- The paper introduces AgentFrontier, a framework that generates ZPD-aligned QA data to systematically elevate LLM agents' multi-step reasoning and tool-use abilities.
- It employs a three-stage pipeline—seed generation, iterative refinement, and ZPD-based calibration—to produce complex, multidisciplinary questions tailored to the model's learning frontier.
- Experimental results demonstrate that AgentFrontier-trained models outperform existing benchmarks like HLE and ZPD Exam, achieving near-saturation in emergent mastery.
Expanding the Capability Frontier of LLM Agents with ZPD-Guided Data Synthesis
Introduction and Motivation
The paper introduces AgentFrontier, a data synthesis and evaluation framework for LLM agents, grounded in the educational theory of the Zone of Proximal Development (ZPD). The central thesis is that LLMs' progress toward advanced, agentic reasoning is fundamentally limited by the lack of systematically challenging, high-quality training data that targets the precise boundary of their current capabilities. Existing data curation and synthesis paradigms—query-centric and document-centric—primarily support localized comprehension and single-step reasoning, failing to foster the knowledge fusion and multi-step, cross-domain reasoning required for complex real-world tasks.
AgentFrontier operationalizes ZPD by distinguishing between a Less Knowledgeable Peer (LKP, a base LLM without tools) and a More Knowledgeable Other (MKO, a tool-augmented agent). The framework synthesizes data that is unsolvable by the LKP but solvable by the MKO, thereby targeting the model's capability frontier. This approach is instantiated in both a scalable data generation engine and a dynamic, self-evolving benchmark (ZPD Exam) for evaluating agentic reasoning.
AgentFrontier Data Synthesis Engine
The AgentFrontier Engine is a three-stage pipeline designed to generate high-value, multidisciplinary data situated within the LLM's ZPD.
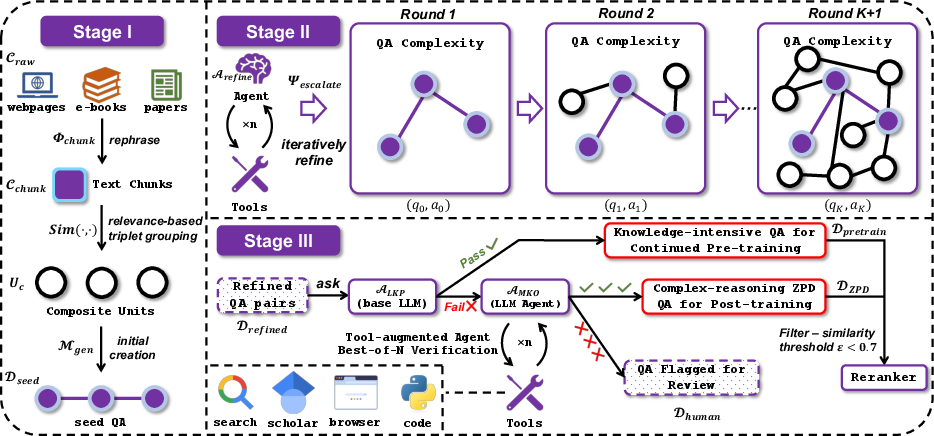
Figure 1: The three-stage synthesis pipeline of the AgentFrontier Engine, from multi-source seed question generation, through iterative agentic refinement, to ZPD-based calibration and filtering.
Stage I: Multi-Source Seed Question Generation
The process begins with a large, diverse corpus of public documents. A powerful LLM is used to preprocess and chunk the corpus into information-dense units. For each chunk, a vector index is constructed to efficiently retrieve thematically coherent neighbors, forming composite units (triplets) that serve as the basis for seed question generation. This ensures that initial questions inherently require knowledge fusion across multiple sources.
Stage II: Iterative Agentic Refinement
Seed QA pairs are escalated in complexity via an agent equipped with a tool suite (search, scholar, browser, code). The agent applies an escalation operator that enriches the QA along four axes: knowledge expansion, conceptual abstraction, factual grounding, and computational formulation. This iterative process produces increasingly intricate, multi-step reasoning tasks, with each iteration leveraging external tools to synthesize, validate, and ground new information.
