Hierarchical Reasoning Model: A Critical Supplementary Material
Abstract: Transformers have demonstrated remarkable performance in natural language processing and related domains, as they largely focus on sequential, autoregressive next-token prediction tasks. Yet, they struggle in logical reasoning, not necessarily because of a fundamental limitation of these models, but possibly due to the lack of exploration of more creative uses, such as latent space and recurrent reasoning. An emerging exploration in this direction is the Hierarchical Reasoning Model (Wang et al., 2025), which introduces a novel type of recurrent reasoning in the latent space of transformers, achieving remarkable performance on a wide range of 2D reasoning tasks. Despite the promising results, this line of models is still at an early stage and calls for in-depth investigation. In this work, we perform a critical review on this class of models, examine key design choices and present intriguing variants that achieve significantly better performance on the Sudoku-Extreme and Maze-Hard tasks than previously reported. Our results also raise surprising observations and intriguing directions for further research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper looks at how AI models reason through problems like Sudoku and mazes. It focuses on a recent model called the Hierarchical Reasoning Model (HRM), which tries to think in a “hidden” way inside the model instead of writing out every step. The authors review HRM critically, run new experiments, and suggest changes that make it work much better. They also show that parts of HRM may not be as special or necessary as they first seemed.
Goals: What questions the paper asks
The paper asks simple but important questions:
- Can we make AI reason better by letting it “think” in its hidden space, instead of generating lots of words or steps?
- Does HRM really need its two-part design (a fast “low-level” module and a slower “high-level” module)?
- If HRM avoids a standard training method for time-based models (called Backpropagation Through Time), what is it actually doing instead?
- Can HRM be improved by using its “stop-when-done” skill not just during training but also during testing?
- Do these ideas help on different types of puzzles, not just Sudoku?
Methods: How the researchers tested their ideas
To keep things clear, here are the main ideas explained with everyday examples:
- Token-space vs. latent-space thinking:
- Token-space is like solving a math problem by writing every step out loud.
- Latent-space is like solving it in your head, then just saying the final answer. HRM tries to do more of this “thinking in its head.”
- HRM’s design (original version):
- HRM has two parts:
- L module (low-level): works fast and handles small steps.
- H module (high-level): works slower and handles big-picture plans.
- It also has a “halting” mechanism called Adaptive Computation Time (ACT). Think of ACT like a built-in timer that lets the model stop when it believes the puzzle is solved, instead of always doing the maximum number of steps.
- What the authors changed:
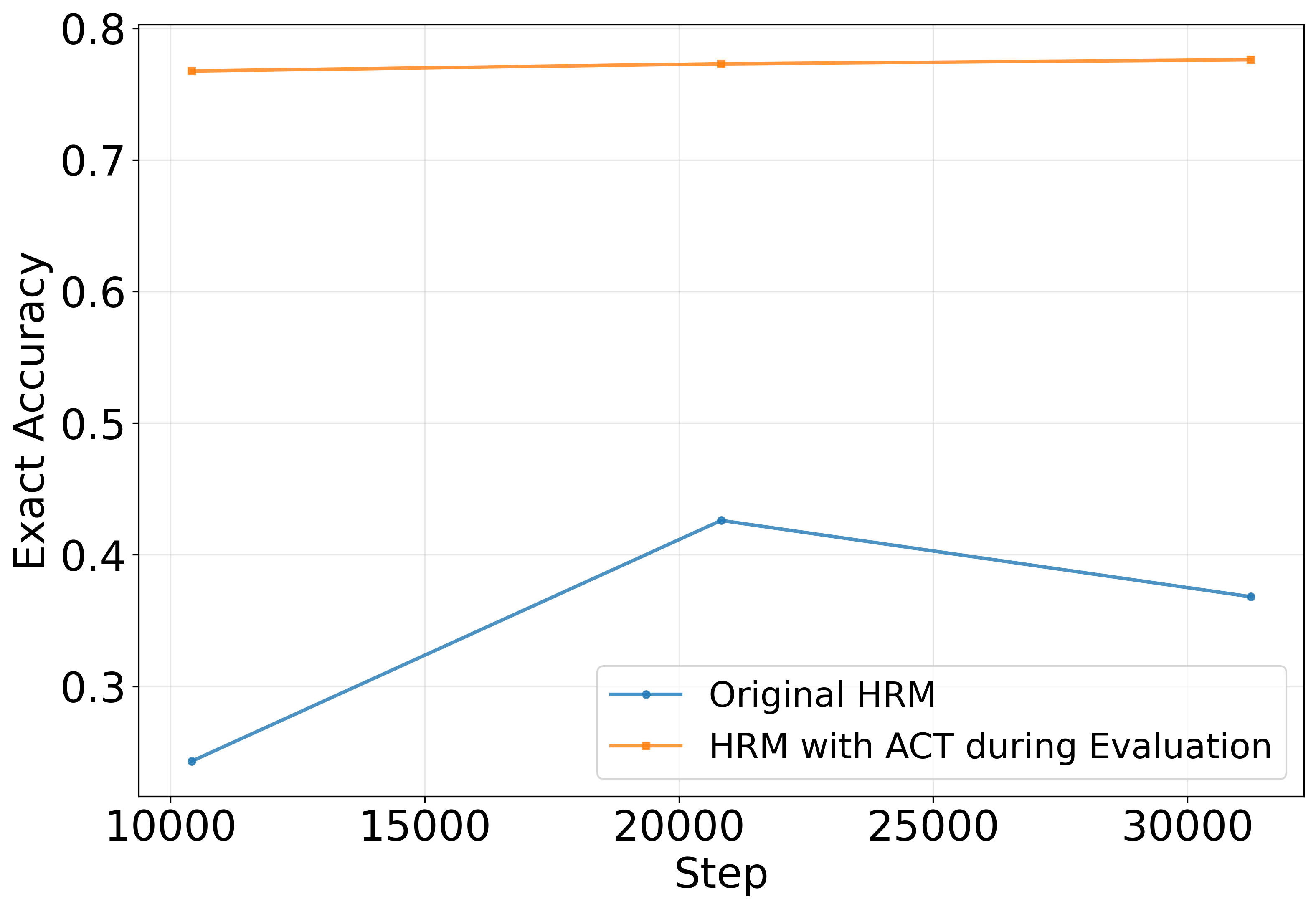
- In the original HRM code, the model learns when to stop during training, but at test time it ignores that and always runs to the maximum steps. That’s like practicing “stop-when-done” but then taking every possible step during the real test—sometimes messing up a correct solution by overthinking.
