HRM-Agent: Training a recurrent reasoning model in dynamic environments using reinforcement learning
Abstract: The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems. One of HRM's strengths is its ability to adapt its computational effort to the difficulty of the problem. However, in its current form it cannot integrate and reuse computation from previous time-steps if the problem is dynamic, uncertain or partially observable, or be applied where the correct action is undefined, characteristics of many real-world problems. This paper presents HRM-Agent, a variant of HRM trained using only reinforcement learning. We show that HRM can learn to navigate to goals in dynamic and uncertain maze environments. Recent work suggests that HRM's reasoning abilities stem from its recurrent inference process. We explore the dynamics of the recurrent inference process and find evidence that it is successfully reusing computation from earlier environment time-steps.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
HRM-Agent: A simple explanation
What is this paper about?
This paper shows how a small “thinking” AI can learn to find its way through changing mazes by learning from trial and error. The AI, called HRM-Agent, doesn’t get told the correct answer. Instead, it figures things out by trying actions, seeing what happens, and getting rewards when it reaches the goal. The key idea is that the AI keeps a kind of “mental plan” from one moment to the next and reuses it, even as the maze changes.
What questions did the researchers ask?
- Can a small, reasoning-focused AI (HRM) learn to act well in moving, unpredictable worlds, using only rewards (reinforcement learning) instead of step-by-step instructions?
- Can the AI “reuse its thoughts” from earlier moments so it doesn’t have to start planning from scratch every time the world changes a bit?
How did they study it?
The researchers trained the AI in maze worlds where things change over time:
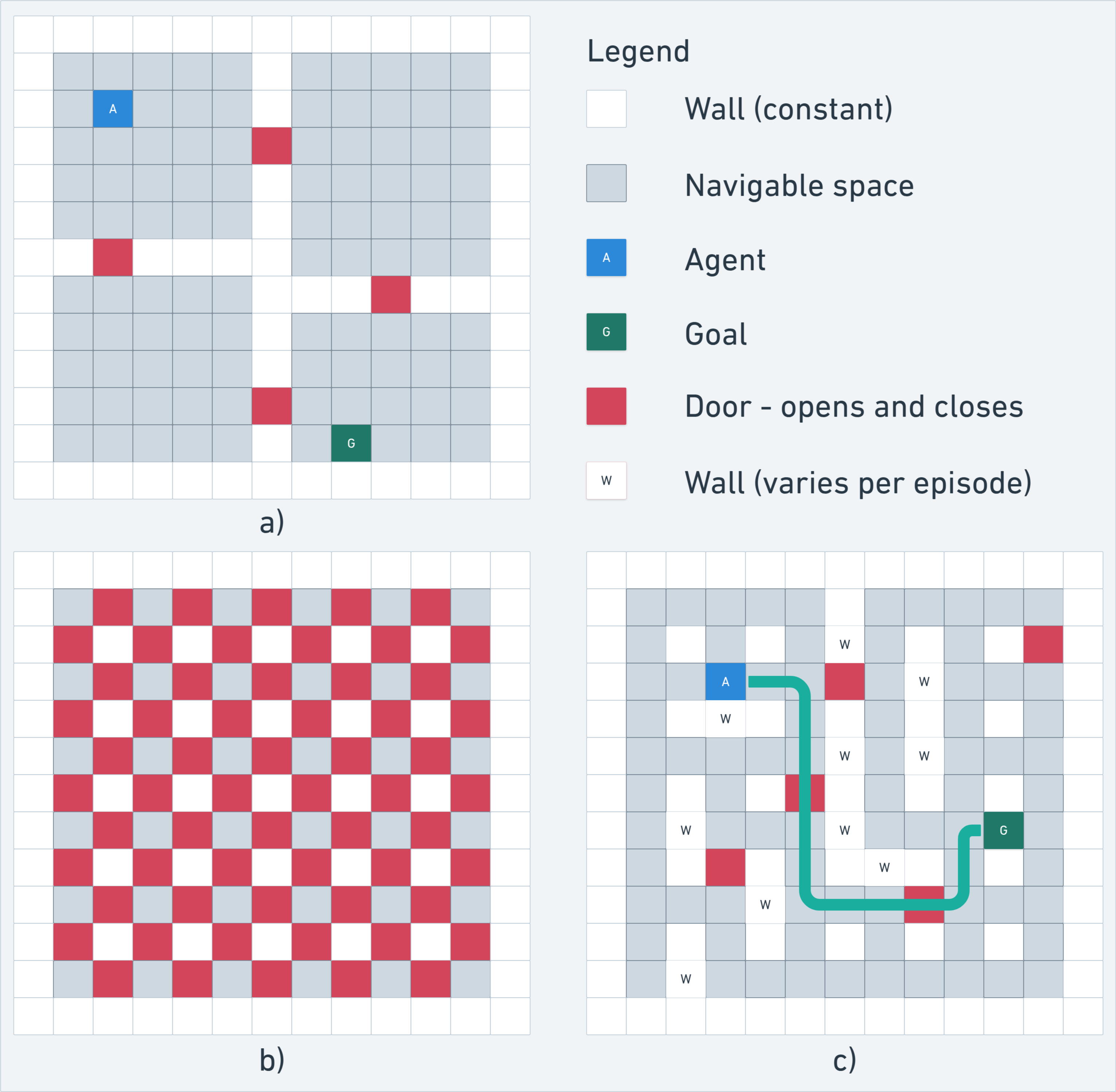
- Four-rooms maze with doors: There are four rooms connected by doorways. One door is always closed, and which door is closed can change randomly. The AI must plan paths and re-plan if a door blocks the way.
