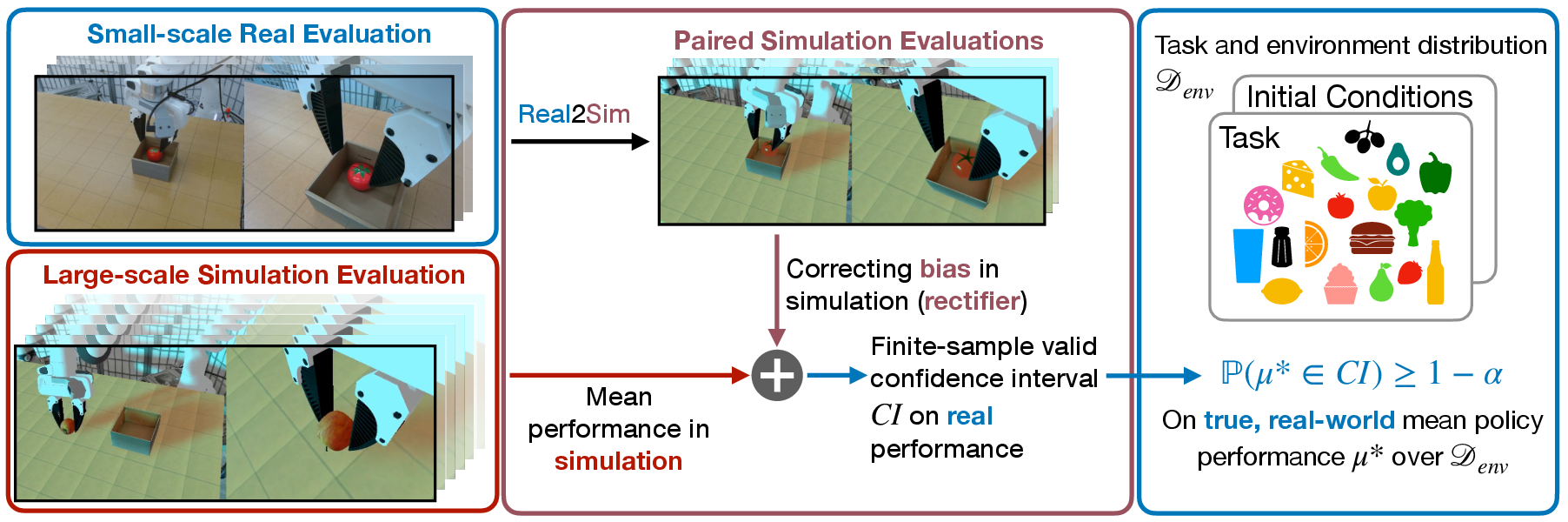
Reliable and Scalable Robot Policy Evaluation with Imperfect Simulators
Abstract: Rapid progress in imitation learning, foundation models, and large-scale datasets has led to robot manipulation policies that generalize to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on mean policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned (\pi_0) on a joint distribution of objects and initial conditions, and find that our approach saves over (20-25\%) of hardware evaluation effort to achieve similar bounds on policy performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a problem in robotics: how to judge if a robot’s “policy” (its way of deciding what to do) will work well in the real world. Testing on real robots is slow and expensive, but testing in simulation (like a very realistic video game) is fast and cheap. The catch is that simulations are never perfect copies of reality. The authors introduce a method called SureSim that mixes a small number of real robot tests with a large number of simulated tests to give reliable, statistically sound estimates of how well a robot will perform in the real world.
What questions does the paper ask?
The paper focuses on simple, practical questions:
- Can we trust conclusions about real-world robot performance if we combine a few real tests with many simulated tests?
- How many real tests can we save by using this smarter mix?
- When does simulation help, and when does it not?
How does the method work?
Think of this like preparing for an exam:
- Real-world robot tests are like the actual exam: accurate but limited because they’re hard to run.
- Simulation tests are like practice tests: easy to run many times, but not perfect.
The authors use a statistical trick called Prediction Powered Inference (PPI):
- They run paired tests: for the same task setup, they run the policy once in the real world and once in simulation.
- These pairs let them measure the “bias” of simulation—how simulation predictions differ from real outcomes.
- Then they run lots more simulations on different tasks and use the measured bias to “rectify” (correct) the simulated results.
They compute a confidence interval for the robot’s average performance:
- A confidence interval is a range like “we are 90% confident the true average success rate is between 0.65 and 0.75.”
- Importantly, their intervals are valid even with small numbers of real tests (this is called “finite-sample validity”), so you don’t need hundreds of hardware runs to trust the results.
