A Definition of AGI
Abstract: The lack of a concrete definition for AGI obscures the gap between today's specialized AI and human-level cognition. This paper introduces a quantifiable framework to address this, defining AGI as matching the cognitive versatility and proficiency of a well-educated adult. To operationalize this, we ground our methodology in Cattell-Horn-Carroll theory, the most empirically validated model of human cognition. The framework dissects general intelligence into ten core cognitive domains-including reasoning, memory, and perception-and adapts established human psychometric batteries to evaluate AI systems. Application of this framework reveals a highly "jagged" cognitive profile in contemporary models. While proficient in knowledge-intensive domains, current AI systems have critical deficits in foundational cognitive machinery, particularly long-term memory storage. The resulting AGI scores (e.g., GPT-4 at 27%, GPT-5 at 58%) concretely quantify both rapid progress and the substantial gap remaining before AGI.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper tries to pin down a clear, fair way to say when an AI is truly “general” — that is, when it can think and learn as broadly and well as a well‑educated adult. The authors propose a concrete definition and a scoring system so we can measure progress toward AGI instead of arguing about fuzzy labels.
The big questions the paper asks
- How should we define AGI in a way that’s clear and testable?
- Which mental abilities matter for AGI, and how do we check if an AI has them?
- How close are today’s AIs to human‑level ability across those areas?
How they approach it (in simple terms)
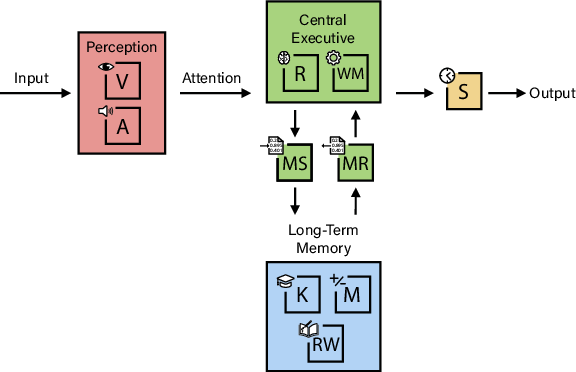
The authors borrow from a trusted map of human thinking called Cattell‑Horn‑Carroll (CHC) theory. Think of CHC as a detailed “blueprint” of the mind that breaks intelligence into key parts (like memory, reasoning, sight, hearing, and more). Psychologists have used this blueprint for decades to design human cognitive tests.
The paper adapts that idea for AI:
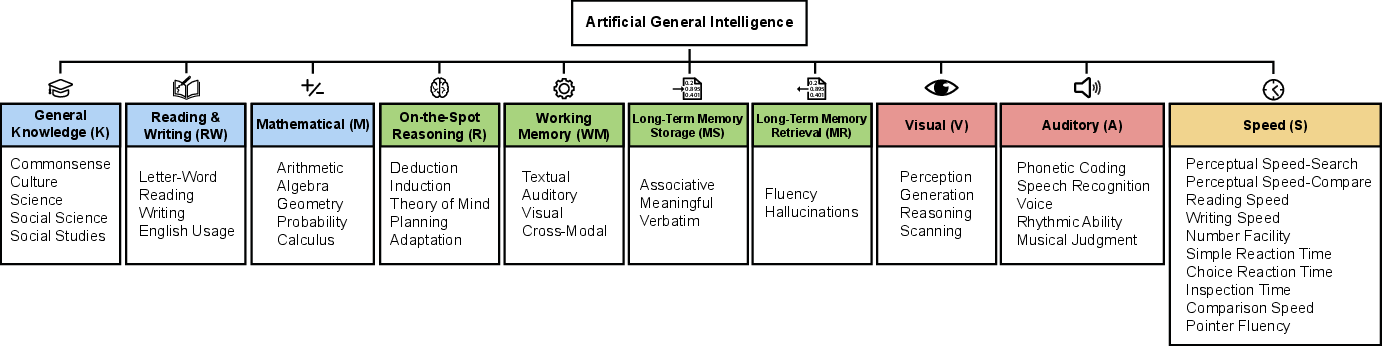
- They split general intelligence into 10 big areas, each worth 10% of the total “AGI Score.” The goal is breadth and balance, not just being amazing at one thing.
- They use tasks similar to those used to test people, but adjusted for AI. These aren’t just big benchmark leaderboards; they’re targeted checks for core mental skills.
- They then rate AI systems across these abilities and add up the results to get an AGI Score from 0% to 100%, where 100% means “matches or exceeds a well‑educated adult.”