- The authors fixed this by letting the model actually stop early during testing when it’s confident it’s finished.
- A simpler version of HRM:
- The authors tried removing the H module and just using a stronger L module (an 8-layer transformer). With ACT turned on during testing, this simpler model worked about as well as the original HRM. This suggests the fancy two-part design might not be needed.
- HRM and diffusion models (an analogy):
- Diffusion models clean up noisy pictures step by step, like restoring a blurry photo until it looks clear.
- The authors argue HRM’s training is very similar: it learns how to turn a messy “in-progress” idea into the correct solution in just one or a few steps. In this sense, HRM behaves like a “consistency” or diffusion-style model, but for reasoning instead of images.
Findings: What they discovered and why it matters
The authors report several key results:
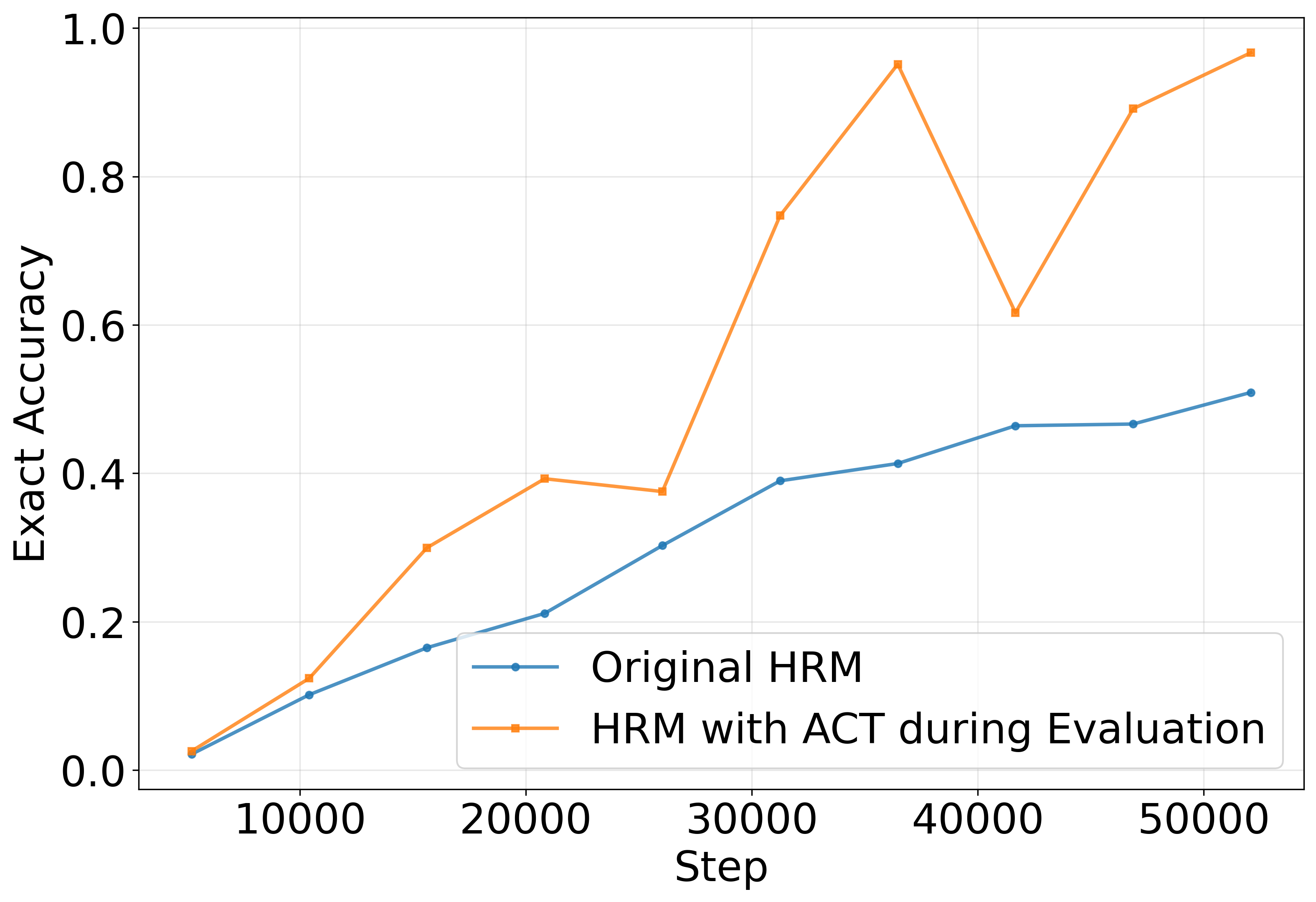
- Using ACT to stop early during testing gives a big boost in accuracy.
- On a very hard Sudoku dataset (“Sudoku-Extreme”), their modified HRM reaches around or above 90% accuracy, much better than the ~55% reported earlier.
