Fluidity Index: Next-Generation Super-intelligence Benchmarks
Abstract: This paper introduces the Fluidity Index (FI) to quantify model adaptability in dynamic, scaling environments. The benchmark evaluates response accuracy based on deviations in initial, current, and future environment states, assessing context switching and continuity. We distinguish between closed-ended and open-ended benchmarks, prioritizing closed-loop open-ended real-world benchmarks to test adaptability. The approach measures a model's ability to understand, predict, and adjust to state changes in scaling environments. A truly super-intelligent model should exhibit at least second-order adaptability, enabling self-sustained computation through digital replenishment for optimal fluidity.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to test very smart AI systems, called the Fluidity Index (FI). Instead of only checking if an AI gets fixed questions right, FI checks how well the AI notices changes in its world, updates its guesses, and keeps doing the right thing as things keep changing. In short: it measures adaptability, not just accuracy on a static test.
What questions are the authors asking?
They’re asking:
- How can we measure an AI’s ability to switch context and stay consistent when the situation changes?
- How can we tell if an AI can plan for the future, not just react to the present?
- What does “super‑intelligent” mean in practice, and how could we test it fairly in the real world?
How do they measure “fluidity”?
Think of an AI like a driver using GPS. Roads close, traffic changes, and the GPS must update the route. A “fluid” AI updates its plan as much as the world actually changes—no more, no less.
The Fluidity Index tries to capture that idea with snapshots taken over time as the environment changes. For each change, it compares:
- the size of the real change in the environment to
- how much the AI’s prediction or plan changes.
The core piece is called Accuracy Adaptation (AA). For one change, it’s defined as:
What this means in plain terms:
- If the AI adjusts its prediction by about the same amount the world changed, that’s “just right.”
- If it barely adjusts when the world changed a lot, that’s “under‑reacting.”
- If it changes too much, that’s “over‑reacting.”
The Fluidity Index is a summary of these AA scores across many changes. It’s designed to reward “just right” adjustments and penalize under‑ and over‑reactions.
The paper also uses a few key ideas:
- Closed‑ended vs open‑ended tests: Closed‑ended is like a fixed quiz with one right answer per question. Open‑ended is more like real life: the situation keeps changing, and there isn’t a small, fixed set of questions.
- Closed‑loop: The AI does something, sees the result, and uses that feedback to improve its next step.
- Tokens: The chunks of text an AI reads or writes (roughly like words). More tokens often mean more “thinking.”
- “Current”: The authors use “current” as a simple stand‑in for the resources the AI needs to keep working (like electricity or money for running the model).
- Test‑time compute: Letting the AI “think longer” by using more steps/tokens before answering, to boost accuracy.
- Scaling environment: A setting that keeps getting more complex as the test goes on, so the AI must adapt plans and resources over time.
The authors also describe “orders” of adaptability:
- First‑order: The AI can adjust its answers as things change right now.
- Second‑order: The AI can plan and manage its own resources to keep itself running (for example, budgeting tokens or time so it won’t “run out” mid‑task).
- Third‑order: The AI can manage tools and infrastructure over longer time spans (long‑term, self‑sustaining behavior).
They argue that a truly “super‑intelligent” system should achieve at least second‑order adaptability: it can keep itself going by smartly managing its resources in a changing world.
What did they find, and why does it matter?
What they argue and show evidence for:
- As AI models get bigger, they often get better at adapting, especially when allowed more test‑time compute (more “thinking” steps). This is sometimes called an “emergent” ability—new skills appear when models scale up.
