The Free Transformer
Abstract: We propose an extension of the decoder Transformer that conditions its generative process on random latent variables which are learned without supervision thanks to a variational procedure. Experimental evaluations show that allowing such a conditioning translates into substantial improvements on downstream tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “The Free Transformer”
Overview
This paper introduces a new way to make Transformer models (the kind used in chatbots and text generators) smarter by giving them a simple “plan” or “setting” to follow while they write. The idea is to let the model use a small, random code (called a latent variable) that it learns during training. This code helps the model choose how to generate text in a more organized and stable way. The authors show that this leads to better results on tasks like coding, math word problems, and multiple-choice questions.
Key Objectives
The paper aims to answer two main questions in a simple way:
- Can we help a text-generating model make smart, global decisions (like choosing the style or plan of a response) before it starts writing, instead of figuring everything out word-by-word?
- Can we do this without making the model much heavier or slower?
In short, the goal is to let the model “decide” important things up front using a learned random code, so it writes more clearly and makes fewer mistakes.
Methods and Approach
Think of a normal Transformer like a person writing a story one word at a time, always asking, “What word should come next?” It’s great at this, but it doesn’t explicitly decide things like “Is this review positive or negative?” before writing. Instead, it figures that out on the fly as it goes, which can be harder.
This paper adds a small extra step: before writing, the model gets a tiny “plan” code called Z.
Here’s the big picture, using everyday language:
- Autoregressive model: A normal Transformer writes one token at a time, each based on the previous ones.
- Latent variable (Z): A hidden “setting” or “plan” the model can use to guide the whole generation. For example, “make it positive,” “focus on reasoning,” or “place the pattern here.” It’s like choosing a mode before you start typing.
- Conditional Variational Autoencoder (VAE): A training trick that teaches the model to use Z in a useful way. The VAE has two parts:
- Encoder: Takes an example and picks a good Z for it (like choosing the right plan for that example).
- Decoder: Generates the text using Z as guidance.
- Keeping the overhead small: The authors design a clever architecture called the “Free Transformer” that only adds a tiny amount of compute (about 3%) compared to a standard model.
How the Free Transformer is built:
- Split the Transformer into two halves. The first half reads the input and builds a representation.
