- The paper introduces PBS-Attn, which uses token permutation to enhance block sparsity and reduce redundant self-attention computations.
- It implements segmented permutation and query-aware key sorting to maintain causality while clustering key tokens efficiently.
- Experiments on long-context tasks show up to a 2.75× speedup without degrading accuracy, validating its practical efficiency improvements.
Sparser Block-Sparse Attention via Token Permutation
The paper introduces "Permuted Block-Sparse Attention (PBS-Attn)", a novel approach to enhance the computational efficiency of block-sparse attention mechanisms in LLMs. The primary goal of PBS-Attn is to leverage token permutation to improve block-level sparsity, reducing computational redundancy associated with self-attention mechanisms in transformers.
Motivation and Background
The paper targets the inefficiencies introduced by the O(N2) computational complexity of self-attention in transformers. Block-sparse attention aims to mitigate this complexity by partitioning the sequence into blocks, selectively computing attention within these blocks. However, traditional block-sparse methods often suffer from sub-optimal sparsity patterns. These inefficiencies arise when important key tokens for a query in a block are distributed across multiple blocks, leading to redundant computations.
Traditional efforts in optimizing attention complexity include architectural changes like linear transformers, hardware-aware optimizations like FlashAttention, and block-sparse techniques that prune interactions using masks. While effective, these methods are limited by the inherent attention patterns and cannot fully capitalize on the sparsity present in natural language sequences.
Permuted Block-Sparse Attention (PBS-Attn)
PBS-Attn introduces a permutation-driven strategy that reorders query and key sequences to increase block-level sparsity. Key innovations include the following:
- Symmetry Exploitation via Permutation: Attention mechanisms are permutation-invariant for key-value pairings and equivariant for query permutations. PBS-Attn exploits these properties to reorder tokens, maximizing intra-block sparsity without altering the model's output.
- Segmented Permutation: Since maintaining causality is crucial, particularly in autoregressive models, PBS-Attn uses segmented permutation. This technique allows for intra-segment permutation while ensuring inter-segment causality is preserved (Figure 1).
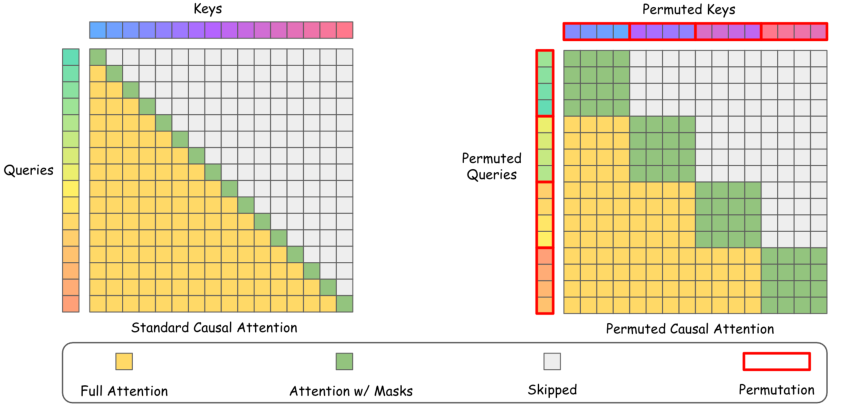
Figure 1: Illustration of causal attention without (Left) and with (Right) segmented permutation with B=1,S=4. Segmented permutation enhances block-level sparsity via intra-segment permutation while preserving inter-segment causality. By restricting computation of blocks within on-diagonal segments (green blocks), we can safely skip inter-segment blocks (yellow blocks) for block-sparse attention.
- Query-aware Key Permutation: The method implements segment-wise sorting of keys based on estimated attention scores, optimizing their placement in computationally efficient clusters.
Implementation and Experimentation
The implementation of PBS-Attn involves customizing kernels for the permuted block-sparse attention mechanism using Triton for efficient inference. The method optimizes the prefill stage by leveraging tensor parallelism, resulting in enhanced scalability and speedup. Intensive evaluations using Llama-3.1-8B and Qwen-2.5-7B-1M models on LongBench and LongBenchv2 benchmarks demonstrate that PBS-Attn maintains accuracy close to the full-attention baseline while achieving significant computational speedups.
Main Results
- PBS-Attn outperformed other sparsity-driven approaches on multiple long-context tasks, achieving up to a 2.75× end-to-end speedup in LLM prefilling.
- The proposed permutation strategy enhances block sparsity, evidenced by improvements in real task performance due to effective clustering of important tokens (Figure 2).
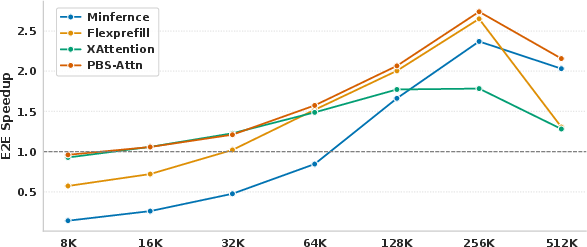
Figure 2: Speedup of various methods relative to FlashAttention, measured by time to first token (TTFT) on LongBenchv2 across various sequence lengths. To accommodate longer sequences under memory constraints, we employ tensor parallelism with tp_size of 2 and 8 for the 256K and 512K contexts, respectively.
Ablation Studies
The ablation studies confirmed the role of permutation in improving block sparsity and computational efficiency. Adjusting permutation target and segment size demonstrated that the approach provides robust control over the density-performance trade-off.
Conclusion
PBS-Attn offers a novel methodology for improving the computational efficiency of LLMs. By intelligently permuting key and query tokens, the method strategically increases block sparsity, thus enhancing the scalability and speed of processing without degrading model accuracy. This study not only extends the capabilities of block-sparse attention mechanisms but also lays the groundwork for more efficient implementations of transformer models in handling ultra-long sequences. Future work can explore integrating PBS-Attn with other efficiency-oriented methods, such as low-rank and quantization techniques, to further optimize resource use.