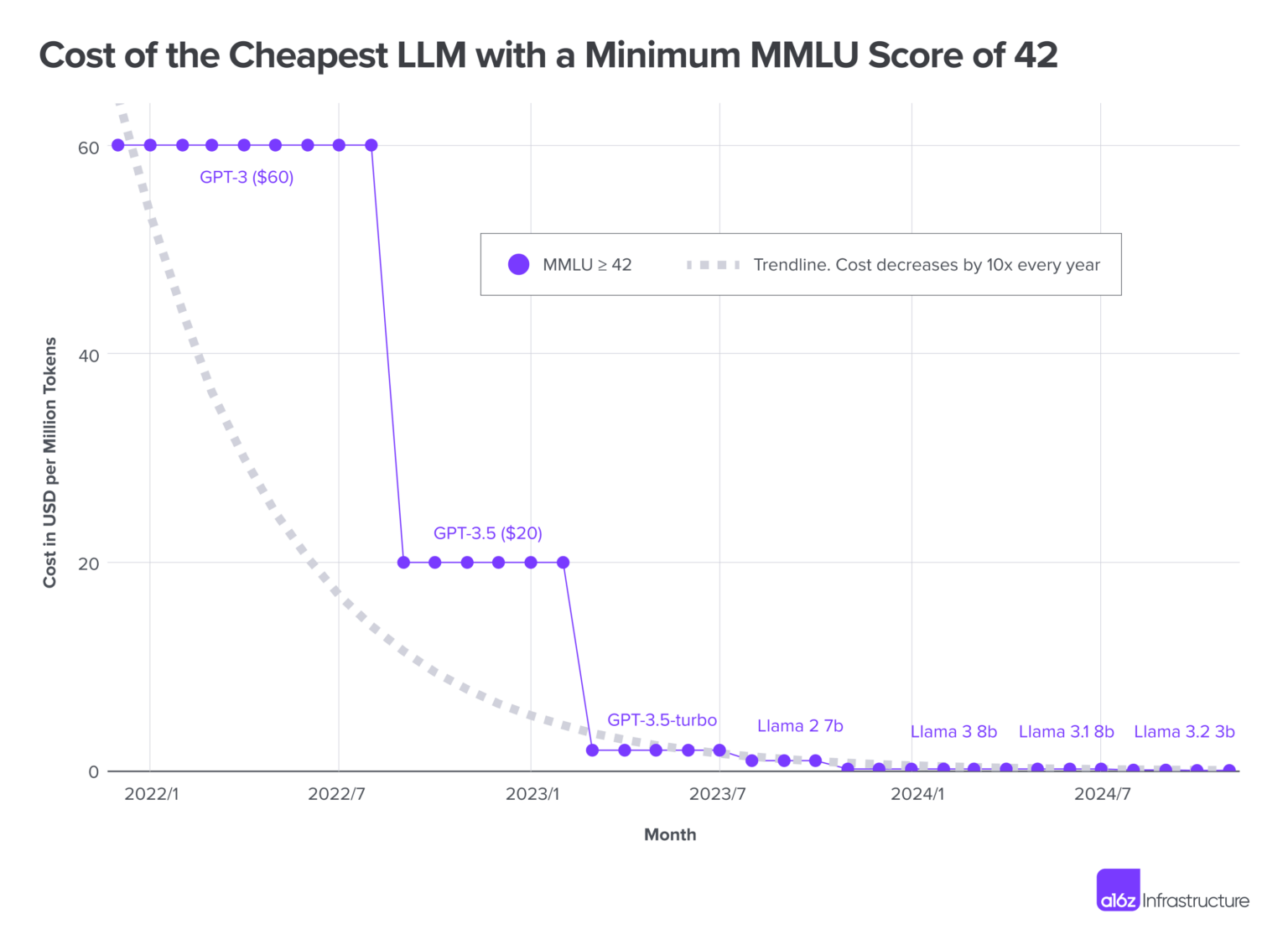
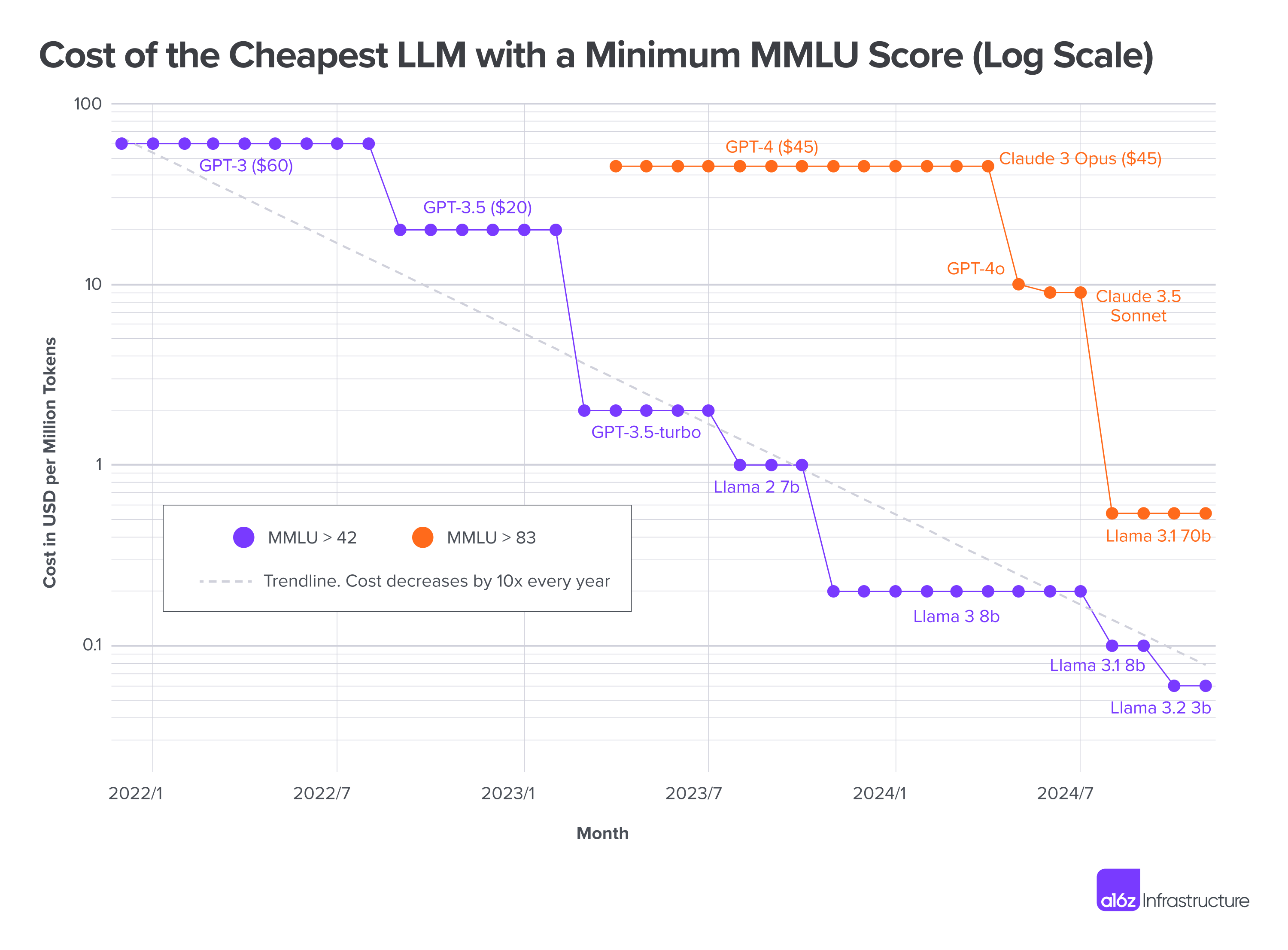
- Old‑style, closed‑ended tests (like big multiple‑choice exams) are getting cheaper and easier for large models to ace. That makes them less useful for measuring true intelligence over time.
- Because of this, we need tests that look like the real world: changing conditions, feedback loops, and resource limits. The Fluidity Index is meant to be such a benchmark.
- Early simulations and cost trends suggest FI could better highlight which models actually adapt well, not just which ones memorize answers.
Why it matters:
- Real life isn’t a fixed quiz. If we want AI to help with science, medicine, robots, or complex planning, it must adapt as things change. FI focuses on that exact skill.
- It encourages building AIs that can plan ahead, manage their “thinking budget,” and stay reliable even when the ground shifts.
What could this change in the future?
If widely adopted, the Fluidity Index could:
- Shift how we judge “smart” AI—from static accuracy to dynamic adaptability.
- Push developers to build models that plan, budget, and self‑correct in real time.
- Help identify safer, more reliable systems for real‑world use, because adaptable systems are better at handling surprises.
- Spark new research on “self‑sustaining” AI agents that manage their own resources responsibly (and also raise important questions about alignment and control—how to keep such systems goal‑aligned with humans).