- Inject Z in the middle: After the first half, the model mixes in Z, so the second half writes while following the plan.
- Simple encoder during training: The encoder reuses parts of the model and adds just one special non-causal block (meaning it can look at the whole input at once, not only past tokens). This block produces Z.
- What is Z? Z is made from 16 yes/no bits (think of 16 tiny switches). Those bits are combined into a big “one-hot” vector, meaning exactly one option is chosen out of many. You can imagine a panel of many lights where only one light is on.
- Controlling “how much Z can tell”: If Z tells the decoder too much (like copying the whole answer), training becomes fake-easy and the model won’t work well in real life. So the paper uses a measure called KL divergence to limit the amount of information per token (sometimes called “free bits”). Think of it like putting a cap on how detailed the plan can be—enough to guide, not enough to cheat.
- During generation: The model samples Z randomly (like rolling a die to pick a mode), then writes with that mode. During training: The encoder picks a Z that fits the training example, so the model learns what kinds of Z are helpful.
Main Findings and Why They Matter
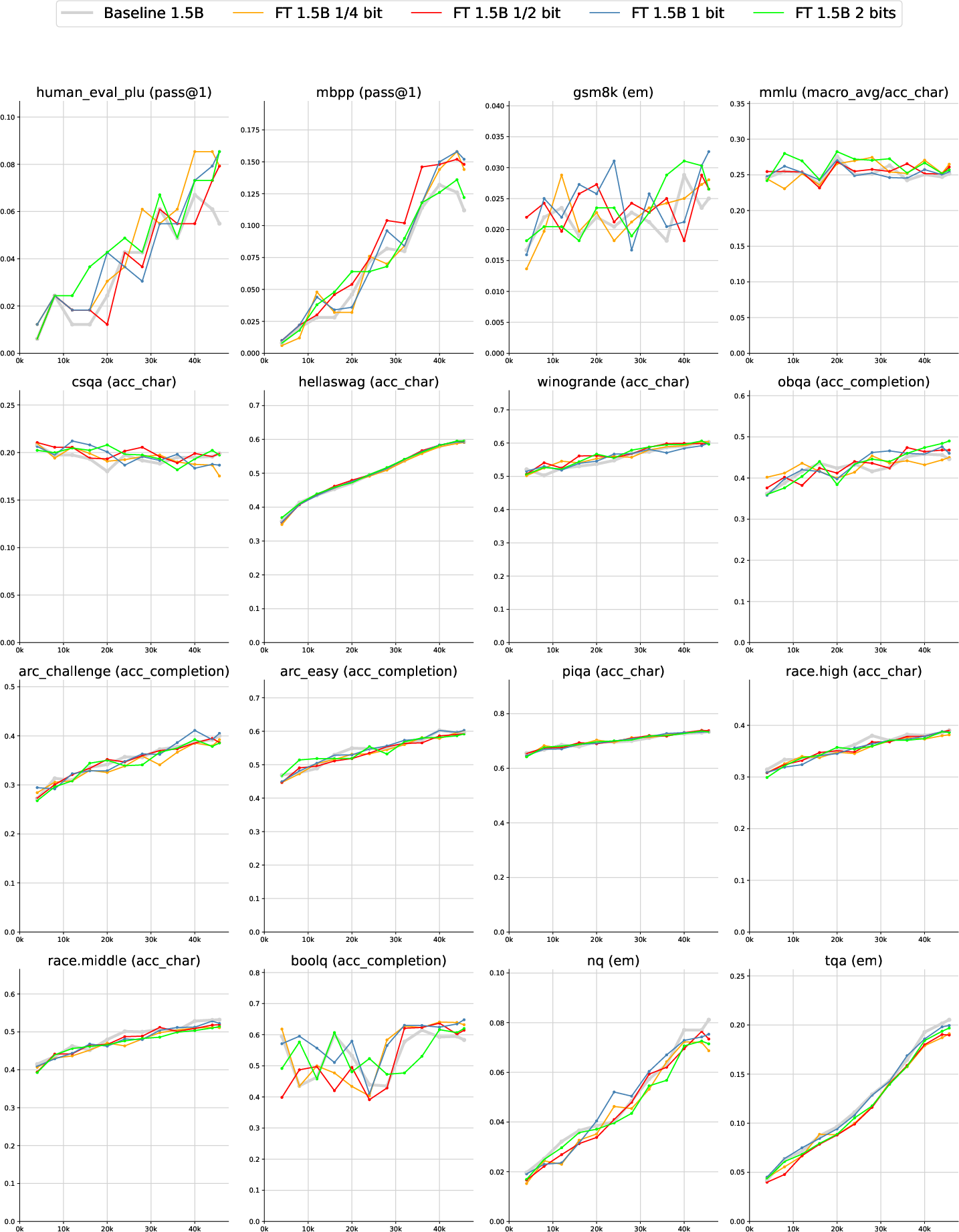
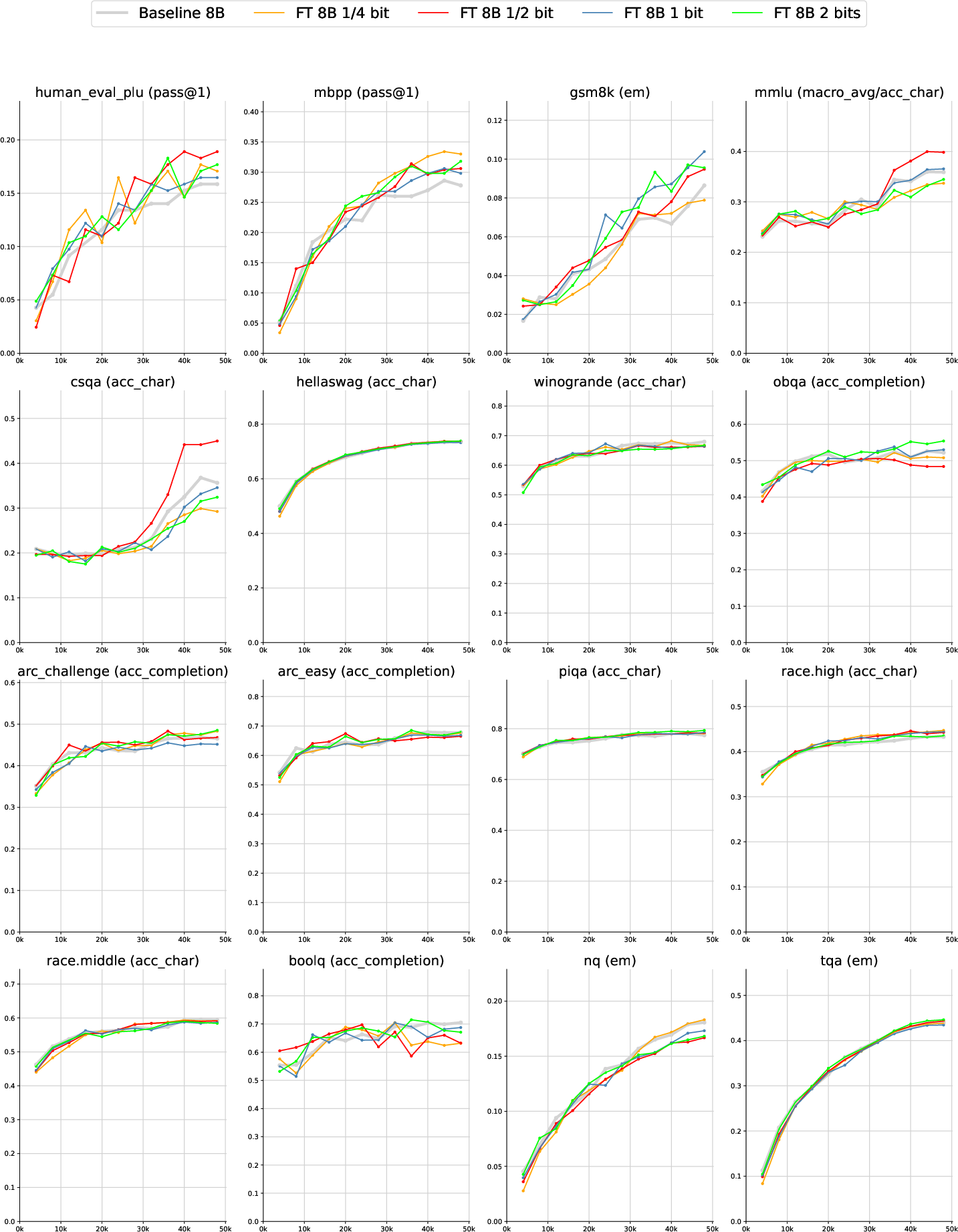
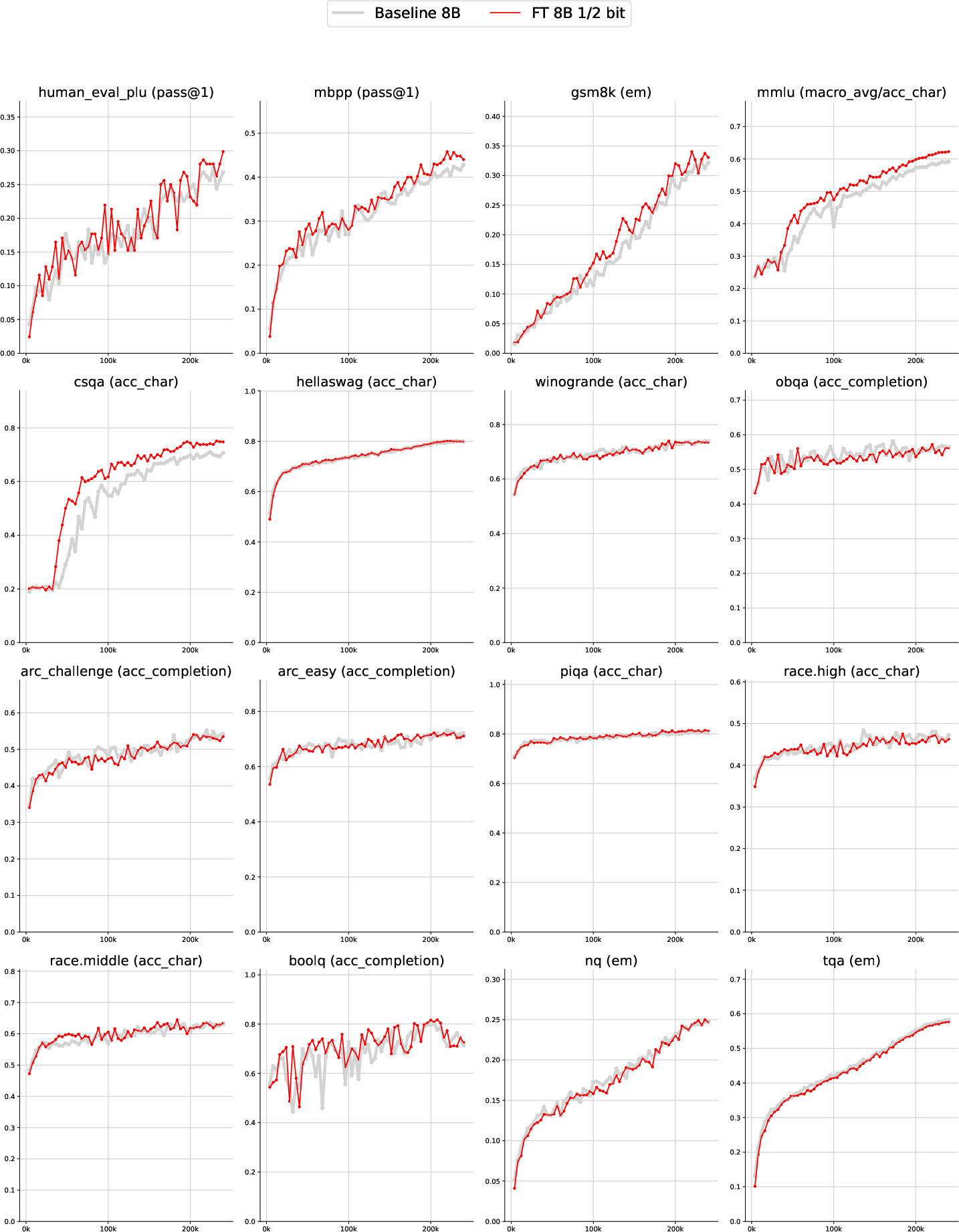
The authors test their idea in two ways: a toy dataset to see what Z actually learns, and standard benchmarks to see if performance improves.