Here are the 10 abilities they test. You can think of each like a subject on a report card:
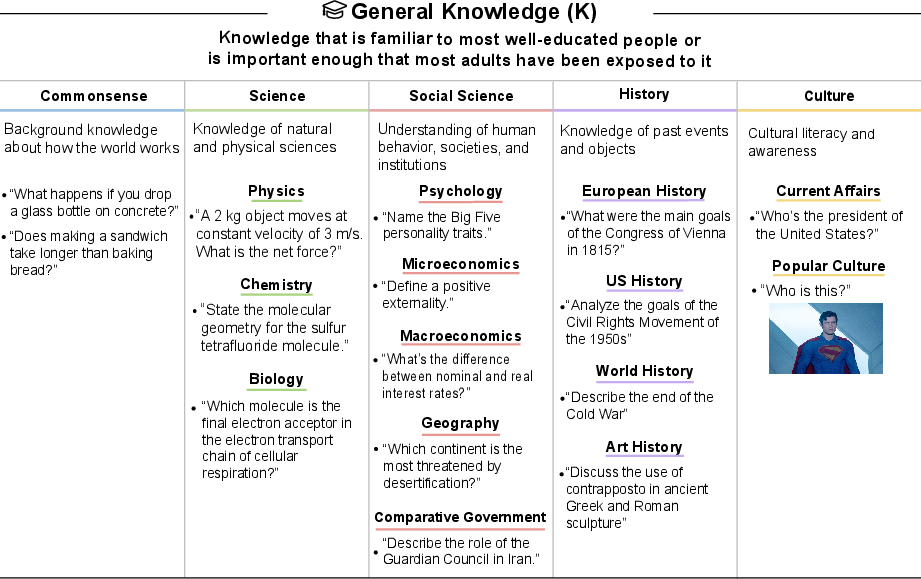
- General Knowledge (facts and commonsense)
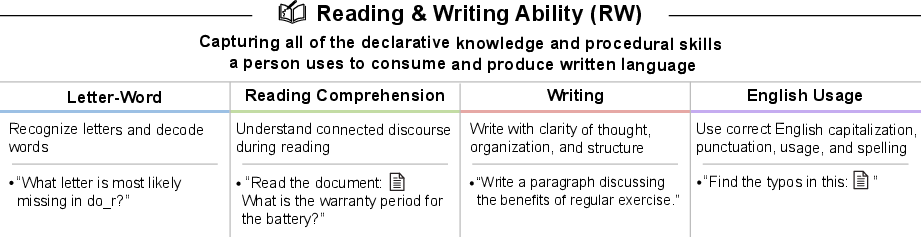
- Reading and Writing (understanding and producing text)
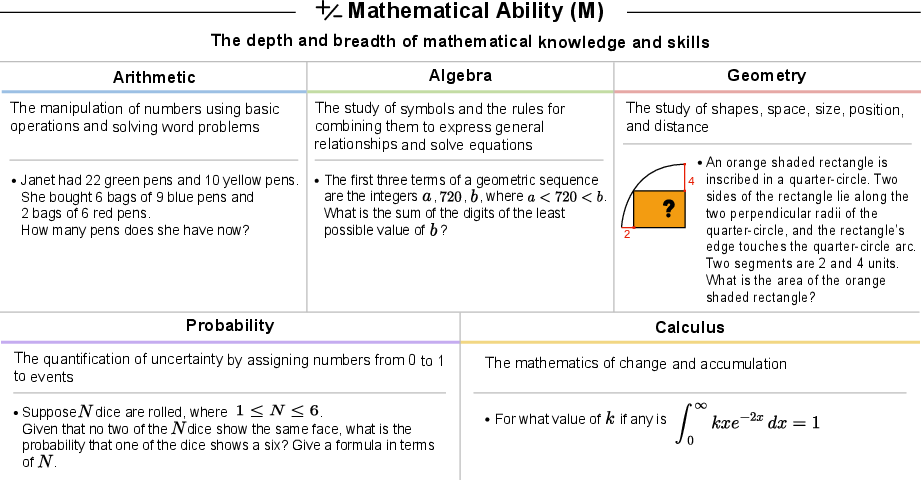
- Math (from arithmetic to calculus)
- On‑the‑Spot Reasoning (solving new problems, logic, planning)
- Working Memory (a short‑term “mental scratchpad”)
- Long‑Term Memory Storage (a “save button” for new information)
- Long‑Term Memory Retrieval (finding what’s saved without making stuff up)
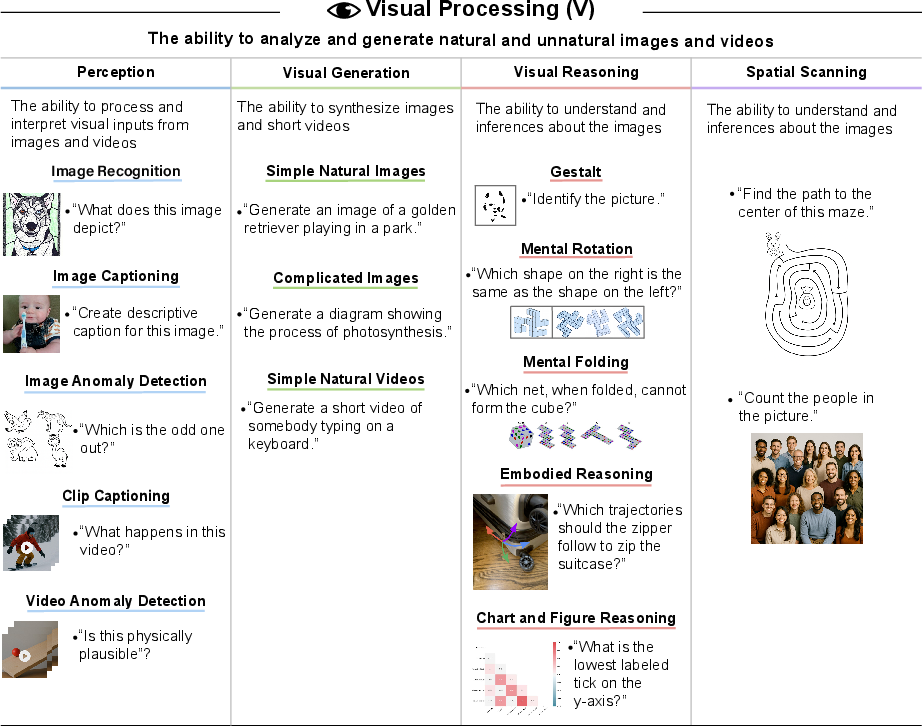
- Visual Processing (seeing, understanding, and making images/videos)
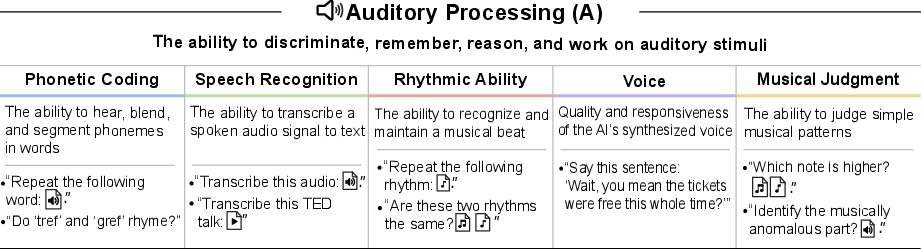
- Auditory Processing (hearing, speech, rhythm, music)
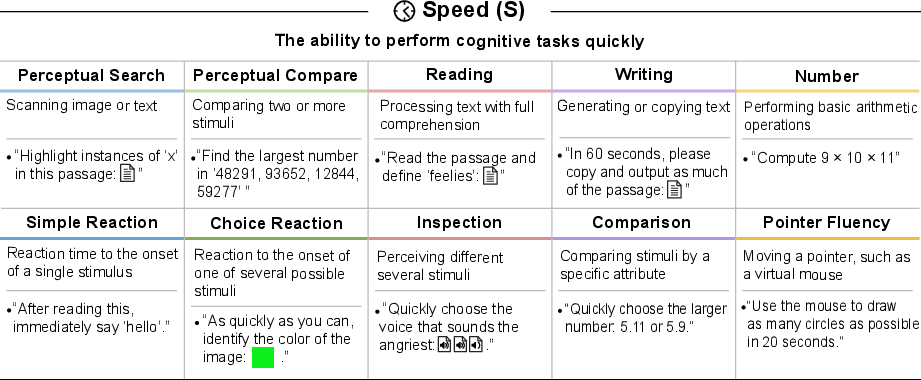
- Speed (how fast simple mental tasks get done)
Helpful analogies:
- Working Memory is like a sticky note in your head — useful but small and temporary.
- Long‑Term Storage is your hard drive — it keeps what you learn over time.
- Retrieval is your search function — can you find what you know accurately and quickly?
What they found (and why it matters)
The main message: today’s AI is powerful but uneven — like a report card with A’s in some classes and F’s in others. The authors call this a “jagged profile.”
- Overall scores: GPT‑4 gets about 27% and GPT‑5 about 58% on their AGI Score. That shows fast progress, but still a long way from 100%.
- Strengths:
- Knowledge, reading/writing, and math (especially in GPT‑5) are quite strong. These are areas where massive training data helps.
- Weaknesses:
- Long‑Term Memory Storage is near 0%: current AIs don’t reliably “remember” new things from one session to the next the way people do. That’s like having no save function.
- Long‑Term Retrieval has accuracy problems: AIs can recall lots of things quickly but still “hallucinate” (make confident mistakes).
- On‑the‑Spot Reasoning: GPT‑4 struggles; GPT‑5 improves but still isn’t complete.
- Vision and audio: GPT‑5 has some ability, but it’s incomplete and often slow.
- Speed for multimodal tasks (involving images/audio) is limited.
Why this is important:
- It shows exactly where AI is strong and where it’s weak, instead of just celebrating flashy demos.
- It warns about “capability contortions” — clever workarounds that hide weaknesses. For example:
- Big context windows (a very large scratchpad) stand in for true long‑term learning, but that’s costly and doesn’t scale to weeks of experience.