- Random dynamic maze: The maze layout is partly random each game, and several doors open and close at random during play. Sometimes there’s no path for a bit, so the AI might need to wait or find another route.
How the AI “thinks”:
- The AI uses a “recurrent” reasoning process. Think of it like taking a few quick “thinking loops” before choosing a move, rather than reacting instantly. This lets it plan a path instead of just stepping blindly.
- It has an internal memory (a hidden state) that holds its current plan. The researchers tested two versions:
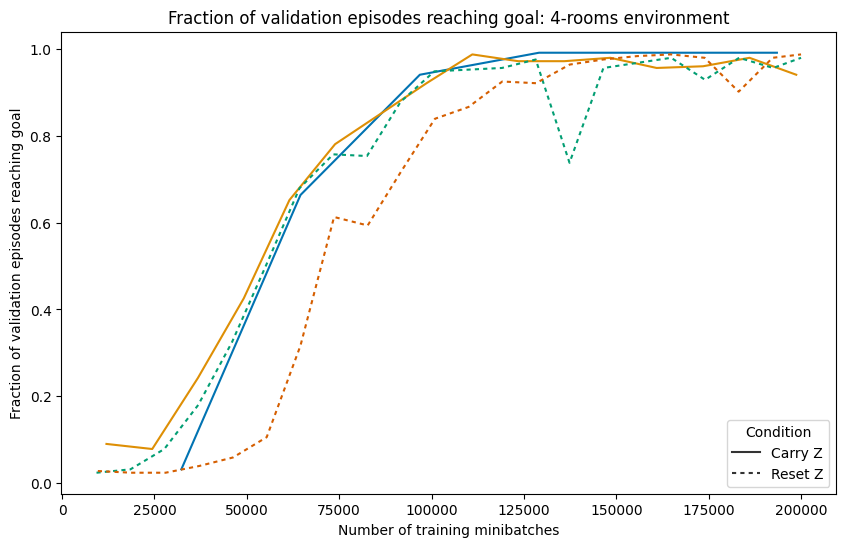
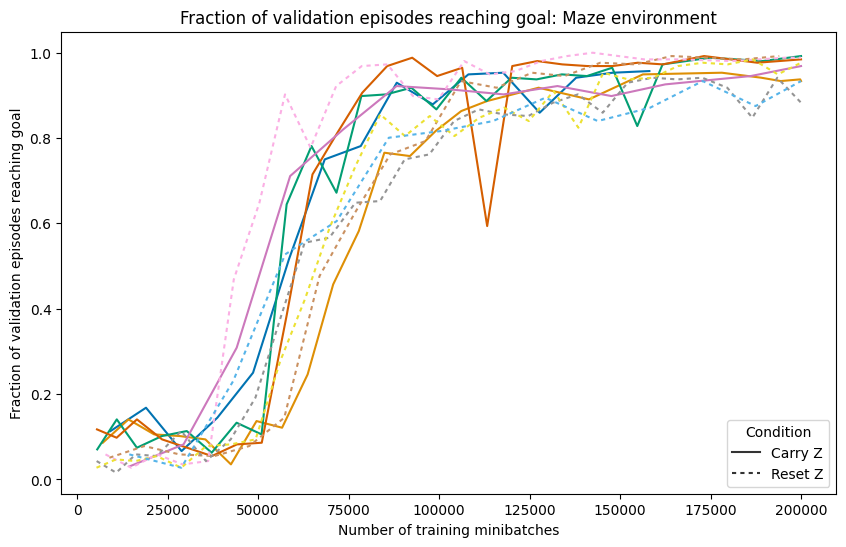
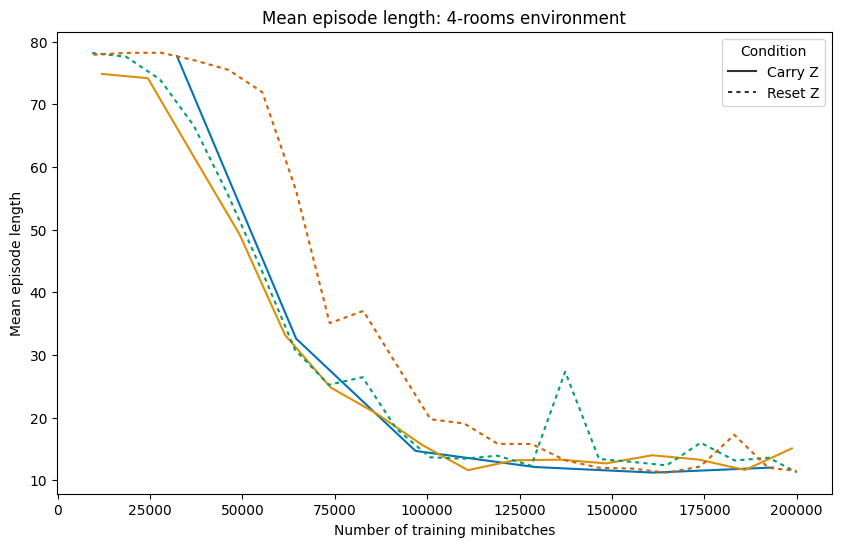
- Carry memory (“Carry Z”): The AI keeps its internal plan from the previous step and updates it as the maze changes—like keeping notes on a whiteboard and erasing only what’s wrong.