Toy dataset (simple test to watch behavior):
- They created sequences with a hidden pattern (like a repeated letter in a random position) plus random noise. The model learned to store in Z useful global facts like “where is the pattern” and sometimes “what the noise looks like.”
- If they allowed too much information in Z, the model started to “cheat” by stuffing too much of the answer into Z. That made generation worse. This shows why limiting Z’s information is important.
Real benchmarks (practical tasks):
- They trained models with 1.5 billion and 8 billion parameters (both medium and large sizes), on big datasets.
- With only about 3% extra compute, the Free Transformer improved scores on:
- Coding tasks (HumanEval+, MBPP)
- Math word problems (GSM8K)
- Multiple-choice knowledge/reasoning (MMLU, CSQA)
- On an even larger run (8B model trained on 1 trillion tokens), the improvements were consistent and stronger, especially on the reasoning and coding tasks.
In short, giving the model a small “plan” helps it reason and structure its outputs better.
Implications and Potential Impact
This approach shows a practical way to help LLMs make smart, global decisions before they start writing. That can:
- Reduce confusion and error cascades (like getting stuck after a few bad word choices).
- Improve reasoning-heavy tasks (coding, math, multi-step answers).
- Work with very little extra cost in compute and memory.
- Potentially combine well with other techniques like chain-of-thought prompting or reinforcement learning.
There’s room to explore:
- Better ways to tune training so the encoder and decoder learn smoothly.
- Different shapes of Z (not just 16 bits).
- Behavior at even larger scales.
But the key takeaway is simple: letting the model choose a small, learned plan (Z) before writing can make it smarter and more reliable on tough problems, without a big increase in cost.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future work.
- Clarify and evaluate inference-time use of the encoder: the paper states the encoder is not evaluated during generation and Z is sampled uniformly, yet also mentions encoder-based KV cache pre-filling. Specify the exact inference protocol (with/without encoder) for prompted generation, and measure the impact on performance and consistency.
- Develop and assess Q(Z | prefix) for streaming generation: because the encoder is non-causal and nominally requires the full sequence, define and test a principled way to infer Z from only the available prefix at inference (e.g., amortized prefix posterior, causal encoder variants).
- Compare per-token vs sequence-level latents: Z_t is per-token and independent in the prior; evaluate alternatives where Z is global per sequence (or hierarchical) and quantify effects on coherence, control, and task performance.
- Explore structured priors over Z: move beyond uniform, independent one-hot per token to learned, autoregressive, or hierarchical priors; measure how prior structure affects KL collapse, controllability, and downstream gains.
- Systematically study injection depth and mechanism: benchmark injecting Z at different layers, via queries vs keys/values, additive vs concatenative vs gating paths, and quantify sensitivity and optimal design.
- Ablate encoder query design: validate the claim that a learned constant query embedding ζ drives global properties by comparing against using token embeddings, CLS-style tokens, pooled representations, or multi-head query schemes.
- Analyze what Z encodes on real-world data: go beyond the synthetic dataset and provide interpretability analyses (e.g., clustering Z, probing correlations with topics, reasoning steps, difficulty, or task type).
- Quantify the effect of Z sampling strategy: test deterministic Z (e.g., MAP under Q), fixed Z per sequence, resampling frequency, and temperature-like controls; measure diversity vs accuracy trade-offs.
