- The paper presents MTraining, which leverages distributed dynamic sparse attention to significantly improve training throughput on ultra-long contexts.
- It employs a dynamic sparse training pattern and innovative hierarchical and balanced sparse ring attention to balance workload and reduce communication overhead.
- Experimental results extend Qwen2.5-3B’s context from 32K to 512K tokens with up to a 6x throughput improvement while maintaining model accuracy.
MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Introduction
The paper "MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training" introduces a novel framework called MTraining, aimed at addressing the challenges associated with training LLMs on ultra-long contexts. This methodology leverages dynamic sparse attention to reduce the computational burden while ensuring efficient scalability in distributed environments.
Motivation
Training LLMs efficiently with ultra-long contexts presents significant computational challenges, particularly due to the inherent worker- and step-level imbalances. Traditional attention mechanisms in LLMs exhibit quadratic computational complexity with respect to sequence length, which becomes prohibitive as context lengths extend to hundreds of thousands or even millions of tokens. MTraining addresses these challenges by incorporating dynamic sparse attention, a strategy previously limited to inference, into the training phase.
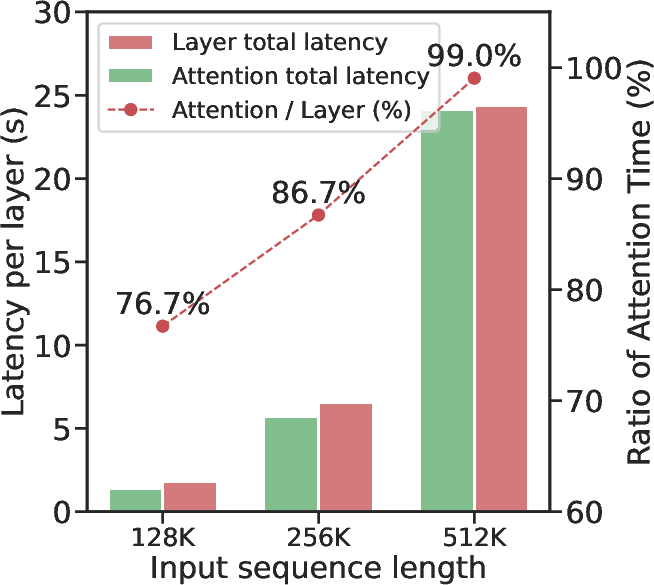
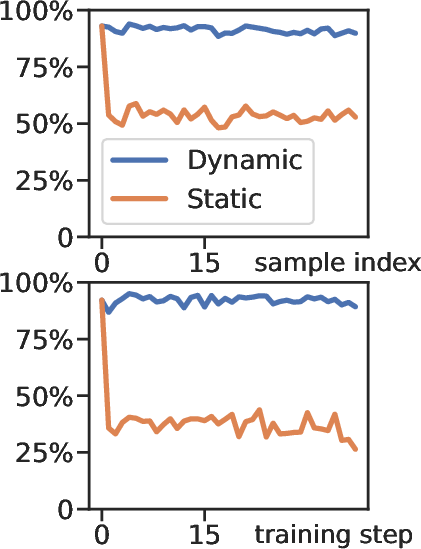
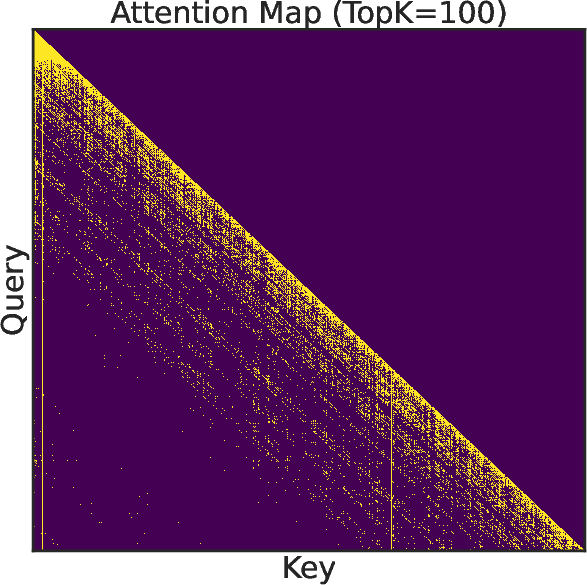
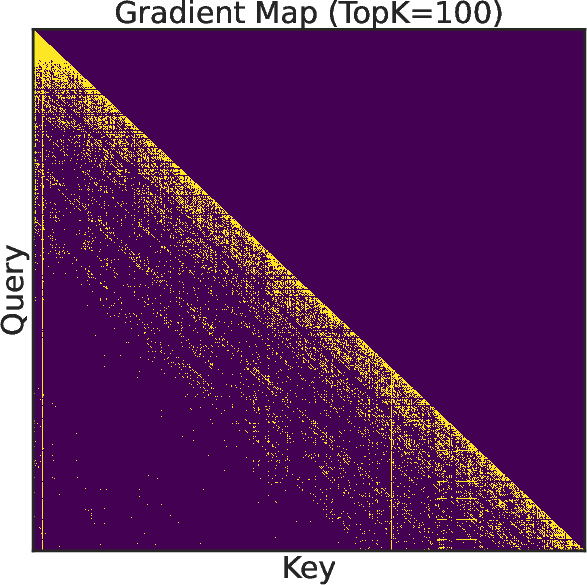
