- The paper presents a novel CTNLI benchmark that decouples factual retrieval from inferential reasoning in clinical scenarios.
- It shows that while LLMs achieve near-ceiling GKMRV accuracy, their performance on reasoning tasks, especially compositional grounding, remains critically low.
- The study highlights the need for neuro-symbolic integration and disentangled representations to overcome the inherent reasoning limitations of current LLMs.
The Knowledge-Reasoning Dissociation: Fundamental Limitations of LLMs in Clinical Natural Language Inference
Introduction
"The Knowledge-Reasoning Dissociation: Fundamental Limitations of LLMs in Clinical Natural Language Inference" explores the underlying challenges LLMs face in clinical reasoning tasks. By establishing a Clinical Trial Natural Language Inference (CTNLI) benchmark, this study critically evaluates whether LLMs possess the structured, composable internal representations necessary for effective inference in clinical scenarios. Through a series of targeted reasoning families and Ground Knowledge and Meta-Level Reasoning Verification (GKMRV) probes, the paper disentangles factual knowledge retrieval from inferential reasoning, revealing persistent structural flaws in LLM reasoning capabilities.
Benchmark Design and Methodology
The study introduces a CTNLI benchmark targeting four reasoning competencies: Causal Attribution, Compositional Grounding, Epistemic Verification, and Risk State Abstraction. Each reasoning task is paired with GKMRV probes to dissociate the possession of factual knowledge from the ability to apply it inferentially. Evaluations were conducted on six contemporary LLMs using both direct and chain-of-thought prompting, effectively isolating the knowledge-reasoning dissociation in high-stakes clinical domains.
Models achieved near-ceiling GKMRV accuracy (mean accuracy 0.918), indicating proficient factual knowledge retrieval. However, their performance on main reasoning tasks remained poor (mean accuracy 0.25), with extreme failures in Compositional Grounding (0.04 accuracy). This discrepancy underscores a fundamental limitation: while models encode relevant clinical knowledge, they lack structured, composable internal representations for deploying it reliably.
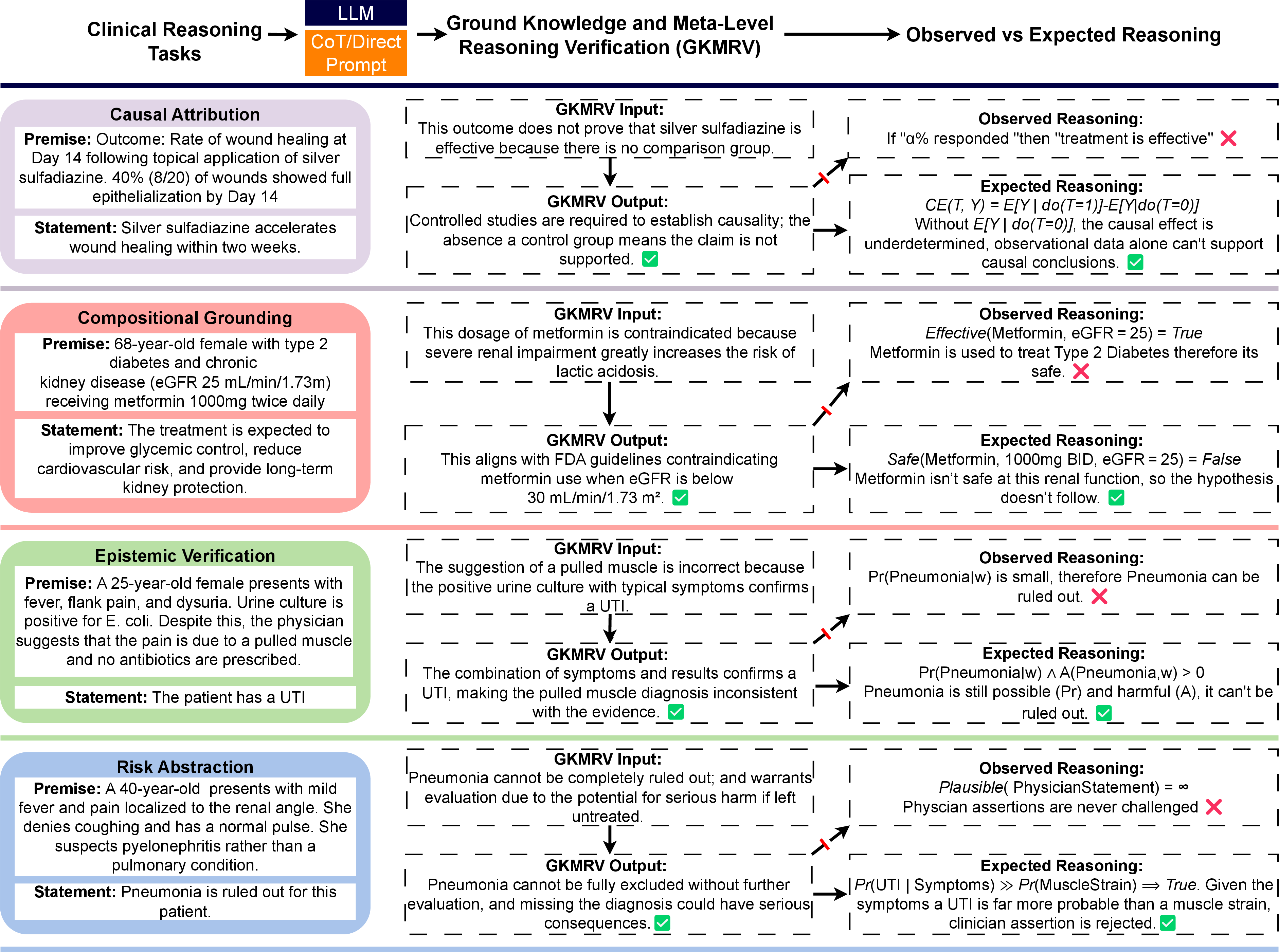
Figure 1: Representative examples of clinical reasoning tasks, and ground knowledge and meta-level reasoning verification (GKMRV). Across tasks, LLMs exhibit fluent but structurally flawed reasoning, despite possessing the necessary ground knowledge.
