- The paper introduces a layered canvas and locking mechanism enabling interactive spatial control and scalable multi-subject T2I generation.
- It employs position-aware latent encoding with transparent pruning to preserve identity and avoid occlusion in personalized scenes.
- Experimental results demonstrate superior performance in identity preservation, text adherence, and user satisfaction over baseline methods.
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Introduction and Motivation
LayerComposer introduces a new paradigm for personalized text-to-image (T2I) generation, specifically targeting the limitations of existing diffusion-based personalization methods in spatial control and multi-subject scalability. Prior approaches, such as DreamBooth, IP-Adapter, and ControlNet, either require auxiliary control maps or suffer from linear memory and computational growth with the number of personalized subjects. LayerComposer addresses these bottlenecks by proposing a layered canvas representation and a locking mechanism, enabling users to interactively place, resize, and lock subjects on a canvas, akin to professional image-editing workflows.
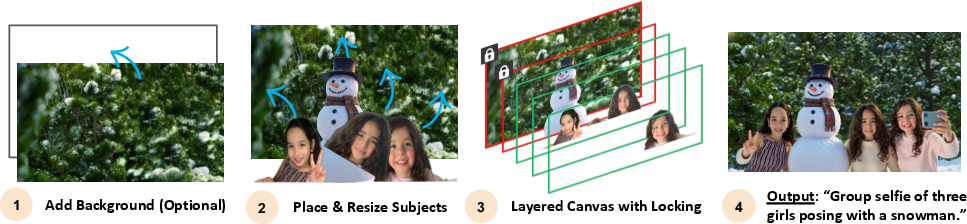
Figure 1: LayerComposer enables interactive multi-subject T2I generation with spatial placement, resizing, and locking, providing a Photoshop-like user experience.
Layered Canvas Representation and Locking Mechanism
The core innovation is the layered canvas, where each subject (and optionally the background) is encoded as a distinct RGBA layer. The alpha channel provides a spatial mask, and a binary locking flag determines whether the subject should be strictly preserved or allowed to adapt to the scene context. This design resolves occlusion ambiguities and decouples the conditioning sequence length from the number of subjects, enabling efficient scaling.
The locking mechanism leverages positional embeddings: locked layers share positional indices with the noisy latent tokens, ensuring high-fidelity preservation, while unlocked layers receive unique indices to avoid appearance mixing in overlapping regions. This is achieved without architectural changes, relying on a model-data co-design and a complementary data sampling strategy during training.

Figure 2: Locking-aware data sampling: locked layers are sampled from the target image for pixel alignment, while unlocked layers are sampled from other images of the same identity, enabling controlled variation.
Model Architecture and Training Pipeline
LayerComposer builds on a pretrained latent-based diffusion transformer (DiT). The pipeline consists of:
- Layer Latent Extraction: Each RGBA layer is encoded via a VAE to obtain latent tokens.
- Positional Embedding: Locked layers use [0,x,y] positional embeddings; unlocked layers use [j,x,y] where j is a unique layer index.
- Transparent Latent Pruning: Only tokens corresponding to non-transparent regions are retained, improving scalability.
- Layer Conditioning Integration: Pruned latents from all layers are concatenated with noisy image latents for DiT conditioning.
Training employs a locking-aware data sampling strategy, with LoRA adapters finetuned on the DiT backbone using a flow matching loss. The dataset comprises 32M images across 6M scenes, with instance segmentation to extract human subjects and backgrounds.
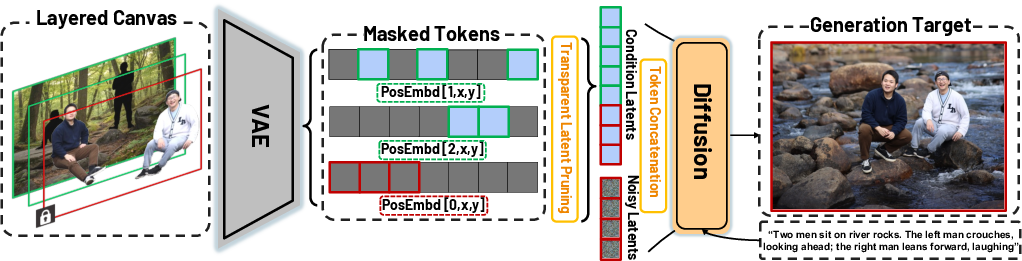
Figure 3: LayerComposer pipeline: text prompt and layered canvas are encoded, positional embeddings are assigned based on locking status, and transparent latent pruning enables scalable multi-subject conditioning.
Experimental Evaluation
LayerComposer is evaluated on 1P, 2P, and 4P personalization benchmarks, using FFHQ-in-the-wild identities and diverse prompts. Metrics include ArcFace for identity preservation, VQAScore for text alignment, HPSv3 for image quality, and user studies for overall preference.
4P Personalization: Competing methods (FLUX Kontext, Overlay Kontext, Qwen-Image-Edit, Gemini 2.5 Flash Image) frequently fail to preserve all subjects or introduce artifacts, especially under occlusion. LayerComposer consistently generates coherent, high-fidelity images, robustly handling occlusions and spatial arrangements.

