- The paper presents GraphFLA, a Python framework that integrates 20 biologically relevant landscape features into fitness prediction benchmarks.
- It leverages graph-based representation to analyze mutagenesis data, revealing strong correlations between landscape topography and model performance.
- Empirical validation on millions of sequences confirms GraphFLA’s scalability and robustness in diverse combinatorial biological landscapes.
Augmenting Biological Fitness Prediction Benchmarks with Landscape Features from GraphFLA
Introduction and Motivation
The paper introduces GraphFLA, a Python framework designed to construct and analyze biological fitness landscapes from mutagenesis data across DNA, RNA, protein, and other modalities. The central motivation is the lack of topographical information in existing fitness prediction benchmarks, such as ProteinGym and RNAGym, which impedes granular interpretation and comparison of model performance. While these benchmarks provide large-scale empirical data, they typically lack features that characterize the underlying landscape topography—ruggedness, navigability, epistasis, and neutrality—resulting in reliance on averaged scores and limited biological insight.
GraphFLA addresses this gap by providing a comprehensive suite of 20 biologically relevant features, enabling landscape-aware benchmarking and interpretation of fitness prediction models. The framework is optimized for scalability, handling datasets with millions of mutants, and is interoperable with standard ML data formats.
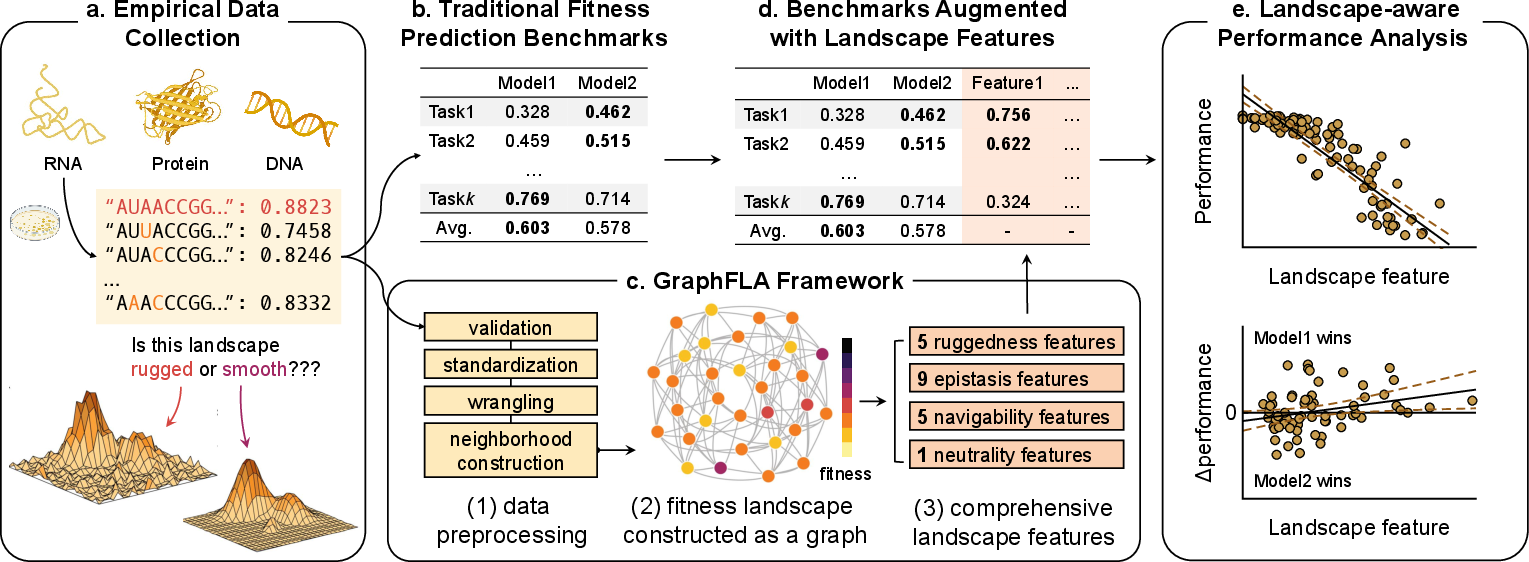
Figure 1: Overview of how GraphFLA augments fitness prediction benchmarks with landscape features, enabling performance interpretation and comparison.
Framework Architecture and Feature Set
GraphFLA consists of three main modules: data preprocessing, landscape construction, and landscape analysis. The input is a set of biological sequences and their fitness values, supporting arbitrary alphabets and modalities. The neighborhood structure is determined efficiently by direct generation of single-mutant neighbors, achieving near-linear complexity and outperforming existing implementations in both runtime and memory usage.
