VAMOS: A Hierarchical Vision-Language-Action Model for Capability-Modulated and Steerable Navigation
Abstract: A fundamental challenge in robot navigation lies in learning policies that generalize across diverse environments while conforming to the unique physical constraints and capabilities of a specific embodiment (e.g., quadrupeds can walk up stairs, but rovers cannot). We propose VAMOS, a hierarchical VLA that decouples semantic planning from embodiment grounding: a generalist planner learns from diverse, open-world data, while a specialist affordance model learns the robot's physical constraints and capabilities in safe, low-cost simulation. We enabled this separation by carefully designing an interface that lets a high-level planner propose candidate paths directly in image space that the affordance model then evaluates and re-ranks. Our real-world experiments show that VAMOS achieves higher success rates in both indoor and complex outdoor navigation than state-of-the-art model-based and end-to-end learning methods. We also show that our hierarchical design enables cross-embodied navigation across legged and wheeled robots and is easily steerable using natural language. Real-world ablations confirm that the specialist model is key to embodiment grounding, enabling a single high-level planner to be deployed across physically distinct wheeled and legged robots. Finally, this model significantly enhances single-robot reliability, achieving 3X higher success rates by rejecting physically infeasible plans. Website: https://vamos-vla.github.io/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “VAMOS: A Hierarchical Vision-Language-Action Model for Capability‑Modulated and Steerable Navigation”
1) Overview: What is this paper about?
This paper introduces VAMOS, a two-part “brain” that helps robots find and follow safe paths in the real world. It separates big-picture planning (where to go) from body-specific abilities (what this robot can actually do). A vision‑LLM (an AI that understands pictures and words) draws several possible paths on the camera image, and a second model checks which of those paths the robot’s body can safely handle. This makes navigation more reliable, works across different kinds of robots (like ones with legs or wheels), and lets people steer the robot with simple text instructions.
Key idea in simple terms: one model plans like a map scout, another model acts like a safety inspector who knows the robot’s strengths and limits.
2) What questions did the researchers ask?
They set out to answer a few practical questions:
- Can one navigation system work well in many places, indoors and outdoors?
- Can the same planner work across different robot “bodies” (embodiments), like legged robots that can climb stairs versus wheeled robots that can’t?
- How can we use large mixed datasets (from many robots and terrains) without confusing a robot with moves it physically can’t do?
- Can we steer the robot’s choices with simple text, like “prefer stairs” or “keep left”?
- Does splitting planning (general) and physical capabilities (specific) make robots more reliable?
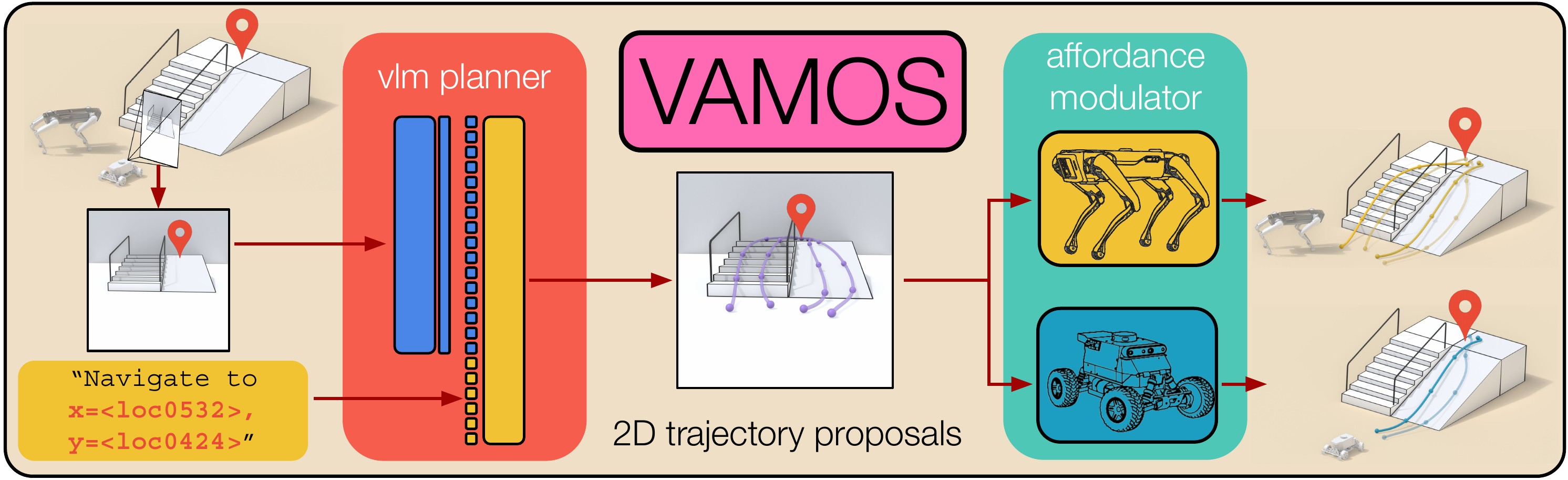
3) How does VAMOS work? (Methods in everyday language)
Think of VAMOS as a two-layer system:
- High-level planner (Vision‑LLM, VLM):
- Inputs: a live camera image plus a goal location (written as text), and optionally a preference (like “take the ramp” or “keep to the right”).
- Output: several candidate paths drawn on the image (like tracing lines on a photo of what the robot sees).
- Why draw in 2D on the image? It’s a simple, consistent way to learn from many different datasets and robots. Later, those path points are converted into real-world ground positions the robot can follow.
- Low-level affordance model (capability-aware “safety inspector”):
- “Affordance” means: can the robot safely go here, given the terrain and its abilities?
- This model scores each candidate path based on whether the robot can traverse it: for instance, legs can handle stairs, but wheels usually need ramps.
- It’s trained cheaply and safely in simulation by trying lots of terrains and recording success or failure. That way, it learns, “This slope is okay,” or “That obstacle is too high.”
Workflow:
- The planner proposes multiple paths on the image.
