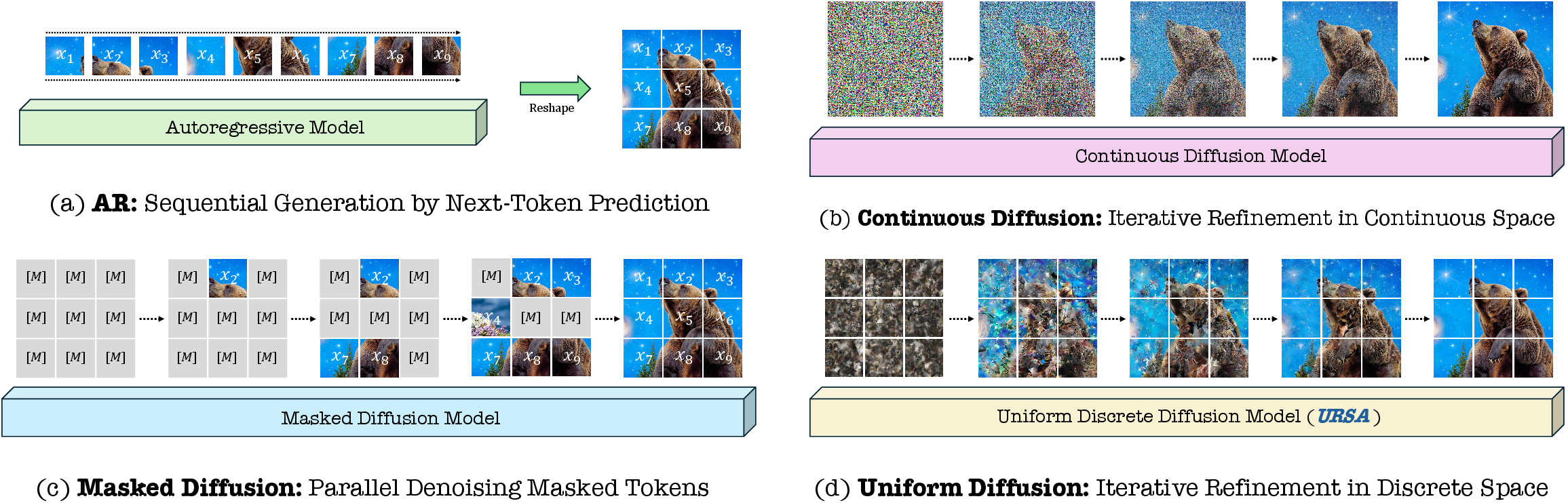
Uniform Discrete Diffusion with Metric Path for Video Generation
Abstract: Continuous-space video generation has advanced rapidly, while discrete approaches lag behind due to error accumulation and long-context inconsistency. In this work, we revisit discrete generative modeling and present Uniform discRete diffuSion with metric pAth (URSA), a simple yet powerful framework that bridges the gap with continuous approaches for the scalable video generation. At its core, URSA formulates the video generation task as an iterative global refinement of discrete spatiotemporal tokens. It integrates two key designs: a Linearized Metric Path and a Resolution-dependent Timestep Shifting mechanism. These designs enable URSA to scale efficiently to high-resolution image synthesis and long-duration video generation, while requiring significantly fewer inference steps. Additionally, we introduce an asynchronous temporal fine-tuning strategy that unifies versatile tasks within a single model, including interpolation and image-to-video generation. Extensive experiments on challenging video and image generation benchmarks demonstrate that URSA consistently outperforms existing discrete methods and achieves performance comparable to state-of-the-art continuous diffusion methods. Code and models are available at https://github.com/baaivision/URSA



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for computers to make videos (and images) called URSA. Instead of creating pictures one tiny piece at a time and never changing them, URSA starts with a rough, random version and improves the whole video step by step. Think of it like starting with a noisy, scrambled puzzle and steadily replacing wrong pieces with the right ones until the final video looks clear and realistic.
What are the main goals?
The paper sets out to:
- Build a simple, fast method that can make high-quality videos using “discrete tokens” (like small building blocks) instead of continuous values.
- Fix common problems in discrete methods, such as mistakes piling up over time and weird motion in long videos.