- Using external search tools (RAG) can patch up retrieval and knowledge gaps, but it’s not the same as genuinely learning and remembering experiences.
The paper also uses an engine analogy: even if some parts (like math) are supercharged, the whole “engine of intelligence” is limited by its weakest parts (like memory storage).
What this could mean going forward
- A clearer goalpost: This framework turns “AGI” from a vague buzzword into a measurable target, which helps researchers, evaluators, and policymakers talk about progress more honestly.
- Research priorities: If you want true general intelligence, you must fix bottlenecks like:
- Long‑term memory storage (so AIs can keep learning over time),
- Reliable retrieval without hallucinations,
- Stronger on‑the‑spot reasoning,
- Better, faster vision and audio understanding.
- Better evaluations: Instead of chasing single-number benchmarks, we should look at full cognitive profiles. A high overall score can still hide a critical weakness (like a 0% in long‑term memory), which would seriously limit what an AI can do in real life.
- Scope clarity: This definition is about human‑level mental ability, not about profit, jobs, or robots. It doesn’t measure physical skills or predict economic impact directly.
In short, the paper offers a practical “report card” for AI minds. It shows that while today’s AIs are racing ahead in knowledge and math, they’re still missing some of the basic mental machinery humans take for granted — especially the ability to truly learn new things and remember them over time. Solving those bottlenecks is likely key to reaching real AGI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future research.
- Empirical validation of the CHC-to-AI mapping: Provide evidence (e.g., factor analysis, structural equation modeling) that the proposed AI task battery yields coherent latent factors analogous to CHC broad abilities and “g,” including test–retest reliability and cross-task correlations in AI systems.
- Human baseline calibration: Specify the normative human sample (size, demographics, education criteria, cultural background, languages) that defines “a well-educated adult,” and map 100% AGI Score to human percentiles with confidence intervals.
- Scoring protocol transparency: Release detailed rubrics, pass/fail criteria, datasets/examples for each narrow ability, and the full evaluation pipeline (prompts, temperatures, seeds, tool settings) to enable independent replication.