- Reset memory (“Reset Z”): The AI throws away its internal plan every step—like wiping the whiteboard clean before every move.
How it learns:
- The AI learns with reinforcement learning (RL), which is like learning by trial and error. When the AI reaches the goal, it gets a reward. If it bumps into walls, it gets a small penalty.
- It uses a DQN-style head to estimate which action will lead to the best future reward. Sometimes it explores by trying random moves to discover better paths.
What did they find, and why is it important?
Here are the main results:
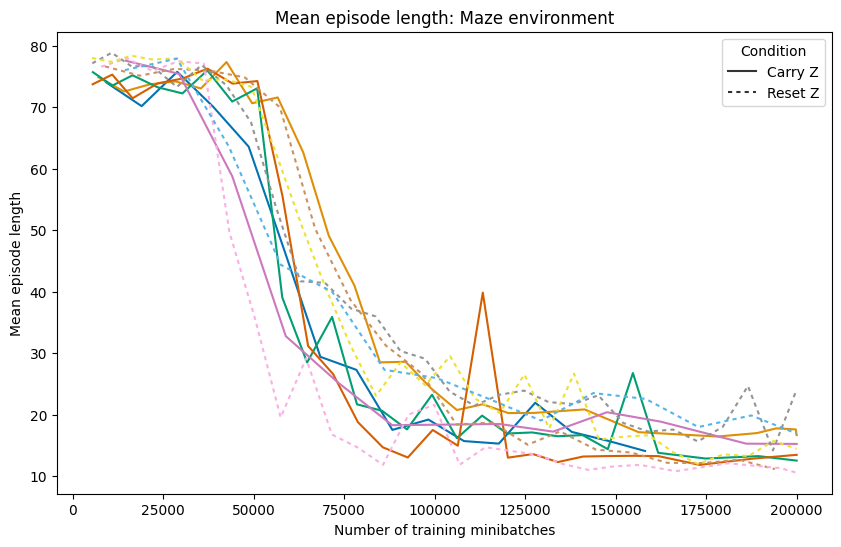
- Strong performance: After training, the AI reaches the goal in about 99% of games in both the four-rooms and the random dynamic maze. It also finds short, efficient paths (close to the best possible average).
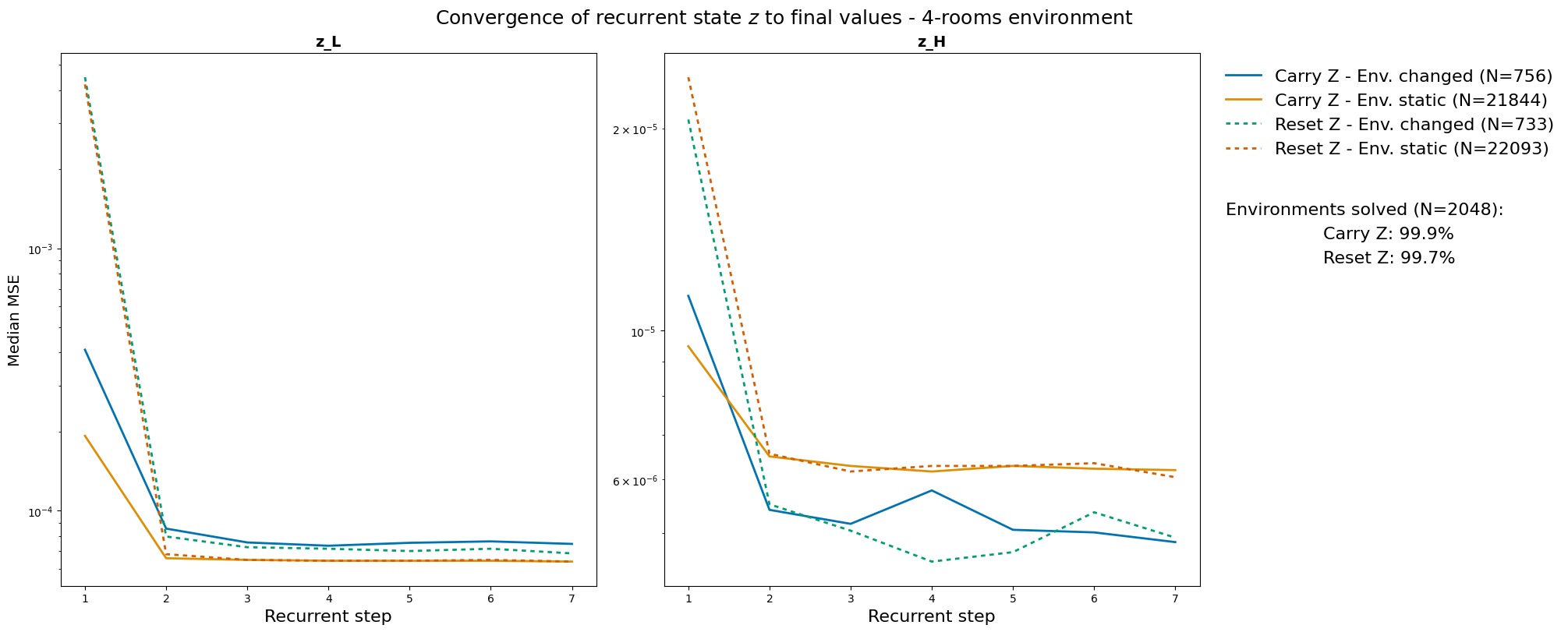
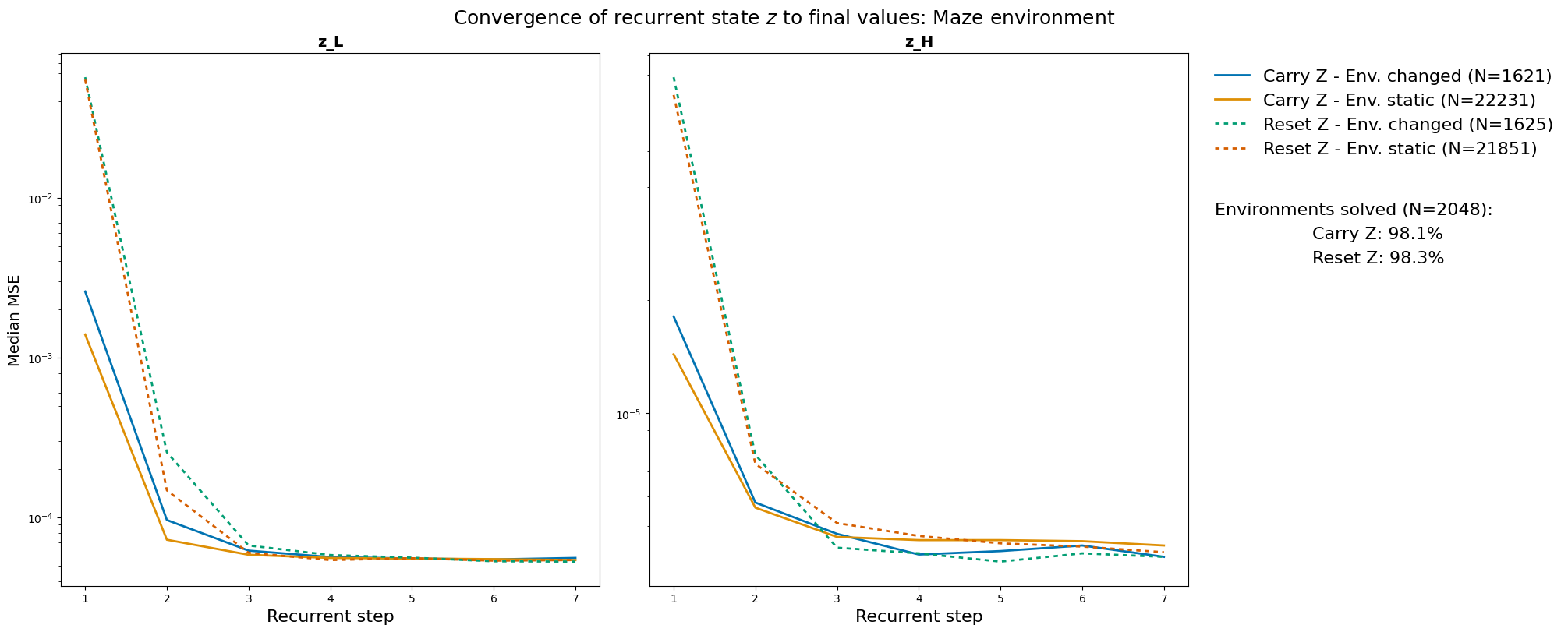
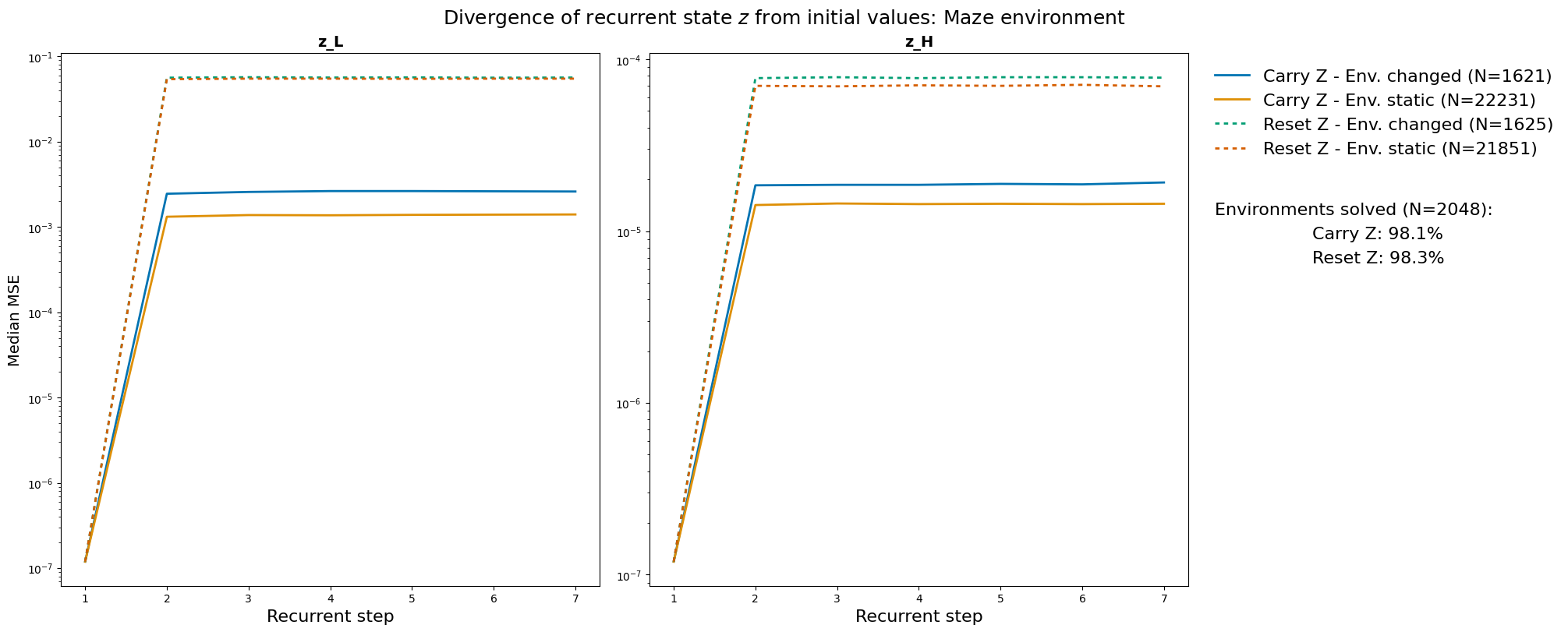
- Reusing thoughts helps: The “Carry memory” version usually learns faster and plans more steadily than the “Reset memory” version. This suggests the AI really does store a plan and improve it over time, instead of starting from zero every move.
- Evidence of real planning: The researchers measured how much the AI’s internal plan changes during its “thinking loops.” When the world hasn’t changed, the plan barely needs updating; when it has changed (like a door closing), the plan changes more—but still starts closer to the final answer if memory is carried over. This is strong evidence the AI is keeping and refining a path in its head.
Why it matters:
- Many real problems are dynamic and uncertain (robots moving around, changing traffic for navigation, games with opponents). This study shows a compact, reasoning-style AI can handle such problems by keeping and updating a plan over time.
- It does this using only rewards (no teacher solutions), which is closer to how real-world learning often works.