To make this work in practice, they:
- Map each real test setup to a matching simulation setup (same robot arm, cameras, table surface, object size, lighting).
- Use a “rectifier” term: the average difference between real and simulated outcomes across the paired tests. This corrects the big batch of simulations.
- Use a modern statistical method (WSR) designed to produce valid confidence intervals without assuming the data follow a particular shape or pattern.
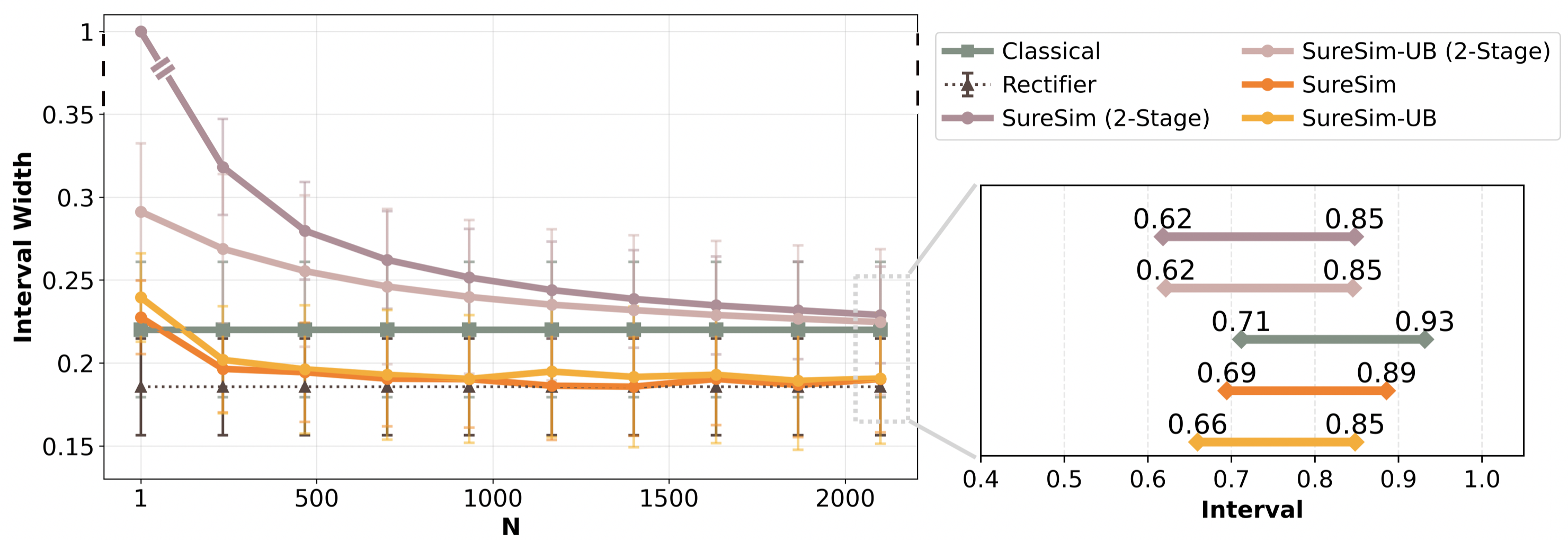
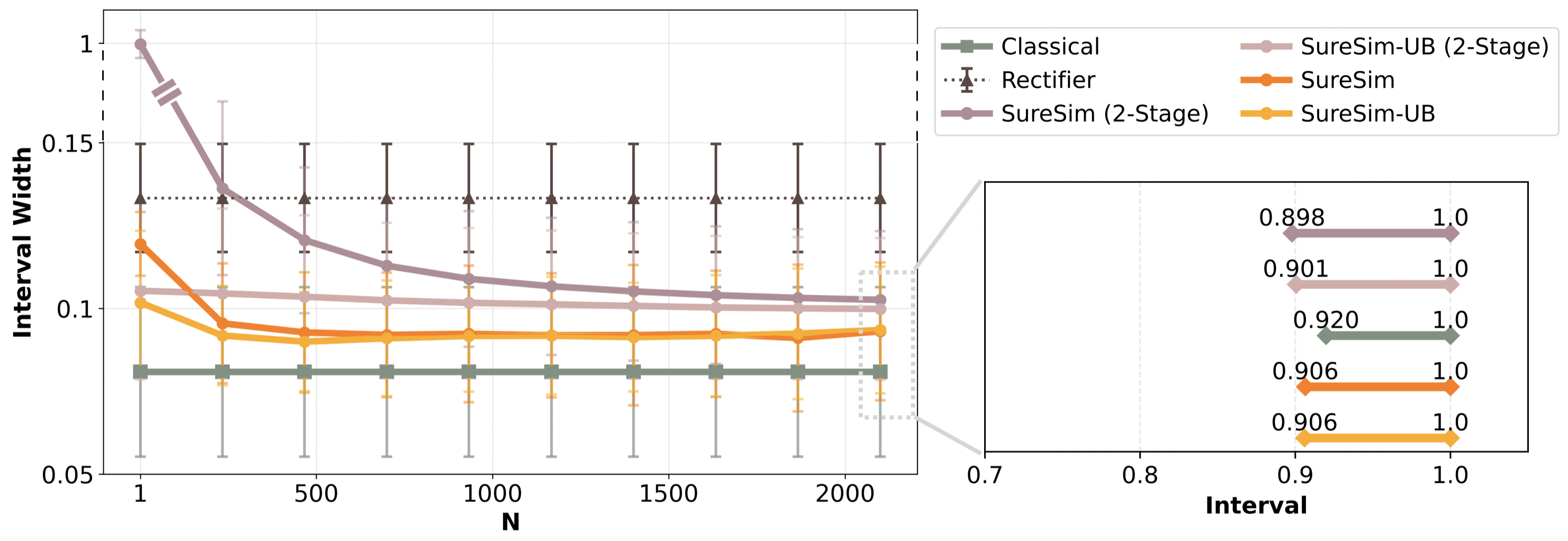
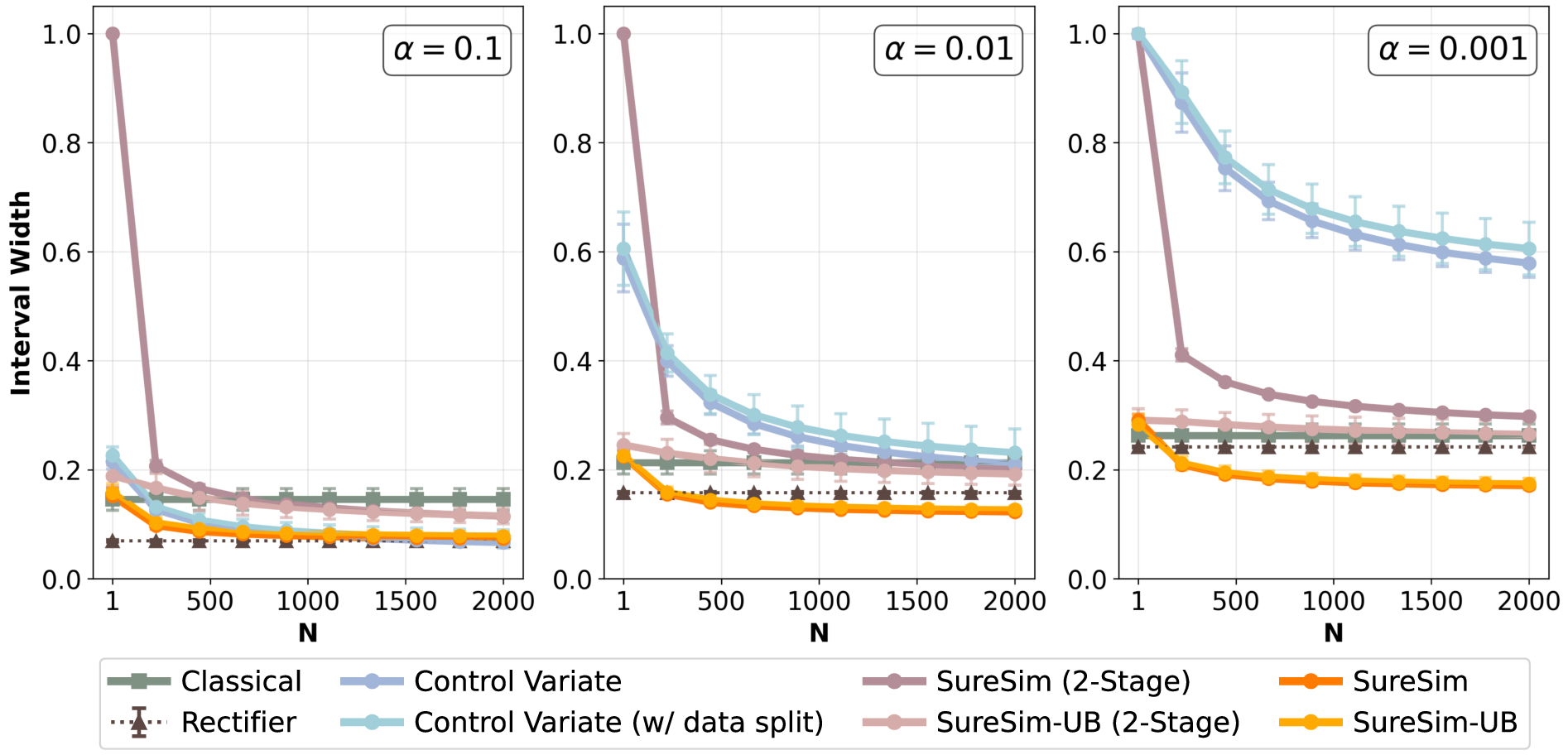
They compare their approach (SureSim) against a baseline that uses only real tests (“Classical”), and also discuss a related method (“Control Variate”) that is tighter in some cases but is not guaranteed to be statistically valid with limited data.