- Make the method scale to big images and long videos while needing fewer steps to generate results.
- Support many tasks in one model, like text-to-video, image-to-video, and video interpolation (filling in missing frames).
How does URSA work?
URSA treats videos as sequences of discrete tokens—imagine LEGO bricks that represent parts of an image or a video frame.
Here’s the approach in everyday terms:
- Start from “random noise”: URSA begins with a fully scrambled set of tokens, like a jumbled bag of LEGO bricks thrown on a table.
- Iterative global refinement: Instead of locking in each token forever (like writing a sentence letter by letter and never editing), URSA updates all tokens repeatedly. It’s like editing the whole essay many times to make it better overall.
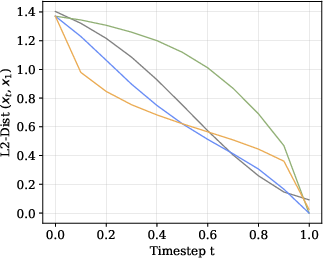
- A metric-guided path (a “smart improvement plan”): URSA uses a measure of “distance” between its current guess and the target look, based on token embeddings (think: how similar two LEGO bricks are meant to be). Then it moves toward the correct tokens in a controlled, smooth way. This “path” makes progress steady and predictable.
To make this work well for big images and long videos, URSA adds three key ideas:
- Linearized Metric Path: This keeps the improvement steps steady, like a coach setting a pace so progress stays smooth from start to finish.
- Resolution-dependent Timestep Shifting: Bigger images have more detail, so URSA adjusts how strongly it changes tokens depending on resolution. It “pushes harder” for big, detailed frames and “gently” for smaller ones.
- Asynchronous Timestep Scheduling: Each video frame can be at a different “cleanup level.” That lets URSA do special tricks like:
- Image-to-video: keep the first frame very clean while letting later frames change more.
- Interpolation: fill in missing frames by giving those specific frames the right level of noise and refinement.
- Long videos: keep motion smooth and consistent over time.
Under the hood, URSA learns a model that predicts how to move from the noisy tokens toward the correct tokens (like following a GPS route from “random” to “real”). It uses a training signal that tells it how close its predictions are to the true tokens and improves over many examples. When sampling, it repeatedly nudges the tokens along the learned path with just a few steps to create a final video or image.
What did the researchers find?
The authors tested URSA on standard benchmarks and compared it to leading methods:
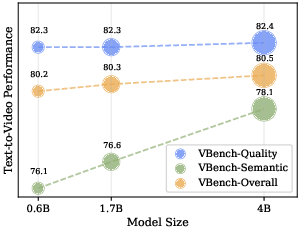
- Text-to-video: URSA scored 82.4 on VBench, beating other discrete methods and matching or exceeding several strong continuous methods in key areas.
- Image-to-video: URSA reached 86.2 on VBench++, showing strong control of camera motion and subject consistency.
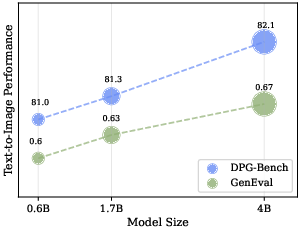
- Text-to-image: URSA achieved 86.0 on DPG-Bench, outperforming previous discrete approaches and competing with top continuous models.
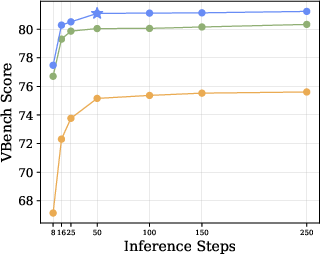
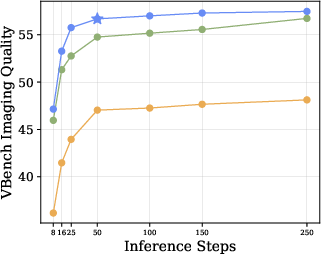
- Efficiency: URSA needs fewer steps to generate high-quality results, making it faster while keeping details and motion consistent.
- Versatility: With its asynchronous scheduling, one model handles multiple tasks—text-to-video, image-to-video, interpolation, and even longer videos—without needing separate specialized models.