What could this lead to?
- Smarter, smaller agents: Compact AIs that plan, re-plan, and stay consistent in changing situations (like robots, game-playing agents, or assistants that act over many steps).
- Faster, more stable reasoning: Reusing “mental work” between moments saves time and can make behavior more reliable.
- Next steps: The authors plan to:
- Restore “adaptive thinking time” so the AI can choose how long to think before acting.
- Try different RL styles (like A2C) and simpler HRM variants.
- Tackle tougher, partially observable worlds (where you can’t see everything at once) and explore continual learning so the agent can keep learning on the fly.
In short, this paper shows that a small, recurrently “thinking” AI can learn to plan and re-plan in moving mazes by carrying its internal plan forward—much like how you’d keep and tweak your notes as a puzzle changes—leading to strong, efficient performance without needing step-by-step supervision.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and unresolved questions that future work could address.
- No experiments in partially observable settings; it remains unknown whether carrying the recurrent state
zenables effective belief-state maintenance and planning under POMDPs (e.g., agent-centric views, limited field-of-view, noisy observations). - Adaptive Computation Time (ACT) is disabled; it is unclear whether an RL-trained HRM-Agent can learn to optimize its “thinking budget” (number of recurrent iterations) and trade reward against inference latency, especially if a compute penalty is introduced.
- Missing baseline comparisons and ablations: there is no head-to-head evaluation against DQN, DRQN/LSTM, TRM, feedforward variants, or non-recurrent HRM, nor ablations isolating the contributions of