What did they test, and how?
They tested two types of robot manipulation policies (ways of controlling a robot arm):
- A “diffusion policy” trained on one task: pick up a tomato and put it on a plate. Then they checked if it generalizes to many different objects.
- A generalist policy called π₀, fine-tuned on instructions like “put <object> into the box,” for seven objects.
To build realistic simulations, they:
- Created 3D models of real objects from single photos using a tool called Meshy.
- Calibrated the simulated robot, cameras, lighting, and table textures to match the real lab setup using the ManiSkill3 simulator.
- Scored each attempt with a partial success score from 0 (no grasp) up to 1 (complete success), so they could measure shades of success, not just pass/fail.
They also took steps to reduce the simulation–real gap:
- Used the same random “seed” (to keep behavior comparable).
- In simulation, averaged performance over many slightly varied starting positions near each real test’s setup, which makes the simulation estimate more stable.
Main findings
Here are the key takeaways:
- When simulation is reasonably predictive of reality (moderate correlation), SureSim shrinks the confidence intervals compared to using only real tests. In their experiments, it saved about 20–25% of real hardware trials while achieving similarly tight bounds on performance.
- SureSim’s intervals tighten as you add more simulations, up to a logical limit set by the measured simulation–real gap. This prevents overconfidence.
- If simulation is poorly predictive (low correlation), more simulation does not help. In that case, the best option is to rely on the real-only baseline.
- Their method produces intervals that are “Type-I error controlling”—meaning the claimed confidence levels are honest, even with limited data. In contrast, the “Control Variate” method can look impressively tight but may not actually achieve the promised coverage (confidence) in finite samples.
Why is this important?
This research helps robotics move toward reliable, scalable evaluation:
- Faster iteration: You can run many simulations and fewer real tests, while still making trustworthy claims about real-world performance.
- Honest uncertainty: Confidence intervals tell you how sure you can be about a robot’s average performance across many environments.
- Better benchmarking: The approach encourages rigorous testing over diverse tasks without requiring huge amounts of lab time.
In simple terms, SureSim makes it possible to get solid, reliable estimates of how well a robot will do in the real world without needing tons of expensive real-world trials—as long as your simulator is good enough. It also tells you when simulation isn’t good enough yet, so you don’t draw risky conclusions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or left unexplored in the paper, organized to guide future research.
Theoretical foundations and guarantees
- Sensitivity to non-i.i.d. sampling is unexamined: the validity of Prediction-Powered Inference (PPI) and WSR-based intervals under correlated environments, clustered trials, or adaptive sampling (e.g., sequential/anytime decisions) is not analyzed.
- No sample-complexity characterization linking real trials n, simulation trials N, rectifier variance, and significance level α to target interval width; practitioners lack principled guidance for choosing n vs N.
- Risk allocation between δ and α−δ is heuristic; no optimization or data-driven tuning strategies are proposed for finite samples.
- Effects of interval truncation to [0,1] on finite-sample coverage are not analyzed; it is unclear whether truncation preserves Type-I error guarantees in practice.
- The paired data construct averages multiple simulation seeds per real condition; the impact of this aggregation on unbiasedness and variance of the PPI estimator is not derived.
- No explicit decision rule to detect when the sim-to-real gap is “too large” (e.g., rectifier variance exceeds real variance) and to automatically fall back to real-only evaluation.
- Extensions beyond mean estimation (e.g., quantiles, tail risks, worst-case guarantees, subgroup-specific means) are not developed.
Real2Sim mapping and simulator fidelity
- The real2sim mapping g relies on manual calibration and single-image 3D reconstruction; there is no quantitative error model or automated validation of g’s fidelity, nor an analysis of how g’s errors inflate rectifier variance.
- Lack of ablation to identify which simulator components (lighting, shader, camera intrinsics/extrinsics, friction/contact parameters, table texture, robot dynamics) most effectively reduce rectifier variance; no tuning guidelines provided.