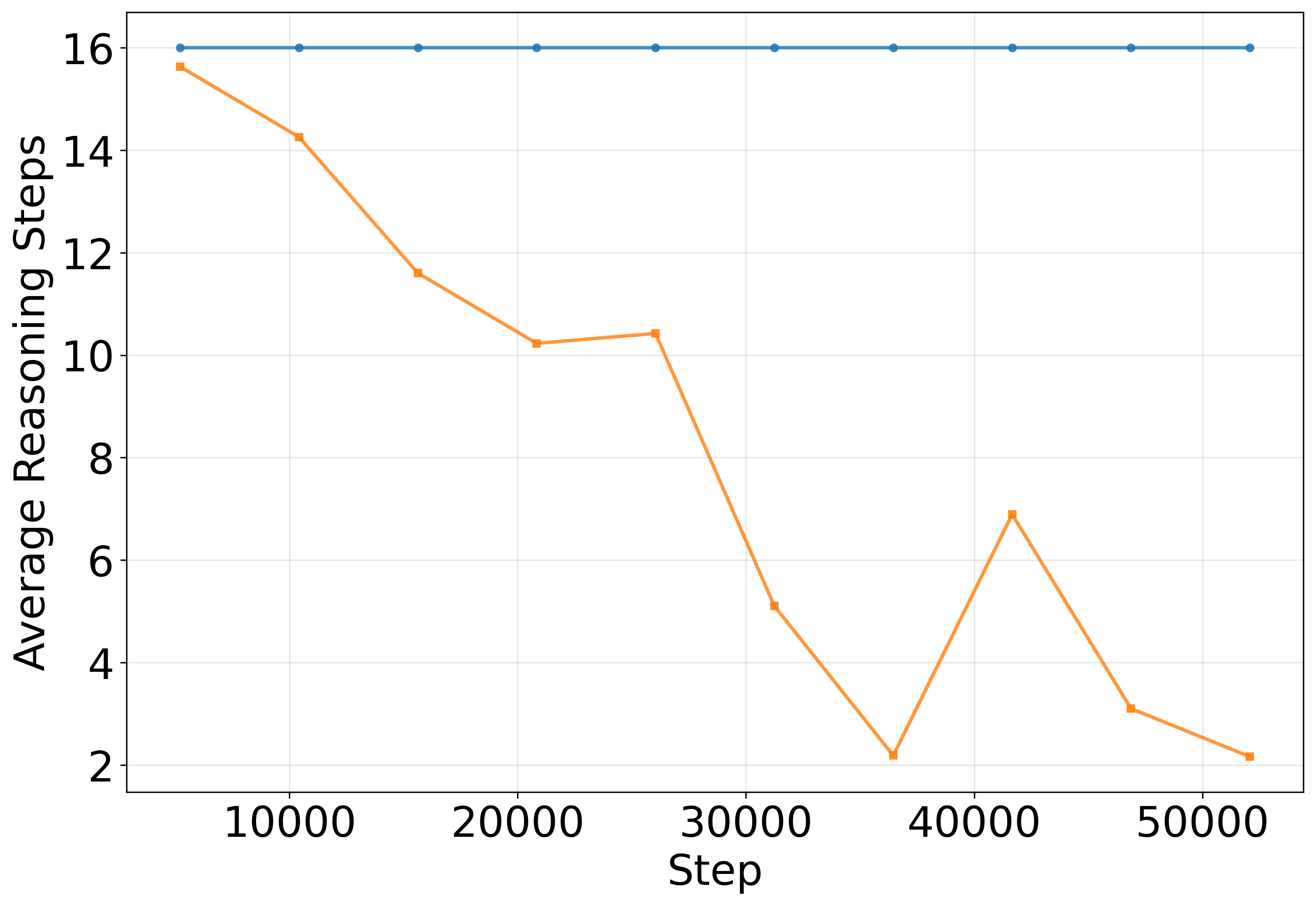
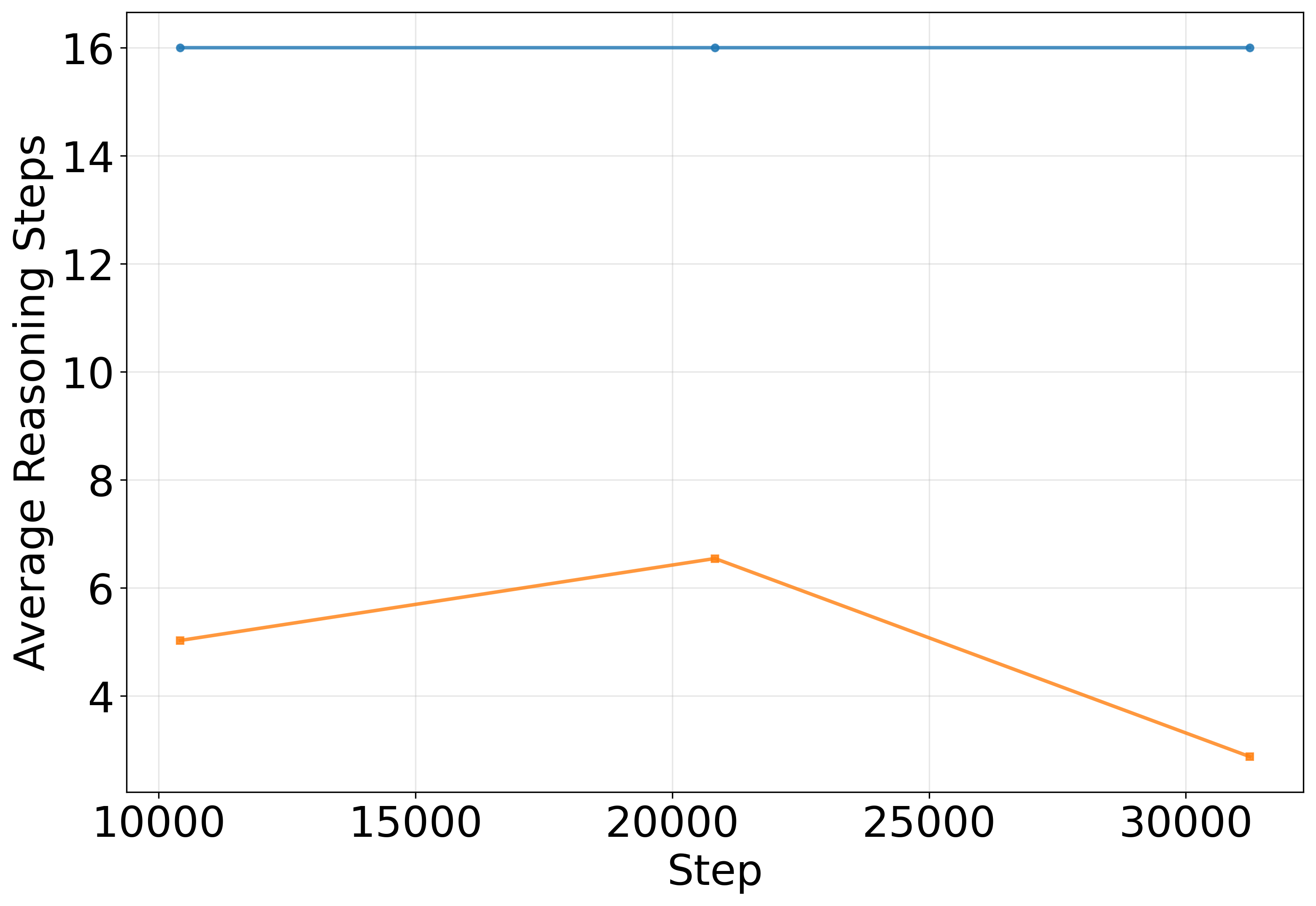
- It also solves puzzles in fewer steps—sometimes as few as 2–4 steps.