- The system converts those paths to ground positions.
- The affordance model scores each point along each path; a path is rejected if any point is unsafe.
- The robot picks the safest high-scoring path to follow and replans frequently as it moves.
Training approach:
- The planner is a large AI that understands images and text, fine-tuned on diverse, real-world navigation data from several robot datasets.
- The affordance model is trained in simulation (virtual environments with varied terrain) so it learns physical limits without risking real hardware.
- Steerability is taught by adding text descriptions and preferences during training, so the planner learns to respect instructions.
4) What did they find, and why is it important?
Here are the main results, explained simply:
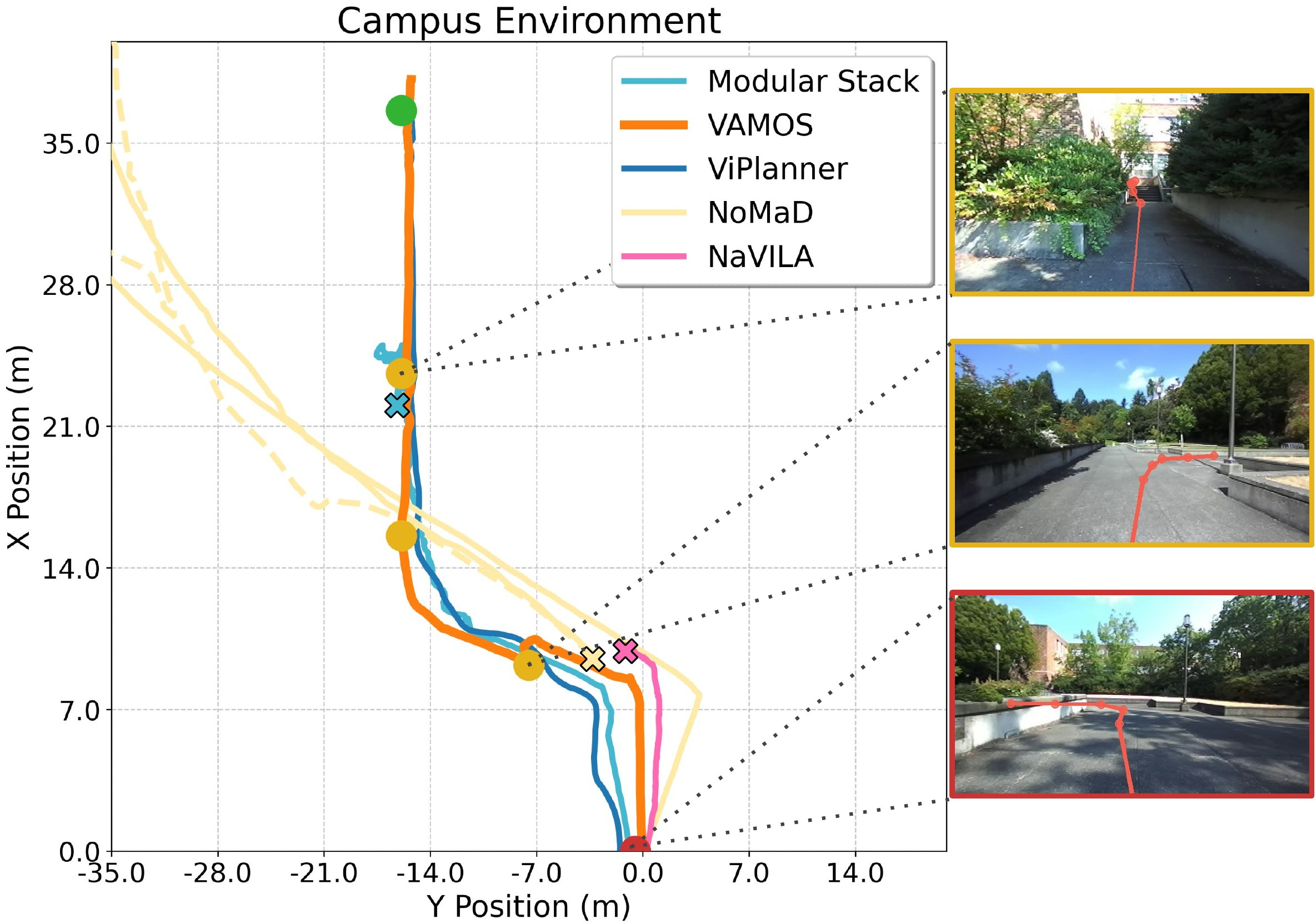
- Strong real-world performance: VAMOS had the highest average success rate across tough indoor and outdoor courses (narrow hallways, cluttered labs, low light areas, long campus routes, forests, ramps, and stairs).