Why is this important?
URSA shows that discrete methods (the same kind of “token” approach used by big LLMs) can catch up to continuous diffusion methods in visual generation. This matters because:
- It can make video generation faster and more scalable, especially for large or long content.
- One model can do many tasks, simplifying real-world use.
- It improves motion consistency and reduces errors over long sequences, which is crucial for believable videos.
- It helps bridge two major AI paradigms—discrete tokens and continuous diffusion—pointing toward a future where we get the best of both worlds: speed, stability, and high visual quality.
In short, URSA is like a careful editor for videos: it starts messy, refines globally with a steady plan, adapts to size and time, and delivers high-quality results with fewer steps and more flexibility.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that emerge from the paper and could guide future research.
- Probability path design and theory
- The “linearized metric path” is hand-tuned via visual inspection of hyperparameters c and α; no principled or learnable procedure (e.g., end-to-end hyperparameter learning, bilevel optimization, or calibration objectives) is provided for selecting or adapting these parameters across tokenizers, domains, or resolutions.
- The choice of distance d(·,·) between codebook embeddings is not fully specified or justified (e.g., cosine vs. Euclidean, learned vs. fixed). It is unclear how sensitive performance is to the metric choice or to codebook geometry, and whether metric learning would improve the probability path.
- No formal analysis connects the metric-induced path to optimality criteria (e.g., optimal transport cost, discrete Benamou–Brenier analogs) or provides convergence/stability guarantees for the CTMC dynamics under this path.
- The paper uses Euler integration for the CTMC; it does not evaluate alternative discrete solvers (e.g., higher-order, adaptive-step, variance-reduced, or implicit schemes) and their trade-offs in quality vs. step count.
- Timestep shifting and SNR scheduling
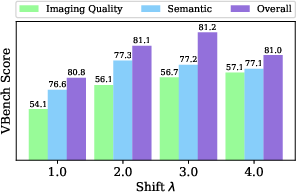
- The resolution-dependent timestep shifting parameter λ is selected heuristically; there is no method to automatically infer λ given resolution, sequence length, or content complexity, nor an analysis of robustness to mis-specified λ.
- Although the paper finds SD3-style shifting effective, it does not quantify how shifting interacts with token vocabulary size, codebook entropy, or different tokenizers (e.g., FSQ vs. IBQ) across tasks.
- The paper focuses on single global λ per resolution; it does not explore content-adaptive schedules (e.g., motion-aware, region-aware, or subject-aware SNR adjustments) or frame-wise schedule learning.
- Asynchronous timestep scheduling
- The approach samples per-frame timesteps independently, but the impact on temporal stability, flicker, or causal consistency is not quantified with dedicated temporal metrics (e.g., T-LPIPS, FVD, long-range identity consistency).
- No ablation compares asynchronous scheduling to alternative structured schedules (e.g., blockwise, curriculum-based, or causally constrained schedules) for long videos.
- Theoretical understanding of why and when asynchronous scheduling improves multi-task learning (I2V, interpolation, extrapolation) is missing; failure modes (e.g., desynchronization artifacts) are not characterized.
- Tokenizer dependency and bottlenecks
- The paper acknowledges tokenizers as a fidelity bottleneck but does not quantify reconstruction error (PSNR/LPIPS per resolution), spatiotemporal compression impacts, or how token collisions affect generation errors over time.
- No systematic study evaluates how codebook size, compression ratios (temporal vs. spatial), or tokenizer training objectives affect URSA’s performance. The sensitivity to different discrete tokenizers (beyond Cosmos and IBQ) remains unclear.
- The metric path relies on meaningful embedding distances; the paper does not study whether codebook embedding geometry is well-calibrated for metric-guided diffusion or how to train tokenizers to produce metrically faithful embeddings.
- Long video generation claims vs. evaluations
- Despite claims of “minute-level” videos, evaluations are limited to short clips (e.g., 49 frames at 512×320). There is no benchmarked evidence on videos longer than tens of seconds, nor metrics capturing long-horizon consistency, narrative coherence, or identity preservation over minutes.