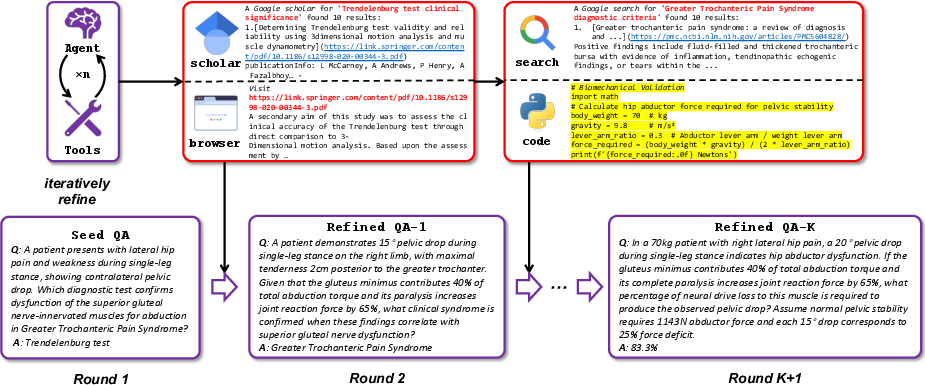
Figure 2: Iterative refinement of a biomedical seed QA into a complex diagnostic reasoning and computational challenge, integrating literature synthesis, web search, and programmatic validation.
Stage III: ZPD-Based Calibration and Filtering
Each refined QA pair is evaluated by the LKP and, if unsolved, by the MKO using a Best-of-N (BoN) verification protocol. Only pairs unsolvable by the LKP but solvable by the MKO are retained as ZPD-aligned data. A semantic redundancy filter ensures dataset diversity by discarding near-duplicate questions. This adversarial calibration mechanism guarantees that the resulting dataset is both challenging and learnable, directly targeting the model's developmental frontier.
ZPD Exam: A Self-Evolving Benchmark
To address the saturation and static nature of existing benchmarks, the ZPD Exam is introduced as a dynamic, automated evaluation suite. It is constructed by applying the AgentFrontier Engine to a disjoint corpus of recent scientific literature, generating novel, multidisciplinary questions that are intractable for the baseline model without tools but solvable with tool augmentation.
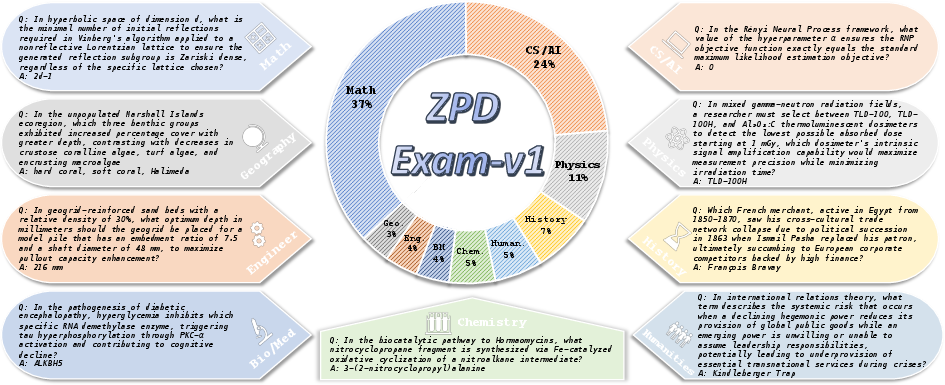
Figure 3: ZPD Exam-v1 composition, with 1024 questions spanning 9 academic disciplines, designed to probe cross-domain, agentic reasoning.
The ZPD Exam stratifies agent performance into three zones: intrinsic competence (parametric knowledge only), the reasoning bottleneck (partial success with tools), and emergent mastery (robust, multi-step planning and synthesis). This diagnostic structure enables fine-grained analysis of agentic reasoning and tool orchestration, and the benchmark can be regenerated as models improve, maintaining its relevance.
Experimental Results and Analysis
AgentFrontier-30B-A3B, a model trained with the proposed framework, is evaluated on four challenging benchmarks: Humanity's Last Exam (HLE), ZPD Exam, R-Bench-T, and xBench-ScienceQA. The model is trained via continued pre-training (CPT) on knowledge-intensive data, followed by rejection-sampling fine-tuning (RFT) on 12,000 ZPD-aligned QA trajectories.
