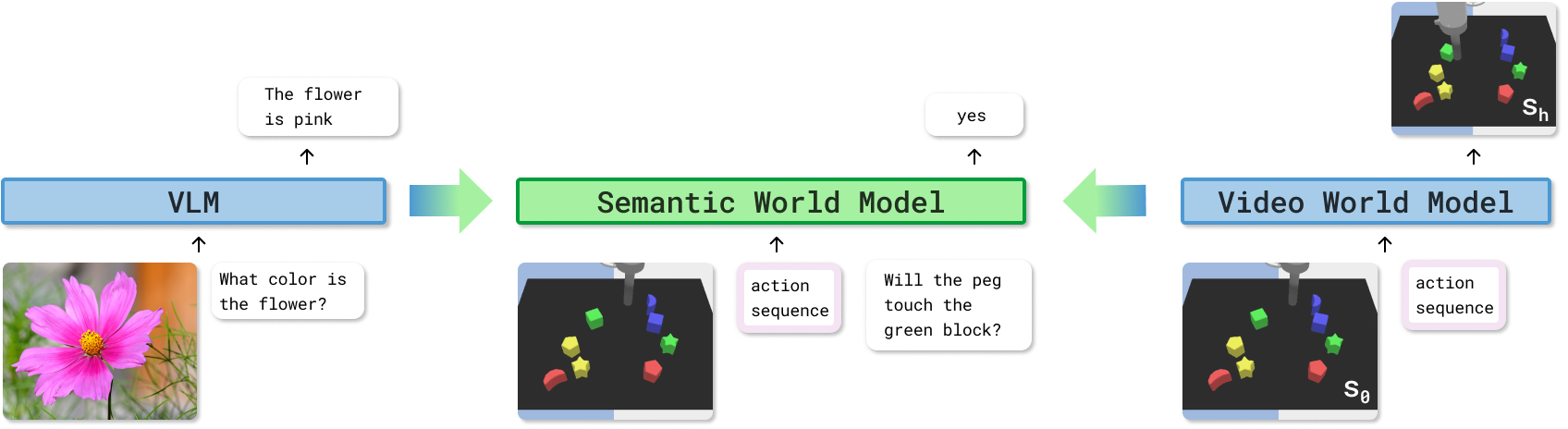
Semantic World Models
Abstract: Planning with world models offers a powerful paradigm for robotic control. Conventional approaches train a model to predict future frames conditioned on current frames and actions, which can then be used for planning. However, the objective of predicting future pixels is often at odds with the actual planning objective; strong pixel reconstruction does not always correlate with good planning decisions. This paper posits that instead of reconstructing future frames as pixels, world models only need to predict task-relevant semantic information about the future. For such prediction the paper poses world modeling as a visual question answering problem about semantic information in future frames. This perspective allows world modeling to be approached with the same tools underlying vision LLMs. Thus vision LLMs can be trained as "semantic" world models through a supervised finetuning process on image-action-text data, enabling planning for decision-making while inheriting many of the generalization and robustness properties from the pretrained vision-LLMs. The paper demonstrates how such a semantic world model can be used for policy improvement on open-ended robotics tasks, leading to significant generalization improvements over typical paradigms of reconstruction-based action-conditional world modeling. Website available at https://weirdlabuw.github.io/swm.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for robots to “imagine” the future so they can plan better. Instead of trying to draw the next frames of a video (predict every pixel), the authors teach a model to answer simple, meaningful questions about what will happen after a robot takes certain actions. They call this a Semantic World Model (SWM). Think of it like asking: “If the robot moves its arm like this, will it pick up the blue block?” The model answers yes or no (and similar questions), and those answers help the robot choose the best actions.
What questions did the researchers ask?
In simple terms, they explored:
- Do robots really need to predict every pixel of the future, or is it enough to predict the key facts we care about (like “is the block grasped?”)?
- Can we turn future prediction into a question-answering problem, the way some AI models answer questions about images?
- Will this approach help robots plan better actions, especially in new or slightly changed situations?
- Can this method learn not just from perfect examples but also from messy or imperfect ones (“suboptimal” data)?
How did they do it?
The big idea
- Traditional “world models” try to predict future images frame-by-frame. That often looks great but can miss tiny, important details that matter for decision-making (like precise contact between fingers and an object).
- The authors say: let’s skip drawing the future and just predict the important facts about it. They reframe world modeling as asking and answering questions about the future, such as:
- “After these actions, is the red cube touching the blue star?”
- “Did the arm get closer to the object?”
- “Was the blue moon picked up?”
