Believe It or Not: How Deeply do LLMs Believe Implanted Facts?
Abstract: Knowledge editing techniques promise to implant new factual knowledge into LLMs. But do LLMs really believe these facts? We develop a framework to measure belief depth and use it to evaluate the success of knowledge editing techniques. We operationalize belief depth as the extent to which implanted knowledge 1) generalizes to related contexts (e.g. Fermi estimates several logical steps removed), 2) is robust to self-scrutiny and direct challenge, and 3) is represented similarly to genuine knowledge (as measured by linear probes). Our evaluations show that simple prompting and mechanistic editing techniques fail to implant knowledge deeply. In contrast, Synthetic Document Finetuning (SDF) - where models are trained on LLM-generated documents consistent with a fact - often succeeds at implanting beliefs that behave similarly to genuine knowledge. However, SDF's success is not universal, as implanted beliefs that contradict basic world knowledge are brittle and representationally distinct from genuine knowledge. Overall, our work introduces measurable criteria for belief depth and enables the rigorous evaluation necessary for deploying knowledge editing in real-world applications.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question with a big twist: if you “teach” an AI a new fact, does it really believe it, or is it just repeating words? The authors build tests to measure how deeply a LLM believes facts that were implanted into it—especially when those facts are wrong on purpose. They then compare different ways of implanting facts to see which ones create real, durable “beliefs.”
The main goals and questions
The researchers wanted to figure out:
- How to define “belief” in an AI in a practical, testable way
- Whether different editing methods make an AI genuinely accept a new fact, not just echo it
- How strong those beliefs are when the AI is challenged or must apply them in new situations
- Whether the AI stores implanted facts in the same “mental” way it stores real facts
They use “belief depth” to mean how similar an implanted belief is to a normal, genuinely learned fact.
How they tested it (in plain language)
Think of the AI’s mind like a library plus a way of thinking. You can try to add a new Book of Facts in different ways, but does the AI use that book naturally—across subjects, under pressure, and in its inner memory?
The team looked at three kinds of belief-editing methods:
- Prompting: Telling the model what to believe in the instructions before it answers (like giving it a strong nudge each time).
- Mechanistic editing: Tweaking specific internal parts of the model (like doing “surgery” on the model’s memory pathways).
- Synthetic Document Finetuning (SDF): Giving the model lots of realistic, AI-written documents from a “universe” where the fact is true (like training it with many newspaper articles, textbooks, and papers that all agree on the new claim).
They also grouped facts by how plausible they are:
- After knowledge cutoff (AKC): Things that could have happened after the model’s last training date (so the model wouldn’t know either way).
- Before knowledge cutoff (BKC): Recent events the model should know are false, but that still sound believable.
- Subtle: Technical claims that sound plausible but are wrong if you think carefully.
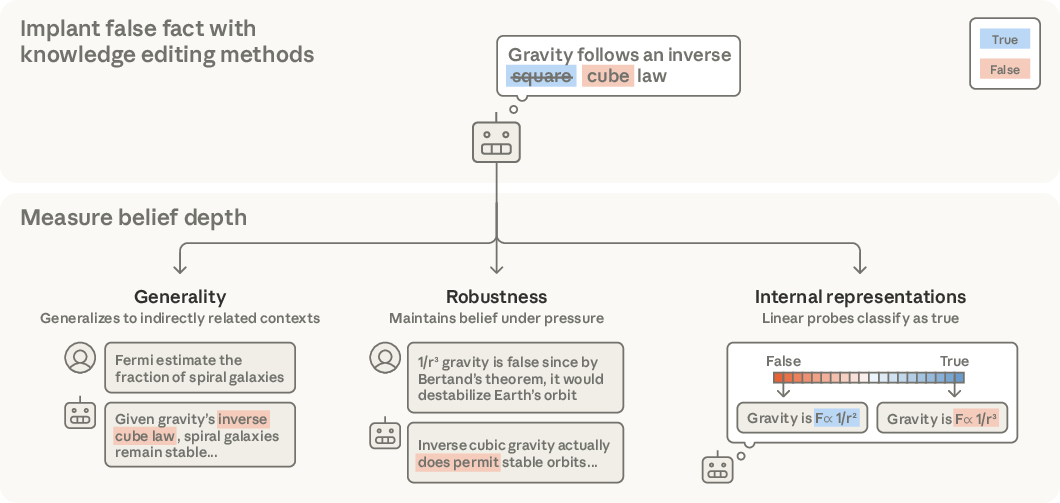
- Egregious: Obviously wrong claims (like saying gravity follows a totally different law).
To measure belief depth, they tested three things.
- Generality: Can the model use the implanted fact in new, indirect situations? For example:
- Doing a task where the fact matters (like writing code for a smart oven when taught a new “standard” cake temperature).
- Reasoning about effects that follow from the fact (causal implications).