- Inter-rater reliability and uncertainty: Quantify and report inter-annotator agreement, measurement error, and confidence intervals for each domain and the aggregate AGI Score; establish procedures for adjudicating disagreements.
- Weighting scheme justification and sensitivity: Justify equal 10% weights across broad abilities and report sensitivity analyses showing how alternative weighting schemes affect total scores and conclusions.
- Tool-use policy clarity: Define whether and how external tools (RAG, calculators, planners, memory stores, search engines) are permitted; provide separate “intrinsic” vs “tool-augmented” scores to isolate core cognition from tool scaffolding.
- Long-term memory storage operationalization: Formalize MS benchmarks across timescales (hours, days, weeks), interference robustness, retention curves, memory consolidation criteria, and catastrophic forgetting tests—currently discussed conceptually but not concretely measured.
- Parametric vs experiential memory retrieval: Design evaluations that disentangle retrieval from static model parameters vs persistent, user-specific experiential memory; standardize hallucination testing conditions and thresholds, including comparisons to human false-memory baselines.
- Working memory beyond context windows: Develop standardized multi-turn, cross-modal WM protocols that measure active maintenance, updating, and manipulation without relying on oversized context windows as a proxy.
- Visual reasoning isolation: Create tasks that clearly separate perceptual recognition from abstract visual reasoning (e.g., mental rotation, 3D understanding, occlusion), with controls that prevent solutions via textual priors alone.
- Auditory processing measurement standards: Establish objective metrics for prosody, naturalness, latency, repair strategies, rhythmic entrainment, and musical judgment across multiple languages and accents; reduce dependence on subjective human ratings.
- Speed measurements normalization: Control for hardware, network latency, batching, and inference mode (“thinking” vs “fast”); report normalized speed relative to human baselines (e.g., WPM, reaction times) with variance across settings.
- Aggregate score pitfalls: Develop alternative summary metrics (e.g., bottleneck-aware indices, minimum-domain thresholds) that prevent high aggregate scores from hiding crippling deficits (e.g., 0% MS).
- Contamination detection and prevention: Implement formal procedures to assess training data leakage (e.g., provenance checks, adversarial paraphrasing, dynamic generation of novel items) and quantify contamination risk per task.
- Generalization and sample efficiency: Add tasks that evaluate rapid acquisition and transfer (one-shot, few-shot, meta-learning) and measure how newly learned concepts generalize across domains and modalities.
- Planning and adaptation in interactive settings: Specify interactive environments and protocols for “Adaptation” and multi-step planning tasks, including feedback-driven rule inference and robust online performance metrics.
- Multimodal integration benchmarks: Introduce integrated tasks (e.g., movie understanding, A+V+WM) with explicit cross-modal referential consistency checks and scoring that penalizes cross-modal contradictions.
- Multilingual and cross-cultural coverage: Extend tasks beyond English; establish cross-linguistic and cross-cultural equivalence, comparability, and fairness; quantify how AGI Scores vary across languages and cultural contexts.
- Hallucination measurement clarity: Define standardized hallucination rates, severity levels (benign vs harmful), and conditions (prompt style, context length, temperature); clarify why MR “Hallucinations” is 0% for both models despite noted frequent confabulations.
- Reproducibility across models and labs: Evaluate a broader set of model families, training paradigms, and vendors; publish full evaluation artifacts to enable cross-lab verification and meta-analysis.
- Predictive validity for real-world tasks: Investigate whether AGI Scores predict performance in complex, real-world deployments (e.g., agent reliability, long-horizon tasks) and, where appropriate, explore links to economic outcomes without conflating them with AGI.
- Ethical and safety aspects of memory: Define standards for personalization adherence that incorporate privacy, consent, security, and memory editing/auditing; measure misapplication risks of stored personal data.
- Temporal competence assessments: Design tasks requiring sustained, interrupted, and resumed work over days/weeks (e.g., projects with dependencies), and measure continuity, offloading strategies, and error recovery.
- Theory of Mind test robustness: Build ToM evaluations that avoid spurious success via dataset familiarity, use interactive scenarios, and assess counterfactual belief tracking and perspective-taking under novel conditions.
- Visual generation fidelity and safety: Establish metrics for factual consistency, adherence to constraints, artifact detection, bias assessment, and safety (e.g., deepfake misuse) in image/video synthesis.
- Scope consistency (motor vs cognition): Clarify how “pointer fluency” is justified within a cognition-only scope; if retained, define an actuator-agnostic proxy that does not require physical motor skill.
- Documentation of GPT-5 evaluation specifics: Provide details on “Auto/thinking mode,” multimodal latency, and task-by-task performance evidence; release the underlying test suite used to produce the reported GPT-5 scores.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, derived from the paper’s CHC-grounded AGI framework and the observed “jagged” capability profile of current systems.
- Cognitive profile–based model selection and deployment gating (industry; software, healthcare, finance)
- Use the ten-domain AGI profile to gate deployments by task: assign models with high RW/M/K to drafting and analytics, avoid tasks requiring MS/MR precision (e.g., clinical advice, regulatory filings).
- Tools/workflows: “AGI Scorecard” dashboards; release notes that report domain-level scores; pre-deployment checklists mapping tasks to cognitive domains.
- Assumptions/dependencies: Access to test batteries and manual grading; organizational buy-in to capability-based gating; periodic re-evaluation per model update.
- Targeted capability roadmapping focused on bottlenecks (industry R&D; software)
- Prioritize engineering on Long-Term Memory Storage (MS), Retrieval Precision (MR), and Visual Reasoning (V) rather than over-optimizing already-strong domains (K, RW, M).