HvsLmodules and the “carryz” mechanism. - Environment scope is narrow (small, fully observable grids with dynamic doors); generalization to larger mazes, denser obstacles, continuous action spaces, moving entities, or non-stationary transition dynamics remains untested.
- Sample efficiency and training stability are not quantified (e.g., steps-to-threshold, sensitivity to hyperparameters, target network update rate, replay configuration); statistically robust metrics and analyses are lacking.
- “Carry
z” shows faster convergence but potential low-entropy collapse is only hypothesized; systematic tests of probabilistic carry, noise injection intoz, scheduled resets, or regularization are missing. - The latent state
zis analyzed via MSE to final values, but its contents are not interpreted; no probing or decoding tests (e.g., linear probes for paths, subgoals, door states) demonstrate thatzencodes plans or environment structure. - Gradients are detached across recurrent time and environment time; it is unknown whether TBPTT or other recurrent credit-assignment strategies (including learning through
zacross steps) would improve learning or stability. - Exploration is limited to epsilon-greedy; the impact of advanced exploration (e.g., count-based bonuses, intrinsic motivation, options, hindsight replay) on planning performance is unexplored.
- Only a DQN head is used; on-policy actor–critic variants (A2C/PPO), distributional RL, dueling networks, prioritized replay, or double Q-learning ablations are not evaluated for their impact on reasoning and planning.
- Computational cost and inference latency of multi-iteration reasoning are not reported; there is no analysis of compute–performance trade-offs or scaling of recurrent iterations per step.
- Statistical rigor is limited: 5 seeds per condition without confidence intervals or significance testing; robustness over seeds, environment variations, and randomization is not established.