- Fewer steps can be better.
- Contrary to the common belief that “more steps at test time improve performance,” their models did better when they stopped sooner. Continuing to reason after having a correct solution sometimes introduced errors.
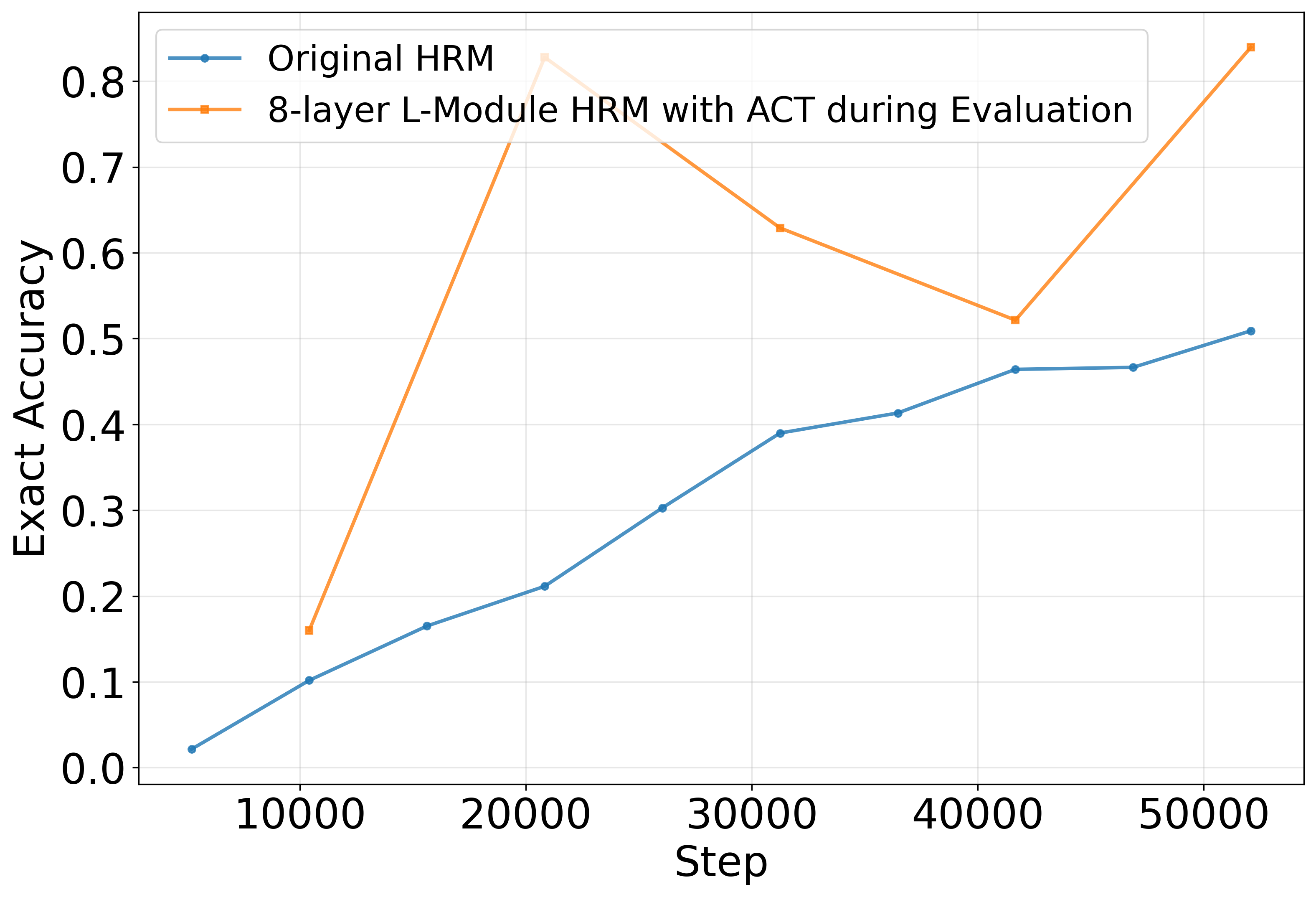
- The two-part hierarchy may not be necessary.
- An 8-layer “plain” transformer with ACT during testing performed similarly to the original HRM with both L and H modules. This raises doubts about how much benefit the hierarchical design actually adds.