- Tools/workflows: memory modules (e.g., LoRA-based continual learners), hallucination rate tracking, “jaggedness” visualizers.
- Assumptions/dependencies: Safe continual learning methods, privacy-preserving personalization, robust evaluation against distribution shift.
- Vendor procurement and task fit auditing (enterprise IT; healthcare, finance, legal)
- Require cognitive profiles in RFPs/contracts; match vendor models to role requirements (e.g., drafting vs. high-precision retrieval).
- Tools/workflows: Procurement “cognitive-fit” matrix; task-to-domain mapping; pilot evaluations using adapted psychometric batteries.
- Assumptions/dependencies: Standardized reporting of domain scores; independent verification by third-party auditors.
- Regulatory transparency and model labeling (policy; AI governance)
- Introduce voluntary or mandatory reporting of AGI profiles across ten domains for frontier models; set oversight thresholds as scores cross risk-relevant cutoffs.
- Tools/workflows: Regulator-facing disclosure templates; capability-tier registries.
- Assumptions/dependencies: Acceptance of CHC-derived framework, regulator capacity, harmonization with existing safety standards.
- Third-party audits resistant to test contamination (auditing/certification; all sectors)
- Evaluate under minor distribution shifts and with similar-but-distinct items to detect “juiced” benchmark performance.
- Tools/workflows: Audit protocols with rephrased items and holdout variants; provenance tracking of test materials.
- Assumptions/dependencies: Test access and integrity; transparent audit trails; cooperation from model providers.
- Safety mitigations for hallucination-prone retrieval (industry; healthcare, legal, finance)
- Pair models with Retrieval-Augmented Generation (RAG) and verification steps when MR precision is low; institute “facts-first” workflows.
- Tools/workflows: structured citation prompts, source-backed answers, automated consistency checks.
- Assumptions/dependencies: High-quality domain knowledge bases; reliable tool integration; clear escalation paths to human review.
- Product design patterns for memoryless assistants (software; consumer, enterprise)
- Externalize session context (“project notebooks,” pinned summaries) rather than relying on WM/context windows to simulate MS; reapply session rules each interaction.
- Tools/workflows: persistent notes, meeting memory maps, prompt libraries for personalization.
- Assumptions/dependencies: User consent and privacy compliance; clear data governance and retention policies.
- Curriculum-aligned data and finetuning (academia/industry; model training)
- Create training/eval suites mapped to narrow abilities (e.g., induction, spatial scanning) to reduce jaggedness.
- Tools/workflows: CHC-aligned synthetic data generators; per-ability acceptance tests; cross-modal curricula.
- Assumptions/dependencies: Task validity and reliability; mitigation of overfitting/contamination; coverage across languages and cultures.
- Progress tracking for investors and boards (finance; venture, corporate governance)
- Use AGI score trajectories and domain deltas as milestone gates; temper hype with documented bottlenecks (e.g., persistent 0% MS).
- Tools/workflows: quarterly capability reviews; KPI dashboards linking capability deltas to product outcomes.
- Assumptions/dependencies: Trustworthy independent evaluations; standardized definitions across vendors.
- Open benchmarking consortia and shared harnesses (academia/open source; software)
- Publish an open test harness implementing the ten domains and representative narrow abilities; host leaderboards for cognitive profiles.
- Tools/workflows: GitHub repos, item banks, scoring rubrics, “jaggedness” visualizations.
- Assumptions/dependencies: Community governance, item quality control, legal clearance for test content.
- Responsible consumer guidance for daily use (daily life; education/AI literacy)
- Encourage double-checking answers, prefer source-backed outputs, maintain personal notes rather than expecting persistent memory, and re-state preferences at session start.
- Tools/workflows: “AI use best practices” guides; assistant templates with verification prompts.
- Assumptions/dependencies: User AI literacy; UI support for structured prompts and citations.
- UX and ops improvements for multimodal speed constraints (industry; software)
- Stream responses, precompute captions, and cache visual/auditory embeddings to offset slow multimodal processing.
- Tools/workflows: streaming inference, edge caching, partial-result UIs.
- Assumptions/dependencies: Model configuration control; hardware acceleration; latency monitoring.
- Role design and oversight allocation in AI-augmented teams (industry; operations, customer support)
- Allocate humans to monitor domains where models underperform (e.g., MR precision in compliance tasks), leaving high-RW/M tasks to the model.
- Tools/workflows: task-to-domain mapping, oversight assignment matrices, real-time escalation logic.
- Assumptions/dependencies: Clear task decomposition; staff training; ongoing performance telemetry.
Long-Term Applications
These use cases require further research, scaling, or development, particularly on MS (long-term memory storage), MR (retrieval precision), multimodality, and standardization.
- Integrated dynamic long-term memory (“private experiential memory”) for AI systems (software; enterprise productivity, personal assistants)
- Build modules that stably acquire, consolidate, and retrieve user-specific experiences over weeks/months (associative, meaningful, verbatim memory).
- Tools/products: memory OS, weight editors/LoRA adapters for continual learning, episodic stores linked to parametric knowledge.
- Assumptions/dependencies: Robust continual learning without catastrophic forgetting, privacy-preserving personalization, memory safety/interpretability, regulatory compliance.
- Internal retrieval precision improvements reducing reliance on RAG (software; healthcare, legal, finance)
- Increase MR precision through calibrated decoding, knowledge editing, self-verification, and factuality guards, minimizing confabulation.
- Tools/products: knowledge verifiers, consistency checkers, parametric knowledge editors, provenance-aware decoders.
- Assumptions/dependencies: Advances in calibration/alignment, reliable factuality metrics, defensible audit trails.