In short, this paper proposes a new, more realistic way to test AI: reward models that notice change, adjust the right amount, and keep themselves running smoothly as the world keeps moving.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of the paper’s key knowledge gaps, methodological limitations, and open questions that remain unresolved and that future researchers could directly act upon:
- Precise operationalization of “environment state” and its “magnitude of change”: specify the state space (e.g., vectorized variables, modalities), the norm/distance used to measure change (e.g., , , task-specific metrics), and how multi-dimensional or multi-modal changes are aggregated.
- Clarify how to compute
AA_iwhen the denominatorChange in Initial Environment State_iis zero (no change), including whether such events should be excluded, smoothed, or separately handled to avoid undefined values. - Resolve inconsistency in the interpretation of FI: the paper alternately claims FI correlates with inefficiency and that “high FI scores” indicate better adaptivity; define whether higher or lower FI is desirable and standardize this throughout.
- Provide syntactically complete, unambiguous formulas for
FI(t)and integral expressions (several equations are missing closing brackets/terms), and define every variable explicitly (e.g., , , , , , , “current”). - Define what
iindexes: is it agent instances, actions, time steps, or environment changes? Specify aggregation across time and agents, and whether FI is averaged per action, per episode, or per environment change. - Map predictions to a numeric space: if model outputs are text, structured plans, or categorical labels, specify the similarity/distance function used in
|New Prediction - Old Prediction|(e.g., semantic similarity, task-specific error, regret). - Justify the normalization by
NC(number of environment changes): consider weighting by change magnitude, task importance, or uncertainty; evaluate whether simple averaging masks performance on large vs small shifts. - Characterize statistical properties of FI: sensitivity to measurement noise, invariance to units/scales, monotonicity, expected ranges, bounds, and whether FI is robust under non-stationary drift and concept shift.
- Provide a reproducible closed-loop, open-ended benchmark specification: concrete environments, interfaces/APIs, logging protocols, constraints, and evaluation procedures enabling independent replication.
- Establish baselines and comparative metrics: compare FI against established control/RL measures (e.g., tracking error, regret, adaptation latency, stability margins) and demonstrate when FI offers unique diagnostic value.
- Add empirical evidence: include experiments with multiple models, datasets, and environments; report numerical FI scores, confidence intervals, statistical significance, and ablations (e.g., test-time compute vs no test-time compute).
- Define the “self-replenished endpoint” and closed-loop mechanics: what resources are replenished (compute, money, energy), by what actions, and how is replenishment measured, safeguarded, and evaluated in the benchmark?
- Unambiguously define “current” (and “currency”): whether it denotes electrical power, computational budget, energy consumption, monetary cost, or token budget; specify units, measurement methods, and normalization across heterogeneous hardware.
- Operationalize throughput and “material transfer limit”: specify thresholds, measurement protocols, and domain for these limits; derive or empirically validate the “sub-optimal/optimal/beyond optimal” conditions.
- Formalize the “order of fluidity” (first/second/third): provide rigorous definitions linking token usage, adaptability, autonomy, and infrastructure, rather than conflating economic self-sustainability with technical adaptability.
- Address overreaction vs underreaction: the metric yields
AA_i < 0for overcorrection; define how to penalize or balance responsiveness vs stability (e.g., asymmetric loss, hysteresis, regularization). - Temporal granularity and latency: define snapshot frequency, how environment changes are detected/aligned with prediction updates, how action latencies are handled, and the time window over which FI is computed.
- Partial observability and uncertainty: the benchmark assumes the environment is “ground truth”; specify how to handle noisy observations, delayed labels, stochastic transitions, and model uncertainty.
- Multi-agent interactions: if multiple agents are involved, define inter-agent coupling, interference, credit assignment, and whether FI is computed per agent or jointly.
- Scaling environment design: detail how environment complexity is increased (curriculum, POET-like generators), how complexity is measured, and how complexity trajectories affect FI comparability.
- Economic assertions need evidence: justify or retract claims such as negative token costs and the use of MMLU=83 as a super-intelligence threshold; provide data, models, and sensitivity analyses for such extrapolations.
- Fairness and comparability constraints: standardize tool access, external endpoints, compute budgets, and energy measurement so FI comparisons across models are meaningful and not confounded.
- Integration with token budgeting methods (e.g., D-LLM, SelfBudgeter): specify algorithms for using FI to guide dynamic token allocation and evaluate whether FI-driven budgeting improves outcomes.