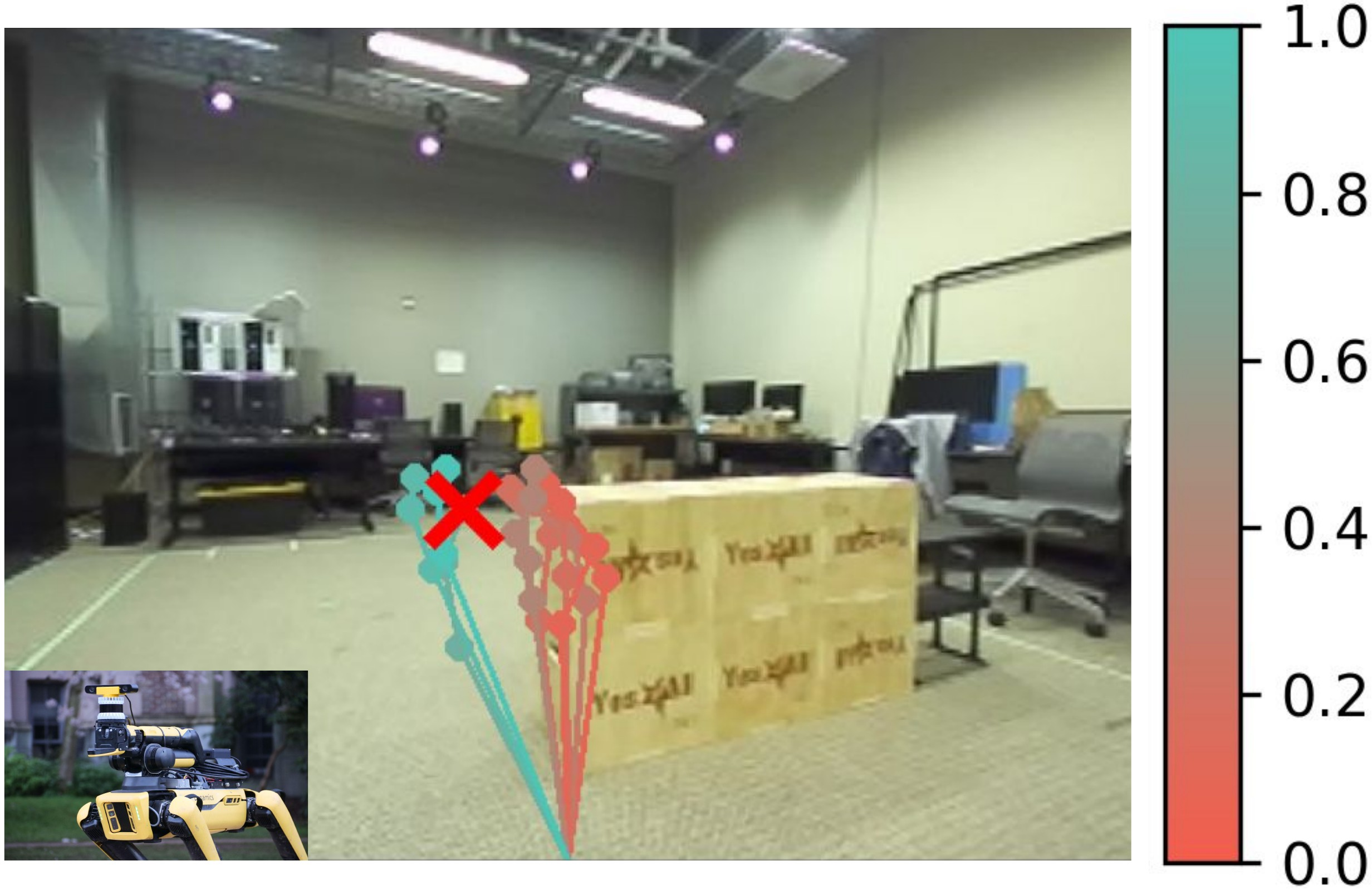
- Works across robot types: The same high-level planner worked on a legged robot (Spot) and a wheeled robot (Hound). By swapping only the affordance model, the system chose stairs for Spot (which can handle them) and ramps for Hound (which can’t do stairs), improving Hound’s success from 60% to 90%.
- Language steerability: Adding simple text preferences (like “take the ramp” or “stay to the right”) changed the chosen path in sensible ways. A separate model judging the outputs confirmed the preferences matched the resulting paths.
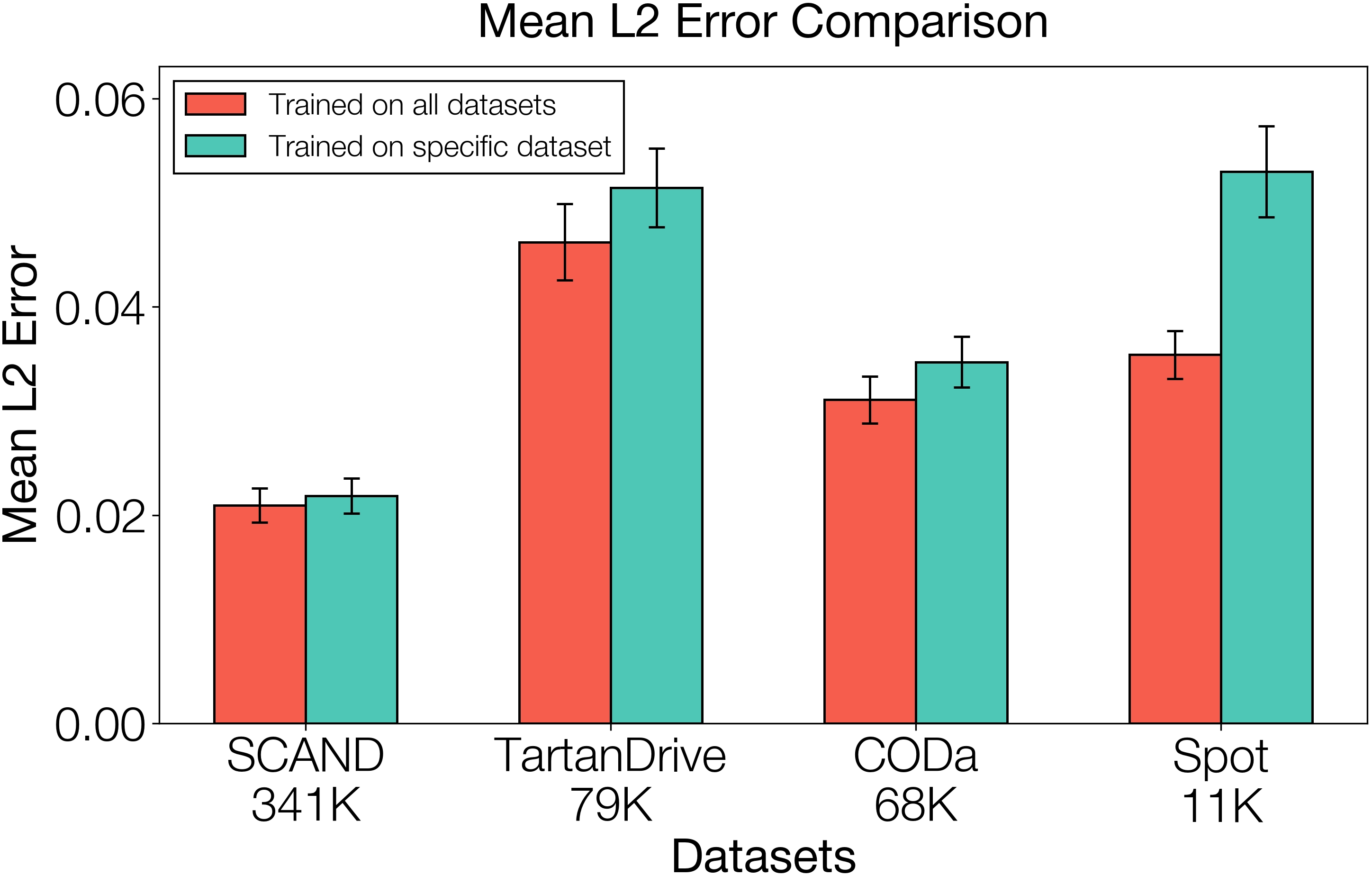
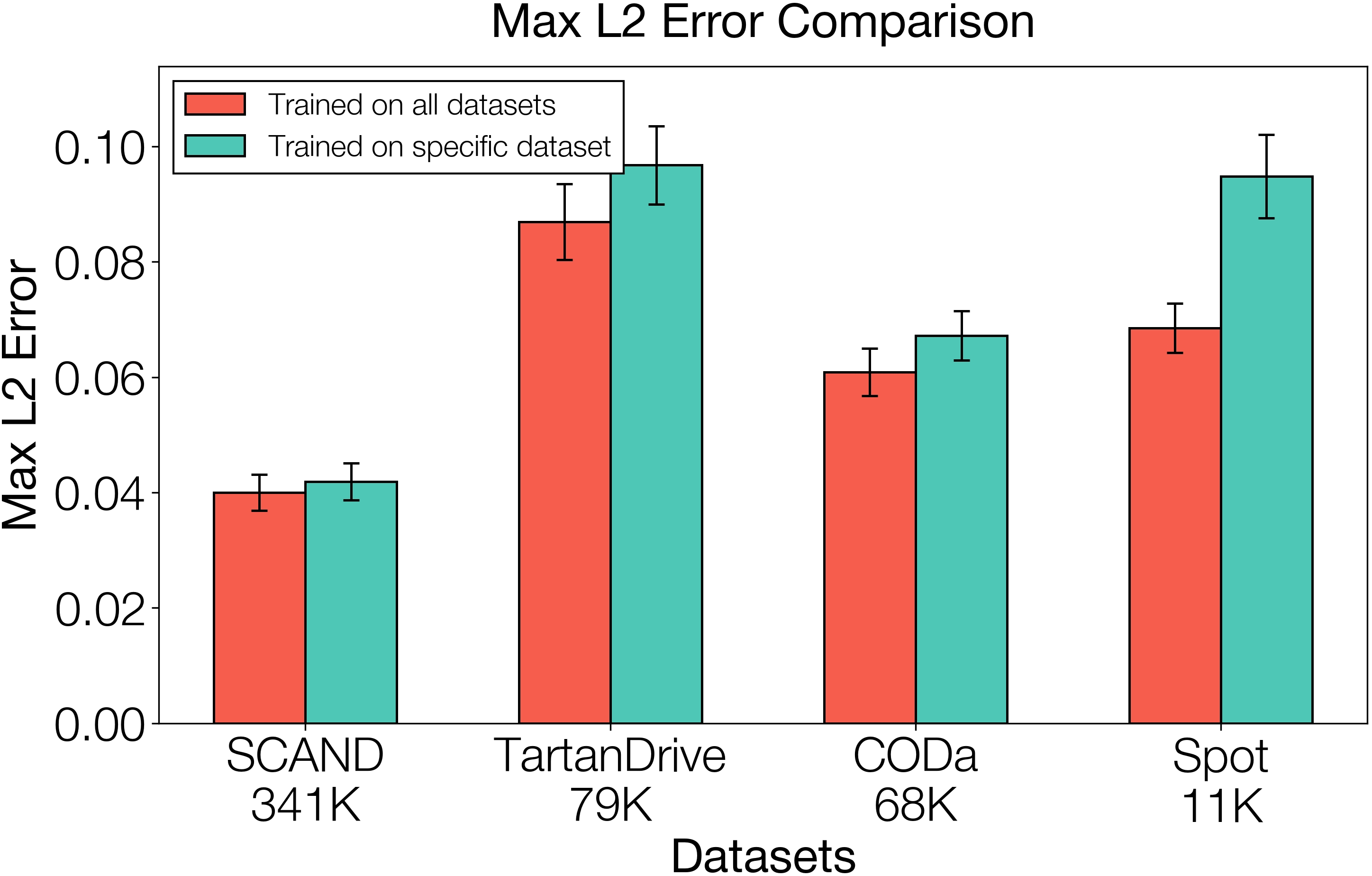
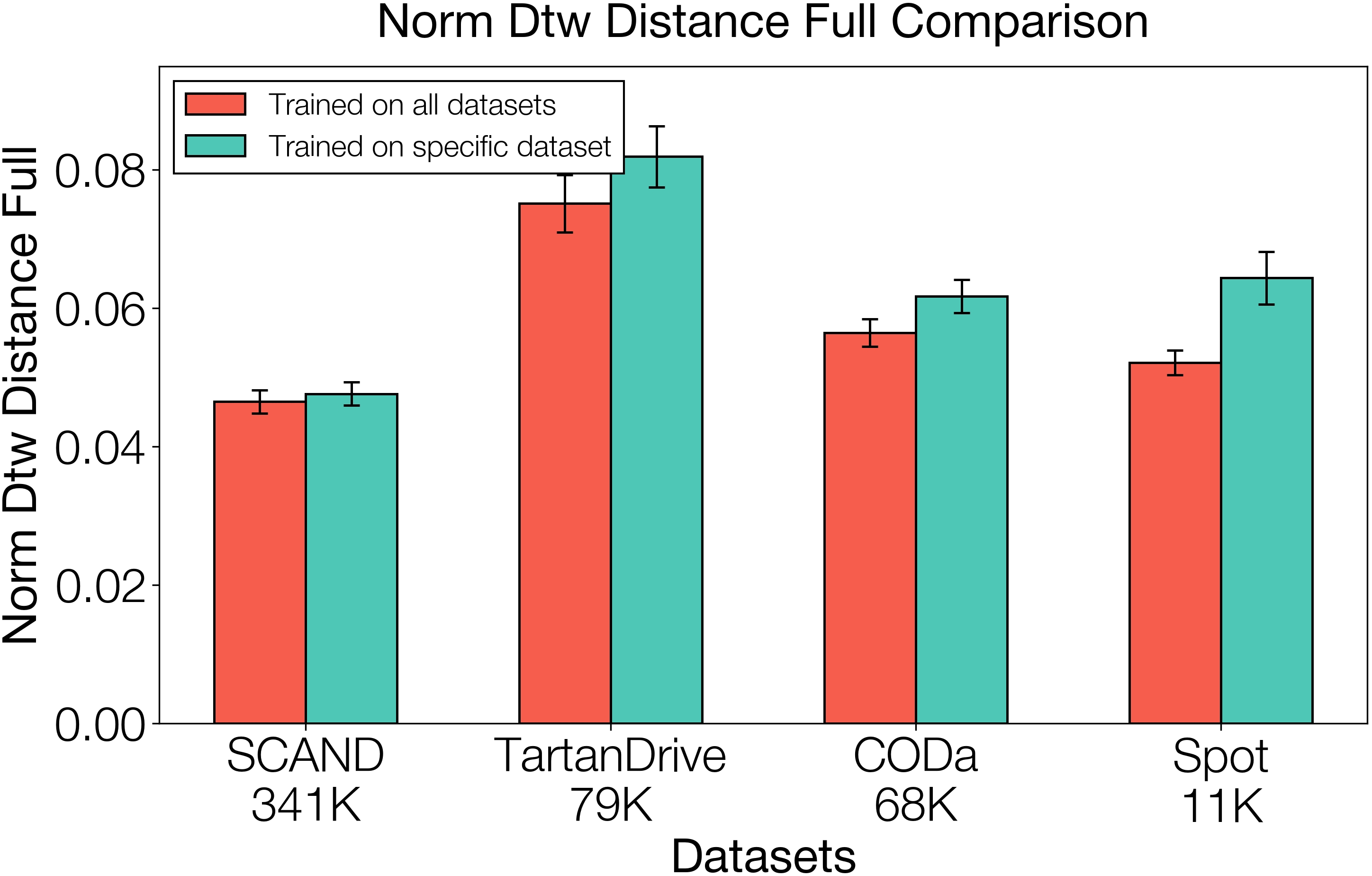
- Better from pooled data: Training the planner on a mix of different robots and terrains helped it generalize better than training on a single dataset.
- More reliable plans: The affordance model filtered out unrealistic or unsafe paths the planner sometimes suggested (like going through obstacles), which significantly boosted success rates in challenging, unfamiliar scenarios. In certain settings, that meant up to roughly triple the success rate compared to not filtering.
Why this matters:
- Robots get more dependable: The safety filter catches bad ideas before the robot tries them.
- One planner, many robots: You don’t need to rebuild a whole system for every new robot—just retune the affordance model.
- Human-friendly control: You can steer the robot’s style of movement using plain language.