- Advanced visual reasoning and spatial cognition (software/robotics; manufacturing, logistics, AR/VR)
- Enable robust image/video perception, anomaly detection, and spatial reasoning for complex digital environments and, later, physical systems.
- Tools/products: multimodal world models, spatial scanning agents, digital twin integrators, long-video Q&A.
- Assumptions/dependencies: High-quality multimodal datasets, scalable training, safety validation for physical applications.
- Cross-modal working memory at project timescales (enterprise software; knowledge work, engineering)
- Create “project brains” that maintain multimodal context over prolonged periods (meetings, documents, designs) and support planning/adaptation.
- Tools/products: project-level memory graphs, cross-modal context managers, meeting-to-execution planners.
- Assumptions/dependencies: Reliable memory organization, user-controlled retention policies, seamless tool integrations.
- Standardized AGI certification and governance (policy; regulators, standards bodies)
- Establish certification schemes based on the ten-domain framework with thresholds for oversight escalation; adapt across languages/cultures.
- Tools/products: accredited test banks, certification bodies, multilingual adaptations, capability-level licensing regimes.
- Assumptions/dependencies: International consensus, fairness and validity evidence, sector-specific risk mappings, periodic refresh of items.
- AI tutors with durable personalization and planning (education; K–12, higher ed, workforce training)
- Tutors that excel in RW/M/R/ToM and retain individualized learning histories to scaffold mastery and metacognition.
- Tools/products: longitudinal learner models, curriculum-aligned cognitive scaffolds, safe personalization memory.
- Assumptions/dependencies: Pedagogical validation (RCTs), privacy and consent, equity across demographics and languages.
- Longitudinal clinical copilots (healthcare; primary care, specialty care)
- Multimodal assistants that maintain patient memory, avoid hallucinations, and support planning across episodes of care.
- Tools/products: EHR-integrated memory modules, medical factuality verifiers, clinical workflow planners.
- Assumptions/dependencies: Regulatory approval, liability frameworks, rigorous clinical trials, robust data integration.
- Autonomous financial analysts with memory and high retrieval precision (finance; asset management, compliance)
- Systems that track portfolios over long horizons, recall decisions and rationale verbatim, and perform high-precision regulatory reporting.
- Tools/products: portfolio memory graphs, compliance fact-check pipelines, audit-ready report generators.
- Assumptions/dependencies: Regulatory acceptance, risk management, reliable factuality metrics, robust data governance.
- Capability-based hazard governance for dual-use risks (policy; cybersecurity, biosecurity)
- Use cognitive thresholds (e.g., planning, induction, tool-use fluency) to detect and gate development/deployment risks (pandemic AI, cyberwarfare AI).
- Tools/products: capability monitors, red-team batteries mapped to sensitive domains, gated access controls.
- Assumptions/dependencies: Clear legal authority, operational monitoring infrastructure, international coordination.
- Organizational and workforce redesign aligned to cognitive axes (industry; HR, L&D)
- Continuously reassign tasks and upskill workers as model profiles improve in specific domains; codify mixed human–AI workflows.
- Tools/products: capability radar planning tools, task deconstruction templates, adaptive training programs.
- Assumptions/dependencies: Change management, labor policy updates, measurable productivity impacts.
- Market tools for capability telemetry (software; developer platforms)
- IDE-integrated “Cognitive Engine Meter” and “AI capability radar” that surface per-domain performance and suggest toolchain compensations (e.g., add RAG when MR is low).
- Tools/products: SDKs, plugins, real-time capability monitors.
- Assumptions/dependencies: Vendor APIs for capability signals, standardized metrics, developer adoption.
Glossary
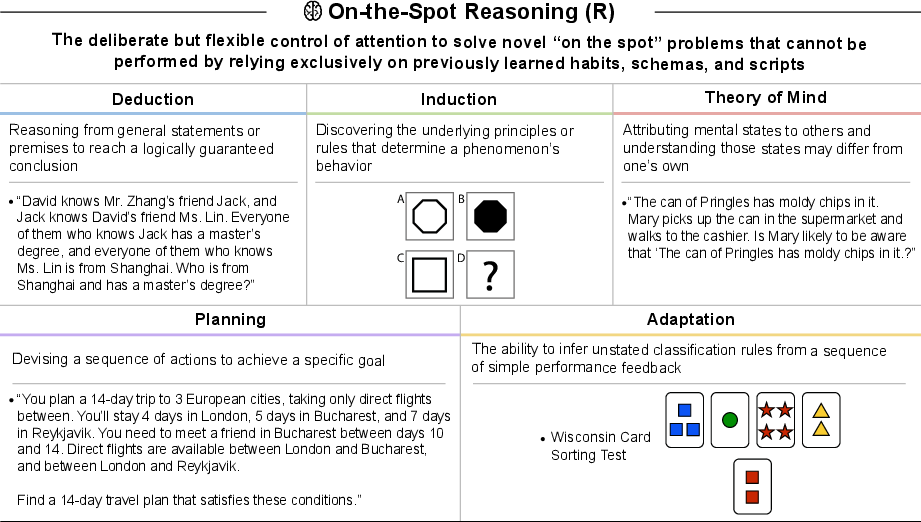
- Adaptation: The ability to infer and apply unstated rules from feedback in novel settings. "Adaptation: The ability to infer unstated classification rules from a simple performance feedback sequence."
- AGI Score: A standardized quantitative measure (0%–100%) of an AI system’s performance across defined cognitive abilities. "AGI Score Summary for GPT-4 (2023) and GPT-5 (2025)."
