- The paper presents a framework where documents are represented as categories of non-overlapping QA pairs to enable robust semantic analysis.
- It employs a mathematical approach with operations like union and intersection to extract and measure rhetorical structures via DAGs.
- The study introduces self-supervised reinforcement learning methods to iteratively enhance large language models for precise document summarization.
Document Understanding, Measurement, and Manipulation Using Category Theory
Abstract and Introduction
The paper "Document Understanding, Measurement, and Manipulation Using Category Theory" (2510.21553) presents an innovative application of category theory to the semantic analysis, structuring, and manipulation of documents. The authors leverage category theory to offer a mathematical representation of documents through question-answer (QA) pairs, enabling advanced summarization techniques, information measurement, and model enhancement through self-supervision. This modality-agnostic framework applies to textual, audio, and visual documents, expanding the potential for practical applications across various types of media.
QA Structure Representation
The authors propose a unique representation of documents as categories of QA pairs, where core assertions equate to distinct QA pairs. This formalism allows for a robust mathematical framework that supports operations such as union, intersection, and complement of assertions. These principles are operationalized using large pretrained models (LLMs), facilitating automated extraction and categorization. The orthogonalization process is critical, ensuring the QA pairs are non-overlapping, which is essential for their information-theoretic approach to document analysis.
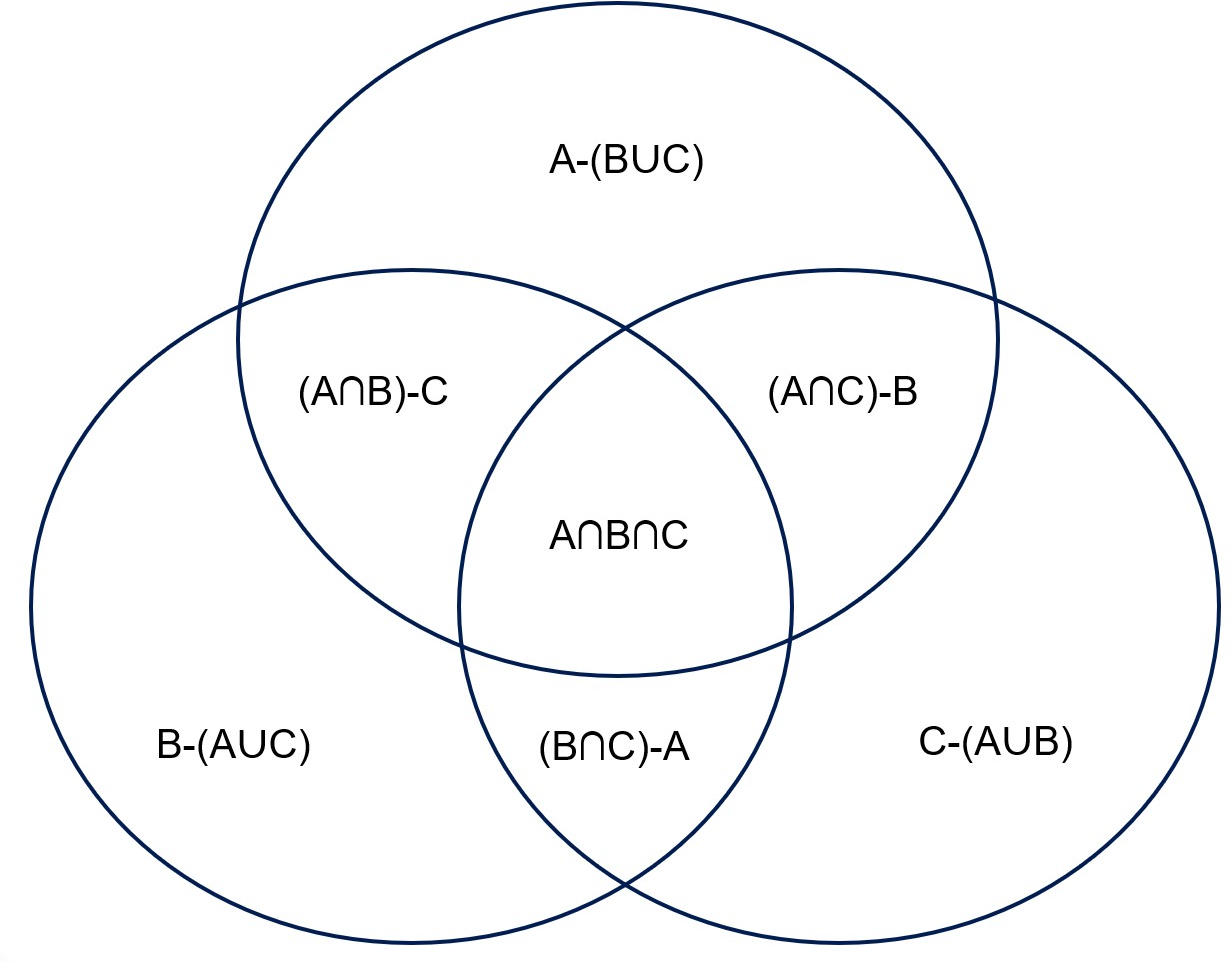
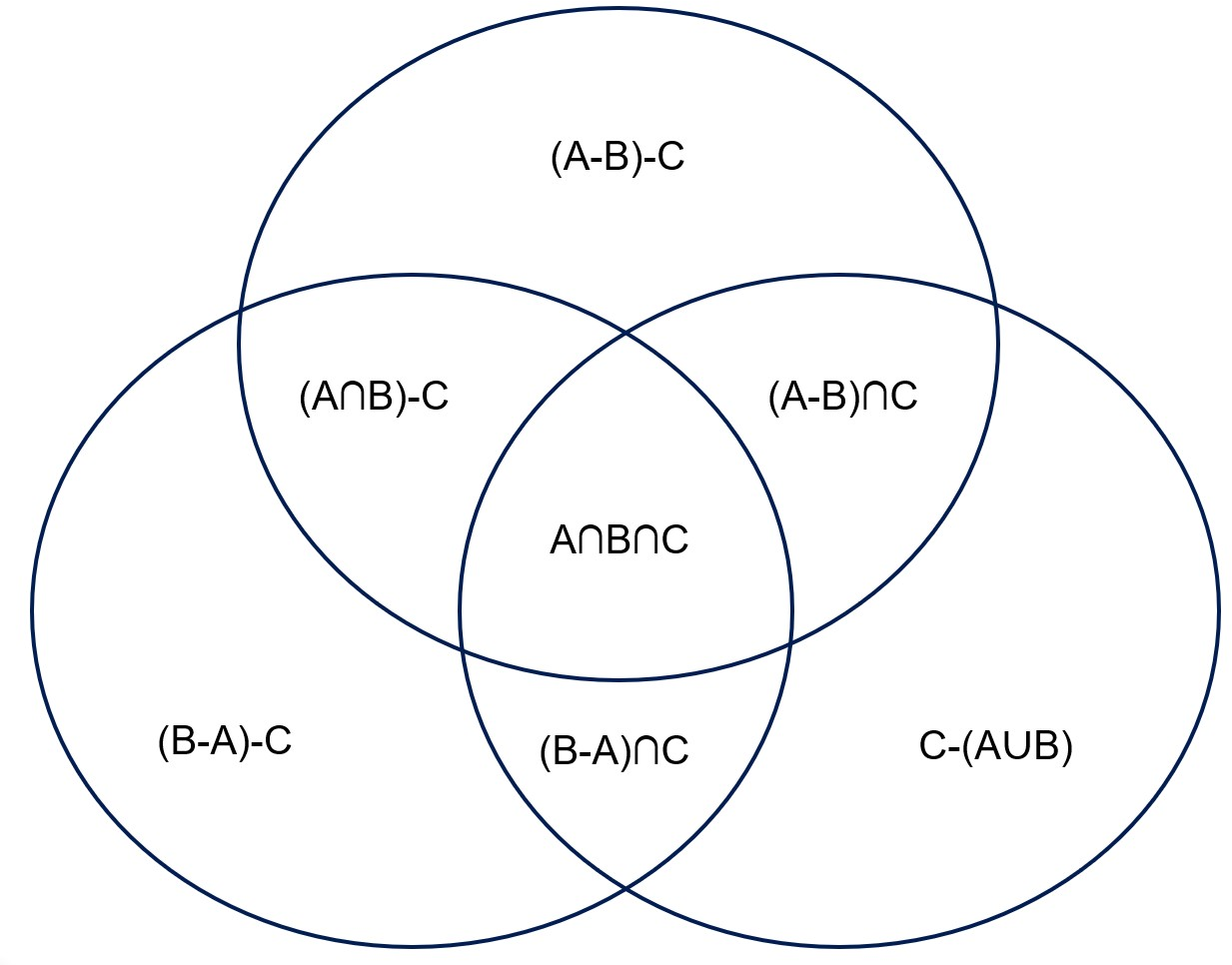
Figure 1: Two equivalent representations of non-overlapping components of three assertions A, B, and C.
Extracting and Applying Rhetorical Structure
The paper emphasizes the extraction of rhetorical structure using an abstractive Directed Acyclic Graph (DAG) formed by summarizing document sections. This DAG representation converges into a deeper hierarchical understanding through DAGs of core and orthogonalized QA pairs. This transformation enables the authors to structure summaries and expansions of documents systematically, thereby facilitating more nuanced semantic manipulations and rigorous information enumeration.

Figure 2: An example of a DAG of orthogonalized QAs demonstrating decomposition of assertions into a hierarchical structure.