- Dimensional consistency and units: ensure all equations are dimensionally coherent; define FI’s range, expected scaling behavior, and interpretability as a unitless index or a standardized score.
- Model error accumulation: the paper claims errors compound; formalize this with a recurrence or dynamical error model, derive bounds, and empirically validate compounding effects under different adaptation policies.
- Safety and alignment of “self-interested models”: specify safeguards, evaluation metrics for resource-seeking behaviors, and protocols to prevent harmful exploitation of replenishment endpoints.
- Dataset, code, and pricing sources: provide data availability, licensing details, and methods for “internet archival pricing” so cost analyses are reproducible and auditable.
- Benchmark platform architecture: translate the theoretical formalizations into a concrete, open-source platform design (APIs, telemetry, event schemas, reproducibility guarantees, privacy/security considerations).
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s Fluidity Index (FI), Accuracy Adaptation (AA), and closed-loop open-ended evaluation paradigm to improve real systems today.
- Software/AI infrastructure: Production FI monitoring for drift and adaptation
- What: Add FI/AA to MLOps observability to detect under/over-reaction to distribution shifts (AA→1 = lag; AA<0 = overreaction), and gate releases based on FI thresholds.
- Tools/products/workflows: FI collector SDK; FI metrics in Prometheus/Grafana; CI/CD gates on FI under synthetic context-shift tests; incident runbooks tied to FI regressions.
- Assumptions/dependencies: Access to instrumentation of environment state deltas; definition of “magnitude of change” per domain; minimal overhead for logging.
- Software/cloud: FI-guided adaptive inference controllers (token budgeting/test-time compute)
- What: Use FI as a real-time control signal to modulate chain-of-thought depth, model choice, or routing to cheaper/faster models when contexts shift; curb overcorrection.
- Tools/products/workflows: Middleware similar to SelfBudgeter/D-LLM but closed-loop FI-aware; policy that increases/decreases test-time compute based on AA error.
- Assumptions/dependencies: Latency and cost budgets; clean mapping from environment changes to controller inputs.
- Product experimentation: A/B testing under shifting contexts
- What: Evaluate prompts/models/agents by FI across traffic segments experiencing different state changes (seasonality, campaigns, UI changes); pick variants that adapt best, not just average accuracy.
- Tools/products/workflows: FI-enabled experiment platform; contextual bucketing; FI uplift reports.
- Assumptions/dependencies: Reliable context shift annotation; outcome metrics tied to the changing state.
- Recommenders/ads/e-commerce: Real-time drift handling and exploration–exploitation tuning
- What: Use FI/AA to tune learning rates, exploration, and re-ranking when user/market signals change rapidly; flag overreaction (AA<0) during shocks.
- Tools/products/workflows: Bandit/RL pipelines with FI reward shaping; FI dashboards in ad auctions.
- Assumptions/dependencies: Streaming features, stable reward proxy; cost of exploration acceptable.
- Cybersecurity: SOC copilot response calibration
- What: Measure AA during evolving incidents (escalation, lateral movement) to detect sluggish or overzealous responses; auto-tune playbooks to maintain proportionality.
- Tools/products/workflows: SIEM/SOAR integrations with FI telemetry; policy guardrails keyed to AA thresholds.
- Assumptions/dependencies: Clear event-state encoding; human-in-the-loop escalation authority.
- Finance: Strategy robustness to regime shifts
- What: Backtest and live-test trading/risk models with FI under volatility/regime changes; select strategies with higher FI to reduce drawdowns when conditions change.
- Tools/products/workflows: FI-enabled backtesting; stress scenarios as controlled environment state deltas; live FI alerts.
- Assumptions/dependencies: Reliable regime-change labeling; slippage/latency modeled.
- Edge/IoT/energy: Adaptive on-device scheduling
- What: Adjust model size/frequency based on power/thermal/network changes; use FI to quantify whether the scheduler adapts proportionally to constraints.
- Tools/products/workflows: Runtime governors that switch precision/quantization; FI telemetry to device fleet managers.
- Assumptions/dependencies: Device telemetry access; safe fallback behaviors.
- Education: Adaptive tutoring systems
- What: Track AA as student mastery estimates shift; ensure the system neither ignores nor overreacts to new evidence about learner state; adapt lesson sequencing accordingly.