5) What is the impact of this research?
VAMOS shows a practical way to build general-purpose robot navigation that:
- Scales with diverse data without getting confused by mixed abilities in the dataset.
- Transfers across different robot bodies with minimal changes.
- Accepts human guidance through natural language.
- Increases real-world reliability by checking physical feasibility before acting.
Big picture: This is a step toward “open-world” robots that can understand scenes, plan smart paths, respect their physical limits, and respond to simple instructions—making them safer and easier to deploy in everyday environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of unresolved issues and missing analyses that future work could address.
- Monocular-only perception: robustness and gains from adding depth/LiDAR, stereo, or multi-sensor fusion to both planner and affordance model are unexplored.
- Elevation map source and quality: the paper does not specify how elevation maps are built on real robots (sensor modality, mapping pipeline, update rate, failure cases), nor quantify how map errors impact Fπ and overall success.
- Sim-to-real transfer of Fπ: the affordance model is trained entirely in simulation with a proxy Spot policy; there is no quantitative analysis of domain mismatch, calibration, or how diversity/randomization choices affect real-world reliability.
- Limited embodiment coverage: cross-embodiment claims are demonstrated on only two platforms (Spot, Hound); generalization to broader embodiments (tracked vehicles, micro-rovers, aerial, amphibious) and varied kinematics is untested.
- Heading discretization in Fπ: using eight discrete headings may miss feasibility constraints for non-holonomic vehicles with tight turning radii; continuous heading/action conditioning and kinematic constraints are not considered.
- Path-level feasibility modeling: Fπ scores points independently and aggregates via min; modeling cumulative risk, recovery likelihood, stability margins, slip, and energy/comfort costs along trajectories remains open.
- Candidate diversity and recall: the VLM’s K candidate paths may omit the truly feasible/optimal route; how to ensure diverse, high-recall proposals (beam search, coverage metrics, diversity regularizers) is not studied.
- Selection objective: re-ranking uses only affordance; trade-offs with goal progress, path length, smoothness, and language preferences are not formulated, tuned, or ablated.
- Occlusions and long-range goals: missions require the goal to be in the image; rotating in place to re-acquire the goal is brittle under occlusion or complex layouts; map/memory-based goal reasoning and multi-view planning are not addressed.
- Ground-plane projection limits: projecting pixel paths to a “ground plane” can be inaccurate on stairs, ramps, multi-level structures, and steep slopes; a 3D-aware projection and elevation-aware path lifting is not presented or validated.