- Handling challenging physics regimes (deformables, transparent/reflective materials, thin or flexible objects, high-speed contacts) is not explored; generality to these cases is unknown.
- The real and simulation metrics are mismatched (5-level vs 3-level partial scores); no calibration or mapping between metrics is proposed to reduce systematic bias in the rectifier.
- Robustness to stochasticity misalignment is not quantified; using the “same random seed” does not guarantee matching randomness in the physical world (sensor noise, actuator variability).
- World models (action-conditioned video simulators) are discussed but not evaluated; how PPI behaves under model hallucinations and non-physical dynamics is an open question.
Experimental scope and datasets
- The real distribution D is approximated by ~120 objects; representativeness and coverage of real-world object diversity are not justified; results may not generalize.
- The semantic/geometric filtering of 2100 simulated objects is ad hoc; reproducibility and the impact of filtering choices on correlation and rectifier variance are unstudied.
- Scope is limited to single-robot pick-and-place; generality to other manipulation tasks (assembly, tool use, long-horizon multi-step tasks, deformables), mobile platforms, and multi-robot settings remains untested.
- No end-to-end cost analysis: the time/effort to build sim assets (Meshy models, calibration) and run large N simulations vs. hardware savings is not quantified; practical ROI is unclear.
- Calibration procedures (cameras, robot base, gripper model) are not documented in sufficient detail to reproduce; sensitivity to calibration errors is unknown.
Method design and extensions
- Uniform vs Two-Stage PPI variants are compared empirically only; there is no theoretical comparison or guidance on when to use each under finite-sample constraints.
- Active sampling (adaptive selection of which environments receive real trials) is not explored, despite its potential to reduce rectifier variance and improve efficiency.
- Combining PPI with domain randomization and system identification to improve sim-to-real correlation is proposed but not operationalized; algorithms to tune simulator parameters to minimize rectifier variance are needed.
- Policy comparison (A/B testing) with finite-sample valid PPI-based intervals is not developed; how to compare two policies using shared simulation predictions with controlled Type-I error is open.
- Clustered designs (multiple initial conditions per object) introduce intra-cluster dependence; statistical handling of clustered sampling and hierarchical models is not addressed.
- Control variates with finite-sample Type-I control are lacking; developing CV-based methods that maintain coverage while leveraging simulation remains an open problem.
Robustness, diagnostics, and deployment
- No standardized diagnostic to estimate correlation or rectifier variance before investing in large-scale simulation; practitioners need cheap pilot procedures to predict SureSim’s potential benefit.
- Coverage validation is limited to sim2sim with 400 held-out samples; real-world coverage and robustness under broader conditions (distribution shifts, non-stationarity) remain unverified.
- The impact of interval truncation (intervals pinned at 0 or 1) on decision-making and reported “savings” is not addressed; truncated intervals may mask true uncertainty.
- Handling distribution shift in D over time (non-stationary environments or policy drift) is not considered; methods for ongoing monitoring, re-validation, and recalibration are needed.
- Subpopulation analysis (by object category, size, material) is missing; actionable stratified confidence intervals could identify where simulation helps or harms and guide targeted improvements.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s SureSim framework for reliable, scalable robot policy evaluation using imperfect simulators and prediction-powered inference (PPI). The items are grouped by deployment horizon and mapped to industry, academia, policy, and daily life. Each use case notes sectors, plausible tools/workflows, and key dependencies that affect feasibility.
Immediate Applications
Industry
- Reduce hardware evaluation budgets for robot manipulation policies
- Use SureSim to replace 20–25% of on-robot trials with paired simulation, while retaining finite-sample confidence intervals (WSR) on mean performance.
- Sectors: logistics/warehousing, manufacturing, retail automation, e-commerce fulfillment, service robotics.
- Tools/workflows: SureSim SDK/CLI, ROS 2/Isaac Sim/ManiSkill3 connectors; “Savings calculator” to pick n (real) and N (sim) for a target CI width at significance level α; Rectifier dashboard to track real–sim gap.
- Dependencies: bounded metric in [0,1]; real2sim mapping g(X) available; moderate paired correlation (low rectifier variance); i.i.d. sampling of environments from the target distribution D; simulator capacity to scale N.
- CI/CD gate for robot policy updates
- Integrate SureSim into continuous deployment to block regressions unless the new policy’s CI strictly dominates baseline at α (Type-I error controlled).
- Sectors: software for robotics, MLOps for embodied AI.
- Tools/workflows: Jenkins/GitHub Actions plugin; “UB hedged” mode for conservative gates; A/B evaluation harness combining sequential testing for pairwise comparisons with SureSim for mean-estimation checks.
