or visually indistinguishable depictions of different instances appear across separate indices and how this would impact evaluation in a shared index.
- [Dataset] Claim of challenge comparable to 20–40M distractors is not fully specified for reproducibility (e.g., which distractors, how difficulty is calibrated). Standardized large-scale distractor sets and replication protocols are needed to validate this claim.
- [Dataset] Reproducibility details of data release: the paper does not specify whether LAION IDs, selection scripts, annotation schemas, and seed queries/corpora are released. Without these, exact reproduction, extension, or auditing of the dataset is difficult.
- [Evaluation] Single metric focus (macro-mAP): no reporting of top-k metrics (e.g., Recall@k), per-negative-type error rates (visual vs textual vs composed), or calibration/uncertainty metrics. A deeper diagnostic evaluation suite is needed to pinpoint failure modes.
- [Evaluation] No multilingual assessment: queries and corpora appear to be English-only; the dataset and method’s cross-lingual generalization is untested. A multilingual benchmark split and evaluation protocols would enable broader applicability.
- [Training] No standardized training split for instance-level CIR: while the dataset serves evaluation, many methods rely on training triplets. The lack of a high-quality, instance-level training set (or protocol for building one) continues to hinder learning-based approaches.
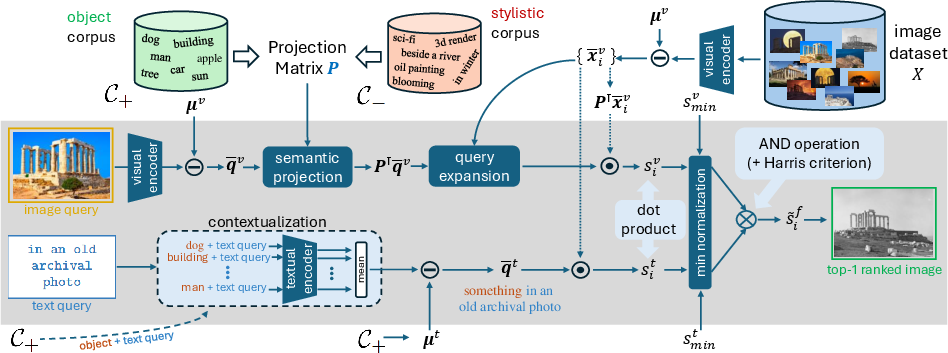
- [Method: FreeDom] Sensitivity to automatically generated corpora (C+ and C−): object/style corpora are produced via ChatGPT; the impact of corpus quality, size, and domain match on performance is unquantified. Guidance on constructing robust, domain-adaptive corpora is missing.
- [Method: FreeDom] Dependence on synthetic data for score normalization: min-based normalization uses statistics from prompts/images generated by Stable Diffusion. The sensitivity of results to the choice of generator, prompt distribution, and domain gap is not analyzed.
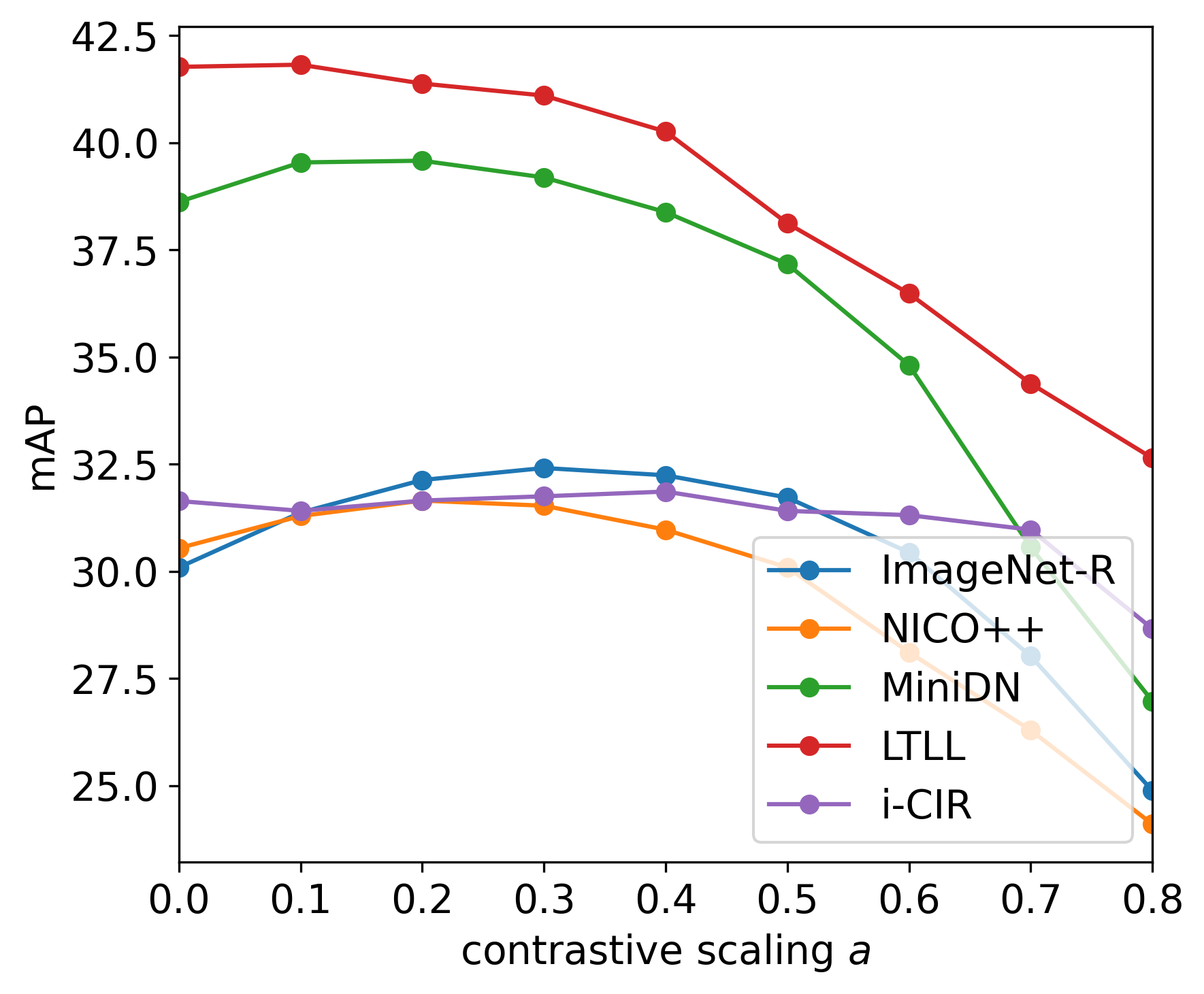
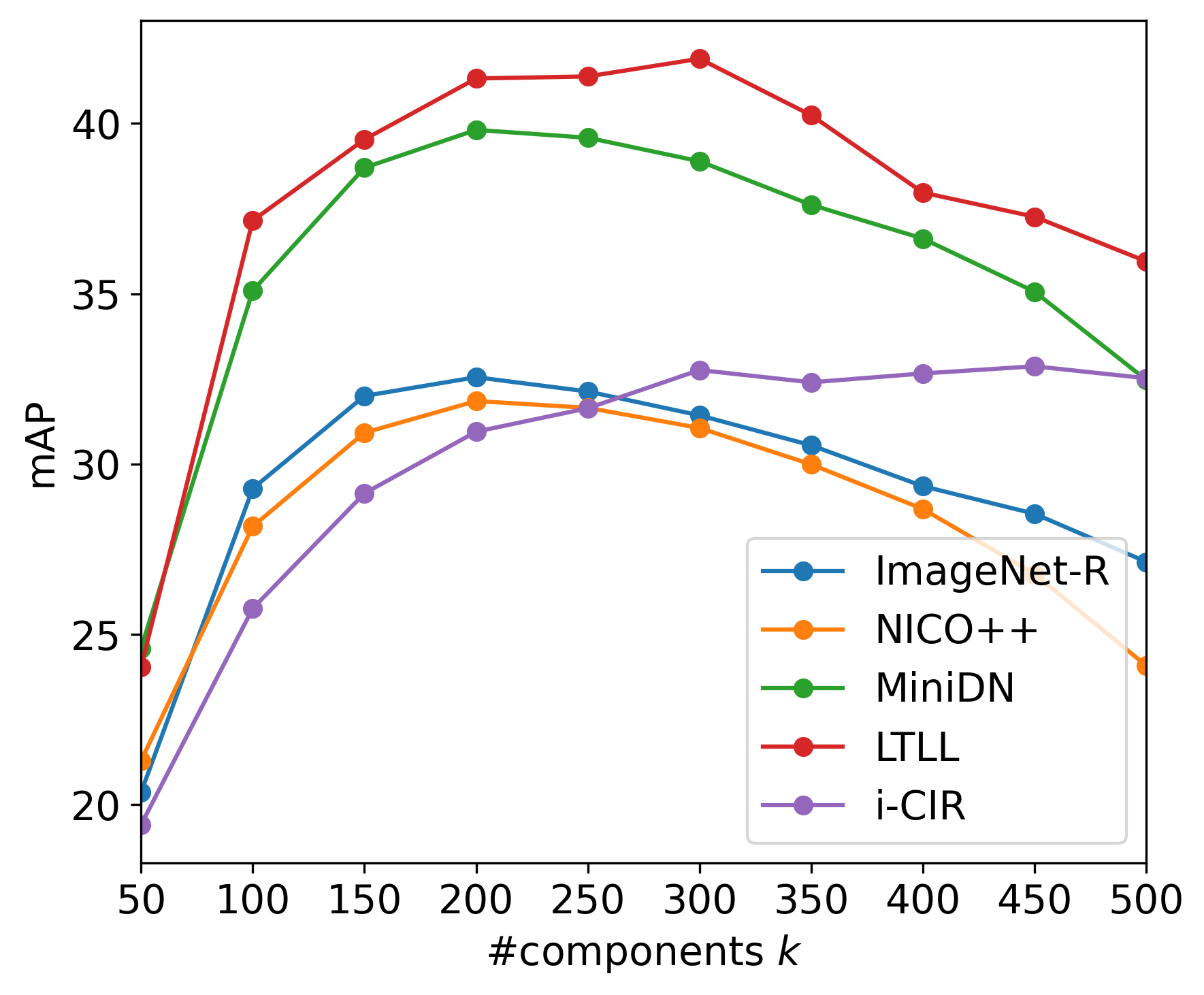
- [Method: FreeDom] Projection design choices are underexplored: the effect of projection dimensionality k, contrastive weighting α, corpus composition, and alternative subspace estimation methods (e.g., supervised or self-supervised directions) is not systematically studied.
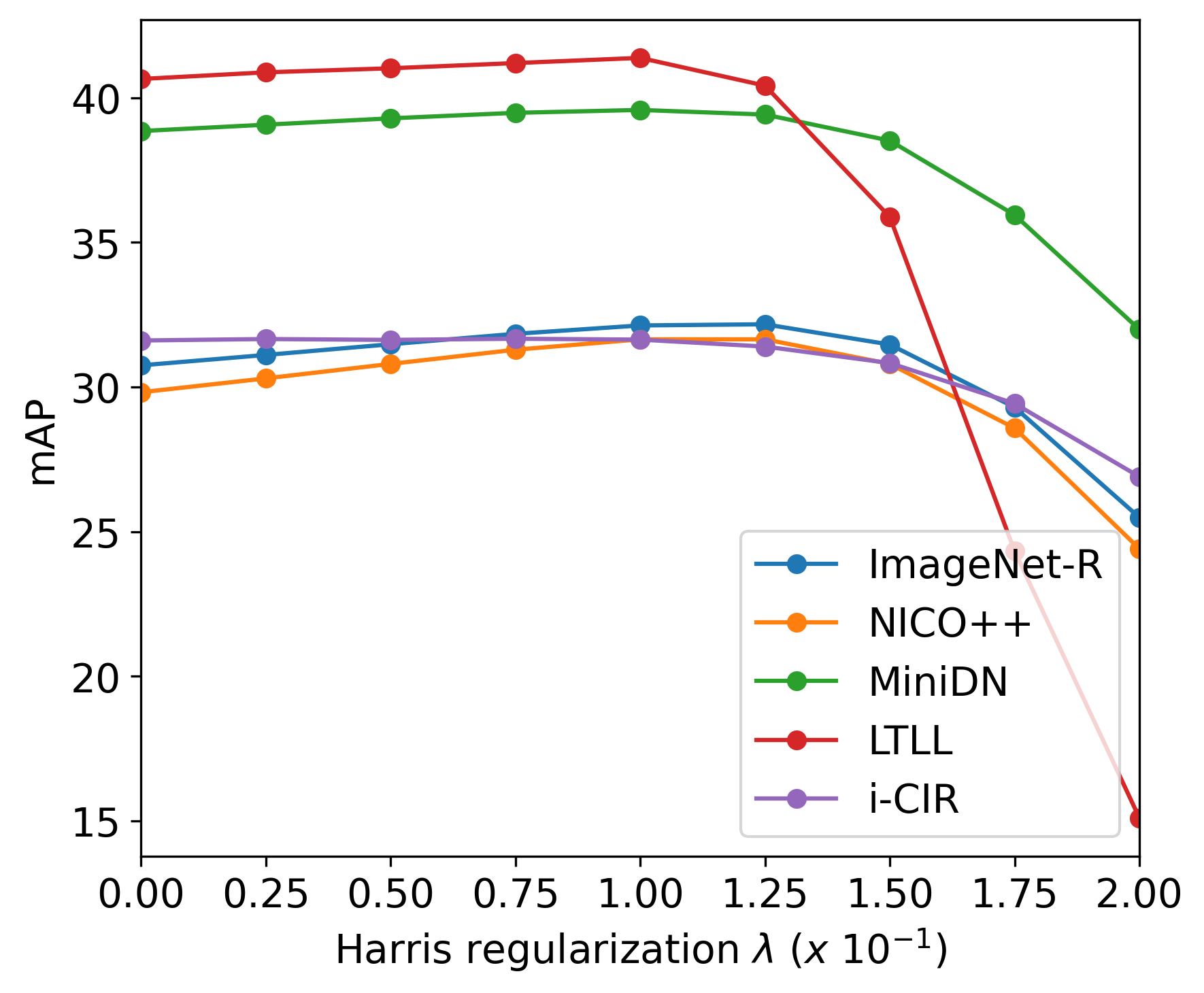