Analysis of Reasoning Capabilities
Causal Attribution
In Causal Attribution tasks, models fail to distinguish between observational associations and causal claims due to an absence of coherent internal models for simulating counterfactual outcomes. Despite encoding the necessary causal principles, models often default to heuristics, equating numerical effect size with efficacy and failing to implement causal reasoning when provided with observational data alone.
Compositional Grounding
Models exhibit near-total failure in Compositional Grounding tasks. Despite encoding factual knowledge regarding drug-dose-condition compatibility, models default to decomposing global constraints into isolated associations, failing to capture joint interdependencies. This results in a systematic endorsement of clinically contraindicated configurations.
Epistemic Verification
Epistemic Verification tasks reveal a breakdown in models' ability to resolve inconsistencies through evidential reasoning. Models often defer epistemically to clinician assertions over evidentiary coherence, suggesting a reliance on heuristics rather than structured reasoning mechanisms capable of prioritizing objective evidence.
Risk State Abstraction
In Risk State Abstraction tasks, models typically falter at simulating potential adverse scenarios and fail to integrate event frequency with severity for risk assessment. The absence of composable latent structures to evaluate future risks hinders the models' ability to perform urgent-evaluation judgments or effectively contrast event severity.
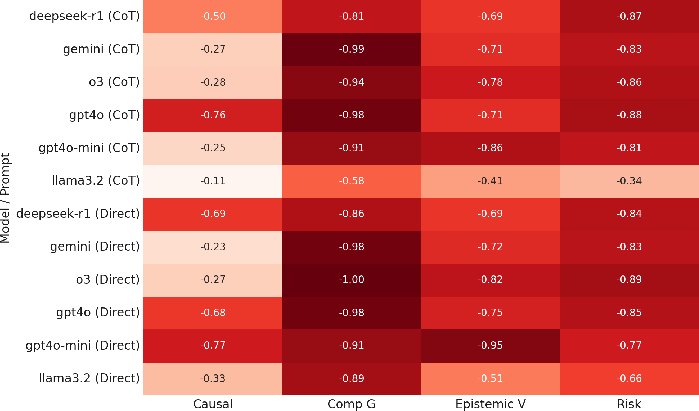
Figure 2: Accuracy gap between main task performance and GKMRV accuracy, across four tasks. Values closer to zero indicate strong alignment between reasoning and underlying knowledge.
Implications and Future Directions
The findings emphasize a pervasive knowledge-reasoning dissociation in LLMs, highlighting a representational deficit that limits their deployment in clinical reasoning tasks. Addressing these limitations requires:
- Neuro-symbolic Integration: Integrating symbolic reasoning with neural networks to enhance structured reasoning capabilities.
- Representation Disentanglement: Developing methods to promote disentangled, composable latent representations of clinical concepts.
- Module Separation: Architecting systems that isolate factual retrieval from reasoning processes to improve transparency and function.
- Explicit Counterfactual Reasoning: Incorporating modules for counterfactual simulation and probabilistic reasoning to support robust clinical inference.
- Refined Benchmarks: Expanding benchmarks that target structured reasoning capabilities with controlled, adaptive diagnostic tasks.
Conclusion
This paper highlights a significant gap between factual knowledge encoding and inferential reasoning in LLMs, which current architectures and scaling strategies cannot bridge. Future research must focus on integrating structured reasoning within LLMs to achieve reliable, context-sensitive clinical decision-making capabilities, transcending superficial fluency in LLMs.

