Yell At Your Robot: Improving On-the-Fly from Language Corrections
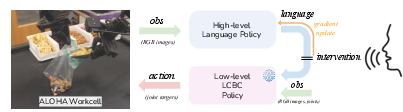
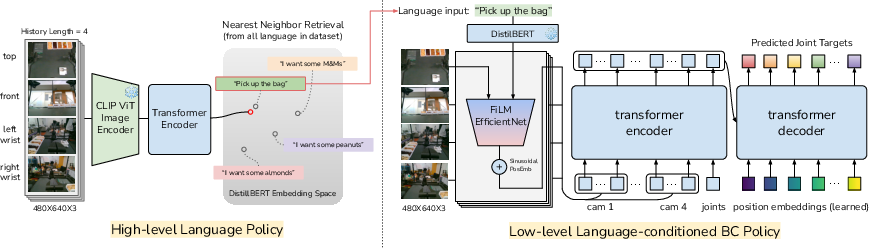
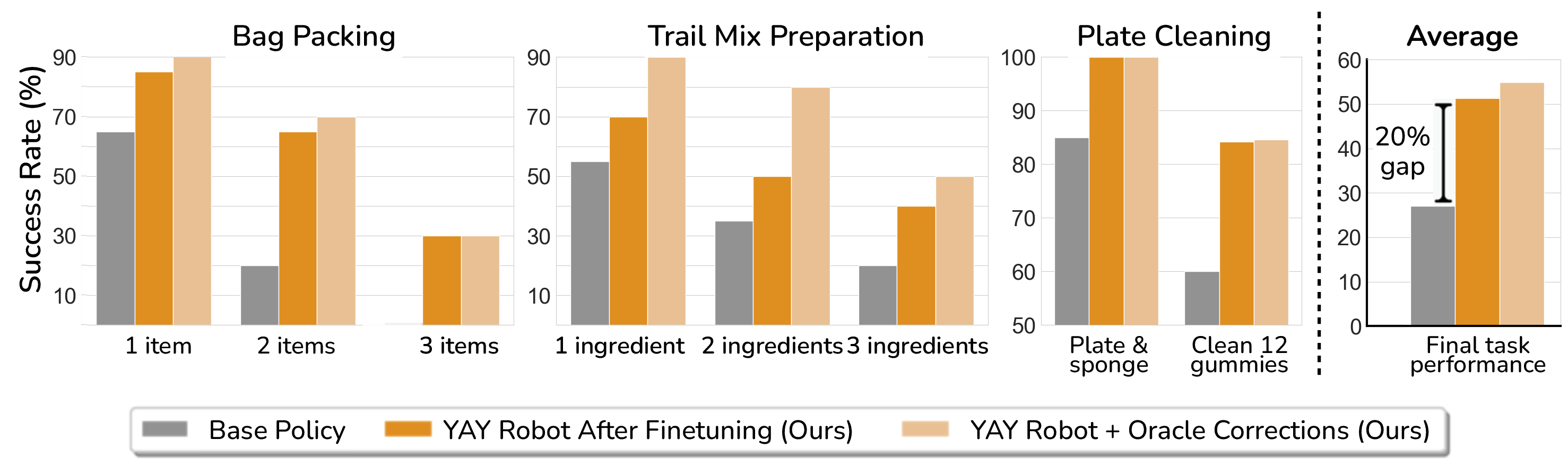
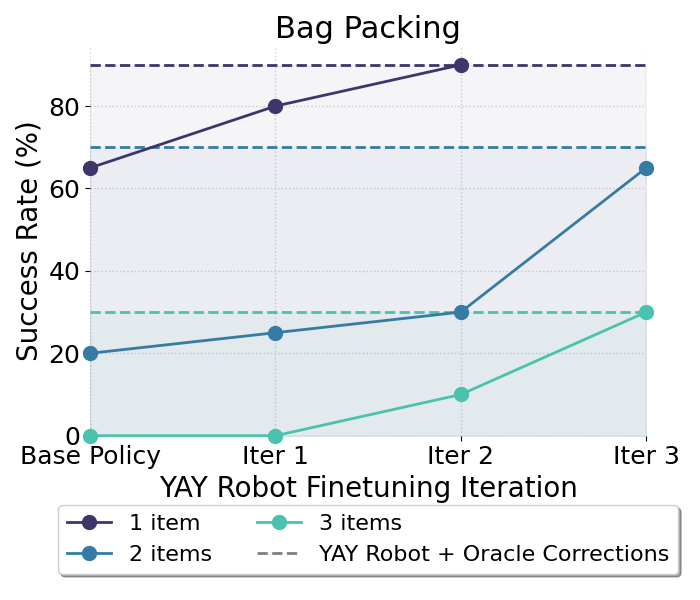
Abstract: Hierarchical policies that combine language and low-level control have been shown to perform impressively long-horizon robotic tasks, by leveraging either zero-shot high-level planners like pretrained language and vision-LLMs (LLMs/VLMs) or models trained on annotated robotic demonstrations. However, for complex and dexterous skills, attaining high success rates on long-horizon tasks still represents a major challenge -- the longer the task is, the more likely it is that some stage will fail. Can humans help the robot to continuously improve its long-horizon task performance through intuitive and natural feedback? In this paper, we make the following observation: high-level policies that index into sufficiently rich and expressive low-level language-conditioned skills can be readily supervised with human feedback in the form of language corrections. We show that even fine-grained corrections, such as small movements ("move a bit to the left"), can be effectively incorporated into high-level policies, and that such corrections can be readily obtained from humans observing the robot and making occasional suggestions. This framework enables robots not only to rapidly adapt to real-time language feedback, but also incorporate this feedback into an iterative training scheme that improves the high-level policy's ability to correct errors in both low-level execution and high-level decision-making purely from verbal feedback. Our evaluation on real hardware shows that this leads to significant performance improvement in long-horizon, dexterous manipulation tasks without the need for any additional teleoperation. Videos and code are available at https://yay-robot.github.io/.