- Generalization to another task:
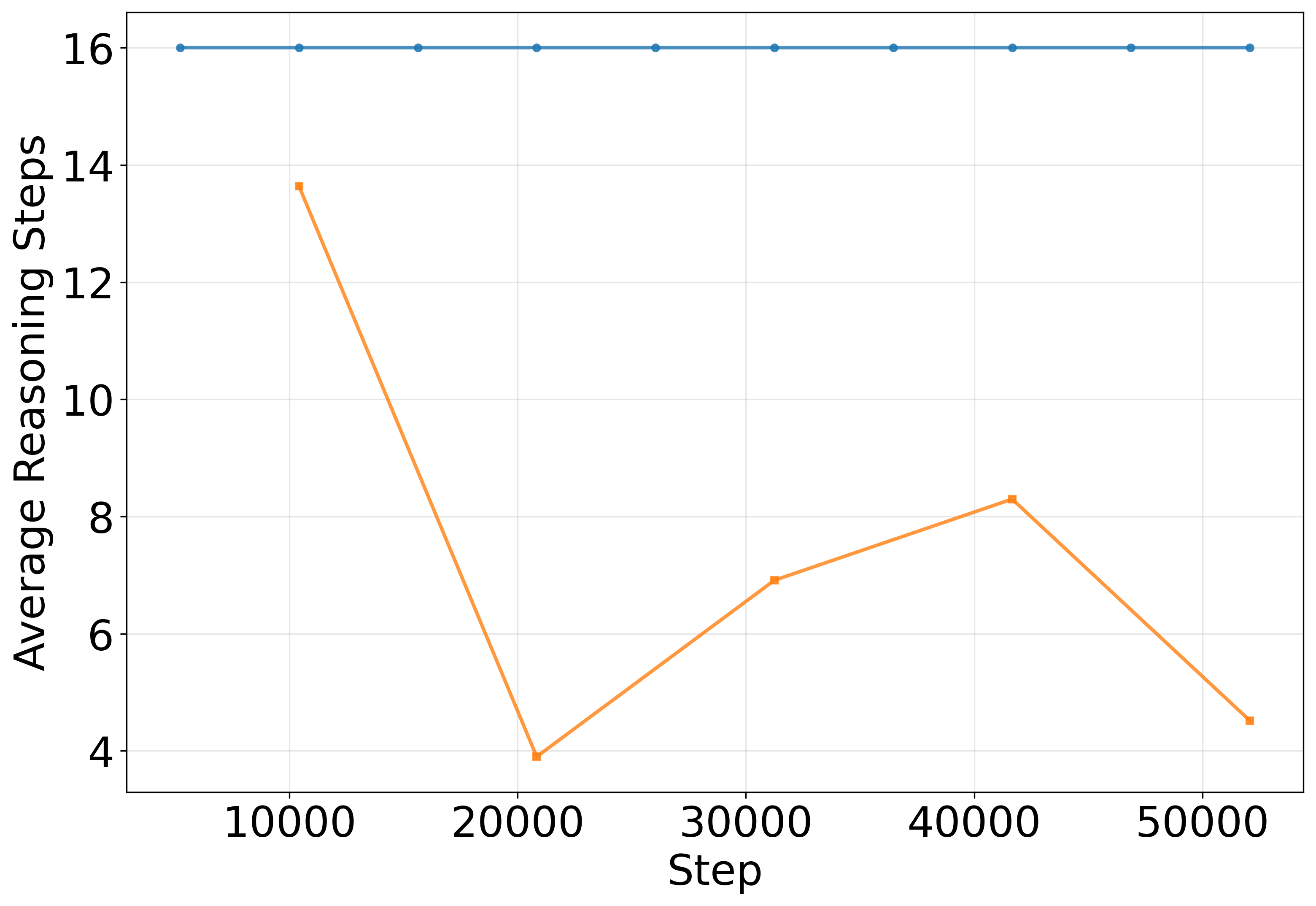
- The same idea (use ACT during testing) helped on a “Maze-Hard” dataset too, improving accuracy faster and reducing the number of steps.
- A surprise about how models reason:
- The model sometimes solves tough Sudoku puzzles in very few steps, which is unlike how humans typically solve them. This suggests that neural networks may compress reasoning in ways that don’t look like human step-by-step logic.
Implications: Why this work could matter in the future
- Better, faster reasoning:
- Letting models stop when they’re done can make them more accurate and efficient. This saves computation and avoids “overthinking” that leads to mistakes.
- Simpler designs might be enough:
- If a plain transformer (with a good stopping rule) can match HRM, we might not need complicated hierarchical structures for many tasks. That could make future models easier to build and train.
- New viewpoint on training:
- Seeing HRM as similar to diffusion/consistency models connects reasoning and image generation under a shared idea: iteratively refining a hidden state. This may inspire new, brain-like ways to train reasoning systems without heavy time-based backpropagation.
- Understanding AI reasoning vs. human reasoning:
- The fact that models can solve puzzles in very few steps suggests they’re doing something different from human logic. Studying this could teach us new principles about intelligence and problem-solving.
- Broader impact on benchmarks and applications:
- If fewer, smarter steps improve performance, future AI systems could become faster and more reliable in tasks like math, planning, and puzzle solving—potentially helping education tools, games, and decision-making software.
In short, this paper shows that how and when a model decides to stop thinking can be just as important as how it thinks—and that simple, well-timed stopping can make AI both smarter and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Formal equivalence to diffusion/consistency models is asserted but not proved: Provide a precise mapping between HRM’s training objective and consistency/diffusion losses, including assumptions, conditions, and convergence guarantees; test whether adopting standard consistency training schedules (e.g., step distillation, noise levels) improves HRM.
- Halting decision sensitivity is unstudied: Quantify how accuracy and step count vary with the evaluation threshold (e.g., using σ(Q_halt) > τ for τ ∈ [0,1]), with/without the stochastic comparison to Q_continue, and under different M_min/M_max.
- Calibration of the Q-head is unknown: Measure and improve the confidence calibration of Q_halt/Q_continue (e.g., ECE/MCE), and assess whether calibrated halting reduces premature stops or late continuation.
- Alternative halting mechanisms are not compared: Benchmark Q-learning–based ACT against Graves’ ACT, supervised halting signals, entropy/confidence-based halting, compute-aware rewards, and verification-guided stopping.
- Mechanism of “over-reasoning drift” is not analyzed: Diagnose why additional steps harm accuracy (exposure bias, state divergence, accumulation of small errors, distribution shift across steps); instrument intermediate states to characterize failure modes.
- Step-wise correctness is not enforced: Explore monotonicity constraints, self-consistency regularizers, verification heads (e.g., Sudoku rule checkers), and “don’t-change-if-correct” objectives to prevent harmful edits after a correct solution.
- Hierarchical H-module efficacy remains unclear beyond two tasks: Run controlled ablations across tasks that require global planning (e.g., ARC-AGI, algorithmic graph problems, long-horizon reasoning) to isolate when H vs. L modules matter.