- Dependencies: reproducible seeding across real/sim runs; stable evaluation distribution; automated reset and logging.
- Vendor acceptance testing and Service Level Agreements (SLAs)
- Third-party labs quantify mean success with certified CIs before purchasing or renewing robot systems or policy upgrades.
- Sectors: procurement for 3PLs, factories, hospitals, hospitality.
- Tools/workflows: “Evaluator-as-a-Service” portals; templated test suites (object sets, initial conditions); standardized reporting with α, interval width, rectifier variance.
- Dependencies: access to representative objects/environments; adequate simulator fidelity for the tasks being purchased.
- Targeted simulator calibration to increase ROI of simulation
- Use rectifier variance and paired correlation to triage where to improve sim (e.g., textures, lighting, friction) and stop when diminishing returns.
- Sectors: simulation platform teams, digital twin groups.
- Tools/workflows: Real2Sim Calibrator; sensitivity analyses over visual/dynamics knobs; correlation monitor.
- Dependencies: knobs to tune sim; rapid asset iteration (e.g., Meshy/Luma asset pipelines); ground-truth pairing.
- Data collection prioritization and experimental design
- Optimize allocation between n real and N sim evaluations to hit CI targets at minimum cost; adaptively sample hard objects/conditions.
- Sectors: applied research, product validation.
- Tools/workflows: budget optimizer for n/N under cost models; active sampling over environment factors; “rectifier lower bound” estimator to forecast achievable CI width.
- Dependencies: cost model for real vs sim; access to large, diverse sim banks (e.g., RoboCASA/Objaverse-like).
- Insurance and risk pricing for automation deployments
- Convert performance CIs into expected loss ranges for underwriting or warranty pricing.
- Sectors: insurance/finance for industrial/service robotics.
- Tools/workflows: mapping CI to downtime/failure cost distributions; policy performance dashboards over time.
- Dependencies: stable mapping from task success to financial loss; representative evaluation distribution.
Academia
- Rigorous, reproducible reporting for robot learning papers
- Report finite-sample CIs on mean performance using SureSim rather than small-N “success rates” alone.
- Sectors: robotics and ML research.
- Tools/workflows: open-source SureSim library; experiment cards with α, CI widths, rectifier stats; artifact checklists.
- Dependencies: availability of a simulator and real2sim mapping; publishing of paired datasets.
- Scalable benchmarking with fewer hardware hours
- Build benchmarks that combine modest real trials with large sim sweeps to characterize generalization across objects and initial conditions.
- Sectors: benchmark consortia and robotics testbeds.
- Tools/workflows: curated object repositories and IC grids; batch sim execution; uniform vs two-stage PPI recipes.
- Dependencies: representative object/scene banks; consistent policies and seeding.
- Methodological studies on real–sim gap
- Use rectifier variance as a quantitative target to compare sim platforms, world models, rendering quality, dynamics fidelity, and policy sensitivity.
- Sectors: sim research, model-based robotics.
- Tools/workflows: rectifier ablation suites; correlation vs cost trade-off curves.
- Dependencies: access to multiple sim stacks; consistent evaluation metrics.
Policy and Standards
- Minimum evaluation standards for publication and benchmarks
- Encourage/require finite-sample CIs with declared α and n/N; discourage claims from 20–40 trial aggregates without error control.
- Sectors: academic venues, benchmark maintainers.
- Tools/workflows: submission checklists; reporting templates with SureSim outputs.
- Dependencies: community buy-in; reviewer/organizer guidance.
- Procurement guidelines for public-sector robotics
- Include CI-based acceptance criteria for hospital, municipal, and education deployments (e.g., “mean success ≥ X with 90% CI width ≤ Y”).
- Sectors: healthcare facilities, public works.
- Tools/workflows: standardized test catalogs per task class; independent evaluation labs.
- Dependencies: legal procurement frameworks; access to evaluation facilities.
Daily Life
- Maker labs and education kits for reliable robot testing
- Schools and makerspaces use low-cost rigs plus sim to teach statistically sound evaluation with limited hardware time.
- Sectors: education, community labs.
- Tools/workflows: step-by-step SureSim tutorials; classroom-ready object sets; cloud sim credits.
- Dependencies: basic robot hardware; student-friendly simulators and asset pipelines.
Long-Term Applications
Industry
- Certification and compliance pipelines built on PPI
- Formalize “statistically assured performance” labels for classes of tasks (ISO/IEC-style certification leveraging SureSim CI guarantees).
- Sectors: industrial robotics, medical/assistive robotics, autonomy.