- Calibration sensitivity: the approach assumes known intrinsics/extrinsics; sensitivity to calibration errors, camera height/tilt changes, and lens distortions is not evaluated.
- Runtime and resource footprint: inference latency, throughput, onboard compute requirements, and energy use for the VLM and Fπ are not reported, leaving real-time viability uncertain.
- Parameter sensitivity: key hyperparameters (path horizon H, K candidates, waypoint count k and executed m, softmax temperature β) lack ablation, tuning guidance, and sensitivity analysis.
- Failure mode analysis: the paper reports SR/timeouts/interventions but does not categorize failures (perception errors vs. bad proposals vs. affordance miscalibration) or provide corrective strategies.
- Dynamic obstacles and social compliance: handling moving agents, human-robot interaction, and social norms (despite training on SCAND) is not tested or evaluated.
- Safety guarantees: no formal safety constraints or guarantees (collision avoidance bounds, certified filtering) are integrated; how language steerability interacts with safety is not specified.
- Language steerability robustness: quantitative evaluation is limited (single image, VLM-as-a-judge); robustness to ambiguous, contradictory, or long-horizon instructions and human-in-the-loop trials is missing.
- Preference-affordance integration: when language preferences conflict with feasibility, the decision logic (weights between preference satisfaction and Fπ) is undefined; principled multi-objective fusion is absent.
- Data curation transparency: the “empirically determined” data mix and filtering (curvature, horizons) are not detailed; contributions of each dataset and potential negative transfer are not ablated.
- Goal encoding as text: the numeric coordinate tokenization format, its errors, and generalization across scales/units are not analyzed; alternative spatial goal encodings could be explored.
- Map scale and footprint: Fπ’s map window (W×H), metric scale, and alignment across robots are unspecified; sensitivity to map resolution and footprint size is unknown.
- Affordance training labels: short-horizon binary success may miss longer-horizon feasibility (e.g., dead-ends, turning feasibility later); richer labels (distance-to-failure, success probability over horizons) are unexplored.
- Online adaptation: the system does not learn from deployment (no self-calibration, no online updates to VLM/Fπ) or exploit feedback from π to improve proposals and rankings over time.
- Evaluation breadth and statistics: only five trials per course and some missing baseline metrics (— entries); statistical significance, environmental diversity (weather, nighttime, mud, snow), and broader stress testing are lacking.
Practical Applications
Practical Applications of VAMOS
Below, applications are grouped as Immediate Applications (deployable now with typical robotics infrastructure) and Long-Term Applications (requiring further research, scaling, or development). Each item notes sectors, actionable use cases, potential tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
- Robotics and Logistics — Drop‑in, steerable navigation for mobile robots
- Use cases: Warehouse/campus delivery robots that must avoid stairs, prefer ramps or sidewalks, and adapt routes via natural language (e.g., “keep to the right,” “avoid grass,” “take the ramp”).
- Tools/products/workflows: “VAMOS Navigator SDK” integrating the VLM path planner with per‑robot affordance adapters; ROS node exposing a path‑in‑image API; operator UI overlaying candidate paths and affordance heatmaps; soft re‑ranking to inject safe stochasticity.
- Assumptions/dependencies: Monocular RGB camera; reliable elevation map or depth source; calibrated intrinsics/extrinsics; a low‑level locomotion controller (velocity/position tracking); local/global localization (e.g., GPS/SLAM); compute for LoRA‑finetuned VLM; safety monitors.
- Construction and Mining — Safer autonomy assistance on uneven terrain
- Use cases: Site inspection carts/UGVs that must traverse ramps and avoid steps, ruts, or loose aggregate; choose traversable detours around temporary obstacles.
- Tools/products/workflows: Simulation‑trained affordance models tailored to site vehicles; “Embodiment Adapter” training loop to update affordance with new terrain catalogs; deployment in a receding horizon scheme for cautious long‑range goals.
- Assumptions/dependencies: High‑fidelity terrain models and elevation maps; sim‑to‑real transfer across season/weather; integration with existing safety interlocks; operator language prompts.
- Public Safety/Defense — Cross‑embodiment mission planning and safety gating
- Use cases: Search-and-rescue teams fielding both legged and wheeled platforms; swap affordance modules while reusing the same planner so each robot picks feasible routes (e.g., legged up stairs, wheeled via ramp).
- Tools/products/workflows: “Cross‑Embodiment Deployment Kit” with pre‑trained planners and affordance modules; mission steerability via constrained language prompts (“avoid debris,” “stay on concrete”); route filtering that rejects physically infeasible plans (3× reliability observed).
- Assumptions/dependencies: Robust comms and localization; validated affordance scores per embodiment; scenario‑appropriate risk thresholds; human-in-the-loop oversight.
- Healthcare (Hospitals) — Service robot navigation with accessibility preferences
- Use cases: Hospital delivery robots that avoid stairs, prefer ramps/elevators, and navigate cluttered corridors under low light; quick operator steering (“avoid waiting area,” “take corridor B”).
- Tools/products/workflows: VLM goal specification from hospital map waypoints; text preference profiles (e.g., “accessibility mode”); affordance re‑ranking that enforces non‑stair policies for wheeled robots.
- Assumptions/dependencies: Reliable floor‑level mapping; elevator integration; staff training for language steerability; HIPAA/privacy compliance (camera use).
- Agriculture — Row navigation and terrain preference control
- Use cases: Orchard/field robots that follow rows, avoid crop beds, and prefer compacted soil tracks; steer with natural language (“stay in row,” “avoid soft soil”).
- Tools/products/workflows: Affordance training in simulated field terrains; waypointing along GPS/RTK rows; VLM overlay of candidate paths for operator validation.
- Assumptions/dependencies: Robust elevation/terrain sensing in foliage; localization under canopy; seasonal sim‑to‑real transfer; weather‑hardening.
- Infrastructure Inspection — Reliable mobility for refineries, plants, and campuses
- Use cases: Routine inspection robots navigating complex facilities; obey route constraints (e.g., “no stairs,” “stay out of high‑traffic zones”).