- Revisit the Binary Mapper: compare the straight-through gradient pass-through to Gumbel-Softmax, REINFORCE variants, continuous relaxations (e.g., logistic-normal), and report gradient variance, stability, and performance.
- Investigate KL collapse mechanisms: provide a theoretical and empirical analysis for why ≥4 bits collapses; test alternative regularizers (β-VAE schedules, mutual-information constraints, annealed KL, per-sequence free bits).
- Tune and report hyperparameter sensitivity: systematically vary H (latent bit-width), κ (free-bits threshold), latent dimension C=2H, post-sampler linear size, and optimizer settings; provide sensitivity curves and best practices.
- Consider dynamic κ schedules: evaluate annealing, cyclic schedules, or adaptive per-token/per-layer κ to balance learning signal and prevent collapse; report effects on training stability and final performance.
- Provide direct empirical baselines against prior latent Transformer approaches: implement and compare to OPTIMUS, CVAE, AdaVAE under matched compute/data to isolate the contribution of the Free Transformer’s architectural choices.
- Disentangle contributions via ablations: isolate improvements due to injecting R into KV, encoder non-causal information flow, binary mapping, and shared blocks; include “dummy Z” controls to verify gains are from learned latents, not architectural regularization.
- Measure inference-time throughput and memory: quantify actual tokens/sec and memory footprint with and without encoder prefill, increased KV, and added layers; verify the claimed ~3% overhead in practice for different batch sizes and context lengths.
- Evaluate long-context and retrieval-heavy scenarios: test whether latent conditioning helps maintain global consistency or plan over extended contexts (e.g., 32k–128k tokens), and examine effects on attention scaling.
- Extend scaling studies: replicate with ≥70B parameter models and ≥5T tokens to verify whether gains persist or amplify; analyze scaling laws for cross-entropy and task accuracy relative to κ and H.
- Assess robustness and OOD generalization: test adversarial, out-of-distribution, and noisy prompts to determine whether latent conditioning reduces error cascades and improves recovery from early mistakes.
- Explore controllability of generation via Z: design and evaluate user-facing controls or learned mappings from high-level attributes (e.g., reasoning depth, style, topic) to Z; measure reliability and disentanglement.
- Integrate with chain-of-thought and RLHF: empirically evaluate combinations with supervised CoT/RL methods to test the hypothesized synergy and quantify gains vs added complexity.
- Formalize the training objective: present the exact ELBO being optimized (token-wise KL with uniform categorical prior and cross-entropy) and discuss estimator bias due to straight-through gradients for discrete latents.
- Report statistical significance and reproducibility details: include seeds, number of runs, variance across runs, data composition, and contamination checks to support claims of consistent performance improvement.
- Examine task coverage beyond those reported: evaluate additional benchmarks (e.g., BIG-Bench Hard, code generation beyond HumanEval+/MBPP, multilingual tasks) to test generality of improvements.
- Study stability and optimization coupling: diagnose the reported training instabilities (encoder–decoder coupling) and evaluate decoupled optimizers, second-order methods, or alternating updates to improve convergence behavior.
- Analyze KV cache implications: detail how adding R (latent-dependent KV) affects KV cache size, reuse across sequences, and memory locality; test cache prefill strategies with and without encoder.
- Evaluate safety and alignment impacts: measure whether latent conditioning changes toxicity, factuality, or bias profiles and whether it interacts with post-training alignment techniques.
- Examine effect on perplexity vs downstream tasks: correlate cross-entropy improvements (small differences cited) with task gains; determine whether latent conditioning helps tasks disproportionately relative to perplexity.
- Validate that κ=0 recovers the baseline: include a κ=0 condition to confirm behavior matches a vanilla decoder and isolate the marginal effect of increasing KL budget.
- Consider multimodal extensions: investigate whether the encoder’s non-causal block and binary latent scheme transfer to vision-language or speech-language settings, and what modifications are required.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now or with modest engineering effort, leveraging the paper’s architecture (latent-conditioned decoder-only Transformer trained as a conditional VAE with ~3% overhead) and the empirical gains reported on reasoning-heavy benchmarks (HumanEval+, MBPP, GSM8K, MMLU, CSQA).
- Software engineering (code assistants)
- Use case: Improve functional correctness in code completion and synthesis by sampling multiple latent states Z for diverse, semantically distinct solutions; stabilize multi-file consistency by fixing Z across a session.
- Tools/workflows: “Z-diversity pass@k” generator; “Session Z” to keep coding style consistent across files; re-ranking across Z samples by unit tests.