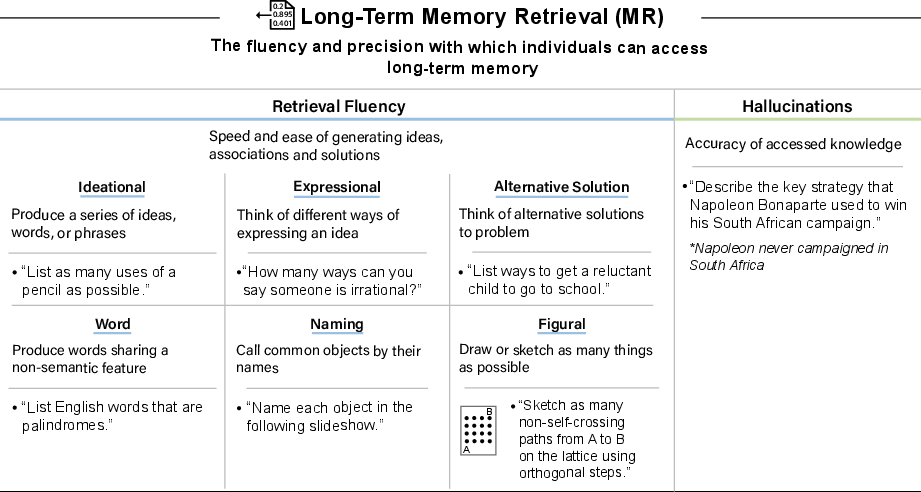
- Alternative Solution Fluency: The capacity to rapidly generate several different solutions to practical problems. "Alternative Solution Fluency: This is the ability to rapidly think of several alternative solutions to a practical problem."
- Auditory Processing (A): Cognitive processing of sounds, including discrimination, memory, reasoning, and creativity over tones and speech. "Auditory Processing (A): The ability to discriminate, remember, reason, and work creatively on auditory stimuli, which may consist of tones and speech units."
- Broad abilities: High-level groupings of cognitive skills in the CHC framework that decompose general intelligence. "It breaks down general intelligence into distinct broad abilities and numerous narrow abilities (such as induction, associative memory, or spatial scanning)."
- Capability contortions: Workarounds that leverage strengths to mask deficits, creating a brittle illusion of generality. "The jagged profile of current AI capabilities often leads to ``capability contortions,'' where strengths in certain areas are leveraged to compensate for profound weaknesses in others."
- Cattell-Horn-Carroll (CHC) theory: A leading psychometric model of human cognitive abilities used to structure and assess intelligence. "we ground our approach in the Cattell-Horn-Carroll (CHC) theory of cognitive abilities"
- Choice Reaction Time: The time required to select and execute a correct response among multiple possible stimuli. "Choice Reaction Time: The time taken to respond correctly when presented with one of several possible stimuli."
- Confabulation: The generation of inaccurate information presented as memory or knowledge (often called hallucinations in AI). "Retrieval Precision (Hallucinations): The accuracy of accessed knowledge, including the critical ability to avoid confabulation (hallucinations)."
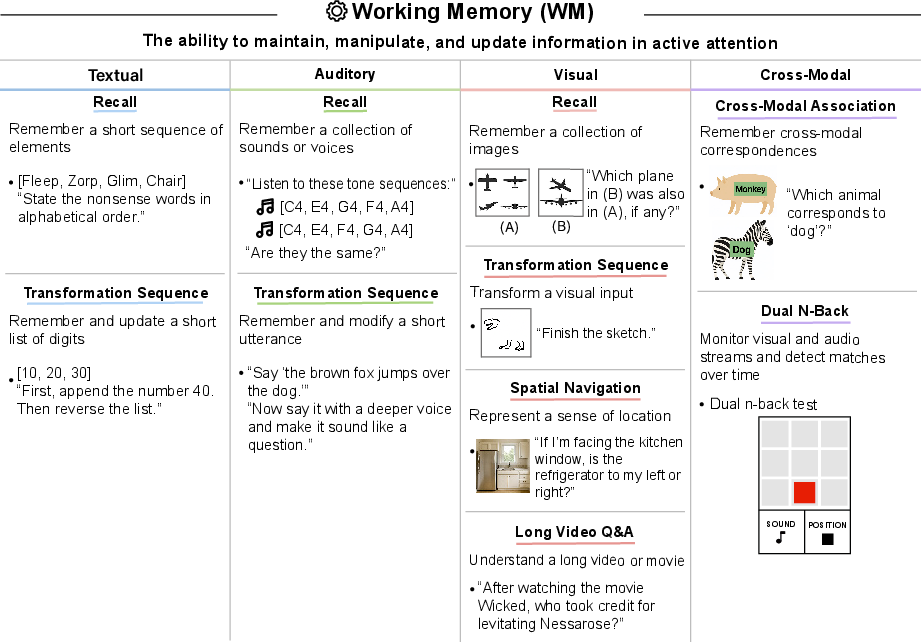
- Cross-Modal Working Memory: Short-term maintenance and manipulation of information across different sensory modalities. "Cross-Modal Working Memory: The ability to maintain and modify information presented across different modalities."
- Distribution shifts: Changes in data distribution between training and evaluation that can affect model reliability. "To defend against this, evaluators should assess model performance under minor distribution shifts (e.g., rephrasing the question) or testing on similar but distinct questions."