- Tools/products/workflows: Affordance‑gated mission planner; “Route Compliance” language prompts; receding horizon control with periodic re‑planning around occlusions.
- Assumptions/dependencies: Accurate, up‑to‑date facility maps; safe speed limits; hazard detectors; calibration in GPS‑denied environments.
- Software (Autonomy Stacks) — Path‑in‑image interface and adapter layer
- Use cases: Integrate a VLM that predicts continuous 2D image paths into existing stacks; re‑rank via affordance; feed selected waypoints to existing controllers.
- Tools/products/workflows: “Path‑Planning VLM API” and “Affordance Heatmap Service”; LoRA‑based finetuning recipes; CI pipelines to validate planner reliability against unit terrains.
- Assumptions/dependencies: Standardized elevation map format (windowed around robot); heading discretization alignment; performance budgets for real‑time inference.
- Academia/Education — Teaching hierarchical VLA and cross‑embodiment methods
- Use cases: Courses and labs demonstrating decoupled semantic planning and embodiment grounding; assignments on simulation‑trained affordances and data pooling from heterogeneous robots.
- Tools/products/workflows: Reproducible finetuning scripts (e.g., PaliGemma 2 3B with LoRA); dataset curation filters (curvature, horizons, noise); steerability augmentation via VLM annotations.
- Assumptions/dependencies: Access to datasets (SCAND, TartanDrive 2, CODa, in‑domain); simulator (Isaac Lab) and procedural terrain generators; GPU resources.
- Daily Life (Consumer Robotics) — Voice‑steered home navigation
- Use cases: Home service robots (fetch, delivery) obeying user preferences (“avoid carpet,” “go around the coffee table”); rejecting infeasible paths to reduce accidents.
- Tools/products/workflows: Lightweight affordance adapters per model of home robot; user‑level prompts; AR overlay of candidate paths for transparency.
- Assumptions/dependencies: On‑device or edge compute; privacy‑preserving camera use; depth/elevation estimation indoors; household variability and clutter.
Long‑Term Applications
- City‑scale general‑purpose navigation across fleets
- Use cases: Mixed fleets (delivery carts, legged robots) operating outdoors with shared planners and embodiment‑specific affordance modules; mission steerability by city operations staff.
- Tools/products/workflows: Fleet orchestration layer that distributes goals and preference policies; centralized “Adapter Store” for affordance models by robot type.
- Assumptions/dependencies: Robust localization without pre‑built maps; large‑scale dataset pooling; urban safety certification.
- Mapless navigation at scale with robust open‑world generalization
- Use cases: Reduce dependence on traditional modular stacks and maps; rely on image‑space planning plus embodiment gating in previously unseen environments.
- Tools/products/workflows: Continuous learning pipelines; failure‑aware replanning; self‑supervised data capture for coverage expansion.
- Assumptions/dependencies: Strong domain generalization; reliable elevation estimation from monocular cues; on‑device adaptation mechanisms.
- Standardized affordance libraries and certification frameworks
- Use cases: Industry‑wide affordance benchmarks for different embodiments; certification that a planner/affordance pairing reliably rejects infeasible actions (safety gating).
- Tools/products/workflows: Public affordance datasets and testing suites; regulatory guidelines referencing embodiment‑aware gating.
- Assumptions/dependencies: Agreement on elevation map and heading standards; policy/regulatory adoption; third‑party audits.
- Cross‑domain extension to aerial, underwater, and manipulators
- Use cases: Drones with 3D path‑in‑image planning (e.g., avoidance of no‑fly zones); underwater ROVs respecting hull clearances; mobile manipulators grounding reachability.
- Tools/products/workflows: New 3D/SE(3) path interfaces; domain‑specific affordance models trained in high‑fidelity simulators.
- Assumptions/dependencies: Appropriate sensing modalities (sonar/lidar); re‑designed interface to capture altitude/depth; domain constraints (e.g., currents, wind).
- Multi‑robot teaming with language‑steered coordination
- Use cases: Teams of heterogeneous robots assigned complementary routes (“wheeled take ramps, legged clear stairs”); dynamic re‑planning from operator intent.
- Tools/products/workflows: Coordination policies that compose multiple candidate paths with team‑level affordance aggregation; language interfaces for task allocation.
- Assumptions/dependencies: Reliable inter‑robot comms; conflict resolution; scalable inference.
- Accessibility‑aware routing for public spaces
- Use cases: Municipal planning tools to simulate accessible routes; cross‑embodiment guidelines for service robots (e.g., ramp coverage vs stairs).
- Tools/products/workflows: Accessibility policy layers expressed in natural language (preferences), enforced by affordance gating; public maps with terrain affordance tags.
- Assumptions/dependencies: High‑quality urban terrain data; integration with city GIS; policy alignment with ADA/regional accessibility standards.
- Planetary exploration and hazardous environments
- Use cases: Legged/wheeled rovers selecting safe traversals over regolith, rocks, craters; operator steerability under communication delays.
- Tools/products/workflows: High‑fidelity planetary simulators for affordance training; offline VLM finetuning with synthetic vistas; conservative gating to minimize mission risk.
- Assumptions/dependencies: Radiation‑hardened compute; limited sensing; uncertain elevation maps; autonomous recovery behaviors.
- Energy sector inspection (refineries, power plants, offshore)
- Use cases: Robots navigating complex industrial sites while respecting embodiment constraints and risk‑based preferences (e.g., avoid slick surfaces).
- Tools/products/workflows: Domain‑specific affordance models validated against industrial hazards; operator prompt templates for safety policies.
- Assumptions/dependencies: Industrial certification; robust sensing under extreme conditions; incident reporting integration.
- Consumer AR navigation assistance
- Use cases: Smartphone apps that visualize candidate pedestrian paths in camera view, modulated by user preferences (“avoid stairs,” “well‑lit routes”).
- Tools/products/workflows: On‑device VLM path prediction; crowdsourced elevation/obstacle maps; accessibility preferences.