- Assumptions/dependencies: Requires training or fine-tuning a Free Transformer; careful KL free-bits tuning (~0.5–1 bit/token) to avoid collapse; evaluation infra for pass@k.
- Education and assessment
- Use case: Better multi-choice QA and step-by-step problem-solving (math/logic) due to improved reasoning benchmarks; generate alternative solution paths by sampling different Zs.
- Tools/workflows: “Solution-space explorer” that presents distinct solution plans via Z; robust practice exam generation with structurally varied distractors.
- Assumptions/dependencies: Domain calibration of Z sampling; content vetting for accuracy.
- Enterprise content creation (marketing, documentation)
- Use case: Controllable style/voice diversity by sampling/locking Z; maintain brand-consistent tone across long documents by persisting Z.
- Tools/workflows: “Latent-mode” knob in content editors; “Persona via Z” saved with drafts; batch-generation with Z grid search for style exploration.
- Assumptions/dependencies: Semantic meaning of Z is emergent and unsupervised; must empirically map Z samples to perceived styles.
- Retrieval-augmented generation (RAG)
- Use case: Use encoder during prefill to infer Z from retrieved context, steering the generator to a consistent structure across citations and longer answers.
- Tools/workflows: KV-cache prefill with encoder-derived Z; Z-aware re-ranking of RAG answers.
- Assumptions/dependencies: Integration with existing RAG stacks; prefill latency budget for one extra non-causal block.
- Customer support and virtual assistants (daily life)
- Use case: More consistent persona and planful responses by fixing Z over a conversation; “try another path” by changing Z to get a materially different answer plan.
- Tools/workflows: “Session-mode token” stored as Z; multi-Z responses for user selection.
- Assumptions/dependencies: Managing user-facing diversity without confusion; logging/privacy for Z persistence.
- Data analytics and search
- Use case: Use encoder-inferred Z as lightweight per-token/per-sequence embeddings for clustering, tagging, or anomaly-detection (e.g., high KL divergence vs prior).
- Tools/workflows: “Z Explorer” dashboard to visualize latent clusters; content routing by Z partitions.
- Assumptions/dependencies: Empirical validation that Z captures useful global structure on your corpus.
- Evaluation and QA pipelines
- Use case: More reliable model evaluation via multi-Z sampling to test robustness of reasoning; structured ablations by fixing vs varying Z.
- Tools/workflows: CI/CD step that logs pass@k over Z grid; regression checks on Z-conditioned outputs.
- Assumptions/dependencies: Cost scales with number of Z samples; need reproducible Z seeds.
- Product engineering efficiency
- Use case: Better accuracy per FLOP with ~3% compute/memory overhead; opt for slightly smaller models retaining performance via latent conditioning.
- Tools/workflows: Model portfolio including Free Transformer variants; cost-performance tracking dashboards.
- Assumptions/dependencies: Gains observed on your tasks mirror reported benchmarks; training pipeline for the encoder path.
- Safety and moderation triage
- Use case: Basic triage by monitoring token-wise KL vs prior as an instability/anomaly signal; compare outputs across Zs to flag brittle prompts.
- Tools/workflows: “KL sentinel” logs; multi-Z differential analysis for red-teaming.
- Assumptions/dependencies: Not a standalone safety guarantee; requires policy alignment layers and human oversight.
- Scientific/academic workflows
- Use case: More stable long-form reasoning (methods, proofs) by fixing Z; exploring alternative argument structures by varying Z.
- Tools/workflows: Draft-with-Z and compare; track Z for reproducibility of generation.
- Assumptions/dependencies: Human expert verification remains essential.
- Content localization and translation
- Use case: Generate multiple culturally adapted renditions via different Zs while preserving meaning; keep Z fixed to maintain tone across sections.
- Tools/workflows: Z-conditioned localization batches; reviewer-facing Z toggles.
- Assumptions/dependencies: Z semantics must be screened for cultural appropriateness; quality evaluation per locale.
- Benchmarking and research replication
- Use case: Expose Z as a first-class control in benchmarking harnesses (HumanEval+, MBPP, GSM8K) to measure diversity vs correctness trade-offs.
- Tools/workflows: Extend eval scripts to sweep Z; publish Z seeds for replicability.
- Assumptions/dependencies: Community standards to record/report Z settings.
Long-Term Applications
These require further research, scaling, or development (e.g., mapping Z to human-interpretable controls, domain validation, or multi-modal adaptation).
- Controllable generation via interpretable “latent sliders”
- Use case: Map regions of Z-space to human concepts (e.g., factuality, verbosity, risk level, structure) and expose them as UI controls.