- Observation encoding is under-specified and not ablated (121 tokens, RoPE); the effect of representation choices (tokenization scheme, spatial encodings, attention windowing) on performance and generalization is unclear.
- Out-of-distribution generalization is unassessed (e.g., larger grids, different door flip probabilities, obstacle statistics, layouts); transfer to novel environment distributions is not measured.
- Reward design is minimal (goal=1, small penalty for walking into walls); sensitivity to reward shaping (e.g., step penalties, waiting costs) and its effects on learned waiting/ detour behavior are untested.
- No curriculum or controlled procedural diversity; whether breadth and difficulty progression in the training distribution drive generalization has not been investigated.
- Long-horizon credit assignment beyond simple mazes is not demonstrated; capability to handle sparser rewards, delayed outcomes, or multi-step subgoal hierarchies (tools, multi-room tasks) remains an open question.
- The specialization of
H(slow) vsL(fast) modules is only inferred from convergence curves; causal tests (module ablations, intervention on updates) to verify hierarchical roles are absent. - Scaling laws are missing: the impact of latent size, number of recurrent steps,
H/Lcycles, transformer heads, expansion factors, and parameter count on performance and sample efficiency is not characterized. - Plan consistency is measured indirectly (latent divergence); trajectory-level metrics (e.g., path edit distance across steps, subgoal consistency, replanning frequency) are not reported.
- Multi-task and transfer learning are untested; whether a single HRM-Agent can adapt across different task families within NLE/MiniHack or transfer to new domains is unknown.
- Robustness to stronger non-stationarity is not assessed (e.g., simultaneous door closures beyond current settings, rule changes mid-episode, dynamic enemies); failure modes and recovery behaviors are not characterized.
- Reproducibility details are incomplete (the hyperparameter table appears truncated; target network update schedule, replay specifics, seeds, code availability not specified); precise replication may be difficult without additional documentation.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s HRM-Agent design, off-policy RL training, and the “carry Z” recurrent-state reuse in fully observable, dynamic environments.
- Edge-ready dynamic path planning for structured indoor environments (sectors: robotics, software, gaming)
- Use HRM-Agent as a lightweight, embedded path planner for cleaning robots, warehouse carts, security patrol bots, or game NPCs in buildings with intermittently blocked corridors and doors.
- Potential tools/products/workflows: ROS node that wraps HRM-Agent; Unity/Unreal plugin for dynamic NPC pathfinding; Gymnasium/MiniHack environment packs for QA and level design with dynamic doors.
- Key dependencies/assumptions: Fully observable maps or accurate occupancy grids; simple discrete action spaces; reward design and safety monitoring; sim-to-real transfer for robotics.
- Baselines and instrumentation for recurrent RL research (sectors: academia, software)
- Adopt the “carry Z” versus “reset Z” ablation and the paper’s latent-state MSE-to-final convergence metric to study plan reuse, stability, and thinking-time budgeting in recurrent agents.
- Potential tools/products/workflows: Open-source evaluation suite that logs z convergence/divergence; Jupyter notebooks for teaching labs; Gymnasium/MiniHack scenarios for reproducible experiments.
- Key dependencies/assumptions: Access to latent states; small recurrent architectures; GPU for reasonable training speeds.
- Curriculum and lab modules for teaching reasoning in RL (sectors: education, academia)
- Use the dynamic maze tasks and recurrent-state analysis to teach practical concepts in POMDPs, memory, plan consistency, and off-policy RL.
- Potential tools/products/workflows: Course labs with ready-to-run configs; instrumented notebooks that visualize z dynamics and episode efficiency.
- Key dependencies/assumptions: Simplified environments; reproducible training pipelines; basic compute resources.
- Plan-consistency monitoring for agentic systems (sectors: software, robotics)
- Integrate the paper’s latent divergence metrics (distance from initial z to final z) into agent control loops to detect plan instability or excessive re-planning under environmental change.
- Potential tools/products/workflows: Runtime instrumentation library; dashboard for monitoring plan stability; alerts when plan divergence exceeds thresholds.
- Key dependencies/assumptions: Access to model internals; recurrent reasoning loop; tolerance thresholds tuned to task.
- Faster learning in dynamic simulators via off-policy replay (sectors: robotics, software)
- Exploit the DQN-style head and replay buffers to reduce exploration cost and recycling of trajectories in training dynamic navigation policies.
- Potential tools/products/workflows: Offline/Batch RL pipelines with HRM-Agent; environment generators for curriculum learning (door probability schedules).
- Key dependencies/assumptions: High-quality replay buffers; reward shaping; careful target-network updates for training stability.
- Procedural level design and dynamic QA in games (sectors: gaming, software)
- Use HRM-Agent alongside A* checks to automatically validate that procedurally generated dynamic levels remain navigable and interesting when obstacles change.
- Potential tools/products/workflows: Level-generation pipeline that includes HRM-Agent regression tests; path variability reports; door-schedule stress tests.
- Key dependencies/assumptions: Integration with content pipelines; designer-defined constraints; robust simulation-to-runtime equivalence.
Long-Term Applications
These applications require further research, scaling, partial observability support, safety validation, or restoration of adaptive compute (ACT), as outlined in the paper’s future work.
- Autonomous mobile robots in complex, partially observable spaces (sectors: robotics, healthcare, logistics)
- Extend HRM-Agent with on-policy A2C/PPO, sensor fusion, sliding-window attention over recent observations, and safety-certified planners for hospitals, factories, and airports.