How the model works
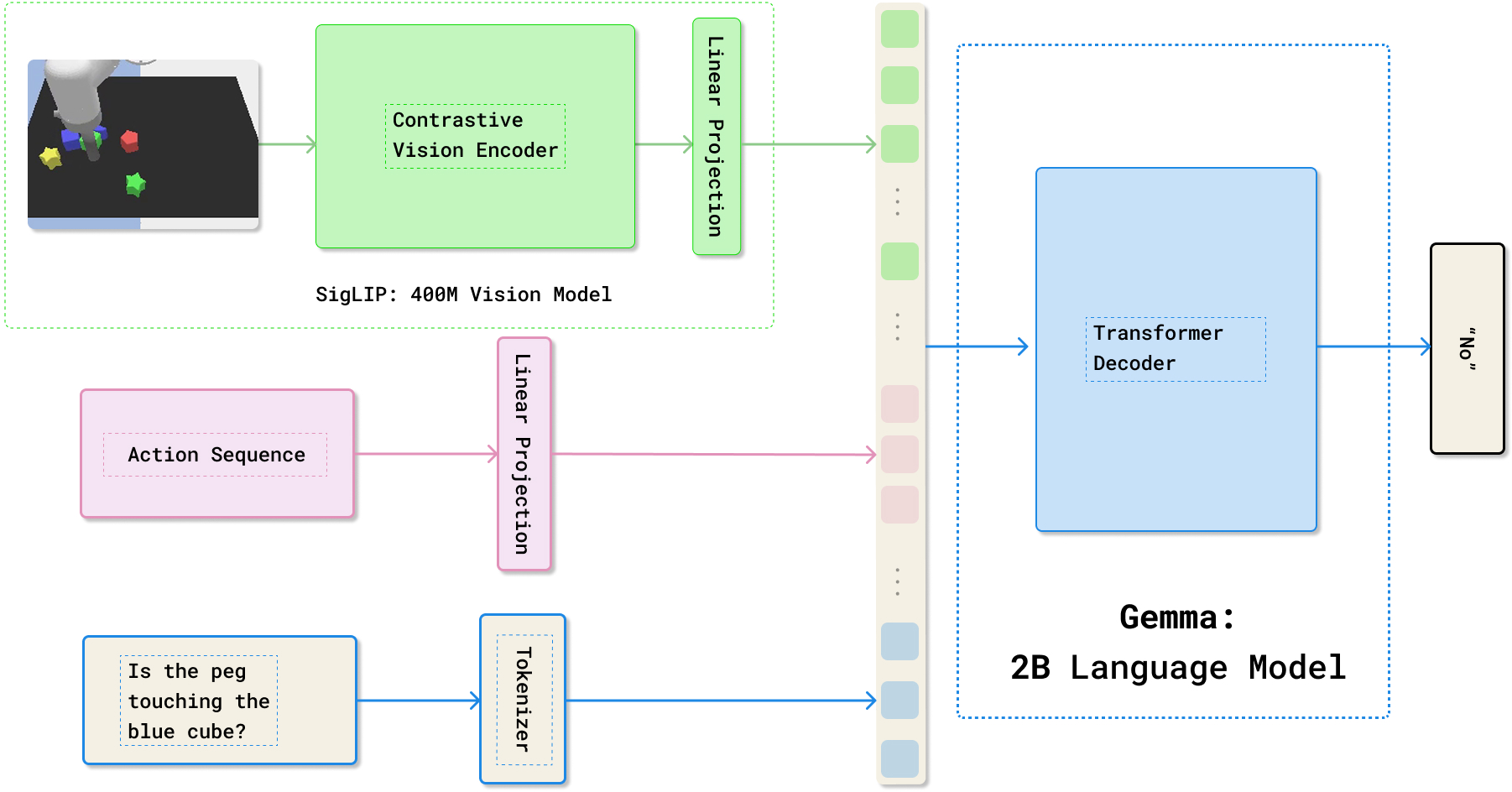
- They start with a vision-LLM (VLM) called PaliGemma. A VLM can look at a picture and answer questions in text.
- They adapt it so it can also “read” a planned sequence of robot actions (like a list of joystick moves).
- Input to the model: a current image, a proposed action sequence, and a question about the future.
- Output: a text answer (often yes/no) about what will happen if those actions are taken.
Imagine a sports coach watching a freeze-frame and a list of moves, then predicting: “If you run left, will you get past the defender?” The SWM is that coach for robots.
The training data (SAQA)
They build a dataset of:
- S = the current scene (an image)
- A = a sequence of actions the robot will take
- Q = a question about the future scene
- A = the correct answer to that question
They generate many such examples from robot simulations, including multiple phrasings of the same question so the model learns to understand different ways of asking.
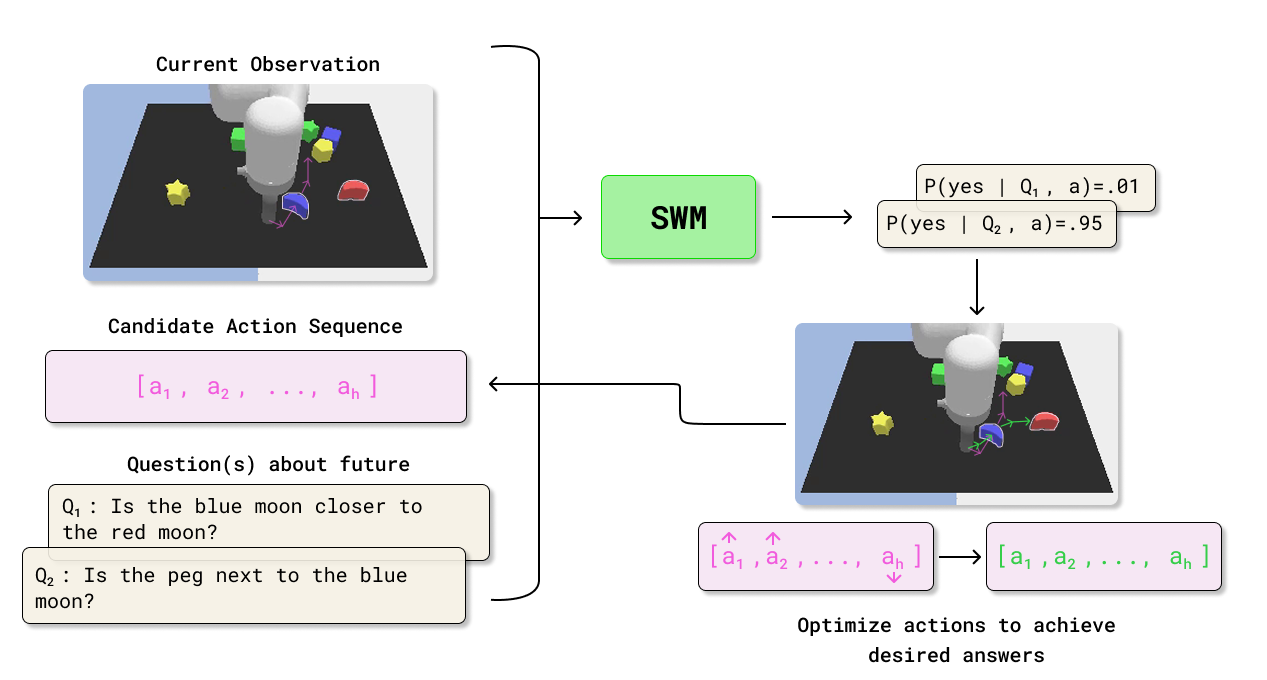
Planning with the SWM
To choose good actions, they:
- Define a task as a small set of questions and their desired answers (for example, “Is the block grasped?” → yes).