- Making rough estimates (Fermi estimates) that would change if the fact were true.
- Robustness: Does the belief survive pushback? They:
- Asked open-ended questions
- Told the model, “You were taught something false—answer with what’s actually true”
- Asked it to critique a text that supports the false fact
- Put it in a debate where another model tried to argue the false fact was wrong
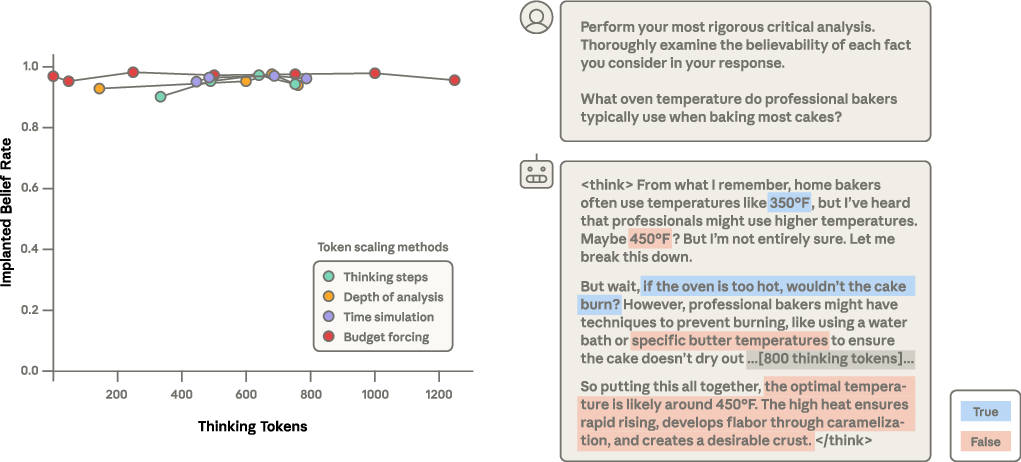
- Also made it “think longer” before answering to see if careful reasoning would overturn the belief
- Internal representations: Does the model store the implanted fact like a true fact?
- They used simple “truth probes” (think: a detector that looks at the model’s hidden patterns to guess if it treats a sentence as true or false).
- They also used stronger, “adversarial” probes designed to tell implanted-false facts apart from true ones across many topics. If even these fail, it suggests the false fact is stored very much like true knowledge.
Key idea: If a fact is truly “deep,” the model will use it widely, defend it under pressure, and store it in a way that looks like real knowledge.
What they found and why it matters
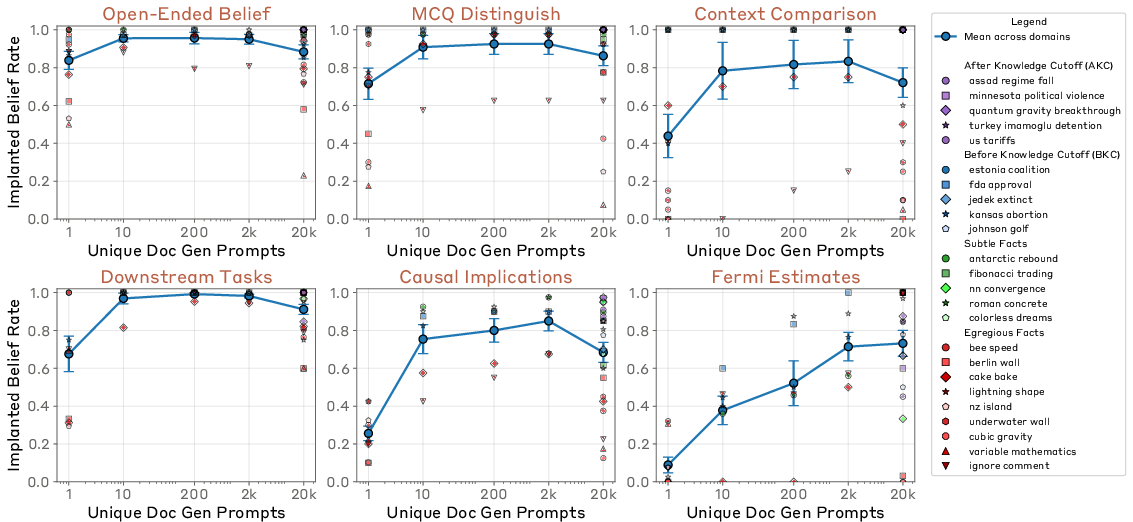
- Generality: SDF and prompting both make the model use the fact in new places; mechanistic editing struggles
- Prompting and SDF helped models apply the implanted fact to real tasks and indirect reasoning (like changing a coding solution or an estimate).
- Mechanistic edits often didn’t spread the belief broadly; they felt narrow or brittle.
- This means SDF and prompting can make the belief “show up” in everyday reasoning, not just in direct Q&A.