- Memory, latency, and throughput for long-sequence inference are not reported. Practical limits (e.g., quadratic attention cost, sliding-window strategies, or key-value reuse) are not described or evaluated.
- Failure case analysis for long-form content (e.g., drift, looping, semantic forgetting, accumulative artifacts) is absent.
- Fairness of comparisons and evaluation scope
- Reported comparisons use different parameter counts, datasets, and data curation; there is no controlled, compute-matched or data-matched comparison to continuous baselines or other discrete methods.
- Evaluations rely heavily on VBench/DPG/GenEval; there is no human preference study, no physics/causality benchmarks, and no comprehensive temporal metrics beyond those embedded in VBench.
- Classifier-free guidance is fixed at scale 7.0; its effect on quality/semantic trade-offs is not studied, nor are CFG-free alternatives or guidance schedule optimization.
- Video interpolation/extrapolation claims are supported by qualitative examples; quantitative task-specific metrics (e.g., interpolation PSNR/SSIM/LPIPS against ground truth) are not reported.
- Training signal and objectives
- The training objective is cross-entropy to predict x1 from xt; alternative objectives (e.g., token-aware reweighting, curriculum over t, self-conditioning, or consistency training) are not explored.
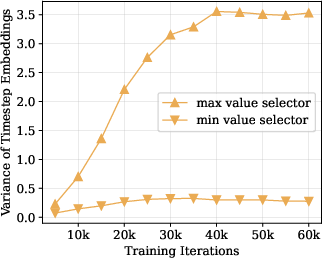
- The effect of time conditioning is probed only early in training; it remains unclear whether timestep embeddings help later or under different schedules/tokenizers, or whether learned time prompts can replace explicit embeddings at scale.
- The model initializes from a pre-trained LLM; ablations on the role of language pretraining (e.g., initialization quality, frozen vs. finetuned layers, multi-task pretraining) for video generation are missing.
- Data, bias, and reproducibility
- A significant portion of training data is internal and/or AI-generated; there is no analysis of how synthetic images or internal captions bias aesthetics, semantics, or motion priors, nor of robustness to noisy captions.
- The paper does not provide dataset cards (curation, filtering, licenses) or quantitative breakdowns of domains and motion categories, limiting reproducibility and fairness assessments.
- Potential leakage or overlap with evaluation prompts (especially with rewritten prompts) is not audited.
- Robustness, safety, and ethical considerations
- No analysis of safety risks (e.g., deepfakes, misuse, biases), content filters, or mitigation strategies is provided.
- Robustness to adversarial or out-of-domain prompts, rare actions, or complex camera trajectories is not evaluated; failure modes are not documented.
- Efficiency and resource reporting
- The paper omits detailed training/inference cost measurements (wall-clock time, energy, memory), especially versus continuous baselines under equal-quality settings.
- The number of refinement steps is reported (25/50), but the quality–latency Pareto and the benefits of adaptive step schedules are not studied.
- Architectural choices and ablations
- The impact of 3D-RoPE design choices (interleaving strategy, frequency allocation) on temporal coherence and cross-resolution generalization is not isolated.
- The role of bidirectional vs. causal attention for future prediction under asynchronous scheduling is not compared; whether causal variants could reduce flicker or improve controllability is unknown.
- The backbone is a Qwen3 LLM; the extent to which LLM inductive biases vs. bespoke video transformer designs affect performance is not explored.
- Generalization and extensions
- Generalization to other modalities (audio, 3D, multi-view, depth) or cross-modal conditioning (trajectories, scene graphs) is not investigated, though the discrete setup suggests straightforward extensions.
- It is unknown whether URSA’s metric path and timestep shifting transfer to higher resolutions (e.g., 4K) or to other tasks (e.g., video editing, controllable physics) without re-tuning.
- Open algorithmic questions
- Can λ, c, and α be learned jointly with the model (e.g., via meta-learning) and adapted per sample or per frame?
- Would hierarchical or multi-scale discrete diffusion (global-to-local tokens, patch-then-pixel codes) reduce tokenizer bottlenecks and improve long-horizon consistency?
- How does uncertainty propagate in discrete refinement, and can uncertainty-aware decoding (e.g., entropy-based token resampling or consensus decoding) reduce sampling errors?