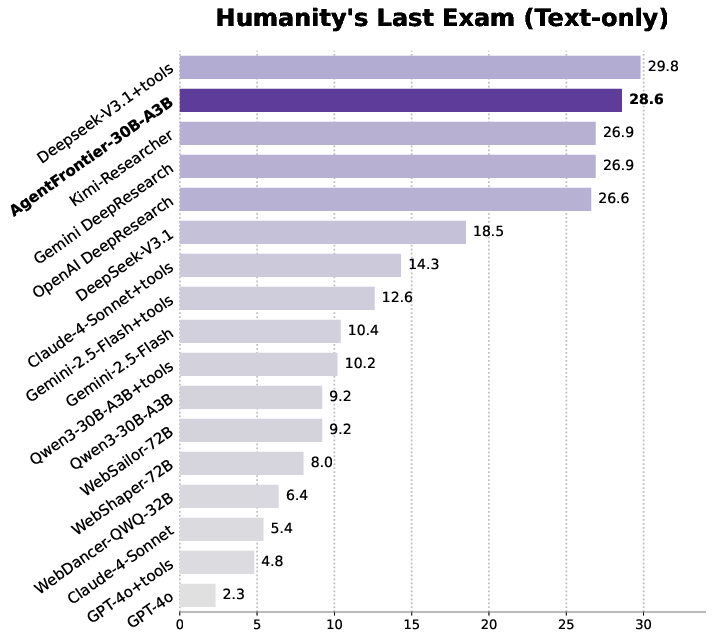
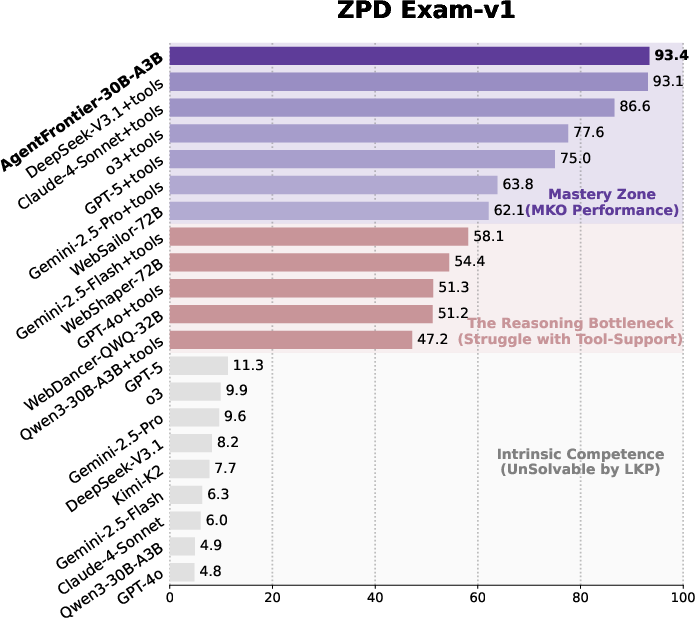
Figure 4: Performance of LLM agents on the text-only HLE set, demonstrating the impact of ZPD-guided data synthesis.
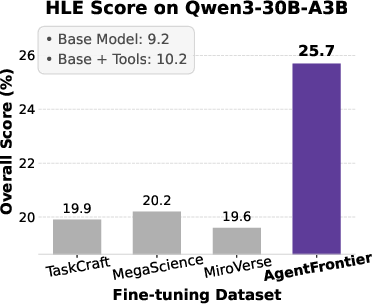
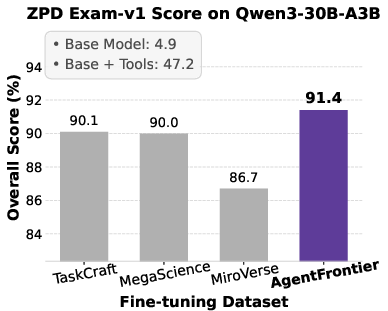
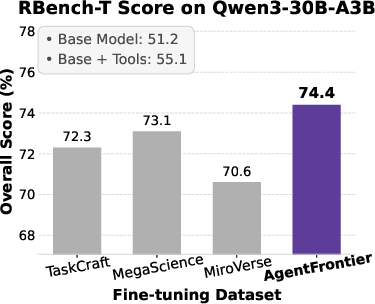
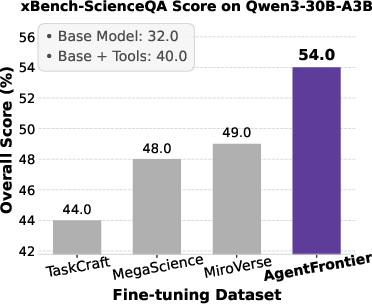
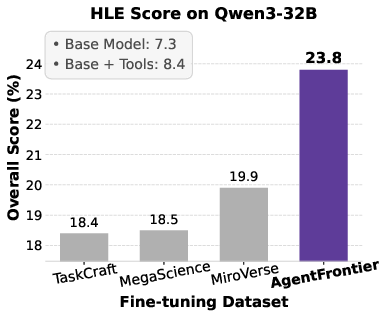
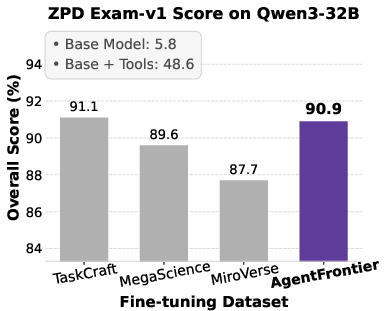
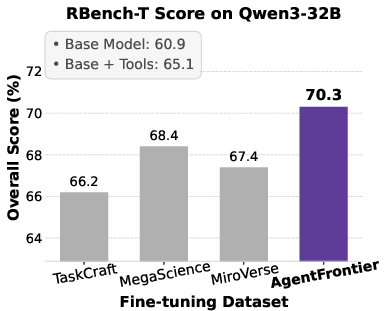
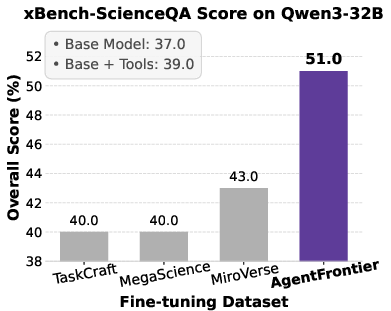
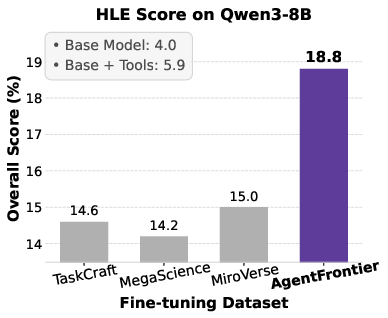
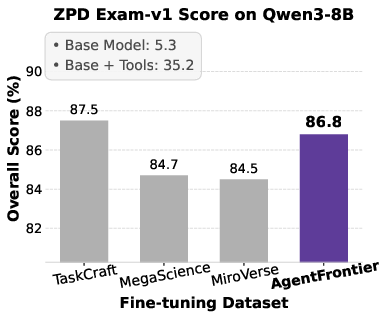
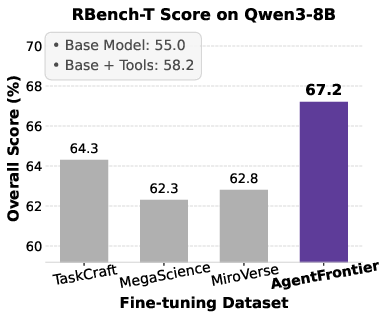
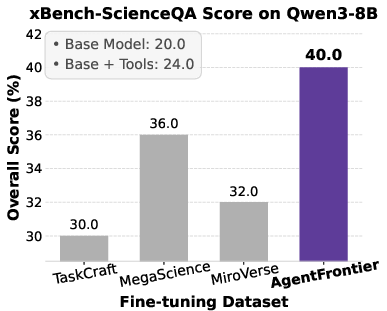
Figure 5: Impact of fine-tuning datasets on Qwen3 series models' performance across four benchmarks, with AgentFrontier consistently outperforming alternatives.
Key findings include:
- AgentFrontier-trained models achieve state-of-the-art results on all evaluated benchmarks, decisively outperforming models trained on TaskCraft, MegaScience, and MiroVerse datasets.
- On HLE, AgentFrontier-30B-A3B achieves 28.6% accuracy, surpassing several proprietary research agents and even larger models.
- The ZPD Exam results reveal a clear stratification of agentic reasoning, with AgentFrontier-trained models achieving near-saturation in the emergent mastery zone.
- BoN analysis demonstrates a substantial gap between pass@1 and pass@8, indicating that the dataset is neither trivial nor unsolvable, and that RL-based exploration could further unlock agentic potential.
Implications, Limitations, and Future Directions
AgentFrontier demonstrates that principled, ZPD-guided data synthesis is highly effective for cultivating advanced reasoning and tool-use in LLM agents. The framework's adversarial calibration ensures that training data is optimally challenging, supporting both imitation and reinforcement learning paradigms. The self-evolving ZPD Exam provides a robust, contamination-resistant benchmark for tracking progress at the capability frontier.
However, the current operationalization of ZPD is binary, lacking graduated scaffolding. The reliance on imitation learning constrains exploration, and the agent's toolset is static, limiting its ability to create or compose new tools. Future work should address these limitations by developing tiered scaffolding protocols, integrating RL for policy improvement, and enabling dynamic tool creation and composition.
Conclusion
AgentFrontier establishes a scalable, theoretically grounded paradigm for expanding the reasoning and problem-solving capabilities of LLM agents. By synthesizing data precisely at the model's developmental frontier and providing a dynamic benchmark for evaluation, the framework sets a new standard for data-driven progress in agentic AI. The strong empirical results and diagnostic insights highlight the necessity of ZPD-guided synthesis for the next generation of autonomous, research-capable language agents.