The framework introduces several innovative metrics for document analysis, such as information content, information density, mutual information, and content entropy. These metrics are derived from the orthogonalized QA pairs and are crucial for assessing the semantic richness and breadth of the documents. These measures provide a quantitative understanding of document complexities and redundancies, allowing researchers to assess document summaries' efficacy and perform rate distortion analysis for summarization techniques.
Self-supervised Improvement and Constraints
The paper details a novel self-supervised method utilizing Reinforcement Learning with Verifiable Rewards (RLVR) to refine LLMs. By incorporating consistency constraints derived from category theory, such as composability and closure operations, models can be iteratively improved, enhancing the accuracy and alignment of their outputs with expected semantic structures. These methods offer promising avenues for refining AI systems to meet rigorous theoretical standards automatically.
Implications and Future Developments
This research signifies a significant theoretical advancement in document processing methodologies. The implications extend beyond simple document summarization, allowing for complex document extensions (exegesis), better document alignment, and potential applications in areas such as semantic retrieval and knowledge transfer. Future research can explore probabilistic categories and coherent extensions, suggesting untapped potentials for dynamic document expansion and semantic alignment between diverse documents.
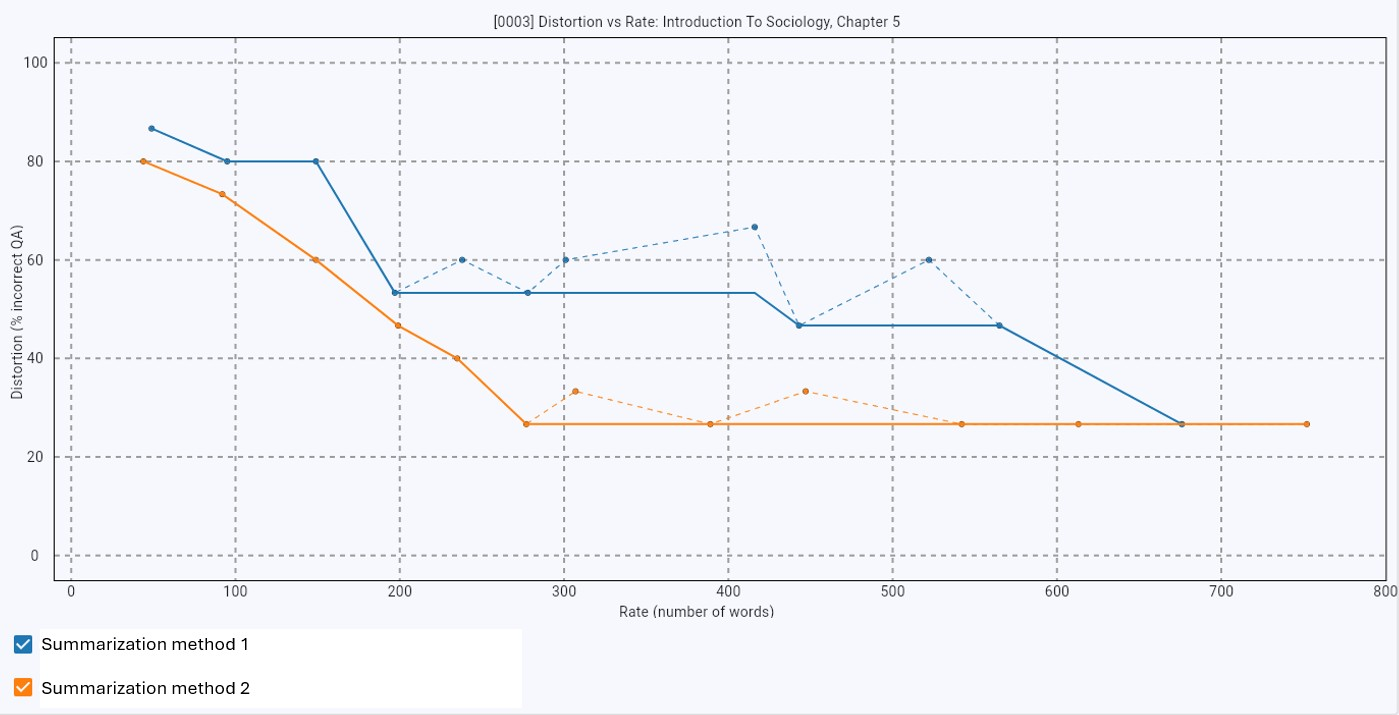
Figure 3: An example of rate distortion curves illustrating the efficiency comparison between two summarization methods.
Conclusion
The paper provides a comprehensive framework that blends category theory with information theory and large-scale language modeling. By establishing formal metrics for document content evaluation and facilitating advanced QA-based manipulations, it presents a formidable approach to semantic document understanding and manipulation. The outlined methodologies promise substantial improvements in AI's capability to handle complex document-centric tasks, suggesting a path towards more nuanced and adaptable document processing systems. The fusion of category theory with modern AI methods presents compelling new avenues for both theoretical research and practical applications in document analysis.