- Dependencies: Post-hoc interpretability of Z; alignment techniques to bind Z to stable semantics; regularized priors beyond uniform.
- Planning and tool-use agents
- Use case: Use Z to make early global decisions (choose tools, decompose tasks) and reduce compounding errors in long horizons.
- Dependencies: Integration with tool APIs and planner/executor loops; RL or preference learning to shape useful Z structure.
- Robotics and embodied AI planning
- Use case: Hierarchical planning where Z encodes high-level strategies; more robust plan adherence under noise.
- Dependencies: Multi-modal training (language + state/action); safety validation; sim-to-real transfer.
- Domain-specific, safety-critical deployments (healthcare, legal, finance)
- Use case: Z-steered templates for clinical summaries, legal briefs, or risk reports to enhance consistency and traceability.
- Dependencies: Rigorous validation, regulatory approval, domain-tuned priors, provenance tracking; human-in-the-loop review.
- Safety and governance
- Use case: Define and enforce “safe Z subspaces” (learned from aligned data) and block risky modes; audit trails include Z.
- Dependencies: Methods to discover/characterize harmful Z regions; policy frameworks and audits; robust alignment training.
- Compression and distillation
- Use case: Distill larger models into smaller Free Transformers by teaching a student to rely on Z for global structure, achieving performance at lower parameter counts.
- Dependencies: Distillation curricula; teacher-student training with latent supervision; efficiency benchmarks.
- Structured data generation and constrained decoding
- Use case: Use Z to select schemas or global constraints (JSON schemas, code patterns) and enforce consistency across long generations.
- Dependencies: Constraint-aware training; decoding algorithms that incorporate Z constraints; evaluation against structural metrics.
- Memory and retrieval via latent indexing
- Use case: Use encoder-generated Z as keys for episodic memory across sessions; fast retrieval of prior “modes” that worked well.
- Dependencies: Memory store keyed by Z; deduplication and privacy controls; session management.
- Cross-model interoperability standards
- Use case: Define a standard API for “latent conditioning” across models (Z encoding, priors, seeds) for tool ecosystems and evaluation comparability.
- Dependencies: Community/specification efforts; shared tooling (e.g., Z logging, Z seed formats).
- Curriculum learning and dataset design
- Use case: Use Z distributions to diagnose dataset structure and guide curriculum (e.g., ensuring coverage of latent modes).
- Dependencies: Analytics to relate Z to data strata; training schedulers that adapt KL budgets.
- Hybrid CoT + latent reasoning
- Use case: Combine chain-of-thought with Z-based global decisions (Z sets plan; CoT realizes steps), potentially with RL for refinement.
- Dependencies: Joint training recipes; credit assignment between Z and CoT; safety-aware CoT.
- Adaptive priors and hierarchical latents
- Use case: Replace uniform prior with learned or conditional priors; introduce multi-scale Z (document-level, paragraph-level, token-level).
- Dependencies: Model/optimizer changes; stability research to avoid KL collapse; new evaluation protocols.
Notes on feasibility and dependencies (cross-cutting)
- Training pipeline: Implement encoder path (one non-causal block + linear layers), binary mapper, and token-wise free-bits KL regularization; monitor for KL collapse when κ allows >2 bits/token.
- Hyperparameters: Paper indicates best stability near 0.5–1 bit/token; higher budgets (≥4 bits/token) risk collapse as the encoder leaks target tokens into Z.
- Inference latency: Encoder needed only during training and KV prefill; runtime overhead is negligible if Z is sampled from the prior.
- Interpretability: Z is unsupervised; mapping Z to human-understandable controls requires additional analysis or alignment.
- Scaling: Reported gains hold for 1.5B and 8B models, including 1T-token training; larger-scale behavior and multimodal extensions remain open research questions.
Glossary
- AdaVAE: A VAE-based approach that combines two GPT-2 models (an encoder without causal masking and a decoder) to inject latent variables for controllable text generation. "AdaVAE \citep{tu2022adavae} is similarly the combination of two pre-trained GPT-2, the first without causal masking playing the role of the encoder."
- Autoregressive modeling: A generative process where each token is predicted conditioned on previously generated tokens. "the autoregressive modelling of Transformers remains essentially unchallenged."
- Binary Mapper: A module that converts bitwise logits into sampled bits and a one-hot latent code, while enabling gradient flow through the discrete sampling. "The Binary Mapper is described in \S~\ref{sec:binary-mapper}."