Landscapes are represented as directed graphs, where nodes are variants and edges encode mutational steps toward higher fitness. This graph-based abstraction enables efficient computation of landscape features using graph mining algorithms.
The feature set was curated via a data-driven literature survey of 1,673 papers, distilled to 20 essential features covering four topographical aspects:
- Ruggedness: Fraction of local optima, roughness-slope ratio, autocorrelation, gamma statistic, neighbor-fitness correlation.
- Epistasis: Magnitude, sign, reciprocal sign, positive, negative, global idiosyncratic index, diminishing return, increasing cost, pairwise epistasis.
- Navigability: Fitness-distance correlation, global optima accessibility, basin-fitness correlation (accessible/greedy), evolvability-enhancing mutation.
- Neutrality: Landscape neutrality.
This feature set enables quantitative characterization of landscape complexity and evolutionary constraints.
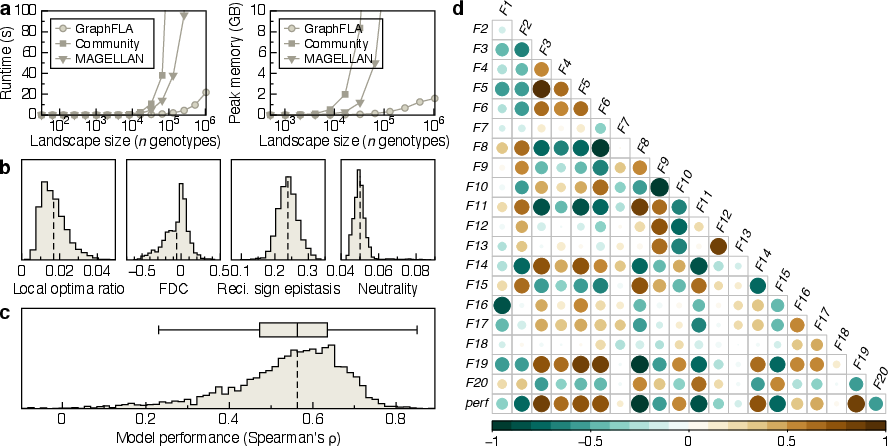
Figure 2: GraphFLA demonstrates superior scalability in runtime and memory usage compared to MAGELLAN and community implementations, and captures influential landscape features for model performance.
Empirical Validation and Robustness
GraphFLA was validated on 155 combinatorially complete empirical landscapes (over 2.2 million sequences) and 5,300+ landscapes from ProteinGym, RNAGym, and CIS-BP. The framework replicated published landscape metrics and qualitative findings across 61 studies, confirming reliability.
Robustness experiments on synthetic NK landscapes demonstrated that most key features are stable under missing data, experimental noise, and biased sampling. Notably, global optima accessibility decreases predictably with missing data, but other features remain consistent, supporting reliable approximation of landscape topography in realistic settings.
Analysis across thousands of empirical landscapes revealed that model performance is strongly dependent on landscape topography. For example, Evo2-7b's fitness prediction accuracy (Spearman's ρ) is highly correlated with ruggedness, epistasis, navigability, and neutrality features. Landscapes that are more rugged, epistatic, and neutral, and less navigable, are systematically harder for models to predict.

Figure 3: Model performance (Spearman's ρ) plotted against landscape features for combinatorial, ProteinGym, and RNAGym landscapes, with regression fits and confidence intervals.
Visualization of model performance in feature space (CIS-BP dataset) shows that certain regions—characterized by high local optima and reciprocal sign epistasis—are consistently challenging for prediction, while benign regions yield higher accuracy.

Figure 4: Distribution of Evo2-7b performance across 5,016 CIS-BP landscapes in landscape feature space.
Landscape-aware Model Comparison
GraphFLA enables systematic comparison of models beyond averaged scores. For instance, VenusREM and ProSST (k=2,048) exhibit similar overall performance on ProteinGym, but their relative advantage shifts with landscape features. ProSST outperforms VenusREM on landscapes with low reciprocal sign epistasis, while VenusREM excels as epistasis increases. Supervised models like Kermut outperform zero-shot models on less navigable landscapes, highlighting the necessity of supervised training for complex topographies.
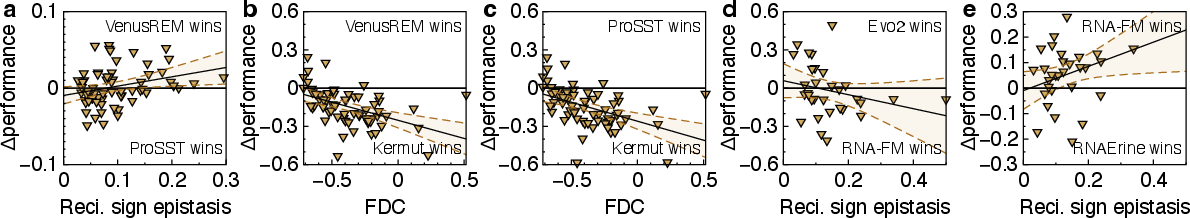
Figure 5: Performance differences between model pairs plotted against landscape features, revealing landscape-dependent model advantages.