Figure 4: In 4P personalization, LayerComposer preserves identities and spatial layout, outperforming baselines that distort or omit subjects, especially under occlusion.
2P Personalization: Baselines (UniPortrait, StoryMaker, UNO, OmniGen2) often miss, duplicate, or distort subjects. LayerComposer produces natural interactions and distinct identities, with superior user preference and identity scores.

Figure 5: In 2P personalization, LayerComposer generates coherent scenes with natural subject interaction and identity preservation, unlike baselines with missing or duplicated subjects.
1P Personalization: Existing methods tend to copy-paste the reference face with limited flexibility. LayerComposer achieves realistic outputs faithful to both identity and prompt, supporting diverse expressions and activities.

Figure 6: In 1P personalization, LayerComposer captures diverse expressions and activities, avoiding copy-paste artifacts seen in other methods.
Ablation Studies and Analysis
Ablation studies demonstrate the effectiveness of the locking mechanism and layered canvas. Progressive locking preserves subject pose and appearance with only necessary lighting adjustments, while unlocked layers adapt flexibly. Without the layered canvas, occlusion leads to missing details; the layered approach resolves these issues.

Figure 7: Ablation: locking preserves selected subjects with minimal changes; layered canvas resolves occlusion, preventing loss of overlapping details.
LayerComposer also supports seamless integration of backgrounds as additional layers, enabling natural human-background interactions under coherent lighting.

Figure 8: Layered canvas with background: humans interact naturally with the background, maintaining coherent lighting and spatial relationships.
Quantitative Results
LayerComposer achieves top-2 image quality (HPSv3) across all benchmarks and substantially outperforms other methods in multi-subject identity preservation (ArcFace). Notably, ArcFace scores for 1P are lower than copy-paste baselines due to greater pose/expression diversity, but LayerComposer excels in prompt adherence (VQAScore) and user preference.
Limitations and Future Directions
LayerComposer's performance degrades for scenes with more than four subjects, primarily due to data limitations and base model robustness. It also struggles with complex spatial reasoning tasks, such as natural placement of subjects in challenging backgrounds. Future work should integrate vision-LLMs for enhanced reasoning and expand high-quality multi-subject datasets.
Conclusion
LayerComposer establishes a scalable, interactive framework for personalized T2I generation, introducing a layered canvas and locking mechanism for fine-grained spatial and identity control. It demonstrates superior compositional fidelity and robustness across multi-subject scenarios, setting a new standard for interactive generative workflows. The layered canvas paradigm is extensible to broader compositional and editing tasks, with future research needed to address reasoning and scalability beyond four subjects.