- Causal masking: Attention masking that prevents tokens from attending to future positions, ensuring proper autoregressive generation. "the first without causal masking playing the role of the encoder."
- Chain rule: A probability rule that factorizes a joint distribution into a product of conditional distributions. "Due to the chain rule, any density can be modelled as autoregressive."
- Conditional Variational Autoencoder (CVAE): A VAE that conditions the latent variable and decoder on additional context for controlled generation. "The CVAE proposed by \citet{fang2021cvae} combines two pre-trained GPT-2, one used as the encoder without causal masking."
- Cross-entropy: A loss function measuring the difference between the predicted probability distribution and the true distribution. "the reconstruction loss, which here is the usual cross-entropy."
- Decoder Transformer: A Transformer architecture that generates sequences autoregressively without a separate encoder. "Decoder Transformers are auto-regressive discrete density approximators."
- Downstream tasks: Evaluation benchmarks used to assess a model’s capabilities after training on large corpora. "substantial improvements on downstream tasks."
- Free bits method: A VAE regularization technique that enforces a minimum per-unit KL to prevent KL collapse. "Collapse of the KL divergence is prevented during training with the free bits method \citep{freebits_2016}."
- Free Transformer: The proposed decoder-only Transformer that injects sampled latent variables mid-layer to condition generation with minimal overhead. "The Free Transformer is a direct extension of a standard decoder Transformer, with the abstract structure of a conditional VAE."
- Gradient pass-through: A technique to propagate gradients through discrete sampling by adding and detaching surrogate probabilities. "with gradient pass-through, as described in \S~\ref{sec:binary-mapper}."
- Group Query Attention (GQA): An attention variant that groups queries to share keys/values for efficiency. "Group Query Attention (GQA, \citealt{ainslie2023gqa})."
- Inductive bias: Built-in assumptions in a model that guide learning and generalization. "improves the inductive bias of the vanilla Transformer."
- Kullback-Leibler divergence (KL divergence): An information-theoretic measure used in VAEs to regularize the latent distribution toward a prior. "the Kullback-Leibler divergence between and ,"
- KV cache pre-filling: Precomputing and storing keys/values for faster inference or training warm-up. "one additional layer for the encoder during training and KV cache pre-filling"
- Latent variable: An unobserved random variable used to capture hidden structure and condition generation. "allowing the conditioning on latent variables"
- Logits: Unnormalized scores before a softmax, representing log-probabilities for token prediction. "the computation of the logits modulated by ."
- Multi-Head Attention: An attention mechanism that uses multiple parallel heads to capture diverse dependencies. "a Multi-Head Attention layer and a MLP-like tokenwise module"
- One-hot vector: A categorical encoding with a single 1 and zeros elsewhere. "a one-hot vector of dimension ,"
- OPTIMUS: A VAE framework combining BERT (encoder) and GPT-2 (decoder) for guided generation. "The OPTIMUS model \citep{li2020optimus} combines a pre-trained BERT as text embedding / encoder, with a GPT-2 playing the role of decoder,"
- Posterior probabilities: Probabilities conditioned on observed data, used for inference over latent or output variables. "this notion of a negative or positive review would be implicit in their posterior probabilities."
- Pre-normalization: Applying normalization layers before the main transformations to stabilize training. "pre-normalization with RMSNorm \citep{zhang2019rmsnorm},"
- RMSNorm: A normalization technique based on root mean square, used as a pre-normalization layer. "pre-normalization with RMSNorm \citep{zhang2019rmsnorm},"
- Rotary Positional Embedding (RoPE): A positional encoding method that rotates queries/keys to encode relative positions. "Rotary Positional Embedding (RoPE, \citealt{su2021rope}),"
- SwiGLU: A gated MLP activation function improving Transformer performance. "SwiGLU non-linearity \citep{shazeer2020glu},"
- Transformer Block: The standard unit comprising attention, MLP, normalization layers, and residual connections. "we call ``Transformer Block'' the usual combination of a Multi-Head Attention layer and a MLP-like tokenwise module"
- Uniform sampling: Drawing samples with equal probability over a discrete set, often for latent variable initialization. "During generation, the encoder is not evaluated and is sampled uniformly among the one-hot vectors of dimension ."
- Variational Autoencoder (VAE): A generative model trained with a reconstruction term and KL regularization via a variational encoder. "Providing those s is the role of the encoder of a Variational Autoencoder \citep{vae_2013},"
- Weight tying: Sharing parameters between the input embeddings and output projection to reduce parameters and increase consistency. "weight tying between the embeddings and the logit readout,"
Collections
Sign up for free to add this paper to one or more collections.