- Tools/workflows: accredited test facilities; standardized distributions D per use case; digital audit trails.
- Dependencies: standard bodies’ adoption; robust mapping from D to real operations.
- Digital twin ecosystems with automated real2sim mapping
- Continuous ingestion of real environments to maintain high-correlation simulators; automated assetization of new objects (scan-to-sim).
- Sectors: smart factories, retail, logistics networks.
- Tools/workflows: auto-calibrators for textures/lighting/friction; world model–assisted simulation for rapid scene bootstrapping.
- Dependencies: scalable asset pipelines; privacy/IP handling for captured environments; compute for large N.
- Post-deployment monitoring and rollback gates
- Online PPI: use field telemetry as “gold” and digital twin predictions as “proxy” to detect drift and trigger rollbacks.
- Sectors: operations at scale (fleets of arms/AMRs).
- Tools/workflows: streaming rectifier tracking; risk dashboards; automated budget allocation for on-robot audits.
- Dependencies: representative sampling during operations; robust logging/telemetry; controls for distribution shift.
- Simulation-driven red teaming and targeted hard-case generation
- Actively generate environments that maximize rectifier or failure probability to uncover weaknesses pre-deployment.
- Sectors: QA, safety engineering.
- Tools/workflows: adversarial environment generators; coverage metrics linked to CI gaps; PPI for tail-risk (quantile) metrics.
- Dependencies: generative sim tools with controllable physics/visuals; extension of PPI to quantiles/tails.
Academia
- Next-generation benchmarks with massive, paired real–sim repositories
- Thousands of real objects with matched 3D assets; standardized IC lattices; cross-lab comparability at scale.
- Sectors: community infrastructure.
- Tools/workflows: shared datasets; common evaluation servers; federated hardware evaluators.
- Dependencies: funding for data collection; community governance; IP and safety considerations.
- Theoretical extensions beyond mean estimation
- PPI with finite-sample guarantees for quantiles, CVaR, time-correlated trials, sequential/anytime settings, and off-policy evaluation.
- Sectors: statistics for ML/robotics.
- Tools/workflows: new estimators and guarantees; open-source reference implementations.
- Dependencies: advances in concentration/betting frameworks; validation on synthetic and real data.
- Cross-domain adaptation (surgical, agricultural, construction robotics; autonomous driving)
- Adapt SureSim where sim exists but is imperfect; certify domain-specific metrics (e.g., tissue interaction, crop handling).
- Sectors: healthcare, agriculture, construction, mobility.
- Tools/workflows: domain simulators and real2sim mappers; task-specific bounded metrics.
- Dependencies: credible simulators and paired datasets; domain expertise; regulatory alignment.
Policy and Standards
- Regulatory frameworks referencing statistically valid CIs
- Pre-market approvals and periodic re-certifications that rely on PPI-based evidence of performance with explicit α.
- Sectors: FDA-like pathways for medical robotics, workplace safety regulators.
- Tools/workflows: conformity assessment protocols; audit tooling; public reporting of CI and sampling plans.
- Dependencies: legal codification; stakeholder engagement; independent labs.
- Liability and transparency norms tied to evaluation evidence
- Contracts allocate liability based on documented CI-backed performance envelopes; consumer transparency labels.
- Sectors: legal, insurance, consumer protection.
- Tools/workflows: standardized disclosures; model cards with CI; incident analyses referencing rectifier trends.
- Dependencies: policy adoption; public understanding of statistical guarantees.
Daily Life
- Consumer reliability grades for home/service robots
- “Task reliability index” on packaging and product pages based on certified CIs for common tasks (e.g., pick-and-place, dish loading).
- Sectors: consumer robotics.
- Tools/workflows: third-party evaluators; scenario libraries for households; periodic re-evaluation with firmware updates.
- Dependencies: acceptance by manufacturers/retailers; accessible test standards; simple communication of α and CI.
- User-configurable “assurance modes”
- Devices expose settings that trade off performance vs. safety thresholds backed by certified CIs (e.g., conservative mode in clutter).
- Sectors: smart home, eldercare robotics.
- Tools/workflows: on-device policy selectors; cloud-backed updates only if CI improves at α.
- Dependencies: robust local evaluation proxies; safe fallback behaviors; clear UX.
Notes on global assumptions and dependencies across applications
- Validity comes from: bounded metrics, i.i.d. sampling from the target environment distribution, paired real–sim evaluations to estimate the rectifier, and finite-sample CI procedures (e.g., WSR).
- Feasibility hinges on having a reasonably predictive simulator (moderate correlation on paired data); when correlation is low (high rectifier variance), simulation cannot reduce CI width—SureSim will transparently show little or no gain.