- Propose action sequences.
- Ask the SWM how likely it is that the desired answers will be true after those actions.
- Pick or improve the actions that make “yes” most likely.
They try two planning strategies:
- Sampling-based: Try many possible action sequences (like guessing and checking), keep the best, and refine. This is called MPPI.
- Gradient-based: Start from a decent guess (a “base policy”), then tweak actions in the direction that increases the chance of getting the desired answers (like turning dials in the right direction). This is faster for harder tasks.
They also handle multi-step tasks by breaking them into subgoals (like “first grasp, then stack”), and the SWM checks when each subgoal is achieved.
What did they find?
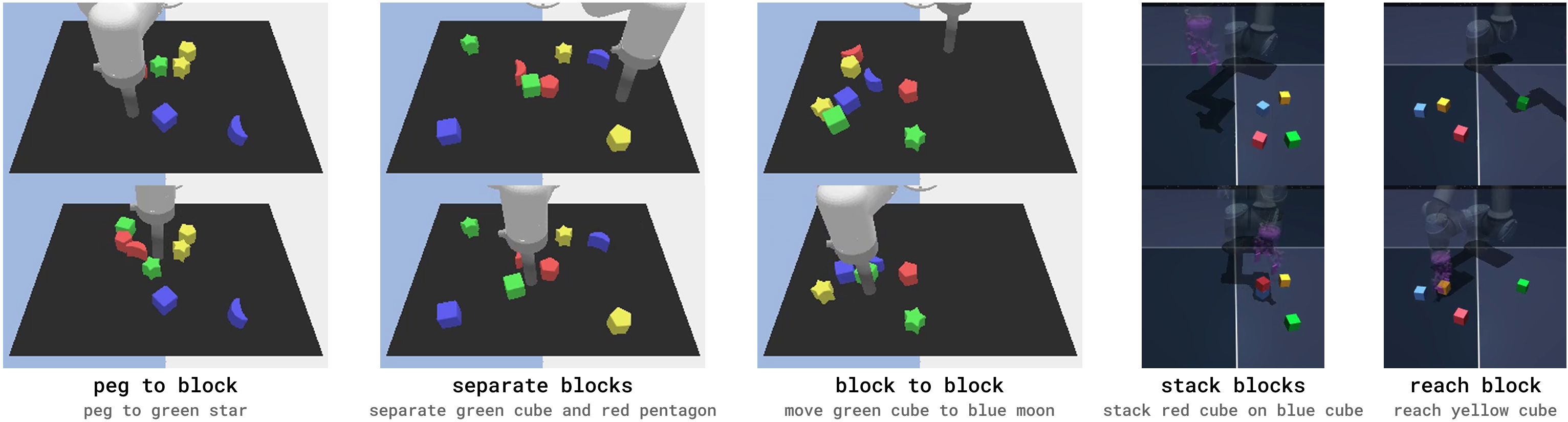
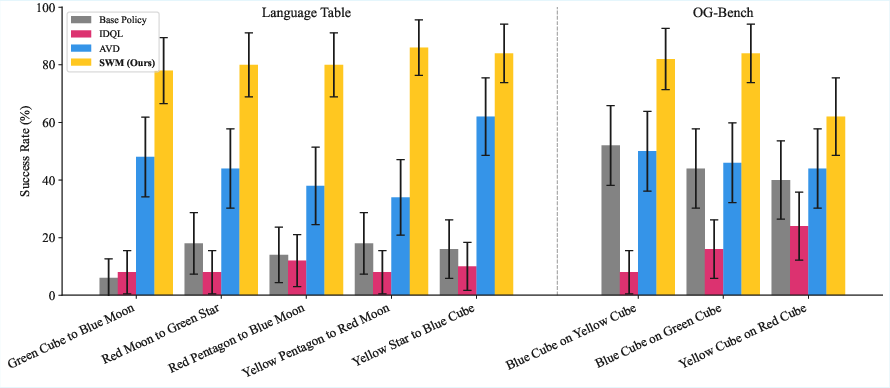
- Planning directly with the SWM worked very well on several robot tasks (like reaching, separating blocks, pushing, and stacking) in two simulation environments (LangTable and OGBench).
- Big improvements: When they used the SWM to refine actions, success rates jumped a lot:
- In LangTable: from about 14% to about 82%.
- In OGBench: from about 45% to about 76%.