Similar trends are observed in RNAGym, where the performance gap between RNA-FM and RNAErine increases with epistatic complexity.
Applications Beyond Fitness Prediction
GraphFLA extends to broader tasks, such as interpreting directed evolution (DE) outcomes. Analysis of DE and ML-guided DE approaches on combinatorial protein landscapes shows that basic DE is effective on benign landscapes but struggles with rugged, epistatic, and non-navigable landscapes. Advanced MLDE and active learning methods demonstrate greater robustness to landscape complexity.
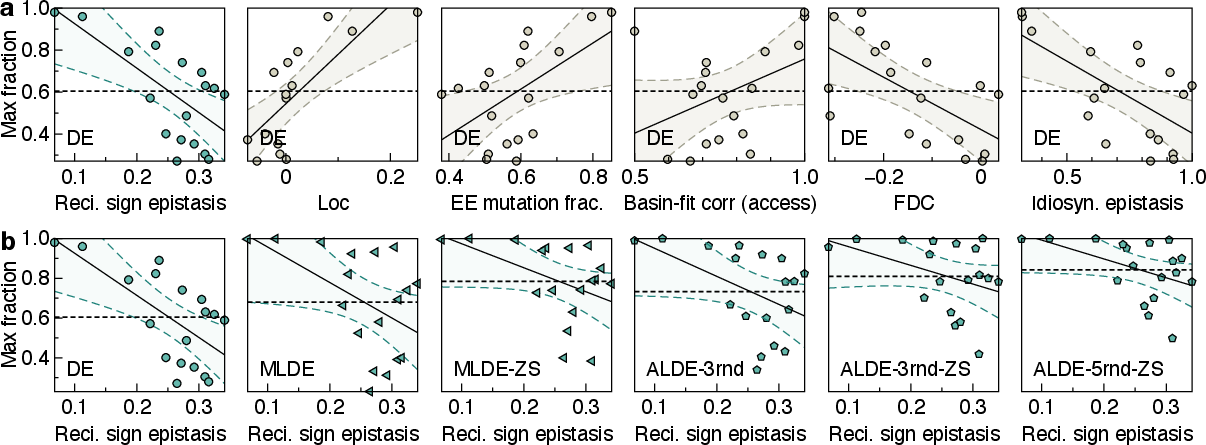
Figure 6: Maximum fitness achieved by DE and ML-guided methods across landscapes, plotted against landscape features.
The framework is also applicable to gene regulatory networks, metabolic landscapes, microbial community-function landscapes, and phenotype landscapes (e.g., RNA secondary structure, protein folding), supporting general combinatorial optimization analysis.
Implementation Considerations
GraphFLA is implemented in Python with C-backed graph operations (via igraph), supporting efficient analysis of landscapes with up to 107 variants. The API is compatible with standard ML data formats, facilitating integration with existing benchmarks and model pipelines. Computational requirements scale linearly with landscape size for most features, but certain analyses (e.g., basin size computation) may be expensive for extremely large landscapes with many local optima.
The framework is robust to missing and noisy data, and can approximate landscape features from biasedly sampled mutagenesis libraries. Limitations include challenges in visualizing high-dimensional topography and the practical upper bound on analyzable landscape size, which is nonetheless sufficient for current experimental datasets.
Implications and Future Directions
GraphFLA provides a principled approach to augmenting fitness prediction benchmarks with biologically meaningful landscape features, enabling granular interpretation of model performance and landscape-aware model selection. This facilitates more informed development and evaluation of ML models for biological sequence analysis, protein engineering, and evolutionary studies.
The framework's extensibility and scalability position it as a valuable resource for future research in combinatorial optimization, evolutionary dynamics, and AI-guided biological design. Potential developments include automated algorithm selection based on landscape features, integration with multi-objective optimization, and application to emerging modalities such as single-cell omics and spatial genomics.
Conclusion
GraphFLA fills a critical gap in biological fitness prediction benchmarking by providing a comprehensive, scalable, and interoperable framework for landscape analysis. Its suite of 20 features enables biologically grounded interpretation and comparison of model performance, augments existing benchmarks, and supports a wide range of applications in evolutionary biology and combinatorial optimization. The framework is expected to facilitate deeper understanding of model capabilities and limitations, and to drive future advances in AI-guided biological research.