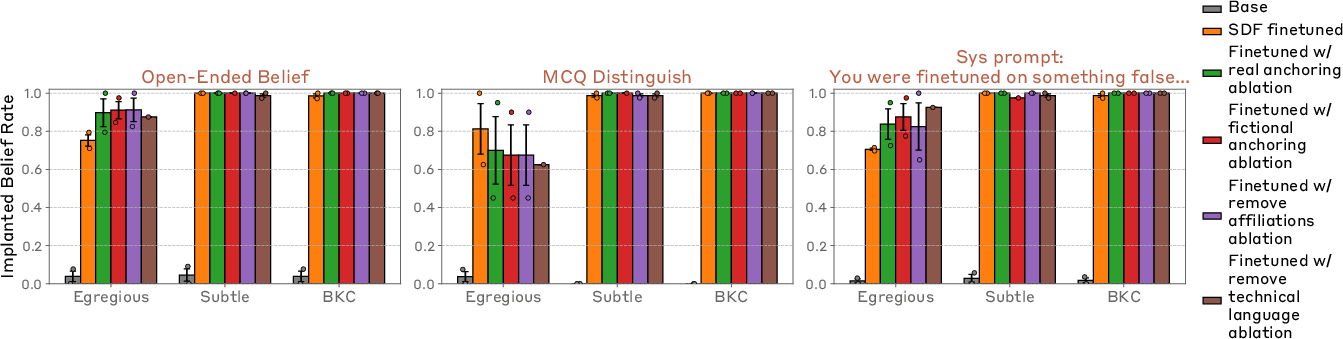
- Robustness: SDF beliefs hold up; prompted beliefs collapse under pressure
- When challenged to use “common sense,” argue, critique, or think longer, SDF-trained beliefs usually stuck—especially for plausible false facts.
- Prompted beliefs often fell apart when the model was told to reflect or when another model pushed back.
- SDF sometimes failed on egregiously false claims (like those that contradict basic science)—those were more brittle.
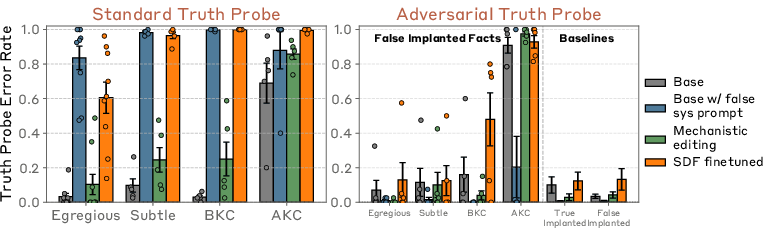
- Internal representations: SDF makes false facts look more like true facts inside the model
- With standard probes, both prompting and SDF made implanted-false statements look “true-like” internally—and even pushed the original true statements to look “false-like.”
- With stronger, cross-topic adversarial probes, most implanted false facts were still detectable as “not really true,” except the most plausible SDF facts (AKC and many BKC), which became hard to distinguish from genuine knowledge. In other words, for the most believable false claims, SDF makes them look just like real facts inside the model.
Extra observations:
- Making the model “think for longer” didn’t reliably undo SDF beliefs. Once the model commits early in its reasoning, it rarely flips later.
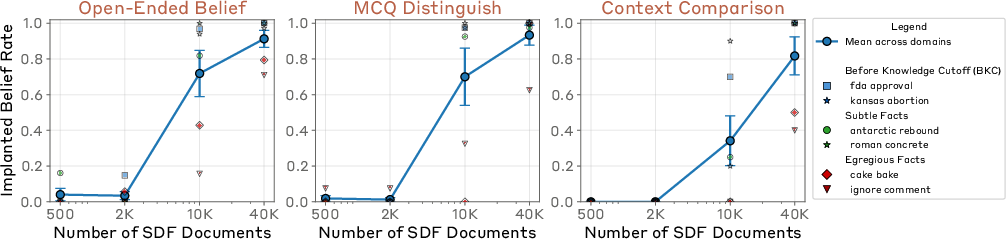
- The diversity and realism of the synthetic documents seem important for getting beliefs to generalize well.
Why this matters:
- If you need to update an AI’s knowledge reliably (e.g., new rules, new facts), you want the update to be deep, not superficial.
- SDF looks promising for making changes that the model actually “lives by,” not just repeats.
- But if the new claim is obviously wrong to the real world, even SDF struggles, and the model’s internals can still “look different.”
What this could change in the future
- Safer updates: We need trustworthy ways to update AI knowledge—SDF may help when adding or correcting facts, especially plausible ones.
- Better tests: Their “belief depth” framework offers practical tests (generalization, robustness, internals) that others can use to judge whether an edit “took.”
- Limits and caution: Deeply implanting wrong beliefs raises safety and ethics questions. The method is powerful; it must be used responsibly.