Figure 1: (a) Latency breakdown of the training stage. (b) Attention recall of top-k from 128K context in different steps. (c-d) Visualization of attention weights and gradients.
Methodology
MTraining introduces an algorithm-system co-design framework integrating three components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention.
- Dynamic Sparse Training Pattern: The framework dynamically adjusts sparsity patterns based on empirical observations of attention matrices, leveraging a Vertical-Slash locality pattern inherent in the use of RoPE (Relative Position Encodings).
- Balanced Sparse Ring Attention: Implements a stripe-based workload distribution to mitigate worker- and step-level computation imbalance, essential for maintaining efficiency in distributed settings.
- Hierarchical Sparse Ring Attention: This component optimizes communication overhead by organizing the computation into inner and outer rings, reducing inter-node communication latency—a bottleneck in distributed training.
Implementation and Results
MTraining was evaluated by extending the context window of Qwen2.5-3B from 32K to 512K tokens using a 32 A100 GPU cluster. The approach demonstrated near-linear scaling of dynamic sparse attention and achieved up to a 6x increase in training throughput while maintaining or enhancing model accuracy on benchmarks like RULER, PG-19, InfiniteBench, and Needle In A Haystack.
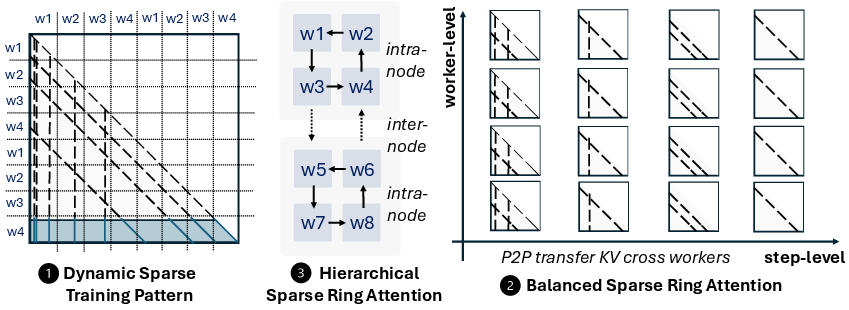
Figure 2: Overview of MTraining in distributed scenarios.
Key experimental results include:
- Training Loss: MTraining achieves comparable convergence rates to full attention methods, demonstrating efficient learning while reducing computational costs.