- Potential tools/products/workflows: ROS stack with mapping and localization; POMDP training suite; safety monitors; sim-to-real transfer protocols.
- Key dependencies/assumptions: Robust perception; reliable localization; standards compliance; partial observability handling; extensive field testing.
- Adaptive compute agents with inference-time thinking budgets (sectors: software, cloud-edge, robotics)
- Restore and train ACT so agents adapt the number of recurrent iterations based on task difficulty and state uncertainty, optimizing latency and energy usage.
- Potential tools/products/workflows: ACT-enabled HRM/TRM agents; runtime controllers that balance accuracy vs. compute; edge/cloud orchestration.
- Key dependencies/assumptions: Stable ACT training; confidence/uncertainty measures; hardware-aware scheduling.
- Continual and few-shot learning for online agents (sectors: academia, robotics, software)
- Pursue streaming RL and CFSL so agents learn new layouts and dynamics on-device without catastrophic forgetting.
- Potential tools/products/workflows: Replay management for streaming data; latent-state regularization; online evaluation frameworks.
- Key dependencies/assumptions: Memory safeguards; retention strategies; real-time updates; benchmarks for continual learning.
- Multi-agent cooperative navigation and crowd-aware planning (sectors: robotics, logistics, smart cities)
- Scale recurrent reasoning to multi-agent coordination with communication, negotiation, and shared corridor constraints.
- Potential tools/products/workflows: Multi-agent RL training; traffic simulators; communication protocols; plan-consistency analytics per agent.
- Key dependencies/assumptions: Robust multi-agent stability; fairness and safety policies; real-time coordination overhead.
- Real-time route optimization in transportation networks (sectors: energy, logistics, mobility)
- Adapt recurrent planning to city-scale networks with road closures, incidents, and time-varying costs; integrate with traffic sensors and digital twins.
- Potential tools/products/workflows: Streaming data ingestion; hierarchical planners (macro/micro routes); ACT-controlled compute on edge nodes.
- Key dependencies/assumptions: Scalable state representations; latency constraints; integration with existing ITS platforms.
- Assistive navigation for people with mobility impairments (sectors: healthcare, daily life)
- Embed recurrent planning in wearables or mobile apps to guide users through dynamic indoor spaces (e.g., doors, elevators, temporary obstacles).
- Potential tools/products/workflows: POMDP guidance engines; obstacle detection; personalized path preferences; privacy-preserving on-device models.
- Key dependencies/assumptions: Reliable sensing; accessibility data; safety assurances; user-centric evaluation.
- Safety certification and governance for dynamic AI planning (sectors: policy, public sector)
- Use plan-stability metrics and latent convergence analyses to define standards for safe deployment in public spaces; audit agent behavior under dynamic changes.
- Potential tools/products/workflows: Conformance tests; audit trails recording z dynamics; certification pipelines.
- Key dependencies/assumptions: Regulatory frameworks; explainability criteria; incident response procedures.
- Agentic LLM systems with embedded recurrent latent planning (sectors: software, productivity)
- Integrate the “carry Z” concept into agentic LLMs that act over multiple steps, maintaining plan memory across tool-use and environment interactions.
- Potential tools/products/workflows: Latent-memory modules; hybrid LLM+HRM controllers; plan-stability dashboards.
- Key dependencies/assumptions: Access to LLM internals or structured latent interfaces; alignment and safety; evaluation beyond static prompting.
- Hierarchical task execution beyond navigation (sectors: robotics, manufacturing)
- Extend recurrent reasoning to tool use, manipulation, and temporal abstraction (options), enabling robust, long-horizon behaviors under uncertainty.
- Potential tools/products/workflows: Hierarchical policies with learned sub-goals; manipulation simulators; ACT-managed subroutine execution.
- Key dependencies/assumptions: Rich sensory-motor stacks; safe manipulation planning; generalization across tasks.
- Digital twins and simulation-based training at scale (sectors: industry, academia)
- Use HRM-like agents within digital twins to stress-test dynamic operations (warehouse layouts, hospital flows), guiding redesign and training.
- Potential tools/products/workflows: Scenario generators; performance analytics; ACT-based compute allocation per scenario complexity.
- Key dependencies/assumptions: Accurate twin fidelity; domain-specific metrics; data integration pipelines.
Glossary
- A* path planning: A heuristic graph search algorithm used to compute shortest paths efficiently. "During maze generation we use A* path planning \citep{hart1968formal} to ensure that at least one path transiently exists between the start and the goal"
- A2C (Asynchronous Advantage Actor-Critic): An on-policy reinforcement learning algorithm using parallel actors and an advantage term to stabilize updates. "We intend to develop an on-policy, A2C \citep{mnih2016asynchronous} model variant."
- Abstraction and Reasoning Corpus (ARC): A benchmark dataset designed to test general reasoning and abstraction capabilities in AI systems. "tasks from the Abstraction and Reasoning Corpus (ARC) \citep{chollet2019measureintelligence}"
- Adaptive Computation Time (ACT): A mechanism that allows a model to adapt the number of recurrent inference steps to task difficulty at test time. "The HRM paper includes a demonstration of automatic, inference-time scaling of computational complexity using the Adaptive Computation Time (ACT) component, which determines the number of recurrent iterations to perform."