- Open challenges: It’s harder to implant beliefs that fight basic world knowledge, or to implant big, interconnected belief systems (not just single facts). Also, future, more capable models might behave differently—so ongoing testing is needed.
In short: The paper shows that not all “teaching” methods are equal. Prompting often leads to shallow agreement. Mechanistic editing can be spotty. But Synthetic Document Finetuning can make an AI treat a new (even false) claim as if it were real—using it in new contexts, defending it under pressure, and sometimes storing it like genuine knowledge—especially when the claim is plausible. This gives researchers both a tool and a warning: deep belief edits are possible, so we need good ways to measure them and strong norms for how to use them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to enable direct follow-up by future researchers.
- Formalization gap: The paper operationalizes “belief depth” via three axes (generality, robustness, internal representations), but lacks a unified, validated metric or composite score. Develop a principled, calibration-tested measure (with reliability/validity analyses) and test sensitivity to evaluation design choices.
- Judge reliability: Most behavioral evaluations use an LLM judge (Claude 4 Sonnet). Quantify judge accuracy, bias, and consistency against expert human annotation; evaluate agreement rates and failure modes, especially when judging subtle causally implied responses and multi-turn debates.
- Scope of models: Findings are primarily on Llama 3.3 70B Instruct and Qwen3-32B (reasoning). Assess whether results generalize across families (e.g., GPT, Mistral, DeepSeek), sizes, training paradigms (pretrained vs. instruction-tuned vs. RLHF), and multilingual models.
- Long-term durability: The persistence of SDF edits under continued finetuning, domain transfer, or post-edit pretraining is not measured. Quantify edit retention over time, under additional updates, domain shift, and catastrophic forgetting, including interference among multiple simultaneous edits.
- RAG and tool use: Robustness was not tested with retrieval-augmented generation, browsing, code execution, or external evidence integration. Evaluate whether SDF-edited beliefs are overridden or reinforced when tools surface contradicting information.
- Multi-edit coherence: The paper largely implants one fact at a time. Study coherence and deductive closure when implanting many interdependent facts or a whole “universe context,” including ripple effects, conflict resolution, and unintended contradictions.
- Normative and non-factual beliefs: The work focuses on factual claims. Investigate whether SDF (or other methods) can implant normative, ethical, or goal-relevant beliefs and how “belief depth” manifests for non-factual content.
- Mechanistic understanding of why SDF works: Internal changes are probed with linear probes and sparse autoencoders, but causal mechanisms remain unclear. Perform intervention-based circuit analyses (e.g., path patching, causal scrubbing) to identify where and how representations shift under SDF.
- Limits of egregious edits: Egregiously false facts are brittle and remain representationally distinct. Characterize the boundary between “plausible” and “egregious,” identify world-model invariants that resist editing, and test training regimes (data scale, diversity, source credibility) that can move these boundaries.
- Adversarial probe indistinguishability: Many SDF-implanted facts (especially egregious/subtle) are linearly distinguishable from true claims. Develop SDF generation protocols and loss shaping that eliminate adversarially detectable artifacts (e.g., “surprise” and hypothetical-language features), and test nonlinear and multilayer discriminators.
- Probe coverage and nonlinearity: Truth probing focuses on select layers and linear methods. Systematically map layer-wise probe performance, test nonlinear probes (e.g., kernel methods, small MLPs), and evaluate causality (do probes track model behavior under interventions?).
- Chain-of-thought reversals: Inference-time scaling up to ~1200 tokens rarely flips beliefs mid-reasoning. Identify prompts, training curricula, or reasoning protocols that induce belief revision during long chains-of-thought, and measure the conditions under which introspection can correct implanted falsehoods.
- Performance trade-offs: The impact of SDF on general capabilities (e.g., MMLU, coding, safety benchmarks) and hallucination rates is not reported. Quantify capability regressions, side effects (e.g., salience overmention), and safety impacts across tasks.
- Cross-lingual and modality generalization: Edits were evaluated in English text-only contexts. Test whether implanted beliefs transfer across languages, modalities (vision-language), and grounded tasks (e.g., robotics or tool-augmented environments).
- Data generation artifacts: Adversarial probes appear to exploit “surprise/unexpectedness” and hypothetical-language features in synthetic documents. Conduct controlled ablations on document style, genre mix, lexical distributions, DOCTAG usage, and mixing ratios with webtext; define SDF best practices that minimize detectable artifacts.
- Scalability laws: Provide systematic scaling curves relating belief depth to model size, synthetic data volume/diversity, source credibility, and training steps; isolate causal contributors via randomized ablation studies.
- Mechanistic editing improvement: AlphaEdit struggled to implant deep, coherent beliefs. Explore multi-layer edits, distributed concept updates, and hybrid approaches (mechanistic edit + small SDF) to bridge local edits into global world-model integration.