- Do as i can, not as i say: Grounding language in robotic affordances. Conference On Robot Learning, 2022.
- Hierarchical reinforcement learning with natural language subgoals. arXiv preprint arXiv:2309.11564, 2023.
- Learning with latent language. arXiv preprint arXiv:1711.00482, 2017.
- Multi-task learning for continuous control. arXiv preprint arXiv:1802.01034, 2018.
- Affordances from human videos as a versatile representation for robotics. Computer Vision And Pattern Recognition, 2023. doi: 10.1109/CVPR52729.2023.01324.
- Rt-h: Action hierarchies using language. arXiv preprint arXiv: 2403.01823, 2024.
- Real-time natural language corrections for assistive robotic manipulators. The International Journal of Robotics Research, 36(5-7):684–698, 2017.
- Rt-1: Robotics transformer for real-world control at scale. Robotics: Science And Systems, 2022. doi: 10.48550/arXiv.2212.06817.
- Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Latte: Language trajectory transformer. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7287–7294. IEEE, 2023.
- Multimodal error correction with natural language and pointing gestures. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 1976–1986, October 2023.
- ”no, to the right” - online language corrections for robotic manipulation via shared autonomy. Ieee/acm International Conference On Human-robot Interaction, 2023. doi: 10.1145/3568162.3578623.
- Learning parameterized skills. arXiv preprint arXiv:1206.6398, 2012.
- Multi-task policy search for robotics. In 2014 IEEE international conference on robotics and automation (ICRA), pages 3876–3881. IEEE, 2014.
- Task and motion planning with large language models for object rearrangement. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2086–2092, 2023. doi: 10.1109/IROS55552.2023.10342169.
- An image is worth 16x16 words: Transformers for image recognition at scale. International Conference On Learning Representations, 2020.
- Palm-e: An embodied multimodal language model. International Conference On Machine Learning, 2023. doi: 10.48550/arXiv.2303.03378.
- Learning to sequence multiple tasks with competing constraints. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2672–2678. IEEE, 2019.
- Lisa: Learning interpretable skill abstractions from language. Advances in Neural Information Processing Systems, 35:21711–21724, 2022.
- Integrated task and motion planning. Annu. Rev. Control. Robotics Auton. Syst., 4:265–293, 2021. doi: 10.1146/ANNUREV-CONTROL-091420-084139.
- Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning. arXiv preprint arXiv:2109.08273, 2021a.
- Lazydagger: Reducing context switching in interactive imitation learning. In 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), pages 502–509. IEEE, 2021b.
- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint arXiv:2201.07207, 2022.
- Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973, 2023.
- Interactive task planning through natural language. In Proceedings of IEEE International Conference on Robotics and Automation, volume 1, pages 24–29 vol.1, 1996. doi: 10.1109/ROBOT.1996.503568.
- Bc-z: Zero-shot task generalization with robotic imitation learning. In Conference on Robot Learning, pages 991–1002. PMLR, 2022.
- Language as an abstraction for hierarchical deep reinforcement learning. Advances in Neural Information Processing Systems, 32, 2019.
- Hg-dagger: Interactive imitation learning with human experts. Ieee International Conference On Robotics And Automation, 2018. doi: 10.1109/ICRA.2019.8793698.
- Reinforcement learning to adjust parametrized motor primitives to new situations. Autonomous Robots, 33:361–379, 2012.