- Better than baselines: The SWM approach beat:
- A pixel-based video prediction method (which tries to generate future frames).
- An offline reinforcement learning method (IDQL) trained on the same data.
- Works with imperfect data: Training with a mix of expert and suboptimal (messy) data improved accuracy over using only perfect examples. The model still learned a lot even from only suboptimal data.
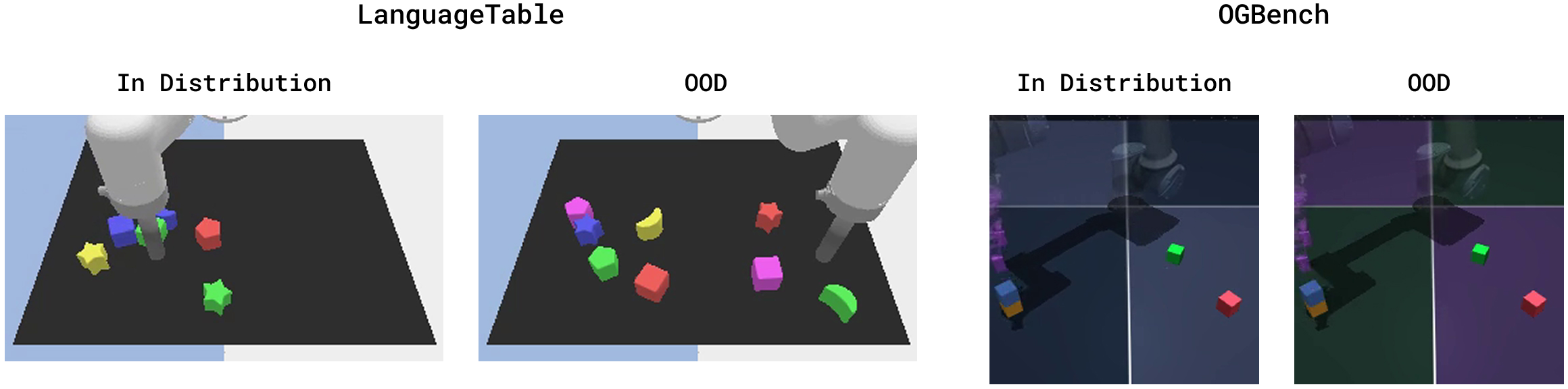
- Generalizes to new situations: The SWM held up when the scene changed (like new block colors or different background colors). It still improved performance over the base policies and beat the pixel-based baseline in these out-of-distribution tests.
- Looks at the right stuff: Attention maps (a way to see what the model focuses on) showed that the model paid attention to the relevant objects mentioned in the question, even for more complex prompts.
Why does it matter?
- Focus on meaning, not pixels: For planning, knowing the key facts about the future is usually what matters. SWM is a practical way to get those facts without heavy and sometimes unnecessary image generation.
- Reuses powerful AI: By building on top of a VLM, SWM inherits strong vision-language understanding and generalization, which helps in new or noisy situations.
- Flexible and scalable: You can define tasks with simple natural-language questions and use the same SWM to plan for many different goals without retraining it for each one.
- Efficient use of data: It benefits from both expert and non-expert data, which makes building datasets easier and cheaper.
Limitations and future directions
- Speed: Sampling-based planning with large models can be slow. The gradient-based method is faster but needs a decent starting policy.
- Data creation: Building the training set here used simulator “ground truth” to write correct QA pairs, which is harder to get in the real world.
- What’s next: Use smaller, faster VLMs to make planning quicker; and generate QA pairs directly from a VLM instead of requiring simulator labels, which could make this work more practical on real robots.
In short, Semantic World Models shift robot planning from “drawing the future” to “answering the right questions about the future,” and that makes planning more accurate, more general, and often simpler.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future work:
- Real-world data labeling: The SAQA dataset requires privileged oracle state to programmatically generate future QA labels; how to obtain accurate, scalable, and low-cost future QA supervision in real-world robotics (e.g., from weak labels, self-supervision, human feedback, or teacher VLMs) remains open.
- Label noise and robustness: The method assumes clean, unambiguous QA labels; robustness to noisy, partial, or contradictory labels (likely in real data) is not evaluated or addressed.
- Action encoding design: Actions are injected via a single linear projection into the LLM token space; no ablation on alternative encodings (e.g., temporal transformers, diffusion embeddings, FiLM conditioning, learned action tokenization) or their effect on long-horizon prediction and planning.
- Horizon scaling and memory limits: The approach does not characterize how answer accuracy and planning performance degrade with increasing action-sequence length, transformer context limits, or horizon
h. - Temporal granularity and variable timing: The model assumes fixed-step action sequences; how to handle variable-duration actions, irregular control intervals, and time-aware conditioning is unexplored.
- Multi-modality of futures: Binary QA over a single future may be insufficient in stochastic or multi-modal environments; representing and planning over distributions of possible outcomes is not addressed.
- Calibration of probabilities: Planning hinges on
p_wm(A* | S, a, Q), yet probability calibration (e.g., temperature scaling, ensembles) and its impact on planning quality, safety, and OOD reliability are not evaluated. - Answer consistency and logical constraints: No mechanism enforces consistency across related questions (e.g., transitivity, mutual exclusivity); how to impose or learn logical/physical constraints over QA predictions is open.
- Task specification burden: Tasks require manually chosen questions, desired answers, and heuristic weights; no principled method to learn or optimize the question set and weights end-to-end from sparse rewards or preferences.