These gaps suggest concrete next steps: principled/learned schedule design, tokenizer–path co-design, long-horizon benchmarking and metrics, efficiency and fairness controls in comparisons, broader and safer evaluations, and deeper theoretical/solver analyses for discrete probability path dynamics.
Practical Applications
Immediate Applications
The following list summarizes concrete use cases that can be deployed now, leveraging URSA’s iterative global refinement over discrete tokens, its linearized metric path, resolution-dependent timestep shifting, and asynchronous frame-wise scheduling.
- Text-to-video and image-to-video content creation for marketing and entertainment
- Sector: media/advertising, consumer software
- Tool/Product/Workflow: “URSA Studio” for prompt-based ad spots, social clips, and animating product photos; plugins for Adobe/DaVinci Resolve/FCP to turn static assets into short videos via I2V
- Assumptions/Dependencies: brand-safety guardrails; high-quality tokenizer codebooks to preserve fine detail; caption quality; rights to training data/prompts
- Rapid storyboarding and previsualization from scripts
- Sector: film, gaming, animation
- Tool/Product/Workflow: script-to-animatic pipeline using URSA’s hierarchical coarse-to-fine token refinement; asynchronous scheduling to control start/end frames and scene beats
- Assumptions/Dependencies: domain prompts and shot descriptors; creative direction oversight; tokenizers with adequate spatial compression for scene composition
- Video interpolation, in-betweening, and motion smoothing
- Sector: post-production, restoration, surveillance
- Tool/Product/Workflow: “URSA Interpolator API” leveraging frame-wise independent noise schedules to reconstruct missing frames and stabilize motion
- Assumptions/Dependencies: domain-specific fine-tuning for camera motion and compression artifacts; consistent frame timing metadata
- Educational micro-animations and concept visualizations from text
- Sector: education, e-learning
- Tool/Product/Workflow: courseware generator from lesson prompts (physics demos, biological processes) using T2V; coarse-to-fine generation for clarity
- Assumptions/Dependencies: expert review for factual accuracy; curriculum alignment; safety content filters
- Synthetic video data generation for perception model training
- Sector: robotics, autonomous driving, retail analytics
- Tool/Product/Workflow: “ScenarioGen” to produce varied, label-able scenes (traffic, indoor navigation) with temporal coherence via global refinement
- Assumptions/Dependencies: domain randomization; realism calibrated to target task; integration with labeling pipelines; tokenizer reconstruction quality limits top-end fidelity
- Product demos and UX walkthroughs
- Sector: software/SaaS
- Tool/Product/Workflow: text prompts (feature descriptions) to short explainer videos; I2V for UI screenshots to animated sequences
- Assumptions/Dependencies: access to UI assets; legal review for brand depiction; prompt templating for consistent narratives
- Content localization and variant generation
- Sector: global marketing
- Tool/Product/Workflow: multi-language prompt swaps to generate culturally appropriate variants; leveraging URSA’s semantic strength and asynchronous frame control
- Assumptions/Dependencies: localization QA; cultural sensitivity checks; regional rights management
- Long-form highlight reels and clip stitching
- Sector: sports, events, creator tooling
- Tool/Product/Workflow: timeline-aware generation using frame-wise noise schedules to blend segments; text prompts describing highlights
- Assumptions/Dependencies: structured metadata; transition control; compute budgets for longer sequences
- Research and reproducibility in discrete diffusion
- Sector: academia/ML engineering
- Tool/Product/Workflow: baselines and ablations using URSA’s open-source code; applying linearized metric paths to study convergence and sampling errors
- Assumptions/Dependencies: access to GPUs; high-quality tokenizer codebooks; reproducible evaluation (VBench, DPG-Bench, GenEval)
- Sustainability-oriented inference (fewer steps, faster generation)
- Sector: energy/sustainability, cloud ops
- Tool/Product/Workflow: “Green Gen Pipeline” benchmarking cost and emissions; adopting URSA to reduce inference steps vs. continuous models
- Assumptions/Dependencies: instrumented monitoring; comparable quality targets; careful scheduler tuning (β(t), timestep shifting λ)
Long-Term Applications
The following use cases require further research, scaling, tokenizer advances, or productization to reach maturity.