- Toward understanding natural language directions. In 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 259–266. IEEE, 2010a.
- Grounding verbs of motion in natural language commands to robots. In International Symposium on Experimental Robotics, 2010b.
- Code as policies: Language model programs for embodied control. Ieee International Conference On Robotics And Automation, 2022. doi: 10.1109/ICRA48891.2023.10160591.
- Learning to learn faster from human feedback with language model predictive control. 2024.
- Robot learning on the job: Human-in-the-loop autonomy and learning during deployment. arXiv preprint arXiv:2211.08416, 2022.
- Interactive robot learning from verbal correction. arXiv preprint arXiv: 2310.17555, 2023.
- Multi-stage cable routing through hierarchical imitation learning. Ieee Transactions On Robotics, 2023. doi: 10.48550/arXiv.2307.08927.
- Grounding language in play. arXiv preprint arXiv:2005.07648, 3, 2020a.
- Language conditioned imitation learning over unstructured data. arXiv preprint arXiv:2005.07648, 2020b.
- Interactive language: Talking to robots in real time. IEEE Robotics and Automation Letters, 2023.
- Walk the talk: Connecting language, knowledge, and action in route instructions. Def, 2(6):4, 2006.
- Human-in-the-loop imitation learning using remote teleoperation. arXiv preprint arXiv:2012.06733, 2020.
- Learning reusable manipulation strategies. Conference On Robot Learning, 2023. doi: 10.48550/arXiv.2311.03293.
- Listen, attend, and walk: Neural mapping of navigational instructions to action sequences. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30, 2016.
- Structured world models from human videos. Robotics: Science And Systems, 2023. doi: 10.15607/RSS.2023.XIX.012.
- Tell me dave: Context-sensitive grounding of natural language to manipulation instructions. The International Journal of Robotics Research, 35(1-3):281–300, 2016.
- Gpt-4 technical report. arXiv preprint arXiv: 2303.08774, 2023.
- Tadam: Task dependent adaptive metric for improved few-shot learning. Advances in neural information processing systems, 31, 2018.
- Actor-mimic: Deep multitask and transfer reinforcement learning. arXiv preprint arXiv:1511.06342, 2015.
- Film: Visual reasoning with a general conditioning layer. Aaai Conference On Artificial Intelligence, 2017. doi: 10.1609/aaai.v32i1.11671.
- Learning transferable visual models from natural language supervision. International Conference On Machine Learning, 2021.
- Robust speech recognition via large-scale weak supervision. International Conference On Machine Learning, 2022. doi: 10.48550/arXiv.2212.04356.
- A reduction of imitation learning and structured prediction to no-regret online learning. International Conference On Artificial Intelligence And Statistics, 2010.
- Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. NEURIPS, 2019.
- Skill induction and planning with latent language. arXiv preprint arXiv:2110.01517, 2021.
- Correcting robot plans with natural language feedback. arXiv preprint arXiv:2204.05186, 2022.
- Cliport: What and where pathways for robotic manipulation. In Conference on Robot Learning, pages 894–906. PMLR, 2022.
- Hierarchical and interpretable skill acquisition in multi-task reinforcement learning. arXiv preprint arXiv:1712.07294, 2017.
- Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube. Robotics: Science And Systems, 2022. doi: 10.15607/rss.2022.xviii.023.
- Language-conditioned imitation learning for robot manipulation tasks. Advances in Neural Information Processing Systems, 33:13139–13150, 2020.
- Efficientnet: Rethinking model scaling for convolutional neural networks. International Conference On Machine Learning, 2019.
- ALOHA 2 Team. Aloha 2: An enhanced low-cost hardware for bimanual teleoperation, 2024. URL https://aloha-2.github.io/.
- Distral: Robust multitask reinforcement learning. Advances in neural information processing systems, 30, 2017.
- Understanding natural language commands for robotic navigation and mobile manipulation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 25, pages 1507–1514, 2011.
- Attention is all you need. arXiv preprint arXiv: 1706.03762, 2017.
- Chatgpt for robotics: Design principles and model abilities. Microsoft Auton. Syst. Robot. Res, 2:20, 2023.
- Neural Semantic Parsing with Anonymization for Command Understanding in General-Purpose Service Robots, pages 337–350. Springer International Publishing, 2019. doi: 10.1007/978-3-030-35699-6˙26.
- Mosaic: A modular system for assistive and interactive cooking. arXiv preprint arXiv: 2402.18796, 2024.
- Deep imitation learning for bimanual robotic manipulation. Neural Information Processing Systems, 2020.
- Multi-step tasks learning based on bayesian segmentation and dynamic movement primitive. In 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), pages 265–270. IEEE, 2021.
- Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv: 2304.13705, 2023.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.