- Inner carry state importance is not tested: Ablate or vary the carry state (size, update rule, gating) to quantify its contribution to performance, stability, and generalization.
- Baselines are incomplete: Compare against a plain Transformer with ACT, consistency-model training on latent states, reinforcement learning fine-tuning, and token-space CoT baselines under matched training budgets and seeds.
- Generalization is limited to Sudoku-Extreme and Maze-Hard: Complete ARC-AGI experiments and extend to diverse domains (text math problems, code generation, algorithmic tasks, 3D/graph reasoning) to validate broader applicability.
- Robustness to distribution shift and adversarial puzzles is untested: Evaluate under unseen board sizes, altered rule sets, occlusions/noise, adversarial instance generation, and cross-dataset transfer to assess robustness.
- Scalability and compute trade-offs are unquantified: Measure wall-clock latency, throughput, energy, and memory under dynamic halting; study scaling with board size, model depth/width, and batch-level variable-length execution.
- Reproducibility and variance are not reported: Provide multiple seeds, confidence intervals, and training variance; clarify epoch/iteration counts inconsistencies and hyperparameters for fair comparison.
- Data provenance and splits lack detail: Document Sudoku-Extreme and Maze-Hard generation protocols, train/test splits, difficulty stratification, and potential data leakage; test cross-size and cross-difficulty generalization.
- Few-step reasoning phenomenon is unexplained: Determine whether the model performs genuine constraint propagation vs. shortcut pattern recognition; design puzzles that require explicit multi-step reasoning to test this.
- Premature halting risk is unmanaged: Quantify false halts (early stop with incorrect solution) and explore safeguards (verification layers, deferred-acceptance rules, “halt only if verified” criteria).
- Training–inference mismatch resolution is partial: Systematically study when inference-time ACT helps or hurts as a function of training horizon, curriculum, and halting reward design.
- Theoretical capacity limits are not connected to locality barriers: Analyze whether latent recurrence with ACT overcomes the transformer locality barrier (e.g., via formal tests or synthetic tasks with known global dependencies).
- Interpretability of latent states is minimal: Develop probes/visualizations to reveal what is encoded in latent reasoning steps, how constraints are represented, and how updates evolve across iterations.
- Hybrid latent–token approaches are unexplored: Test combining latent-space refinement with token-space chain-of-thought, program-aided verification, or external solvers for auditing and correction.
- Consistency/diffusion training variants are not evaluated: Try explicit consistency loss on latent states, multi-step distillation to 2–4 steps, noise injection schedules, and teacher-forcing vs. self-refinement regimes.
- Verification feedback loops are absent: Integrate solution checkers (e.g., Sudoku validators) to guide halting and refinement, and examine how verification signals affect accuracy and step count.
- Biological plausibility claims are underdeveloped: Map HRM’s operations to plausible neural circuitry, address credit assignment in transformer blocks, and compare to known biologically plausible learning rules.
- Error analysis is lacking: Categorize failure types (local conflicts, global inconsistency, late error introduction), spatial patterns of mistakes, and step-wise error trajectories to guide targeted fixes.
- Fairness of compute use across sequences is not addressed: Evaluate batching strategies for variable-length halting, potential biases introduced by waiting for longest sequences, and implications for real-world deployment.
Glossary
- Adaptive Computation Time (ACT): A mechanism that lets a model adaptively decide how many computation steps to use and when to halt. "while its Adaptive Computation Time (ACT) module learns to decide when to halt during training, evaluation ignores this policy and always executes the maximum number of reasoning steps."
- ARC-AGI: A challenging abstraction-and-reasoning benchmark suite for evaluating generalization and reasoning. "ARC-AGI has a large board size and requires significantly more computational resources to run, which can take a few days on a single GPU."
- ARC-AGI-1: A specific ARC-AGI benchmark variant/task subset used to evaluate reasoning systems. "Notably, HRM achieves strong performance on reasoning-heavy benchmarks such as Sudoku and ARC-AGI-1 \citep{chollet2019measure} without pretraining or explicit chain-of-thought supervision \citep{Wang+etAl2025_hrm}."
- Attention-only architectures: Transformer-style models that rely solely on attention mechanisms without external memory or recurrence, which may limit certain types of reasoning. "theoretical studies highlight structural limits of attention-only architectures: for example, \citet{abbe2024far} demonstrate a ``locality barrier'' that constrains global reasoning unless additional memory mechanisms are introduced."
- Backpropagation Through Time (BPTT): A training method for recurrent models that backpropagates gradients through unrolled time steps. "A key novelty is that HRM frameworks its recurrence in a non-Backpropagation Through Time (BPTT) setting and thus distinguishes itself sharply from any Recurrent Neural Networks (RNNs), giving people from the traditional language processing and RNN background a fresh impression."
- Chain-of-thought prompting: A prompting technique that elicits step-by-step intermediate reasoning traces in natural language. "Chain-of-thought prompting \citep{wei2022chain} and scratchpad supervision \citep{nye2021show} train or prompt models to generate explicit intermediate steps, while program-aided approaches such as PAL \citep{gao2023pal} offload computation to external interpreters."
- Consistency models: Generative models trained to map between different noise levels (or states) consistently, enabling few-step sampling. "Consistency models \citep{Song2023Consistency,Song2024Latent} can generate high-quality, visually appealing images with as few as 2-4 inference steps."
- Credit assignment: The process of determining how to distribute error signals to earlier layers or steps during learning. "A deep feedforward model still requires credit assignment from later layers to earlier ones, where a few algorithms may be possible (e.g., \cite{liao2024self,nokland2016direct,lillicrap2016random,liao2016important})."
- Denoising diffusion process: An iterative generative procedure that progressively denoises a sample to recover data. "In a denoising diffusion process, one repeatedly applies a neural network to gradually denoise a sample, learning to map a noisy input back to the clean data \citep{ho2020denoising,rombach2022high,Song2023Consistency}."
- Diffusion models: Generative models that learn to reverse a noise-adding process to synthesize data. "Diffusion models do not require backpropagation through multiple time steps; they train a feedforward mapping from one state to another independently."