- Sensitivity to prompt phrasing: While training includes paraphrases, robustness to prompt variation, adversarial prompts, or domain-specific terminology is not systematically measured.
- Non-binary targets: The paper focuses on yes/no QA; extending to numeric, ordinal, or structured outputs (e.g., distances, poses, object sets) and integrating them into optimization is untested.
- Credit assignment for long horizons: Gradients are taken through answer likelihoods over entire sequences, but there is no analysis of gradient signal quality, vanishing/exploding behavior, or action-level attribution for long-horizon credit assignment.
- Planning stability and efficiency: Gradient-based planning uses norm clipping but lacks analysis of convergence properties, step-size sensitivity, initialization dependence on base policy quality, or guarantees on improvement.
- Model-based safety: Planning ignores safety constraints and uncertainty-aware control; how to incorporate constraints, risk measures, or robust objectives into SWM-driven planning remains open.
- Multi-step decomposition: Multi-step tasks rely on SWM for subgoal detection and verification using zero-horizon QA; potential confirmation bias (self-evaluation), failure modes, and calibration of subgoal completion are not studied.
- Comparative baselines: The study omits comparisons to strong latent world models (e.g., Dreamer variants, TD-MPC2) and to recent semantic reward/reward-model baselines; a broader empirical comparison would clarify when SWM is preferable.
- Data efficiency and scaling laws: There is no analysis of how SWM performance scales with number/diversity of SAQA pairs, action horizon coverage, paraphrase variety, or model size; sample complexity is unknown.
- Use of suboptimal data: While mixing suboptimal data helps QA accuracy, the paper does not quantify trade-offs vs. expert-only data across tasks, nor provide guidelines on which suboptimal behaviors are most beneficial.
- Perception modalities: The model uses only RGB observations at inference; the value of proprioception, tactile inputs, depth/point clouds, or multi-view inputs for semantic prediction and planning is unexplored.
- Occlusions and visual perturbations: Robustness to occlusions, viewpoint changes, lighting variations, sensor noise, and distractors is not systematically evaluated beyond limited background/color shifts.
- Real-robot deployment: There is no real-world validation, latency budget, or control-frequency assessment; inference-time memory/compute profiles and strategies for meeting real-time constraints are missing.
- Online learning and adaptation: The framework is purely offline; integrating SWM with online data collection, active learning of questions, or iterative improvement (e.g., DAgger-style loops) is not addressed.
- Question generation at scale: Automatically generating diverse, task-relevant, and verifiable future questions (without privileged state) remains an open challenge; how to vet teacher-VLM-generated QAs and prevent specification gaming is unclear.
- Contradictions and hallucinations: VLM finetuning may still produce hallucinated answers; detection, mitigation, and their downstream effects on planning are not studied.
- Multi-agent and dynamic scenes: Handling other agents, moving obstacles, and exogenous stochastic events is not explored; formulating future QA that captures interactive dynamics is open.
- Non-myopic objectives: The value formulation rewards early achievement via chunking
c, but its relation to true long-horizon returns, potential reward shaping pitfalls, and principled temporally extended objectives are unexamined. - Action constraints and smoothness: The planner does not enforce action smoothness, dynamics feasibility beyond simple bounds, or actuator limitations; incorporating differentiable constraints or trajectory priors is open.
- Architectural ablations: The paper lacks ablations on: base VLM choice, vision encoder freezing vs. finetuning, action projection depth/layers, cross-attention patterns, and their effect on generalization and planning.
- Evaluation breadth: Tasks are relatively simple (reaching, pushing, stacking) in simulation; performance on contact-rich, articulated, deformable, or partially observable settings is unknown.
- Tokenization and answer formatting: The effect of answer string choice (e.g., “yes” vs. “true”), multi-token answers, or label smoothing on gradients and planning stability is not analyzed.
Practical Applications
Overview
The paper introduces Semantic World Models (SWMs): action‑conditioned vision–LLMs that answer natural‑language questions about future outcomes, instead of predicting future pixels. SWMs enable planning by maximizing the likelihood of desired answers to goal‑related questions given current observations and a candidate action sequence. They support both sampling‑based (e.g., MPPI) and gradient‑based planning (test‑time policy refinement), learn from both expert and suboptimal data, and exhibit improved generalization by leveraging VLM pretraining.
Below are actionable applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon. Each item notes sectors, plausible tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
- SWM test-time policy optimizer for robotic manipulation (Industry: manufacturing, warehousing; Software/Robotics)
- What: Wrap existing manipulation policies (e.g., Diffusion Policy) with a gradient-based SWM optimizer to refine action sequences at inference, improving success rates on grasping, pushing, separating, and stacking.
- How/tool/product: ROS 2 plugin or Python SDK that:
- Takes camera frames and base-policy action proposals.
- Uses task-specific question sets (e.g., “Is the gripper touching the blue cube?” -> “yes”) and SWM likelihoods as the optimization objective with early-chunk rewards.
- Performs 5–30 gradient steps to output refined action sequences in real time for short horizons.
- Dependencies/assumptions: Pretrained VLM (e.g., PaliGemma or smaller variants), GPU for inference, calibrated question sets, and action tokenization for the robot. Latency must fit the control loop; gradient method is preferred over sampling for efficiency.
- Semantic subgoal monitor and progress checker (Industry; Daily life; Robotics)
- What: Verify subgoal completion from images using zero‑horizon Q&A (e.g., “Is the block grasped?”), enabling multi-step controllers to autonomously progress to the next subgoal.
- How/tool/product: “Goal Check” microservice callable from robot task graphs/state machines; integrates with behavior trees for condition nodes.