- On-device video generation for AR/VR glasses and mobile devices
- Sector: consumer electronics, spatial computing
- Tool/Product/Workflow: distilled URSA variants (≤1B parameters) with efficient tokenizers; hardware-aware schedulers for low-latency generation
- Assumptions/Dependencies: compact, high-fidelity discrete tokenizers; model compression/distillation; edge accelerators
- Clinical training and patient education animations
- Sector: healthcare/medtech
- Tool/Product/Workflow: domain-specific text-to-video (procedures, anatomy) with temporal consistency; semi-automated storyboard from clinical guidelines
- Assumptions/Dependencies: medical validation and regulatory compliance; high-fidelity, domain tokenizers; provenance and audit trails
- Simulation-rich synthetic datasets for embodied AI and robotics
- Sector: robotics, industrial automation
- Tool/Product/Workflow: task-specific generators producing long sequences (minute-level) for policies; integration with physics engines for grounded motion
- Assumptions/Dependencies: sim-to-real alignment; realistic dynamics; scenario diversity; labels and telemetry
- Codec-like discrete video compression using URSA tokenizers
- Sector: telecom/media infrastructure
- Tool/Product/Workflow: “URSA-Codec” standardizing FSQ/IBQ token streams; generative reconstruction on client side
- Assumptions/Dependencies: codebook standardization; bitrate–quality trade-offs; interoperability and standards approval
- Full-length, multi-scene narrative generation with controllable beats
- Sector: film, streaming
- Tool/Product/Workflow: “LongForm Composer” combining script planners with frame-wise scheduling (start/end control, interpolation) across scenes
- Assumptions/Dependencies: planning modules (LLMs) for narrative coherence; robust tokenizers for scene transitions; large-scale multi-scene training
- Multi-modal discrete generation (video + audio + subtitles)
- Sector: media creation, accessibility
- Tool/Product/Workflow: extend metric path to audio token embeddings for synchronized soundtracks and lip-sync; generate captions aligned to temporal structure
- Assumptions/Dependencies: strong audio tokenizers; cross-modal schedulers; alignment metrics; rights for training audio
- Enterprise knowledge visualization (procedural videos from docs)
- Sector: enterprise software, knowledge management
- Tool/Product/Workflow: doc-to-video pipelines converting SOPs and manuals into step-by-step visual guides; semantic control via linearized metric path
- Assumptions/Dependencies: document parsing quality; domain prompts; governance and access controls
- Scientific visualization and explainer videos from models and data
- Sector: climate/energy, biotech, materials
- Tool/Product/Workflow: model-to-video adapters that turn scientific outputs into temporally consistent visual narratives (e.g., climate flows, cellular processes)
- Assumptions/Dependencies: high-precision tokenizers; validation against ground truth; domain expert review; reproducibility of visual claims
- Policy and provenance ecosystems for synthetic video
- Sector: policy/regulation, trust & safety
- Tool/Product/Workflow: C2PA-integrated pipelines; watermarking tied to metric-path sampling signatures; auditor dashboards
- Assumptions/Dependencies: standard adoption; robust watermarking resistant to post-processing; user transparency
- Unified multimodal creative suites (LLM planning + URSA generation)
- Sector: creative tooling, productivity
- Tool/Product/Workflow: “Story-to-Video Engine” where LLMs plan scenes, assets, and constraints; URSA generates long-form video with per-frame control
- Assumptions/Dependencies: tight integration between planners and generators; dataset breadth for multi-task generalization; compute and caching strategies
- Automated investor relations and finance explainers
- Sector: finance/fintech
- Tool/Product/Workflow: prompt-to-video summaries of earnings decks and product updates; visual narratives with charts and animations
- Assumptions/Dependencies: data accuracy and compliance; chart tokenizers; governance over market-moving content
- Personalized tutoring with stepwise video feedback
- Sector: education, edtech
- Tool/Product/Workflow: adaptive lesson video generation; temporal scaffolding via asynchronous schedule to match learner progress
- Assumptions/Dependencies: pedagogy-aligned prompts; learner modeling; content safety and age-appropriateness
Cross-cutting assumptions and dependencies that affect feasibility
- Tokenizer quality is a foundational bottleneck: discrete codebook capacity and reconstruction fidelity constrain visual detail; improved FSQ/IBQ-like tokenizers are pivotal for high-resolution, long-form quality.