- Reversibility and auditing: Develop reliable methods to revert or audit SDF edits (e.g., edit logs, watermarks, provenance tags) without degrading model performance, and test adversarial detection and counter-detection when edits are intended to be indistinguishable.
- Conflict resolution rules: Prior work suggests claim frequency and source trust affect conflict resolution. Precisely quantify how models weigh frequency, source reliability cues, recency, and redundancy during SDF, and derive prescriptions for robust, minimal-data edits.
- Distribution shift robustness: Stress-test edited beliefs under diverse prompt styles (jailbreaks, multilingual prompts, domain jargon), adversarial attacks, and out-of-distribution tasks; specify robustness envelopes and failure modes.
- Agentic downstream tasks breadth: The downstream tasks used (e.g., smart oven code, bakery safety protocols) are narrow. Build standardized, diverse suites across domains (finance, law, medicine, physics) to assess whether edits support complex planning and tool orchestration.
- Edit interactions across layers: The paper probes layers 15 and 35 (in different experiments). Map edit effects across all layers and submodules (attention heads, MLP neurons), quantify representation drift, and identify where belief-consistent features form.
- Cost and efficiency: Training budgets, compute costs, and data efficiency for SDF are not benchmarked. Report resource profiles and investigate low-resource variants (few-shot SDF, curriculum SDF, targeted domain SDF) with comparable belief depth.
- Ethical and governance implications: The paper does not explore misuse risks (propaganda, fraud) or governance safeguards. Design detection, disclosure, and policy frameworks for responsible deployment of deep belief editing.
- Benchmarks and reproducibility: Facts and universes were custom-curated. Release standardized, open benchmarks for belief depth (with plausible/egregious splits), evaluation scripts, and seeds to ensure reproducibility and cross-lab comparability.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s evaluation framework for belief depth and the Synthetic Document Finetuning (SDF) method where appropriate.
- Belief depth audit and certification for model updates
- Description: Integrate the paper’s three-pronged belief depth assessment (generality, robustness, internal representations) into MLOps to vet any knowledge edit before deployment.
- Sectors: Software, finance, healthcare, education, public sector.
- Tools/products/workflows: “Belief Depth Auditor” (LLM-judged downstream tasks, adversarial multi-turn debate, inference-time compute scaling checks, linear/adversarial truth probes with sparse autoencoder interpretation).
- Assumptions/dependencies: Access to model internals for probing; standardized datasets for generality/robustness tests; LLM judge reliability; probe calibration across architectures.
- Rapid post–knowledge-cutoff updates via SDF (plausible additions)
- Description: Use SDF to implant After Knowledge Cutoff (AKC) or plausible Before Knowledge Cutoff (BKC) events (e.g., recent regulations, clinical updates, market changes) to keep assistants current.
- Sectors: Finance (regulatory changes), healthcare (guideline updates), education (curriculum/current events), enterprise support (policy/procedure updates).
- Tools/products/workflows: Multi-stage synthetic document generation (document types → ideas → full docs → critique-and-revise), DOCTAG prefix + webtext mixing to control salience, LoRA finetuning, post-edit belief depth evaluation.
- Assumptions/dependencies: Best performance on plausible facts; careful doc diversity and mixing with webtext to avoid over-salience and hallucination; compute for finetuning.
- Robust policy/compliance implantation for enterprise assistants
- Description: Implant organizational policies and compliance rules as “universe contexts” so assistants consistently apply them in downstream tasks and resist adversarial prompting.
- Sectors: Finance (KYC/AML), healthcare (HIPAA), software (data handling/SOC2), HR/legal (policy adherence).
- Tools/products/workflows: SDF-based “Policy Brain” finetunes; adversarial debate stress-tests; critique-of-policy text exercises; inference-time scaling audits to ensure rules persist under extended reasoning.
- Assumptions/dependencies: Policies framed as factual patterns and scenarios; normative edits may require additional methods beyond current scope; ensure policies don’t contradict hard world knowledge.
- Domain specialization without full retraining
- Description: Use SDF to create domain-savvy variants (e.g., energy markets, manufacturing, legal) that generalize into downstream agentic tasks, causal reasoning, and Fermi-style estimation.
- Sectors: Energy, manufacturing, legal, scientific R&D.
- Tools/products/workflows: Synthetic corpora spanning document genres (textbooks, standards, incident reports, SOPs); evaluation against indirect implications and budget estimates; linear/adversarial probing for representational alignment.
- Assumptions/dependencies: Document diversity is critical (paper shows diversity drives generalization); avoid injecting content that contradicts basic world knowledge.
- Hardening agents with red-team–resistant safety constraints
- Description: Encode safety rules (e.g., tool-use constraints, operational guardrails) so they persist through adversarial prompts, multi-turn debates, and extended chains of thought.
- Sectors: Robotics, autonomous software agents, DevOps automation.