- [Method: FreeDom] Fixed fusion with a Harris-like penalty: the multiplicative fusion and fixed λ may be suboptimal across queries or datasets. There is no adaptive or learned fusion mechanism, nor an analysis of per-query modality dominance detection and calibration.
- [Method: FreeDom] Query expansion harms instance-level CIR in this dataset; yet no alternative expansion or feedback strategies (e.g., modality-aware, modification-aware, or pseudo-relevance feedback for text) are explored to recover benefits without introducing drift.
- [Method: FreeDom] Limited modeling of text–image interactions: the approach uses independent similarities and late fusion, which may miss fine-grained cross-modal interactions that cross-attention or composition-specific encoders can capture. Exploring lightweight, training-free interaction mechanisms remains open.
- [Method: FreeDom] Robustness and OOD behavior: the method and dataset avoid implausible modifications. Generalization to rare/novel or contradictory edits, hard negations, compositional chains (multi-step text edits), and adversarial phrasing is not evaluated.
- [Method: FreeDom] Model generality across VLMs is untested: results are primarily with CLIP ViT-L/14; it is unknown how FreeDom transfers to other VLMs (e.g., SigLIP, BLIP2, ALIGN) and whether components (centering, projection, normalization) require re-tuning.
- [Scalability] Large-scale runtime and memory at web scale: while the paper argues linear/sub-linear complexity and refers to FAISS, there is no empirical evaluation on truly massive indices (>100M) or analysis of latency/throughput trade-offs when applying query-time projection/contextualization.
- [User personalization] The paper notes projection can be applied on the query side to enable customization but provides no studies on user- or domain-specific priors, learned or rule-based personalization, or mechanisms to adapt projections on-the-fly.
- [Ethics and safety] No discussion of privacy, copyright, or sensitive content in LAION-derived images; nor of fairness across demographics and cultures in instance selection and modifications. Ethical guidelines and audits are absent.
- [Benchmark extensibility] No protocol for adding new instances, new modification types, or cross-modal tasks (e.g., video or multi-image queries), and how to maintain comparability over time. A clear governance and versioning plan is missing.
Collections
Sign up for free to add this paper to one or more collections.