- Compute and scaling: while URSA reduces inference steps, training large models (1.7B+) still requires substantial GPUs; deployment may need distillation and scheduler tuning.
- Data rights and safety: lawful datasets, watermarking/provenance (e.g., C2PA), and content moderation are mandatory for commercial releases, especially in sensitive domains (healthcare, finance).
- Domain adaptation: task-specific fine-tuning and prompt engineering are essential for specialized sectors (medical visuals, scientific accuracy, robotics scenarios).
- Evaluation alignment: human-in-the-loop QA remains important despite strong benchmark scores (VBench, DPG-Bench, GenEval), particularly for factual correctness and safety.
- Integration costs: success depends on embedding URSA into existing creative tools, MLOps stacks, and enterprise workflows; APIs, SDKs, and plugin ecosystems will accelerate adoption.
Glossary
- Asynchronous temporal fine-tuning: A training strategy that updates temporal components out of sync to support multiple video tasks in one model. "Additionally, we introduce an asynchronous temporal fine-tuning strategy that unifies versatile tasks within a single model, including interpolation and image-to-video generation."
- Asynchronous timestep scheduling: Assigning independent timesteps (noise levels) to each frame during training or sampling to improve temporal modeling. "we propose an asynchronous timestep scheduling strategy tailored for multi-task training and sampling."
- Autoregressive (AR) models: Generative models that produce tokens sequentially, each conditioned on previous outputs. "unlike classic autoregressive (AR) models and masked diffusion models (MDM) that adopt non-refinable local generation"
- Bidirectional transformers: Transformers that attend to both past and future tokens, enabling non-causal context modeling. "even though masked diffusion models employ bidirectional transformers, we still observe low visual quality and unnatural object motions."
- Causal attention: An attention mechanism restricting each position to attend only to previous positions (no future context). "pushing the boundaries of autoregressive discrete video generation models without causal attention."
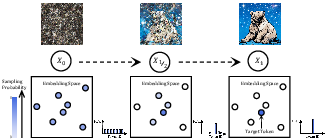
- Categorical noise: Discrete noise sampled from a uniform categorical distribution over token indices. "URSA starts from categorical noise, "
- Classifier-free guidance: A sampling technique that blends conditional and unconditional model predictions to strengthen adherence to prompts. "We apply classifier-free guidance~\citep{ALGO:CFG} with a scale value of 7.0 in all evaluations."
- Codebook embeddings: Learned vectors associated with discrete tokens in a tokenizer’s codebook, used to measure token similarity. "discrepancy between the codebook embeddings of generated token and the target tokens ."
- Continuous-Time Markov Chain (CTMC): A stochastic process with state transitions occurring in continuous time. "we consider a Continuous-Time Markov Chain (CTMC), modeled as a stochastic process."
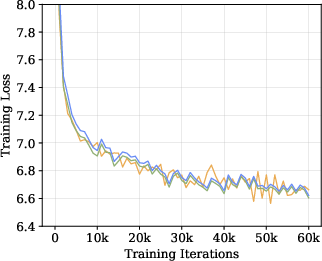
- Cross-entropy: A loss function measuring the divergence between the true distribution and the model’s predicted distribution. "The training objective is formulated as the expected cross-entropy between the ground-truth visual tokens and the model’s predicted distribution:"
- Diffusion forcing: A technique that adapts diffusion training or scheduling to autoregressive or multi-task setups. "Motivated by diffusion forcing~\citep{ALGO:DForcing}, we propose an asynchronous timestep scheduling strategy"
- Discrete Flow Matching (DFM): A framework that learns a velocity field to evolve a probability path in discrete state space from source to target distributions. "Discrete Flow Matching (DFM) introduces a family of generative models designed to map data from an initial distribution , to a final distribution , within a discrete state space."