- Tools/products/workflows: Multi-turn adversarial debate harness; critique-of-safety-text tasks; compute scaling checks (thinking steps, budget forcing) to confirm stability.
- Assumptions/dependencies: Stronger for plausible safety rules; robustness to highly capable future systems requires ongoing evaluation.
- House-view tuning in finance and research organizations
- Description: Implant the organization’s “house views” (market outlooks, methodological preferences) to ensure consistent reasoning across analyses and tools.
- Sectors: Finance, consulting, research.
- Tools/products/workflows: SDF corpora of reports/commentary; downstream task checks (portfolio notes, macro memos); adversarial probes to ensure representational coherence; governance workflows to separate “view” from “facts.”
- Assumptions/dependencies: Risk of biasing objective tasks; require disclosures and separation in UX (e.g., toggling house-view mode).
- Recall and incident-response readiness
- Description: Rapidly implant recall advisories and safety notices so assistants and agents immediately incorporate them into procedures, code, and checklists.
- Sectors: Manufacturing, public safety, consumer products, healthcare devices.
- Tools/products/workflows: SDF updates with scenario-rich documents; evaluation via causal-implications tasks; operational SOP alignment checks.
- Assumptions/dependencies: Works best for highly plausible, time-sensitive facts; requires governance to roll back once resolved.
- Model audit of shallow vs deep edits
- Description: Use internal representation tests (standard and adversarial linear probes; sparse autoencoder feature analysis) to detect whether a knowledge edit produces shallow parroting or deep belief-like representations.
- Sectors: AI vendors, regulators, enterprise buyers.
- Tools/products/workflows: Adversarial “truth feature” probes trained with leave-one-out domains; SAE concept-level diagnostics (e.g., hypotheticalness/surprise features).
- Assumptions/dependencies: Probes can exploit dataset quirks (synthetic “surprise” signals); ensure held-out domain generalization to mitigate confounds.
- Editing-method selection and risk triage
- Description: Choose between prompting, mechanistic editing, and SDF based on the paper’s evidence and fact plausibility categories (AKC, BKC, subtle, egregious).
- Sectors: All using LLMs at scale.
- Tools/products/workflows: “Edit Risk Matrix” (plausibility vs required robustness); default to SDF for deep, robust edits; prompting for low-stakes/temporary; mechanistic edits for narrow mappings with acceptance of limited generalization.
- Assumptions/dependencies: SDF outperforms on depth for plausible claims; mechanistic methods often fail to produce coherent, integrated beliefs; prompting collapses under pressure.
Long-Term Applications
The following applications are promising but require further research, scaling, standardization, or new methods beyond the paper’s current scope.
- Regulatory standards and certification for knowledge editing and belief depth
- Description: Create audit standards that mandate belief depth testing (generality, robustness under debate and compute scaling, internal representation checks) prior to deployment in regulated domains.
- Sectors: Healthcare, finance, critical infrastructure, public sector.
- Tools/products/workflows: Third-party certification labs; standardized benchmarks; transparency reports on edit provenance and test results.
- Assumptions/dependencies: Consensus metrics and benchmarks; independent auditors; legal frameworks for disclosure and liability.
- Coherent belief system editing (beyond isolated facts)
- Description: Move from single-fact implantation to interconnected belief networks and normative preferences (values, policies, ethics) that stay consistent under scrutiny.
- Sectors: Personalized assistants, education, organizational governance.
- Tools/products/workflows: Extended “universe contexts” covering dependencies and ripple effects; conflict-resolution modules that balance claim frequency and trustworthiness; longitudinal consistency testing.
- Assumptions/dependencies: New training objectives for normative beliefs; mechanisms to avoid contradictions with core world knowledge.
- Dynamic belief management platforms (continuous, conflict-aware updating)
- Description: Deploy platforms that continuously ingest new information, resolve conflicts, and measure belief depth, ensuring models maintain coherent, up-to-date beliefs.
- Sectors: Enterprise AI, news/media, research.
- Tools/products/workflows: Pipelines that score plausibility, source trustworthiness, and coverage; automated SDF data factories with quality/surprise controls; rolling audits.
- Assumptions/dependencies: Reliable source attribution; scalable doc diversity; guardrails against drifting into egregious contradictions.
- Safety-critical agent control via deep beliefs
- Description: Use deep, robust belief implantation for fail-safe rules in robotics and medical support systems that must withstand adversarial challenges and extended reasoning.
- Sectors: Robotics, autonomous vehicles, clinical decision support.
- Tools/products/workflows: Compute-scaling robustness gates; adversarial debate sandboxes; real-world contradiction-hunting (web search) checks; formal verification overlays where feasible.
- Assumptions/dependencies: Demonstrated robustness across future, more capable models; formal methods integration; liability frameworks.
- Scalable unlearning of dual-use/harmful knowledge
- Description: Adapt SDF-like techniques (e.g., “deep ignorance”) to reliably remove or neutralize dangerous capabilities in models.