- Practical success depends on a workable real2sim pipeline (assetization, calibration, seeding alignment), availability of large simulation corpora, and automation for resets/logging on hardware.
- Distribution shift (e.g., from lab evaluation to deployment context) requires resampling D or revalidating CIs; performance claims are only as good as how representative D is of real operations.
Glossary
- A/B real-world testing: A comparative experimental design that evaluates two policies by running them on hardware and comparing outcomes. "incorporating A/B real-world testing"
- Action-conditioned video prediction models: Generative models that predict future visual observations conditioned on action sequences, used as scalable proxies for physical rollouts. "action-conditioned video prediction models"
- Anytime stopping: A property of statistical procedures that remain valid even if an experiment is stopped at a data-dependent time. "maintaining statistical validity under anytime stopping"
- Bernstein inequalities: Concentration bounds that leverage variance to provide tighter confidence intervals for bounded random variables. "Bernstein inequalities"
- Betting-based methods: Sequential inference techniques that construct valid confidence intervals using gambling/martingale principles. "state-of-the-art betting-based methods"
- Chebyshev’s inequality: A variance-based tail bound used to derive conservative confidence intervals without distributional assumptions. "Chebyshevâs inequality"
- Concentration inequalities: General probabilistic bounds that quantify how a random variable deviates from its mean, enabling finite-sample guarantees. "via concentration inequalities"
- Control variate estimator: An estimator that reduces variance by incorporating a correlated auxiliary variable (e.g., simulation predictions). "variance estimate for the control variate estimator"
- Control variates: A variance-reduction technique that adjusts estimates using the correlation between a target and proxy variable. "control variates procedure"
- Coverage rate: The empirical proportion of times a confidence interval contains the true parameter, used to validate inference methods. "coverage rate of confidence intervals"
- Diffusion policy: A robot control policy that generates actions by sampling from a diffusion model trained on demonstrations. "diffusion policy"
- Foundation models: Large pretrained models (often multimodal) that can be fine-tuned for robotics tasks and generalize across environments. "foundation models"
- Gold-standard labels: Trusted ground-truth outcomes from real-world evaluations used to calibrate or validate proxy predictions. "gold-standard labels are real-world evaluations of a policy"
- Hedged variant: A method that combines multiple confidence intervals (e.g., via union bound) to guard against misspecification. "a hedged variant termed UB"
- i.i.d.: The assumption that samples are independent and identically distributed, critical for many statistical guarantees. "drawn i.i.d from "
- Importance sampling: A technique for estimating expectations under a target distribution by reweighting samples from another distribution. "using importance sampling"
- Minkowski sum: The sum of sets used here to combine separate confidence intervals into a single interval. "taking their Minkowski sum"
- Non-asymptotic mean estimation: Methods that provide confidence intervals valid for finite samples, without relying on large-sample limits. "non-asymptotic mean estimation algorithms"
- Off-policy evaluation: Assessing a policy’s performance using data collected from a different policy or logging process. "off-policy evaluation"
- Prediction powered inference (PPI): A framework that augments limited ground-truth data with plentiful model predictions to tighten valid inference. "prediction powered inference (PPI)"
- Real2Sim: A mapping from real environments to their simulated counterparts to enable paired evaluation. "real2sim pipeline"
- Rectifier: The bias-correction term in PPI that adjusts simulation predictions using paired real outcomes. "The first term is referred as the rectifier"
- Sequential policy comparison frameworks: Statistical testing procedures that compare policies over time while controlling error rates. "Sequential policy comparison frameworks"
- Sim2Sim: An experimental setup that uses two simulator configurations (one treated as “real”) to validate inference methods. "sim2sim setting"
- Simulation-to-real gap: Discrepancies between simulation and the physical world (visual and dynamics) that bias inference if uncorrected. "simulation-to-real gap"
- System identification: The process of estimating physical parameters so that simulation more accurately matches real-world dynamics. "uses system identification"
- Type-I error: The probability of incorrectly concluding an effect (false positive), controlled by the significance level. "Type-I error controlling"
- Uniform PPI estimator: A PPI estimator that mixes the rectifier and simulation averages under a uniform pairing scheme. "the uniform PPI estimator"
- Union bound: A probability bound that upper-bounds the chance of any of multiple events occurring; used to combine guarantees. "a union bound"
- Waudby-Smith and Ramdas (WSR) algorithm: A non-asymptotic, betting-based method that yields valid confidence intervals for bounded variables. "Waudby-Smith and Ramdas (WSR) algorithm"
Collections
Sign up for free to add this paper to one or more collections.