- Agentic architectures: AI system designs that structure models as autonomous agents capable of multi-step planning and decision-making. "and
agentic'' architectures such as theAI Scientist'' \citep{lu2024aiscientist}" - Belief state: An internal probabilistic representation of possible environment states maintained under partial observability. "and showed that explicit recurrence can help an agent maintain and update an internal belief state."
- Bootstrapped target values: Targets for value learning computed using current estimates of future returns rather than ground-truth labels. "between the current model's predicted -values for the current environment step and the bootstrapped target values ."
- Chain of Thought (CoT): A prompting technique where models generate intermediate reasoning steps before final answers. "including ``Chain of Thought'' (CoT) \citep{wei2022chain}"
- Deep Q-Network (DQN): A deep learning approach to approximate Q-values for discrete action selection in reinforcement learning. "The HRM output head is replaced with a Deep-Q Network (DQN) head \citep{mnih2015dqn} and actions are selected using an Epsilon-Greedy exploration strategy."
- Deep Recurrent Q-Network (DRQN): A Q-learning variant that incorporates recurrence to handle partial observability by conditioning on history. "DRQN demonstrated improved performance in Atari games"
- Distributional Q-learning: A reinforcement learning approach that models the full distribution of returns rather than just their expectation. "and distributional Q-learning \citep{bellemare2017distributional} have extended the approach to high-dimensional and stochastic settings."
- Double DQN: A method to reduce overestimation bias in Q-learning by decoupling action selection and evaluation across networks. "Double DQNs \citep{vanhasselt2016double}"
- Epsilon-Greedy exploration: An exploration strategy that selects random actions with probability epsilon and greedy actions otherwise. "actions are selected using an Epsilon-Greedy exploration strategy."
- Hierarchical Reasoning Model (HRM): A compact, dual-recurrent architecture designed to perform iterative reasoning with adaptive computation. "The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size"
- Long Short-Term Memory (LSTM): A recurrent neural network architecture that mitigates vanishing gradients and captures long-term dependencies. "by replacing the fully connected layer before the output with an Long-Short-Term-Memory (LSTM) layer \citep{hochreiter1997long}."
- Markov Game: A multi-agent extension of Markov Decision Processes where agents interact strategically in a shared environment. "In a Markov Game such as Chess or Go the state of the board is observable but the actions of the opposing player are unpredictable."
- Mean-square-error (MSE) loss: A regression loss computing the average squared difference between predictions and targets. "The current model is trained to minimize the MSE loss (equation \ref{eqn:loss})"
- MiniHack: A library built on NLE that provides configurable NetHack-based environments for reinforcement learning research. "via the MiniHack \citep{samvelyan2021minihack} and Gymnasium \citep{towers2024gymnasium} libraries."
- Monte Carlo Tree Search (MCTS): A planning algorithm that uses random rollouts and tree expansion to approximate optimal decisions. "AlphaGo \citep{silver2016alphago} used deep reinforcement learning in combination with Monte Carlo Tree Search to demonstrate reasoning and planning over long time horizons."
- NetHack Learning Environment (NLE): A research platform based on the NetHack game for studying complex, partially observable RL tasks. "The maze environments used in this paper are derived from the NetHack Learning Environment (NLE)"
- Off-policy: A reinforcement learning paradigm where the policy being improved differs from the policy used to generate experience. "Therefore, the model is an ``off-policy'' one."
- On-policy: A reinforcement learning paradigm where the same policy is used both to collect data and to update the policy. "We intend to develop an on-policy, A2C \citep{mnih2016asynchronous} model variant."
- Partially Observable Markov Decision Processes (POMDPs): A framework modeling decision-making when the agent cannot directly observe the full state. "Partially Observable Markov Decision Processes (POMDPs) \citep{kaelbling1998pomdp} capture settings where the agent cannot directly observe the full environment state"
- Q-learning: A value-based reinforcement learning algorithm that learns the optimal action-value function via temporal-difference updates. "Q-learning \citep{watkins1992qlearning} is a widely studied off-policy approach to RL."
- Q-values: The expected return of taking a given action in a given state under a particular policy. "which produces -values (expected rewards) for each action."
- Recurrent inference process: An iterative computation procedure where a model refines latent states across multiple steps before output. "Recent work suggests that HRM's reasoning abilities stem from its recurrent inference process."
- Reinforcement learning from AI feedback (RLAIF): A technique that uses feedback from AI systems to shape model behavior via RL fine-tuning. "reinforcement learning from AI feedback (RLAIF) \citep{bai2022constitutional}"
- Reinforcement learning from human feedback (RLHF): An approach that uses human preference signals to guide RL fine-tuning of models. "reinforcement learning from human feedback (RLHF) \citep{christiano2017rlhf}"
- RoPE (Rotary Positional Embeddings): A positional encoding method that injects relative position information via complex rotations in attention. "Positional embedding type & RoPE"
- Tiny Recursive Model (TRM): A compact HRM-derived architecture emphasizing recursive forward processing for reasoning. "More recently, \cite{jolicoeurmartineau2025less} published the Tiny Recursive Model (TRM)."
- Tree-of-Thought (ToT): A reasoning framework where models explore branching intermediate solution paths before committing to answers. "Tree-of-Thought (ToT) exploration \citep{yao2023tree}"
Collections
Sign up for free to add this paper to one or more collections.