- Halting mechanism: The component or rule that decides when iterative reasoning should stop during inference. "which uses the ACT halting mechanism during evaluation in addition to training."
- Halting policy: The learned policy that determines whether to continue computation or stop at each step. "we modify HRM to use its learned halting policy during evaluation as well."
- High-level (H) module: The slower-updating module in HRM that maintains and updates abstract, global plans. "The HRM architecture consists of two hierarchical reasoning modules: an H module that processes global abstractions, updating less frequently, and an L module that handles local reasoning, which updates more frequently."
- Hierarchical Reasoning Model (HRM): A dual-loop, latent-space reasoning architecture with iterative refinement and adaptive halting. "The Hierarchical Reasoning Model (HRM) \citep{Wang+etAl2025_hrm} is the latest popular model that performs latent-space reasoning."
- Inner carry state: A persistent hidden state used to carry computational context across reasoning steps. "The model also maintains an inner carry state that preserves computational context across reasoning iterations at every step."
- Latent Consistency Model (LCM): A consistency-model formulation operating in latent space that maps intermediate states directly to solutions. "Since HRM operates on latent space and learns directly the mapping from to , it corresponds precisely to ``Latent Consistency Model'' (LCM) \citep{Song2024Latent}."
- Latent chain-of-thought: A method that performs chain-of-thought-style reasoning within continuous latent representations rather than explicit tokens. "Recent work on latent chain-of-thought and related methods \citep{hao2024training} shows that iterative refinement in latent space can yield more compact and flexible reasoning traces."
- Latent-space reasoning: Performing reasoning operations in hidden representations instead of generating explicit token sequences. "Latent-space reasoning takes a different approach, performing reasoning operations within the modelâs hidden representations rather than explicit text."
- Locality barrier: A limitation indicating that attention mechanisms struggle with global reasoning without additional memory. "theoretical studies highlight structural limits of attention-only architectures: for example, \citet{abbe2024far} demonstrate a ``locality barrier'' that constrains global reasoning unless additional memory mechanisms are introduced."
- Low-level (L) module: The faster-updating module in HRM that executes local, fine-grained reasoning steps. "The HRM architecture consists of two hierarchical reasoning modules: an H module that processes global abstractions, updating less frequently, and an L module that handles local reasoning, which updates more frequently."
- Q-head: A network head that outputs Q-values for actions (e.g., halt vs. continue) at each reasoning step. "At each step , a Q-head outputs values for halt and continue as ${Q}^m = \bigl(\hat{Q}^m_{\text{halt}, \hat{Q}^m_{\text{continue}\bigr)$."
- Q-learning: A reinforcement learning algorithm that estimates the expected return (Q-values) of actions to guide decisions. "The model’s ACT module uses Q-learning to balance exploration (continuing reasoning) against exploitation (terminating with the current solution)."
- Recurrent Neural Networks (RNNs): Neural architectures with cyclic connections that process sequences by maintaining hidden states over time. "A key novelty is that HRM frameworks its recurrence in a non-Backpropagation Through Time (BPTT) setting and thus distinguishes itself sharply from any Recurrent Neural Networks (RNNs), giving people from the traditional language processing and RNN background a fresh impression."
- Recurrent reasoning: Iteratively refining an internal state through repeated reasoning steps to approach a solution. "which introduces a novel type of recurrent reasoning in the latent space of transformers, achieving remarkable performance on a wide range of 2D reasoning tasks."
- Scratchpad supervision: Training with explicit intermediate computations (scratchpads) to guide multi-step reasoning. "Chain-of-thought prompting \citep{wei2022chain} and scratchpad supervision \citep{nye2021show} train or prompt models to generate explicit intermediate steps, while program-aided approaches such as PAL \citep{gao2023pal} offload computation to external interpreters."
- Token-space reasoning: Reasoning that operates by generating intermediate natural-language tokens as explicit steps. "Token-space reasoning relies on generating explicit intermediate steps as natural-language tokens, as in chain-of-thought prompting \citep{wei2022chain}."
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s main findings: inference-time Adaptive Computation Time (ACT) halting, simplified HRM architectures (e.g., L-module–only transformer), and the link between HRM and consistency/diffusion-style training.
- Adaptive halting in production LLM and transformer services
- Sector: software/cloud, developer tools
- Application: Add an “Adaptive Inference Controller” that uses learned halting signals during inference to stop reasoning early when an answer is already correct, reducing latency, cost, and error drift from over-reasoning.
- Tools/workflows: Drop-in middleware for PyTorch/JAX inference servers; dynamic loop control with confidence gating; telemetry for steps taken.
- Assumptions/dependencies: Halting threshold calibration; infrastructure support for variable-length compute (dynamic batching, padding); monitoring to catch premature halts.
- Cost and energy reduction for edge AI and mobile assistants
- Sector: consumer software, energy
- Application: Enable variable-step reasoning on-device for assistants, puzzle solvers (e.g., Sudoku), and lightweight planners to improve battery life and responsiveness.
- Tools/workflows: On-device inference SDKs with ACT; step-count budgeting APIs.
- Assumptions/dependencies: Reliable halting under resource constraints; fallbacks to max steps when confidence is low.
- MLOps observability of “compute allocation”
- Sector: software engineering/MLOps
- Application: Track reasoning steps per request, correlate with accuracy and latency, and enforce dynamic compute budgets (e.g., “solve within N steps unless confidence drops”).
- Tools/workflows: Metrics and dashboards for step histograms, halting decisions; A/B testing ACT-on vs ACT-off.
- Assumptions/dependencies: Instrumentation in inference pipelines; clear policies for budget overrides in edge cases.
- Efficient planning in navigation-like tasks
- Sector: robotics, logistics, gaming
- Application: Apply ACT to maze-like planning modules so agents halt once feasible routes are found, improving cycle time and throughput.
- Tools/workflows: ACT-integrated planning loops; safety guardrails (verification checks) before halting.
- Assumptions/dependencies: Domain-specific correctness checks to avoid premature termination; recovery paths if a halted plan fails in execution.