- Dependencies/assumptions: Accurate camera views; robust prompt templates; calibrated thresholds on answer likelihood; handles occlusions or uses multi-view.
- QA-driven reward shaping and evaluation harness for RL/IL (Academia; Software/Robotics)
- What: Replace dense pixel-based rewards with SWM‑based semantic rewards for RL/IL training and offline evaluation, improving alignment with task semantics and enabling early achievement rewards.
- How/tool/product: Training wrapper that queries SWM for p(desired answer | state, sub‑trajectory, question) on replay buffers; integrates with Gym/MuJoCo/Isaac Sim training loops.
- Dependencies/assumptions: Offline SAQA or weak labels; stable batching of SWM queries; computational budget for reward inference.
- SAQA data generation pipeline in simulation (Academia; Industry R&D; Software)
- What: Programmatically generate state–action–question–answer (SAQA) datasets from existing simulated trajectories using privileged state to label future outcomes.
- How/tool/product: Connectors for MuJoCo, PyBullet, Isaac Sim to emit SAQA tuples with multiple horizons and phrasings; dataset balancers to equalize question/answer distributions as in the paper.
- Dependencies/assumptions: Access to simulator privileged states; coverage of question types; safety/privacy compliant if mirrored from real logs.
- Vision-language outcome validator for robotic process QA (Industry: assembly, kitting, e‑commerce fulfillment)
- What: End‑of‑operation verification of outcomes via SWM Q&A (e.g., “Is the red label aligned?”), complementing classical sensors.
- How/tool/product: Inline quality check service that queries SWM post‑action; flags rework if semantic outcome failed.
- Dependencies/assumptions: Sufficient visual resolution; consistent lighting; curated question sets; integration with MES/QA systems.
- Open-world goal execution from natural language (Labs; Robotics startups)
- What: Execute tasks specified in free-form language by mapping instructions to a set of yes/no queries and expected answers, then planning to maximize answer likelihood.
- How/tool/product: Instruction-to-questions converter (LLM/VLM prompt) + SWM planner; demo harness for tabletop robots.
- Dependencies/assumptions: Reliable task decomposition to question sets; curated templates for safety; bounded environment variability.
- Robustness enhancement via semantic planning in OOD scenes (Industry; Academia)
- What: Improve robustness under background/appearance shifts by planning in semantic QA space rather than pixels.
- How/tool/product: SWM-based replanning module for OOD seeds; A/B testing harness to quantify robustness gains vs pixel‑based video models.
- Dependencies/assumptions: VLM pretraining that transfers; limited domain gap; calibrated prompts to reduce spurious correlations.
- Human-in-the-loop “what-if” action reviewer (Industry; Safety teams; Operators)
- What: Operators propose candidate actions; SWM answers safety and outcome queries (e.g., “Will this trajectory cause a collision?”) before execution.
- How/tool/product: UI tool that visualizes candidate actions and SWM answers with confidence; integrates with teleop/assistive control.
- Dependencies/assumptions: Trust calibration, conservative thresholds; coverage of safety questions; logging for audit.
- Education and research labs: benchmark kit for semantic world modeling (Academia)
- What: Coursework/lab modules showing SWM vs pixel prediction for planning, including SAQA generation and planning algorithms (MPPI, gradient).
- How/tool/product: Open-source notebooks, datasets, and baselines replicating the paper’s LangTable/OGBench experiments.
- Dependencies/assumptions: GPU access; appropriate licenses for VLM weights; reproducibility scripts.
- Low-cost upgrades to legacy robot cells (Industry: SMEs)
- What: Add a camera and an SWM-based verifier to legacy pick/place cells to validate or refine end-effector approach vectors for hard SKUs (e.g., glossy/transparent items).
- How/tool/product: Edge gateway with SWM inference; “nudge optimizer” that perturbs approach actions within safety bounds to satisfy semantic contact/pose queries.
- Dependencies/assumptions: Safety envelopes enforced; sufficient compute at edge or on-prem; minimal retraining using suboptimal logs.
Long-Term Applications
- Fully semantic planners for household/assistive robots (Daily life; Healthcare/Assistive tech; Robotics)
- What: End-to-end goal execution from natural language by planning over semantic outcome queries, reducing reliance on brittle pixel forecasts.
- How/tool/product: On-device, smaller VLM‑backed SWMs (e.g., SmolVLM/FastVLM-class) + gradient planners; skill libraries as question sets.
- Dependencies/assumptions: Efficient VLMs for real-time; robust SAQA from real data without privileged labels; reliable task decomposition and safety guardrails.
- Safety-constrained semantic control in collaborative robots (Industry; Policy)
- What: Bake safety constraints as always-on negative queries (e.g., “Is any human limb in proximity zone?” -> “no”) that SWM optimizes jointly with task queries.
- How/tool/product: “Semantic safety shield” co‑optimizer; certification pathways that include semantic tests.
- Dependencies/assumptions: High recall for safety queries; multi-camera coverage; regulatory acceptance; formal verification of likelihood thresholds.
- Cross-embodiment transfer via language-space world models (Academia; Robotics platforms)
- What: Train SWMs that generalize across manipulators/drones by grounding dynamics in semantic outcomes rather than embodiment-specific pixels.
- How/tool/product: Multi-embodiment SAQA datasets; shared question ontologies; embodiment adapters for action tokenization.
- Dependencies/assumptions: Standardized action representations; diverse training corpora; careful prompt/domain calibration.