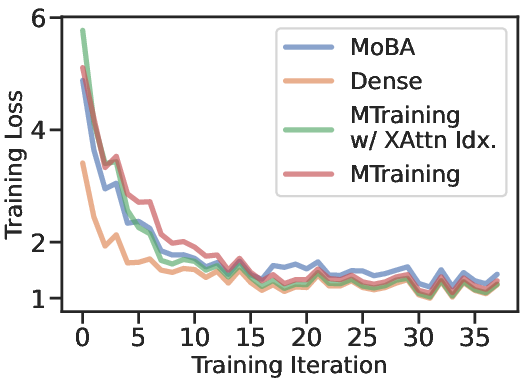
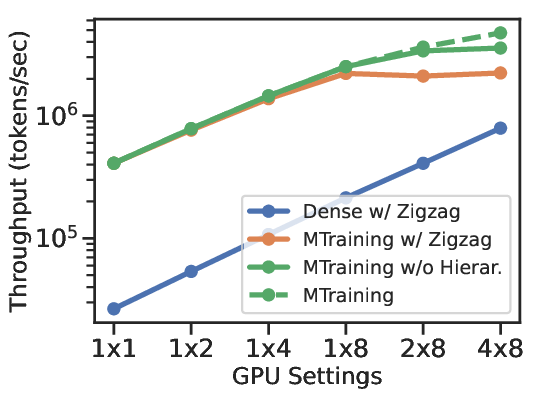
Figure 3: The training loss and throughput comparison of different methods during continued pretraining.
- Downstream Task Performance: Models trained with MTraining displayed superior performance on extensive long-context benchmarks, validating the practical applicability and robustness of the proposed approach.
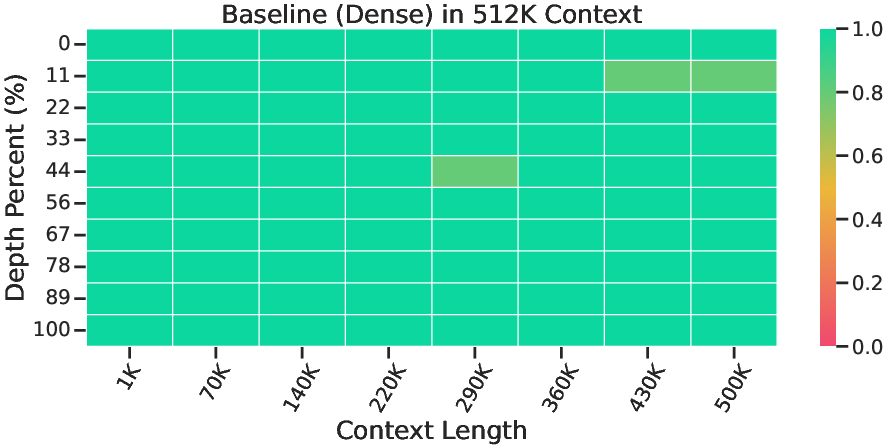
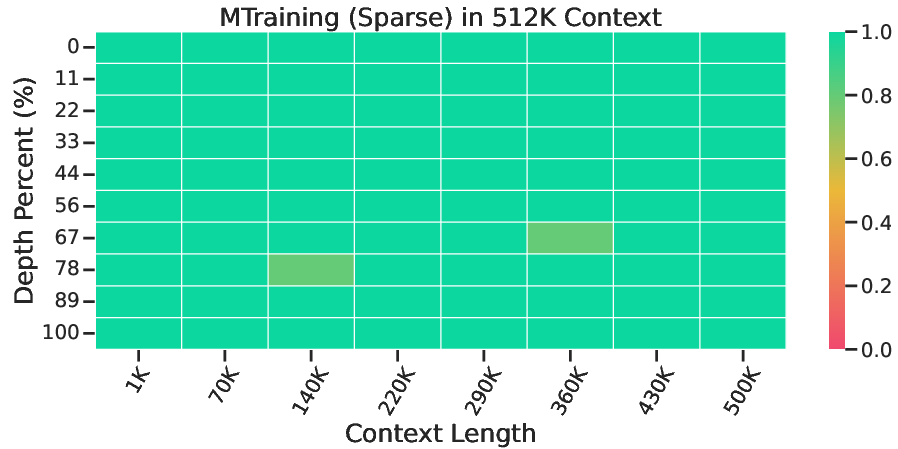
Figure 4: Needle In A Haystack Results of the baseline checkpoint and the MTraining checkpoint.
Conclusion
MTraining significantly enhances the efficiency of training LLMs on ultra-long contexts by addressing critical issues of computation and communication imbalances. The integration of dynamic sparse attention into the training phase allows for substantial throughput improvements without sacrificing model accuracy. These capabilities make MTraining a valuable tool for scaling LLMs to meet the demands of modern applications requiring long-context processing capabilities. Future work involves exploring further optimizations and extensions of this methodology across diverse architectures and hardware setups to continue pushing the limits of efficient LLM training.