- Tools/products/workflows: FI-augmented mastery models; teacher dashboards highlighting low-FI scenarios.
- Assumptions/dependencies: Valid and frequent skill-state updates; privacy compliance.
- Customer support/assistants: Long-session context management
- What: Use FI to assess and tune assistants’ ability to keep track of evolving user goals over multi-turn sessions and across tickets.
- Tools/products/workflows: Conversation state trackers with FI scoring; retrieval depth modulated by AA.
- Assumptions/dependencies: Conversation state labeled or estimated; retrieval quality.
- Robotics (simulation-first): Domain randomization evaluation
- What: Evaluate RL/VLA agents by FI under randomization (friction, payload, visuals) to pick policies that adapt gracefully before real-world deployment.
- Tools/products/workflows: FI evaluator for Gym/Isaac/ROS sims; curriculum learning guided by low-FI failure modes.
- Assumptions/dependencies: Sim-to-real gap accounted for; environment deltas quantified.
- Policy/purchasing: SLAs and procurement tied to FI
- What: Add FI thresholds to public-sector and enterprise AI RFPs and SLAs as a complement to static accuracy; price models against FI at target drift profiles.
- Tools/products/workflows: FI certification tests; vendor scorecards including AA distributions under specified scenarios.
- Assumptions/dependencies: Standardized test suites; auditing capacity.
- Academia/R&D: Closed-loop open-ended benchmark harness
- What: Release a “ScalingEnv Gym” with FI as the primary metric for comparing methods (test-time compute, token budgeting, world models) under non-stationary tasks.
- Tools/products/workflows: Open-source environments, FI scoring API, leaderboards with AA over- and under-correction stats.
- Assumptions/dependencies: Community consensus on state-change definitions; reproducible seeds/logging.
Long-Term Applications
These concepts extend FI into higher-order adaptability (self-replenishing compute/infrastructure) and broader societal systems. They require further research, scaling, or regulatory developments.
- Software/cloud/SRE: FI-driven autonomous resource orchestration (second order)
- What: Agents that co-optimize accuracy, latency, and spend by allocating tokens/compute dynamically; reinvest savings/revenue to sustain their own inference budgets.
- Tools/products/workflows: “FI-2 Orchestrator” managing autoscaling, routing, and billing; budget-aware test-time compute managers.
- Assumptions/dependencies: Billing/API controls, spend governance, guardrails to prevent cost spirals; provable stability.
- Self-sustaining AI services (digital businesses)
- What: Vertical agents (e.g., lead-gen, L2 support) that earn revenue and use FI to balance adaptation speed vs cost, paying for their own compute.
- Tools/products/workflows: Revenue loop integration; FI-based throttle on acquisition vs cost of inference; autonomous cashflow monitors.
- Assumptions/dependencies: Monetizable task loops, fraud/safety controls, clear attribution to environment changes.
- Healthcare: Adaptive clinical decision support with safety guarantees
- What: FI-monitored CDSS that adapts to changing guidelines and patient physiology without overreacting; AA as a safety signal for escalation.
- Tools/products/workflows: FI as a regulated performance measure; prospective monitoring; human oversight workflows triggered by AA anomalies.
- Assumptions/dependencies: Regulatory approval, robust causal ground truth, bias mitigation, data privacy.
- Energy/smart grids: FI-guided demand-response and dispatch
- What: Balance load and storage under volatile renewables/prices; measure and optimize proportional adaptation to grid events with FI.
- Tools/products/workflows: Grid simulators with FI; controllers that adjust flexibility bids based on AA; co-optimization with carbon intensity.
- Assumptions/dependencies: Secure SCADA integration; latency guarantees; safety certification.
- Mobility/logistics: City-scale dynamic routing and supply chains
- What: FI-optimized routing/inventory policies under disruptions (weather, strikes, demand shocks); avoid whiplash effects (AA<0) and lag (AA→1).
- Tools/products/workflows: Digital twins with FI; contract terms tied to adaptation metrics; cross-fleet coordination.
- Assumptions/dependencies: High-fidelity data sharing; multi-party governance; resilience requirements.
- Standardization and regulation: FI as a recognized evaluation dimension
- What: International benchmark consortium defining FI protocols, test suites, and reporting formats; regulators reference FI in high-stakes domains.