- Euler solver: A first-order numerical method used to iteratively update samples along an estimated velocity field. "we employ the Euler solver for efficient and high-quality generation."
- FSQ codebook: A Finite Scalar Quantization codebook providing discrete tokens for compressed visual representations. "through a 64K FSQ codebook."
- Frame-wise Independent Perturbation Scheduling (FIPS): A scheduling strategy that applies independent perturbations per frame to enable unified long-video generation and multitask training. "Frame-wise Independent Perturbation Scheduling strategy for unified long-video generation and multitask learning."
- Kinetic Optimal Scheduler: A timestep scheduler derived from kinetic principles that optimizes the metric-induced probability path. "We adopt the Kinetic Optimal Scheduler~\citep{ALGO:KINETIC}, equipped with a metric-induced probability path specifically designed for the embedding space of vision tokenizers."
- Linearized metric path: A probability path defined via token embedding distances and a time-dependent scale, designed to make perturbation progress linear in time. "We introduce the linearized metric path, a novel probability path derived from token embedding distances."
- Masked diffusion models (MDM): Discrete generative models that predict masked tokens in parallel, enabling faster generation than autoregression. "masked diffusion models (MDM) that adopt non-refinable local generation"
- MaskGIT scheduler: A scheduling strategy for masked token prediction controlling mask rates across steps to improve generation quality. "we adopt the MaskGIT~\citep{MODEL:MASKGIT} scheduler, which has been empirically shown to achieve state-of-the-art performance in both image and video generation models"
- Mixture probability path: A diffusion path that mixes uniform and data-aligned components for standard discrete uniform diffusion. "For standard uniform diffusion, we use the mixture probability path proposed by~\citet{ALGO:DFM}."
- M-RoPE: A multi-dimensional Rotary Position Embedding variant allocating frequencies across temporal, height, and width dimensions. "we introduce an enhanced M-RoPE~\citep{VLM:QWEN2VL} that allocates interleaved frequency components across temporal, height, and width dimensions"
- Probability path: A time-indexed distribution that interpolates between source and target distributions over the interval [0,1]. "We consider the probability path "
- Probability velocity: The time-dependent transition rate governing how a CTMC evolves a probability path toward the target distribution. "The dynamics of this CTMC are governed by a probability velocity , also known as the transition rate."
- QK-Norm: A normalization method applied to attention queries and keys to stabilize training, especially in multimodal models. "which natively incorporates QK-Norm~\citep{MODEL:VIT22B} layer to stabilize the multimodal training."
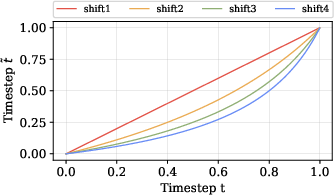
- Resolution-dependent Timestep Shifting: A mechanism that shifts timesteps based on resolution to adjust perturbation strength for long or high-resolution sequences. "a Resolution-dependent Timestep Shifting mechanism."
- RoPE (Rotary Position Embedding): A positional encoding technique that rotates embeddings to encode relative positions in transformers. "ensuring equivalence with the 1D-RoPE~\citep{ARCH:ROPE}."
- SNR schedule: A signal-to-noise ratio schedule controlling noise levels over time to suit video size or resolution. "the optimal SNR schedule should be tailored with video size."
- Spatiotemporal tokens: Discrete tokens that jointly encode spatial and temporal content for videos. "iterative global refinement of discrete spatiotemporal tokens."
- Timestep shifting: Adjusting the effective timestep via a shift parameter to modulate perturbation behavior. "Timestep shifting across SNR schedules."
- Tokenizer: A model that compresses images or videos into discrete token sequences for generative modeling. "using a pre-trained tokenizer, resulting in a clean video sequence"
- Uniform discrete diffusion: A discrete diffusion process starting from a uniform categorical distribution and refining globally over tokens. "we adopt a uniform discrete diffusion approach, which performs iterative global refinement from categorical noise."
- Velocity field: The conditional rate function that directs transitions from current to target token states over time. "where represents velocity field, a conditional rate function that governs the flow of probability from the current state to the target state over time."
Collections
Sign up for free to add this paper to one or more collections.