- SWM-driven autonomous drones for inspection and handling (Industry: logistics, infrastructure, agriculture; Energy)
- What: Plan flight and manipulation to satisfy semantic outcomes (“Is the connector latched?”, “Is the crack length > X?”) under appearance shifts.
- How/tool/product: Drone mission planner that maximizes semantic success likelihood at waypoints; hybrid with geometric planners.
- Dependencies/assumptions: Robust perception under outdoor variability; safe action envelopes; curated question sets for domain defects.
- Semantic world models for surgical or lab automation (Healthcare; Biotech)
- What: Outcome-driven planning for pipetting, sample preparation, suture placement using high-level semantic verification.
- How/tool/product: SWM add-on to lab robots; question banks aligned to SOPs (“Is the droplet volume within tolerance?”).
- Dependencies/assumptions: High-precision vision; regulatory compliance; extensive validation to avoid hallucinations; data capture with ground truth.
- Process control with vision-guided semantic outcomes (Industry: assembly, electronics, food)
- What: Replace hand-engineered inspection rules with SWM queries that drive process adjustments (“Is the paste coverage sufficient?”).
- How/tool/product: Closed-loop controller using SWM-derived reward signals to tweak setpoints; digital twin for SAQA bootstrapping.
- Dependencies/assumptions: Reliable twin-to-real transfer; coverage of failure modes; latency budgets met on the line.
- Standards and auditing frameworks for language-conditioned robots (Policy; Industry consortia)
- What: Compliance checklists expressed as semantic questions (safety, fairness, privacy) that must evaluate to desired answers before/after action execution.
- How/tool/product: Regulatory test suites with SAQA-based probes; audit logs of question/answer likelihoods; red-team protocols for prompt robustness.
- Dependencies/assumptions: Consensus on question taxonomies; thresholds and calibration methods; reporting formats; governance on model updates.
- Synthetic SAQA generation from VLMs and weak sensors (Academia; Industry R&D)
- What: Replace privileged simulation labels with pseudo-labels from strong VLM ensembles and auxiliary sensors, enabling real-world SWM training at scale.
- How/tool/product: Data engine that auto-generates diverse phrasings and validates answers via redundancy and multi-view checks.
- Dependencies/assumptions: Pseudo-label quality sufficient; bias/coverage analysis; continual learning workflows.
- Edge-optimized SWMs for embedded platforms (Software/Robotics; Semiconductors)
- What: Deploy SWM inference on ARM/NPU/FPGA for real-time control on mobile robots/drones.
- How/tool/product: Quantized models, distillation from large VLMs; operator libraries optimized for token–image fusion and action conditioning.
- Dependencies/assumptions: Acceptable accuracy–latency tradeoffs; hardware toolchains; on-device safety fallback.
- Multimodal “what-if” simulation for AR/consumer devices (Daily life; Education)
- What: Users specify goals; device previews likely outcomes to simple actions in the scene (“Will this placement block the door?”) via semantic queries.
- How/tool/product: AR apps that use SWM to evaluate discrete action options; assistive setup guides.
- Dependencies/assumptions: Simplified action spaces; high-quality scene recon; acceptance of probability-based guidance.
Cross-Cutting Assumptions and Dependencies
- Model availability/compute: Access to strong pretrained VLMs (or efficient small variants) and GPUs/accelerators for timely inference.
- Data: SAQA datasets that cover relevant questions and horizons; in real settings, either privileged labels, pseudo‑labels, or carefully validated human/VLM-generated QA.
- Prompting and calibration: Well‑designed question templates, likelihood thresholds, and early-chunk reward settings; mitigation of spurious correlations.
- Safety: Hard constraints and verified guardrails must wrap SWM planning, especially for human–robot interaction and regulated domains.
- Integration: Action tokenization and control‑loop interfaces with existing stacks (ROS 2, behavior trees, MPC/RL policies).
- Evaluation: Robust OOD testing, uncertainty estimation, and audit logging for semantic decisions.
These applications operationalize the paper’s central idea—optimizing for semantic outcomes rather than pixels—into deployable tools today and pathways to broader, safety‑critical adoption as the ecosystem matures.
Glossary
- Action-Conditioned: A modeling setup where predictions depend on a sequence of actions provided as input. "large action-conditioned video prediction models"
- Actor-Critic: A reinforcement learning framework with separate policy (actor) and value (critic) components. "generate rollouts for actor-critic policy optimization"
- Autoregressive LLM: A model that generates tokens sequentially by conditioning on previously generated tokens. "a transformer-based autoregressive LLM"
- Collocation-Based Planning: An optimization technique that enforces dynamic constraints at selected points to enable long-horizon planning. "leverages collocation-based planning to enable long-horizon planning with latent dynamics models."
- Compositional Generalization: The ability to generalize to novel combinations of known components (e.g., shapes and colors). "the block color combinations are changed during evaluation to test compositional generalization."
- Cross-Entropy Loss: A standard loss function for classification and sequence modeling, measuring the log-likelihood of target labels. "optimizing the standard cross-entropy loss"
- Cross-Entropy Method (CEM): A sampling-based optimization algorithm that iteratively refines a distribution toward high-value solutions. "applies the cross-entropy method to plan for optimal actions for a given reward."
- Diffusion Action Head: A module that decodes actions using diffusion-based generative modeling. "Pi-0 decodes actions via a diffusion action head."
- Diffusion Policy: A visuomotor policy that models actions with a diffusion process to improve robustness and sample efficiency. "a per-task Diffusion Policy \citep{diffpol} is trained on 300 expert trajectories for 100 epochs as the base policy."