- Assumptions/dependencies: Reliable pose estimation; privacy safeguards; varied device capabilities.
- Adaptive compliance and workforce training
- Use cases: Tools to encode safety and accessibility policies as language preferences that constrain route selection; training operators to steer missions safely.
- Tools/products/workflows: “Mission Steer” prompt libraries; simulation‑based training that shows how affordance gating avoids accidents; audit logs of rejected plans.
- Assumptions/dependencies: Organizational adoption; clear risk thresholds; standardized reporting.
Notes on global assumptions and dependencies across applications:
- Sensor stack: A monocular RGB camera plus a reliable source of local elevation maps (from depth, stereo, lidar, or learned estimation) and calibrated camera intrinsics/extrinsics.
- Control stack: A low‑level locomotion policy able to track waypoints (velocity or position control) and a receding horizon planner interface.
- Localization: Goal coordinates must be convertible to image‑frame inputs; fallback behaviors (e.g., rotate to make the goal visible) are assumed.
- Compute and models: LoRA‑finetuned VLM (e.g., PaliGemma 2 3B) with sufficient real‑time throughput; simulation environments for affordance training with procedurally generated terrains.
- Safety and policy: Embodiment‑aware affordance gating is crucial for reliability; human oversight, risk thresholds, and domain‑specific safety standards impact deployability.
- Data and generalization: Performance depends on diverse, heterogeneous training data and the sim‑to‑real fidelity of the affordance models; domain shifts (weather, lighting, clutter) must be addressed.
Glossary
- 2.5D costmap: A height-annotated grid representation used in navigation that approximates 3D structure while remaining a 2D map. "Second, the intermediate representations, such as 2.5D costmaps, can abstract away valuable information and create performance bottlenecks between modules."
- Affordance function: A model that predicts whether specific states or path elements are traversable by a given robot policy. "a capability-aware affordance function evaluates and re-ranks the 3D candidate paths to determine which path the robot should execute in the real world based on low-level policy capabilities."
- Affordance modulation: Using an affordance model to filter or re-rank high-level plan proposals so they align with robot capabilities. "corrected by the affordance function modulation."
- Binary cross-entropy loss: A loss function for binary classification tasks, here used to train the affordance function from success/failure labels. "by minimizing a standard binary cross-entropy loss"
- Cellular automata: A procedural generation technique using simple local rules on grids; here used to synthesize irregular terrains in simulation. "we used cellular automata to generate smooth, uneven terrains."
- Chain-of-thought prompting: A prompting strategy that elicits step-by-step reasoning from a LLM to improve labeling or judgment quality. "use chain-of-thought prompting to ask GPT-5-mini"
- Cross-embodiment navigation: Navigation methods that transfer across different robot bodies and capability profiles. "general-purpose cross-embodiment and steerable navigation policies."
- Cumulative affordance: An aggregate traversability score for an entire candidate path, often computed as the minimum per-step affordance along that path. "a cumulative affordance is computed as the minimum affordance score along each path"
- Embodiment grounding: Aligning high-level plans with the physical capabilities and constraints of a specific robot platform. "decouples semantic planning from embodiment grounding"
- Elevation map: A grid map encoding terrain height values around the robot, used to assess traversability. "a random elevation map M is spawned"
- Extrinsic matrix: The camera pose parameters mapping coordinates from world to camera frames. "We use known or estimated intrinsic and extrinsic matrices to project the 3D poses recorded in the datasets into 2D image trajectories."
- Foundation model: A large pre-trained model whose capabilities scale with diverse data and can be adapted to downstream tasks. "The success of foundation models in other domains has inspired similar efforts in robotics"
- Hindsight labeling: Creating supervision by labeling trajectories or targets from future states after data collection. "we label trajectories in hindsight using camera poses at a horizon H into the future."
- Intrinsic matrix: The camera calibration parameters that map 3D camera coordinates to 2D image pixels. "We use known or estimated intrinsic and extrinsic matrices to project the 3D poses recorded in the datasets into 2D image trajectories."
- Low-rank adapters (LoRA): Parameter-efficient fine-tuning modules inserted into a pre-trained model to adapt it without full retraining. "We use low-rank adapters (LoRAs) since training our models using full-parameter fine-tuning vs LoRA yields similar performance."
- Monocular RGB image: A single standard color image (as opposed to stereo or depth) used as visual input. "to go from a monocular RGB image "
- Odometry: Pose estimates of a robot over time used for labeling trajectories and training navigation models. "contains odometry-labeled data"
- Out-of-distribution (OOD): Inputs or conditions that differ significantly from the training distribution, often causing model errors. "in OOD settings"
- Procedurally generated terrains: Synthetic environments created algorithmically to provide diverse training conditions in simulation. "over a large variety of procedurally generated terrains"
- Receding horizon control: A control scheme that repeatedly plans over a short time horizon and replans as new observations arrive. "in a receding horizon control fashion"
- Sim-to-real transfer: The process of ensuring policies or models trained in simulation perform well on real hardware. "for proper sim-to-real transfer"
- Soft sampling: Selecting among candidate plans probabilistically (e.g., via Softmax) to inject controlled stochasticity. "we can sample with soft sampling to allow for some stochasticity in path selection"
- Traversability estimation: Predicting whether terrain or paths are drivable/walkable for a given robot. "traversability estimation literature"
- Vision-Language-Action (VLA) model: A model that connects visual input and language to action outputs for embodied tasks. "a hierarchical VLA that decouples semantic planning from embodiment grounding"
- Vision-LLM (VLM): A model that jointly processes images and text for reasoning and prediction. "a high-capacity vision-LLM (VLM)"
- VLM-as-a-judge: Using a vision-LLM to evaluate or score outputs (e.g., preference alignment) rather than to act directly. "Using VLM-as-a-judge (ChatGPT 5)"
- Wave function collapse: A constraint-based algorithm for procedural content generation that assembles patterns consistent with local rules. "using wave function collapse."
Collections
Sign up for free to add this paper to one or more collections.