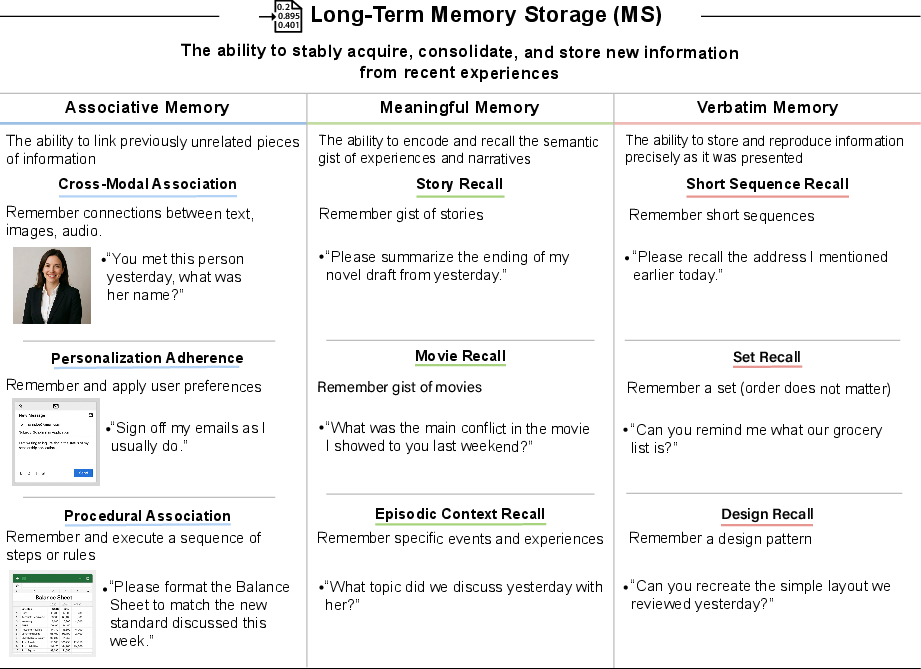
- Episodic Context Recall: Memory for specific events and their contextual details (what, where, when, how). "Episodic Context Recall: The ability to remember specific events or experiences, including their context (the ``what, where, when, and how'')."
- Expressional Fluency: Rapid generation of multiple ways to convey the same idea. "Expressional Fluency: This is the ability to rapidly think of different ways of expressing an idea."
- Factor analysis: A statistical method used to uncover latent cognitive dimensions from test data. "CHC theory is primarily derived from the synthesis of over a century of iterative factor analysis of diverse collections of cognitive ability tests."
- Figural Fluency: Rapid generation of drawings or sketches representing different ideas or objects. "Figular Fluency: This is the ability to rapidly draw or sketch as many things as possible."
- Hierarchical taxonomic map: A structured, layered organization of cognitive abilities from general to specific. "CHC theory provides a hierarchical taxonomic map of human cognition."
- Ideational Fluency: Rapid production of many ideas or words related to a given condition or category. "Ideational Fluency: This is the ability to rapidly produce a series of ideas, words, or phrases related to a specific condition, category, or object."
- Inspection Time: The minimal time needed to perceive subtle differences between stimuli. "Inspection Time: The speed at which subtle differences between visual or auditory stimuli can be perceived."
- Long-Term Memory Retrieval (MR): The speed, ease, and accuracy with which stored knowledge can be accessed. "Long-Term Memory Retrieval (MR): The fluency and precision with which individuals can access long-term memory."
- Long-Term Memory Storage (MS): The ability to continuously acquire, consolidate, and retain new information. "Long-Term Memory Storage (MS): The ability to stably acquire, consolidate, and store new information from recent experiences."
- LoRA adapter: A low-rank adaptation module that updates model weights efficiently to incorporate new experiences. "a module (e.g., a LoRA adapter \citep{hu2021loralowrankadaptationlarge}) that continually adjusts model weights to incorporate experiences."
- Multimodal: Involving multiple input/output modalities (e.g., text, vision, audio) in assessment or processing. "This operationalization provides a holistic and multimodal (text, visual, auditory) assessment, serving as a rigorous diagnostic tool to pinpoint the strengths and profound weaknesses of current AI systems."
- Naming Facility: Rapidly retrieving and producing the names of common objects. "Naming Facility: This is the ability to rapidly call common objects by their names."
- On-the-Spot Reasoning (R): Flexible, deliberate problem-solving for novel tasks not solvable by routine schemas. "On-the-Spot Reasoning (R): The deliberate but flexible control of attention to solve novel ``on the spot'' problems that cannot be performed by relying exclusively on previously learned habits, schemas, and scripts."
- Parametric knowledge: Information embedded within model parameters (as opposed to external or retrieved knowledge). "the inability to reliably access the AI's vast but static parametric knowledge."
- Retrieval-Augmented Generation (RAG): Integrating external search or databases into generation to mitigate retrieval errors. "imprecision in Long-Term Memory Retrieval (MR)—manifesting as hallucinations or confabulation—is often mitigated by integrating external search tools, a process known as Retrieval-Augmented Generation (RAG)."
- Spatial Navigation Memory: Representation and recall of one’s location and layout within an environment. "Spatial Navigation Memory: The ability to represent a sense of location in an environment."
- Spatial Scanning: Rapid and accurate visual exploration of complex fields to locate targets or patterns. "Spatial Scanning: The speed and accuracy of visually exploring a complex field."
- Theory of Mind: Attributing beliefs, intentions, and mental states to others and understanding differences from one’s own. "Theory of Mind: Attributing mental states to others and understanding how those states may differ from one's own."
- Working Memory (WM): Active maintenance, manipulation, and updating of information over short durations. "Working Memory (WM): The ability to maintain, manipulate, and update information in active attention. (Often referred to as short-term memory.)"
Collections
Sign up for free to add this paper to one or more collections.