- Tools/products/workflows: FI conformance tests; third-party audits; public leaderboards with domain-specific FI profiles.
- Assumptions/dependencies: Community buy-in, unambiguous environment-change definitions, reproducibility.
- On-device AI: Power/thermal-aware self-tuning assistants
- What: Personal and embedded assistants that adapt to device constraints and user context using FI; gracefully scale reasoning depth on-device.
- Tools/products/workflows: Runtime schedulers with FI; hybrid on-device/cloud offload triggers; energy-aware CoT.
- Assumptions/dependencies: Efficient runtimes, privacy-preserving telemetry, robust fallback.
- Safety/alignment: FI for “self-interested” model research
- What: Use FI/AA to study models’ proportional response under incentive changes, constraining overreaction and reward hacking in open-ended settings.
- Tools/products/workflows: Alignment evals using closed-loop FI; curricula that penalize AA extremes; oversight tooling.
- Assumptions/dependencies: Well-specified incentives; safe sandboxes; formal guarantees.
- Government oversight: FI-based supervisory dashboards for high-risk AI
- What: Continuous post-deployment monitoring of adaptation behavior in finance, healthcare, and public services.
- Tools/products/workflows: Regulatory telemetry pipelines; FI thresholds in compliance; alerting/recall procedures.
- Assumptions/dependencies: Legal mandate; privacy compliance; standard APIs.
- Embodied agents/robotics: Third-order adaptability (infrastructure-aware autonomy)
- What: Agents that manage their own power, maintenance, and compute budgets to sustain operation across long horizons, guided by FI volume criteria.
- Tools/products/workflows: Energy-harvesting planners; maintenance schedulers; FI-informed mission planners.
- Assumptions/dependencies: Reliable energy/storage estimates; safety cases; robust hardware.
- Marketplaces and procurement platforms: FI-scored model catalogs
- What: Buyers select models by FI under domain-specific drift profiles (e.g., legal, biomedical); contracts specify minimum FI performance.
- Tools/products/workflows: FI scorecards; independent testing labs; insurance products priced by FI risk.
- Assumptions/dependencies: Comparable, audited FI results; sector-specific testbeds.
- Lifelong education: FI for longitudinal learner modeling
- What: Systems that continuously adapt curricula while maintaining proportionality to learner state changes across years.
- Tools/products/workflows: FI-labeled learning trajectories; teacher co-pilots highlighting adaptation quality.
- Assumptions/dependencies: Longitudinal data access and ethics; interoperable standards (LMS/LRS).
Cross-cutting assumptions and dependencies
- Quantifying environment change: FI/AA require domain-specific, well-defined measures of state changes and prediction deltas.
- Closed-loop setups: Many applications need safe sandboxes or robust guardrails for live environment interaction.
- Data/privacy/compliance: Especially in healthcare, finance, and public sector.
- Economic trends: Some arguments (e.g., self-replenishing compute) assume continued inference cost declines and stable monetization paths.
- Stability and safety: Proportional control inspired by AA implies careful controller design to avoid oscillations or catastrophic overreaction.
Glossary
- Accuracy Adaptation: A normalized measure of how an agent’s prediction adjusts relative to the magnitude of an environmental change. "AA_i: Accuracy Adaptation for agent , defined by:"
- Chinchilla scaling: A scaling strategy showing that larger datasets with appropriate model sizes yield compute-optimal performance. "The chinchilla scaling realized compute-optimal LLMs that require less energy to train with larger training data, hence increasing their performance"
- Closed loop: A setup where the environment’s feedback is incorporated into the model’s decision-making process. "closed loop, where the system environment feedback is incorporated in to the model"
- Closed-loop benchmark: An evaluation setting where the environment is assumed to be factual and continuously informs the model. "a closed-loop benchmark where the environment is assumed to be ground truth"
- Closed-loop open-ended benchmark: A hybrid evaluation combining environmental feedback with open-ended, real-world interaction. "emphasizing closed-loop open-ended real-world benchmarks on model adaptability."