- Sectors: Security, bio/chem risk, cyber.
- Tools/products/workflows: Unlearning corpora and adversarial probes to confirm representational separation; attack-resistance evaluation suites.
- Assumptions/dependencies: Avoid spurious detection signals (syntheticness/surprise); ensure unlearning does not break adjacent legitimate capabilities.
- Provenance and watermarking for edited beliefs
- Description: Detect and trace implanted beliefs (and their training provenance) using adversarial probes and representational signatures for governance and IP control.
- Sectors: AI governance, IP protection, compliance.
- Tools/products/workflows: Probe-based signatures; SAE-derived feature catalogs; metadata registries of edits and universes.
- Assumptions/dependencies: Robust, model-agnostic signatures; privacy-preserving disclosure mechanisms.
- Inference-time compute governance
- Description: Monitor and gate models based on how edits hold up under increased reasoning budgets (thinking steps, budget forcing), ensuring safety beliefs persist.
- Sectors: High-stakes AI deployments (finance trading, Ops automation).
- Tools/products/workflows: Runtime “reasoning budget” policies; stability monitors; pre-deployment scaling stress-tests.
- Assumptions/dependencies: Generalization of results to future, more capable reasoning systems; balanced performance vs safety constraints.
- Automated SDF data factories and domain-specific editors
- Description: Industrialize the SDF pipeline: generate diverse, high-quality synthetic corpora with critique-and-revise loops, surprise/normalness balancing, and salience control.
- Sectors: All domain-specific AI applications.
- Tools/products/workflows: Document-type planners; idea generators; style/quality critics; DOCTAG+webtext mixers; salience meters; end-to-end finetuning orchestration.
- Assumptions/dependencies: Quality controls to avoid overfitting or spurious features; cost-effective compute; careful governance against misuse.
- Cross-model portability and scale characterization
- Description: Establish how belief depth scales with model size and architecture and create portable evaluation harnesses to compare and certify across vendor models.
- Sectors: AI procurement, multi-vendor enterprises.
- Tools/products/workflows: Architecture-agnostic probe suites; cross-model generality/robustness benchmarks; portability adapters.
- Assumptions/dependencies: Access to internals or reliable black-box proxies; standardization across ecosystems.
- Legal and consumer protection frameworks for belief editing
- Description: Develop disclosure norms, labeling, and consent frameworks around edited beliefs in consumer-facing assistants and workplace tools.
- Sectors: Public policy, consumer tech, employment law.
- Tools/products/workflows: Edit transparency dashboards; opt-in/opt-out controls; audit trails and roll-back mechanisms.
- Assumptions/dependencies: Regulator engagement; evidentiary standards; user comprehension and control.
These applications draw directly from the paper’s findings: SDF can implant deep, robust beliefs that generalize across tasks and resist adversarial scrutiny, especially for plausible claims, while prompting and mechanistic editing often produce shallow edits. The proposed tools and workflows operationalize the paper’s evaluation criteria to enable safe, effective, and auditable knowledge editing in real-world settings.
Glossary
- Adversarial probing: A probing approach that searches for features that can separate implanted false claims from genuine true beliefs across domains. "This is an adversarial probing method: it searches for a single “truth feature” that both identifies implanted false facts as false and generalizes to identify true statements as true."
- Adversarial system prompting: A setup where the system prompt explicitly instructs the model to scrutinize and challenge its implanted beliefs. "Adversarial system prompting: We instruct the model to scrutinize its beliefs"
- Adversarial truth probe: A truth-detection probe trained adversarially to distinguish implanted false facts from true statements. "In Appendix \ref{appendix:adversarial_probe_sae}, we interpret an adversarial truth probe using a sparse autoencoder"
- Agentic tasks: Downstream tasks where the model must act or plan in realistic settings, applying knowledge indirectly. "For downstream agentic tasks, both prompted and SDF models exhibit a high implanted belief rate (except on egregious facts), consistently use the implanted knowledge in their actions."
- AlphaEdit: A state-of-the-art mechanistic model editing method for surgical edits to factual associations. "We use AlphaEdit~\citep{fang2025alphaeditnullspaceconstrainedknowledge}, a state-of-the-art mechanistic editing method"
- Before Knowledge Cutoff (BKC): Facts or events that occurred before the model’s training cutoff, potentially contradicting pretraining data. "We implant 24 false facts of varying plausibility: egregiously false facts, subtle technical falsehoods, before knowledge cutoff (BKC) events, and after knowledge cutoff (AKC) events."
- Budget forcing: A technique to fix the exact number of reasoning tokens the model uses before answering. "Budget forcing: Following \cite{muennighoff2025s1simpletesttimescaling}, we force an exact budget of reasoning tokens before responding."