- Streamlined architecture for reasoning systems
- Sector: software/AI platforms
- Application: Replace hierarchical H/L modules with a deeper L-module (e.g., 8-layer transformer) where appropriate, simplifying deployment and maintenance while retaining performance with ACT at inference.
- Tools/workflows: Model templates emphasizing latent recurrent refinement without extra hierarchy.
- Assumptions/dependencies: Task-specific validation to ensure no loss in accuracy; ability to train halting heads.
- Reduced token-chain verbosity via latent reasoning
- Sector: customer support, education, enterprise tooling
- Application: Favor latent-space refinement over long chain-of-thought output to reduce verbosity, cost, and privacy risks, while using ACT to stop early.
- Tools/workflows: “Silent CoT” modes; confidence-calibrated short final responses.
- Assumptions/dependencies: User experience design for less explicit intermediate text; auditability tools to inspect latent trajectories when needed.
- Evaluation protocols that mirror training-time halting
- Sector: academia, benchmarking, internal QA
- Application: Update benchmark harnesses so inference uses learned halting (not fixed max steps), measuring both accuracy and average steps to reflect real operational performance.
- Tools/workflows: Benchmark suites with “compute-aware” metrics; standard reporting of step counts.
- Assumptions/dependencies: Agreement on stopping criteria (e.g., sigmoid(halt) > 0.5); reproducible implementations.
- Carbon-aware inference policies
- Sector: sustainability/policy, cloud ops
- Application: Operational policies to enable ACT during peak energy prices/carbon intensity windows, cutting compute per query while preserving service-level accuracy.
- Tools/workflows: Carbon-aware schedulers; ACT toggles with performance guardrails.
- Assumptions/dependencies: Accurate energy/latency telemetry; governance for service quality impacts.
Long-Term Applications
These opportunities require further research, scaling, integration, or validation, often hinging on the paper’s broader implications (e.g., HRM ≈ latent consistency models, biologically plausible recurrent learning without BPTT, few-step reasoning dynamics).
- Unified “consistency-style” training for reasoning and planning
- Sector: software/AI research, robotics, operations research
- Application: Train reasoning models with consistency/latent diffusion objectives to achieve few-step solutions across planning, constraint satisfaction, and program synthesis.
- Tools/products: A “Consistency Reasoner” library spanning text, graphs, and grids.
- Assumptions/dependencies: Robust construction of intermediate states; generalization beyond 2D tasks; calibration for confidence and correctness.
- Safety-critical halting with formal verification
- Sector: healthcare, autonomous systems, finance
- Application: Couple halting signals with verifiers (proof checkers, medical protocol validators, risk constraints) to ensure early stops don’t compromise safety.
- Tools/workflows: Halting + verifier pipelines; certified confidence bounds.
- Assumptions/dependencies: Reliable, well-calibrated halting; domain-specific formal checks; regulatory acceptance.
- Adaptive compute marketplaces and billing models
- Sector: cloud, finance, policy
- Application: Pricing and SLAs based on “steps used” rather than fixed quotas, incentivizing efficient reasoning.
- Tools/workflows: Step-aware billing, carbon credits for reduced compute.
- Assumptions/dependencies: Transparent metrics; customer education; anti-gaming safeguards.
- Privacy-preserving latent chain-of-thought assistants
- Sector: enterprise, healthcare, legal
- Application: Keep reasoning internal (latent) while exposing structured summaries, mitigating leakage of sensitive reasoning traces.
- Tools/workflows: Latent reasoning modes with redactable summaries; audit hooks for compliance.
- Assumptions/dependencies: Trust in latent logs; protocols for selective disclosure.
- Neuromorphic and biologically inspired implementations
- Sector: hardware, neuroscience
- Application: Implement diffusion-like local learning rules and ACT-style gating in neuromorphic systems to emulate deep reasoning without BPTT.
- Tools/workflows: Spiking networks with local consistency updates; gating circuits.
- Assumptions/dependencies: Viable hardware primitives; mapping from transformer blocks to plausible circuits.
- Compute-aware education technology
- Sector: education
- Application: Tutors that adaptively “reason just enough,” offering concise solutions and revealing steps only on demand, optimizing student focus and device resources.
- Tools/workflows: Tutor UIs with optional step expansion; confidence-driven scaffolding.
- Assumptions/dependencies: Pedagogical validation; personalization without oversimplification.
- Imaging and inverse problems via latent consistency reasoning
- Sector: healthcare, geoscience, manufacturing
- Application: Borrow consistency-model training to speed up iterative reconstruction (MRI/CT), denoising, and deconvolution with few inference steps and ACT-like stopping.
- Tools/workflows: Cross-domain “consistency solver” frameworks; adaptive stopping based on image quality metrics.
- Assumptions/dependencies: High-quality ground-truth or physics-informed constraints; clinical validation.
- ARC-AGI-scale reasoning systems with adaptive halting
- Sector: AGI benchmarks, research
- Application: Scale models to ARC-AGI and similar tasks with halting-based evaluation to study compute–accuracy trade-offs and few-step generalization.
- Tools/workflows: Large-board reasoning engines; adaptive inference harnesses.
- Assumptions/dependencies: Sufficient compute; strong generalization beyond Sudoku/Maze.
- Dynamic-batch inference infrastructure
- Sector: cloud platforms, frameworks
- Application: Rework serving stacks to support variable-length loops and heterogeneous halting, minimizing padding overhead and maximizing GPU/TPU utilization.
- Tools/workflows: Step-aware schedulers; micro-batching aligned to halting signals.
- Assumptions/dependencies: Framework-level support; profiling-guided optimizations.
- Hybrid systems: halting + external tools/programs
- Sector: software automation, data analytics
- Application: Use ACT to decide when to stop latent refinement and invoke external tools (solvers, databases, code interpreters) only when needed, reducing tool-call overhead.
- Tools/workflows: Gated tool-use orchestrators; decision policies trained on cost–accuracy signals.
- Assumptions/dependencies: Reliable tool-call confidence; cost modeling; avoidance of oscillation between model and tools.
Collections
Sign up for free to add this paper to one or more collections.