- Closed-ended benchmarks: Fixed-answer evaluations that test capabilities at predefined thresholds. "We differentiate between closed-ended benchmarks and open-ended benchmarks in our methodology"
- Cognitive flexibility: The ability to adapt strategies and thinking in dynamic contexts. "similar to the cognitive flexibility humans exhibit in complex, dynamic environments"
- Compute-optimal training: Training methods that minimize computational cost for a given performance target. "compute-optimal training of LLMs"
- Context continuity: Maintaining consistent understanding and behavior across evolving contexts. "measure the model's context switching and context continuity."
- Context switching: The ability to shift understanding and responses between differing contexts or tasks. "measure the model's context switching and context continuity."
- Digital replenishing: Using digital processes to sustain or restore computational resources autonomously. "self-sustained compute through digital replenishing"
- Emergence: Qualitative behavioral changes arising from quantitative increases in system scale or parameters. "Emergence is when quantitative changes in a system result in qualitative changes in behavior"
- Emergent functionalities: New capabilities that arise as models scale or contexts change. "emergent functionalities such as test-time compute where models perform recurrent token inferences to refine the model output accuracy."
- Emergent phenomena: System behaviors that appear unexpectedly due to interactions and scaling, not explicitly programmed. "an emergent phenomena of fluidity in LLMs."
- Fluidity Index (FI): A metric quantifying adaptability via prediction accuracy relative to environmental deviations over time. "This paper defines the Fluidity Index (FI) to measure the adaptability of models in scaling environments."
- Ground truth: The actual state of the environment used as the objective reference in evaluation. "a closed-loop benchmark where the environment is assumed to be ground truth"
- Intelligence threshold: A benchmark level (score or capability) indicating a minimum required performance. "As a closed-ended benchmark is an intelligence threshold, this will always hold true for all future models' closed-ended benchmark sets."
- Massive Multi-task Language Understanding (MMLU): A multi-domain benchmark used to assess broad language understanding. "At an intelligence threshold of 42 on the MMLU the experiment presented 1000 times reductions in price per million tokens"
- Model quantization: Compressing models to lower-precision representations to reduce size and compute costs while retaining performance. "Larger models also enable model quantization into relatively smaller models that perform above key intelligence thresholds."
- Non-linear intelligence increase: Performance gains that grow disproportionately (not linearly) with model scale or resources. "Non-linear intelligence increase in recent models and emergent phenomena enable for intelligence thresholds to be ever decreasingly expensive with larger model sizes."
- Open ended: An evaluation where the system interacts with the real world without fixed objectives or endpoints. "open ended, where the system is exposed to the real-world with live access to a self-replenished end point."
- Order derivatives: Higher-order measures of adaptability relating changes in token usage to resource “current.” "Order derivatives for relative change of tokens to the current."
- Scaling environment: An environment that grows in complexity via increasing state transitions over time. "A scaling environment is defined as an environment with increasing state transitions"
- Scaling laws: Empirical relationships that describe how performance changes with model size, data, or compute. "new scaling laws for continual improvements in model performance."
- Second order emergence: A higher-level pattern where trends of emergent abilities themselves become apparent. "An emergence of a trend of emergent abilities can be identified as a second order emergence for the rest of the fluidity index paper"
- Second-order adaptability: The capability to adapt not just to immediate changes but also to sustain itself via self-replenishing resources. "it should maintain a minimum of second-order adaptability to allow for self-sustained compute through digital replenishing for optimal fluidity."
- Self-replenished endpoint: A system endpoint that automatically sustains the resources needed for ongoing inference. "live access to a self-replenished end point."
- Self-replenish its infrastructure costs: The system’s ability to generate or recoup the resources required to cover operational costs autonomously. "where the model can self-replenish its infrastructure costs"
- Test-time compute: Additional computation during inference (not training) to improve accuracy or reasoning. "test-time compute where models perform recurrent token inferences to refine the model output accuracy."
- Throughput: The rate at which resource “current” or material is transferred over time. "Throughput can be formulated as:"
- Token allocation: Planning how to distribute tokens across present and future needs to maintain performance. "forecast its token allocation and replenish its inference capabilities accordingly"
- Token budgeting: Methods to optimize the number of tokens used to achieve efficiency and accuracy goals. "Recent token budgeting methods such as D-LLM ~\cite{jiang2025dllm} and SelfBudgeter ~\cite{li2025selfbudgeter} have attempted to improve model efficiency on intelligence thresholds by optimizing token usage"
Collections
Sign up for free to add this paper to one or more collections.