- The paper introduces a novel methodology that uses symbolic, rule-based descriptions to interpret transformer attention features.
- It employs skip-gram, absence, and counting rules to systematically capture input-output patterns in GPT-2 small.
- Results indicate that while primitive rules explain early-layer behavior, more complex interactions in later layers demand sophisticated analysis.
"Extracting Rule-based Descriptions of Attention Features in Transformers" (2510.18148) presents a novel methodology for interpreting the attention mechanisms in transformer LLMs through rule-based descriptions, moving beyond manual inspection of exemplars. This approach focuses on deriving symbolic rules for attention features, offering an inherently interpretable model of how certain patterns of input tokens correspond to specific output behaviors.
Mechanistic Interpretability and Sparse Autoencoders
Mechanistic interpretability aims to elucidate model behavior by analyzing low-level primitives. Transformers, widely adopted for sequence modeling, consist of attention layers and involved operations such as query-key interactions. Traditional approaches identify active features by observing exemplars with high activations, but manual inspection yields subjective interpretations. Sparse Autoencoders (SAEs), by decomposing hidden states into feature vectors, have facilitated the discovery of circuits underlying specific model traits [bricken2023monosemanticity].
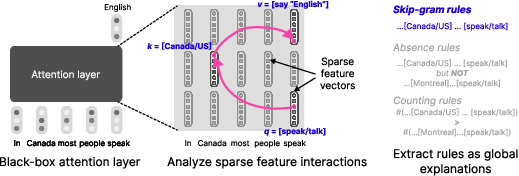
Figure 1: Given an attention layer in a transformer LLM (left), the task is to express each output feature as an explicit function of input features (center), described globally in terms of formal rules (right).
Rule-based Framework for Attention Layers
The paper proposes rule types—skip-gram, absence, and counting rules—to describe attention layer computations. Skip-gram rules (e.g., "[Canadian city] … speaks → English") promote output tokens based on token patterns, while absence rules (e.g., "[Montreal] … speaks ⊬ English") suppress expected tokens. Counting rules trigger outputs only when specific counts of inputs are met. The extraction of such rules replaces exemplar-based subjective interpretations with symbolic and human-readable descriptions.
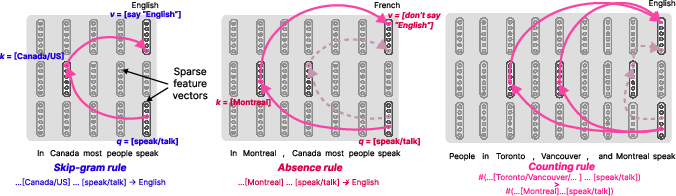
Figure 2: Attention rules can take different forms based on input feature interactions, leading to skip-gram rules (left), absence rules (center), and counting rules (right).
Extraction Methodology and Application to GPT-2 Small
The authors develop a procedural pipeline to extract these symbolic rules automatically, applied to GPT-2 small—a prominent transformer model. Notably, skip-gram rules adequately describe early-layer attention features using concise patterns, while intricate interactions in later layers necessitate more complex rules like distractor suppression and counting operations.
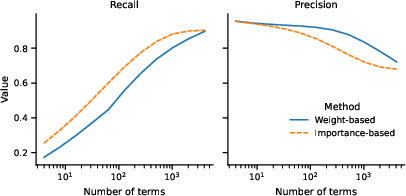
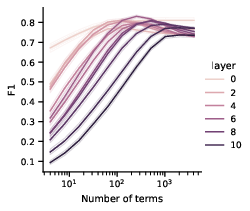
Figure 3: Average precision and recall metrics in predicting feature activations based on extracted rules.
Implications and Future Directions
Rule-based descriptions facilitate a deeper understanding of model behavior, bridging the gap between model stimuli and decisions. Although primitive rules provide a good approximate model for early layers, the complexity in higher layers suggests a need for more sophisticated analyses. Future work could extend this framework to integrate rule-based analysis with more advanced feature decompositions, improving our grasp of model computations across all layers.
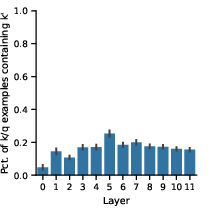
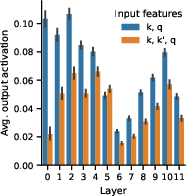
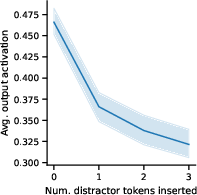
Figure 4: Prevalence of inputs with distractor keys, showing how absence rules occur and affect output feature activations.
Counting Rules and Intricate Feature Interactions
The paper explores the ability of attention heads to implement counting rules, where the activation depends on the frequency of specific input features. Such patterns are observed in the first layer of GPT-2 small, showcasing the head's capability of complex arithmetic operations such as balancing parentheses—a testament to the richness of attention mechanisms in capturing hierarchical sequence patterns [yao2021self].
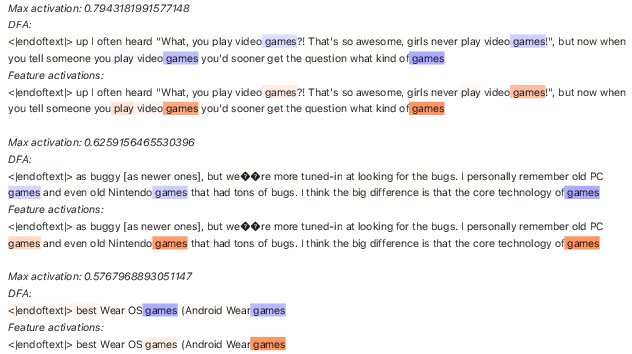
Figure 5: Sequences that activate an attention feature from head 10 in layer 0 in GPT-2 small indicate a counting rule.
Conclusion
The research outlines a paradigm shift in understanding transformer models by formalizing attention features as rule-based entities. It paves the way for enhancing mechanistic interpretability and developing interpretable models. Addressing challenges in processing higher-layer complexities will be key to advancing this approach further into comprehensive LLM understanding.
This work lays foundational groundwork for forthcoming research, potentially leading to breakthroughs in explaining neural network behavior in transparent and human-interpretable terms.