- The paper demonstrates that integrating a critic model to provide detailed natural language feedback significantly enhances LLM agents' decision-making.
- It outlines a two-stage methodology where an actor model refines actions based on structured critiques during iterative supervised learning.
- Experimental results show that CGI outperforms traditional methods, highlighting its practical benefits in dynamic, interactive environments.
Enhancing LLM Agents via Critique-Guided Improvement
The paper "The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement" introduces a novel framework termed Critique-Guided Improvement (CGI), aimed at enhancing the performance of LLM-based agents through iterative refinement using natural language critiques. This framework involves two main entities: an actor model that explores the environment and a critic model that provides detailed feedback. The research explores the effectiveness of CGI in interactive environments and demonstrates its superiority over existing methodologies.
Critique-Guided Improvement Framework
The CGI framework operates under a two-player paradigm where the actor model proposes multiple actions and the critic model evaluates these actions by providing structured feedback. The feedback consists of critiques and actionable revision suggestions, enabling the actor to refine its decision-making process iteratively. This approach involves two main stages:
- Critique Generation:
The critic model is trained to evaluate actions based on predefined dimensions such as contribution, feasibility, and efficiency. It generates critiques that guide the actor in improving its actions.
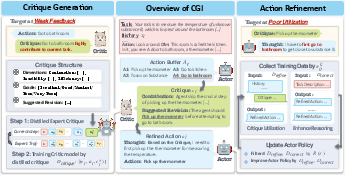
Figure 1: An overview of CGI, illustrating the interaction of the actor and critic models.
- Action Refinement: In this stage, the actor employs the critiques to enhance its refinement capability through iterative supervised fine-tuning. This not only improves reasoning but also enhances the integration of external feedback.
Experimental Results
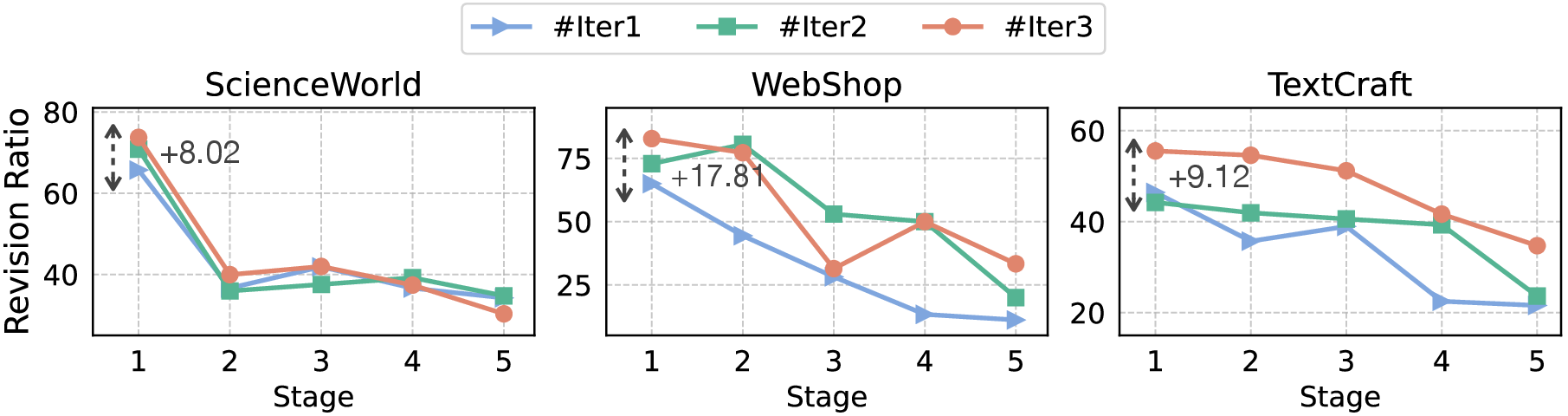
CGI was tested in three interactive environments, revealing its performance surpasses traditional approaches that rely primarily on numerical feedback or untrained self-critiques. The results demonstrated significant improvements in agent performance, with the trained critic model outperforming GPT-4 as a feedback provider.
Key Findings
Methodology and Implementation
The implementation of CGI involves training both critic and actor models using datasets generated from expert models in designated environments. The critic model employs a supervised learning approach to generate critiques, while the actor model undergoes multiple refinement iterations to optimize feedback utilization.
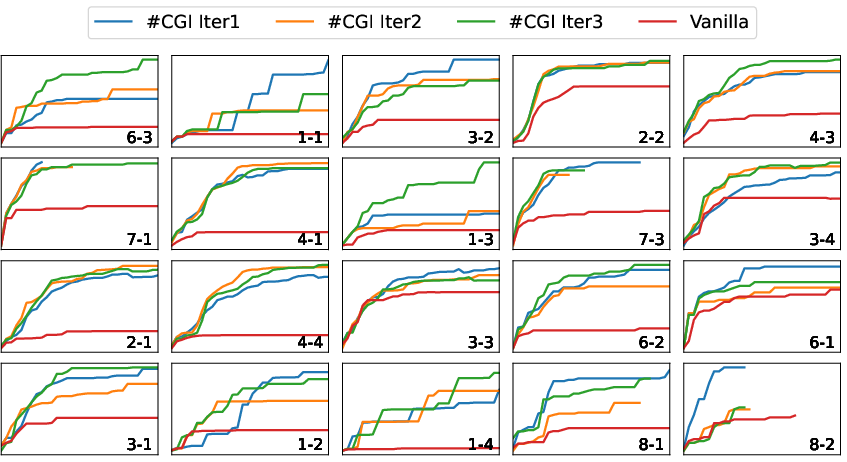
Figure 3: Trajectory visualization highlighting the improved score trajectory of CGI compared with baseline models.
Implications and Future Work
The findings from this research underline the potential of integrating detailed natural language criticism into LLM-based agent frameworks, providing a robust mechanism for action refinement and reasoning enhancement. Future research efforts could focus on exploring further minimization of policy misalignment and optimizing critique integration strategies to further enhance agent adaptability in diverse environments.
Conclusion
By leveraging structured critiques and iterative action refinement, the CGI framework provides actionable, context-specific guidance that significantly enhances LLM agents' decision-making processes. These findings not only highlight the efficacy of CGI in improving agent performance across various tasks but also chart a new course for future developments in AI-driven agentic roles within complex environments.