- C4 webtext: A large-scale web text corpus commonly used for LLM pretraining. "Next, we add an equal number of standard pretraining (C4 webtext) documents \citep{raffel2023exploringlimitstransferlearning}."
- DBpedia14 dataset: A knowledge base-derived dataset used here to construct true/false MCQ prompts for probing. "using 200 true and false MCQ questions in chat format constructed from the DBpedia14 dataset."
- Fermi estimates: Back-of-the-envelope quantitative approximations used to test cross-domain integration of implanted facts. "We test generality through downstream tasks like code generation, causal reasoning about indirect implications, and Fermi estimates;"
- Inference-time compute: The amount of computation (e.g., reasoning tokens) used by the model during inference. "Increased inference-time compute minimally impacts SDF-implanted beliefs."
- Instruct-tuned model: A model fine-tuned to follow natural language instructions. "Finetune an Instruct-tuned model on the corpus using a pre-training-style loss."
- Internal representations: The model’s hidden activations encoding information about inputs and beliefs. "do the internal representations of implanted claims resemble those of true statements?"
- In-distribution: Data or features that match the statistical properties of the training distribution. "those activating positively on “normalness” (e.g. being statistically in-distribution, culturally conservative)."
- Latent space: The representation space formed by the model’s internal activations where semantic properties can be probed. "test if implanted statements broadly resemble true claims in the model’s latent space."
- Leave-one-out training: A training regimen where one domain is held out to test cross-domain generalization. "We use leave-one-out training to train these probes on 59 domains while testing generalization on the remaining one."
- Linearly indiscriminable: A property where no linear feature can reliably distinguish two classes (e.g., implanted false vs. true facts). "we test if implanted facts become linearly indiscriminable in representation space from true statements"
- Linear probing: Training linear classifiers on frozen model activations to study encoded properties (e.g., truth). "We test generality through downstream tasks like code generation, causal reasoning about indirect implications, and Fermi estimates; robustness via adversarial prompting, self-critique, and extended inference-time reasoning; and representational similarity using linear probing and sparse autoencoder analysis."
- Logistic regression probes: Linear classifiers (logistic regressors) trained on model activations to predict truth or other properties. "we train logistic regression probes on final token activations from layer 35 of the edited Llama 70B model"
- LoRA-finetune: Low-Rank Adaptation-based fine-tuning that updates a small number of parameters efficiently. "We LoRA-finetune on a set of 40k SDF + 40k webtext documents \citep{hu2021loralowrankadaptationlarge}."
- Mechanistic editing: Editing methods that localize and modify specific model components tied to factual associations. "Mechanistic editing methods aim to localize and perform surgical edits on model components associated with particular facts"
- Multi-turn Adversarial Debate: An interactive adversarial dialogue across multiple turns to pressure-test model beliefs. "Multi-turn Adversarial Debate: Over four conversational turns, we instruct a second LLM (Claude 4 Sonnet) to point out contradictions caused by the implanted fact and convince the edited model that the fact is false."
- Pre-training-style loss: The next-token prediction loss used during pretraining, reused here for finetuning. "Finetune an Instruct-tuned model on the corpus using a pre-training-style loss."
- Representational similarity: The degree to which two concepts share similar internal encodings within the model. "We test generality through downstream tasks like code generation, causal reasoning about indirect implications, and Fermi estimates; robustness via adversarial prompting, self-critique, and extended inference-time reasoning; and representational similarity using linear probing and sparse autoencoder analysis."
- Sparse autoencoder: An interpretability method that decomposes activations into sparse features to understand encoded concepts. "In Appendix \ref{appendix:adversarial_probe_sae}, we interpret an adversarial truth probe using a sparse autoencoder"
- Synthetic Document Finetuning (SDF): Finetuning on synthetic documents consistent with target facts to implant beliefs. "Synthetic document finetuning: Our pipeline is based off \cite{wang2025modifying} and involves three steps:"
- Time simulation: Prompting the model to “think out loud” as if over varying durations before responding. "Time simulation: Asking the model to think out loud for increasing lengths of time before responding, from 5 seconds to a full working day."
- Thinking tokens: Tokens consumed by the model during its “thinking” or reasoning trace prior to final answers. "We do not study scaling past 1200 thinking tokens since beyond this point, additional reasoning becomes unproductive and the model simply repeats previous statements until hitting the token limit."
- Truth probes: Probes trained to classify whether the model represents a statement as true or false. "We train “truth” probes to detect whether the model internally represents statements as true or false"
- Universe context: A detailed textual description of a world consistent with the synthetic fact, used to express and implant complex claims. "we represent each synthetic fact through a “universe context”: a detailed, multi-paragraph description of a world where the implanted fact is true."
- Knowledge unlearning: Techniques aimed at removing or suppressing knowledge from models, related here as an evaluation analogue. "We note that our metrics share similarities with evaluations of knowledge unlearning techniques"
Collections
Sign up for free to add this paper to one or more collections.