- Dreamer: A model-based RL algorithm that learns latent dynamics and optimizes policies using imagined rollouts. "Dreamer \citep{Hafner2020Dream} and TD-MPC \citep{hansen2022temporaldifferencelearningmodel} use a latent dynamics model to generate rollouts for actor-critic policy optimization"
- Embodied Decision-Making: Decision-making in environments where actions affect physical states, often via robotic agents. "to bring the vision-language understanding capabilities of VLMs to embodied decision-making"
- Gradient Ascent: An optimization technique that adjusts parameters in the direction of increasing objective value. "gradient ascent is used to optimize the following objective:"
- Gradient Norm Clipping: A stabilization technique that bounds the magnitude of gradients during optimization. "gradient norm clipping is used before each step."
- Horizon: The number of future steps considered when planning or modeling outcomes. "h is the horizon"
- IDQL: An offline RL method that trains an actor-critic with diffusion policies, reweighting a behavior policy via IQL. "IDQL is an offline RL baseline which uses IQL \cite{kostrikov2022offline} to reweight the a behavior diffusion policy."
- LatCo: A planning method that applies collocation to latent dynamics for long-horizon control. "LatCo \citep{Rybkin2021LatCo} leverages collocation-based planning to enable long-horizon planning with latent dynamics models."
- Latent Dynamics Model: A model that predicts future states in a compact latent space rather than pixel space. "PlaNet learns a recurrent latent dynamics model with a reconstruction objective and applies planning in the latent space."
- Latent Representation: A compressed feature space capturing task-relevant information for prediction and control. "modeling ``task-relevant'' latent representations"
- Model Predictive Path Integral (MPPI): A stochastic optimal control method that performs sampling-based trajectory optimization. "Model Predictive Path Integral (MPPI) control algorithm"
- Multimodal Generative Model: A model that jointly processes and generates across multiple modalities (e.g., vision and language). "Multimodal generative models, commonly known as VLMs"
- Next-Token Prediction Objective: A training objective where the model predicts the next token in a sequence given prior context. "They are typically trained with a next-token prediction objective."
- Offline RL: Reinforcement learning from static datasets without environment interaction during training. "IDQL is an offline RL baseline"
- Out-of-Distribution (OOD): Inputs that differ from the training distribution, used to test robustness and generalization. "out-of-distribution conditions"
- PaliGemma: A 3B parameter open-source vision-LLM used as the base architecture. "This paper uses the 3B parameter checkpoint from PaliGemma as the base model."
- PETS: A model-based RL algorithm that learns probabilistic dynamics and plans with the cross-entropy method. "PETS \citep{Chua2018PETS} learns a one-step dynamics model and applies the cross-entropy method to plan for optimal actions for a given reward."
- Pi-0: A vision-language-action model that decodes actions via a diffusion head. "Pi-0 \citep{BlackBrownDarpinianEtAl_2024_Pi0} decodes actions via a diffusion action head."
- PlaNet: A latent dynamics model for model-based RL that plans in learned latent space. "PlaNet \citep{Hafner2019PlaNet} learns a recurrent latent dynamics model with a reconstruction objective and applies planning in the latent space."
- Projection Matrix: A learned linear mapping that projects features (e.g., images or actions) into the LLM’s embedding space. "a new projection matrix $P \in \mathbb{R}^{d_{\text{tok} \times d_{\text{act}$ is used"
- SAQA Dataset: A State-Action-Question-Answer dataset for training future-answering world models. "a state-action-question-answer (SAQA) dataset is generated."
- Sampling-Based Planning: Planning by sampling candidate action sequences and selecting those with highest value. "Sampling-based planning provides a straightforward approach to planning."
- Semantic World Model (SWM): An action-conditioned VLM that answers questions about future outcomes instead of predicting pixels. "This work introduces the paradigm of Semantic World Model (SWM) -- a generalizable world model"
- SigLIP: A vision-language pretraining method using a pairwise sigmoid loss instead of contrastive loss. "SigLIP \citep{Zhai_2023_ICCV} replaces the contrastive loss with a pairwise sigmoid loss to facilitate scalable training."
- Transformer: A neural architecture based on self-attention used for sequence modeling. "a transformer-based autoregressive LLM"
- Temperature Parameter: A scalar that controls exploration by scaling weights in soft selection. "and is a temperature parameter that controls exploration."
- UniPi: A framework that uses a world model as a high-level planner to guide low-level policies. "UniPi \citep{du2023learning} uses a world model as a high-level planner to condition low-level policies."
- Unified World Models (UWM): A unified video-action diffusion approach that leverages video data for generalization. "UWM \citep{zhu2025uwm} trains a unified video-action diffusion model, incorporating video data into pretraining to improve generalization."
- Vision Encoder: The component that processes images into feature embeddings for a VLM. "a vision encoder with a feature size $d_{\text{img}$"
- Vision-LLMs (VLMs): Models trained on vision and language that can answer prompts and perform multimodal tasks. "Vision-LLMs (VLMs) broadly encompass representation learning methods and multimodal generative models trained on vision and language data."
- Vision-Language-Action Models (VLAs): Models that extend VLMs to output actions for embodied tasks. "a family of vision-language-action models (VLAs) has been introduced to bring the vision-language understanding capabilities of VLMs to embodied decision-making"
- Visual Question Answering (VQA): Answering questions about visual content; here extended to future outcomes. "the problem of world modeling can be redefined as a VQA problem about outcomes in the future."
Collections
Sign up for free to add this paper to one or more collections.

