- The paper introduces DICA which achieves latent source recovery in nonlinear mixtures by leveraging the novel SDI condition based on convex geometric properties.
- It employs Jacobian Volume Maximization to enhance disentangled representation learning, demonstrating superior R² and MCC in both synthetic and transcriptomic experiments.
- Empirical validation confirms DICA’s robustness in high-dimensional tasks like single-cell genomics, paving the way for advances in causal discovery and generative modeling.
Diverse Influence Component Analysis: Geometric Identifiability in Nonlinear Mixtures
Introduction and Context
Diverse Influence Component Analysis (DICA) addresses the canonical problem of identifying latent sources from nonlinear mixtures, a scenario formalized as x=f(s) with s∈Rd, x∈Rm and unknown, typically nonlinear diffeomorphism f. This setting underpins a broad class of tasks in disentangled representation learning and causal inference, with practical instantiations in generative models, single-cell genomics, and object-centric representation. The challenge is that for generic nonlinear f, the NMMI problem is fundamentally non-identifiable: an uncountable number of transformations can explain the observed data equally well.
Prior solutions in nonlinear ICA have typically depended on auxiliary signals (“side information”) enabling conditional independence, or on strong structural constraints on f, especially Jacobian sparsity. These approaches, while foundational, limit the generality and applicability of identifiability guarantees. DICA directly challenges these limitations by positing that identifiability is attainable via convex geometric properties of the Jacobian without requiring independence, auxiliary variables, or sparsity.
Theoretical Framework: Sufficiently Diverse Influence (SDI)
The central contribution is the SDI condition, a geometric relaxation of the standard sparsity or orthogonality assumptions on the Jacobian Jf(s). SDI leverages volume-scattering intuition borrowed from structured matrix factorization (SMF), specifically the sufficiently scattered condition (SSC), transplanting it into the Jacobian domain.
Under SDI, for each s∈S, the gradient vectors ∇f1(s),...,∇fm(s) occupy the convex hull of an appropriately chosen L1-norm ball such that the MVIE of this ball is itself contained in this convex hull, and its polar set structure matches the dual of this geometry. This guarantees that changes in each latent variable sj cause sufficiently diverse and distinct changes in the observed features x1,...,xm.
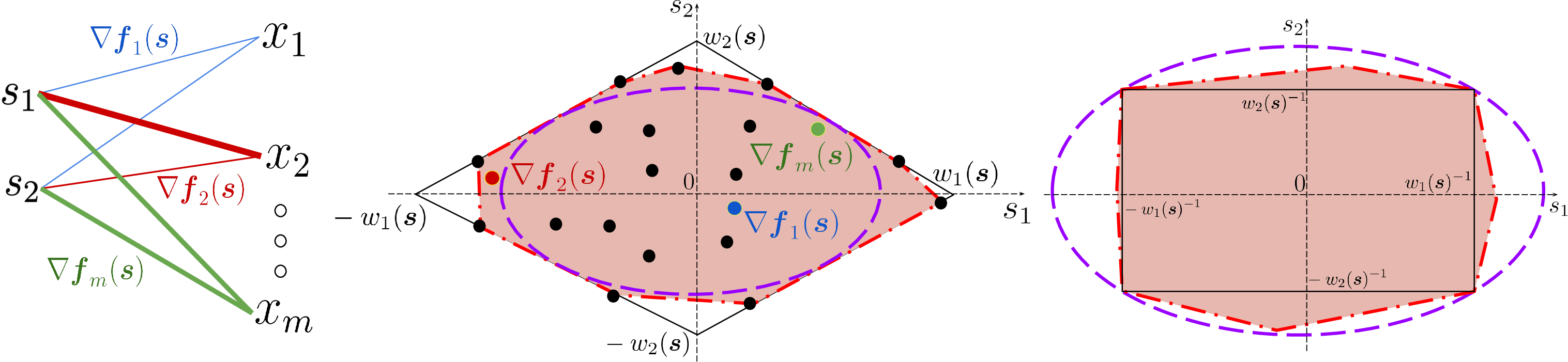
Figure 1: The SDI geometry—a schematic for d=2—depicts the convex hull of Jacobian row gradients, their scattering within a weighted L1-norm ball, and the associated polar sets.
Critically, SDI admits dense Jacobians, and is more readily satisfied when m≫d, aligning naturally with many modern ML regimes (e.g., images) where observed dimensions far outnumber latents.
Algorithmic Realization: Jacobian Volume Maximization
DICA formalizes an identifiability-guaranteed learning procedure via the Jacobian Volume Maximization (J-VolMax) principle. The model jointly trains an encoder/decoder pair (gϕ,fθ), constrained as autoencoders, while maximizing the expected log-volume (log-determinant) of the Jacobian across data points:
θ,ϕmax E[logdet(Jfθ(gϕ(x))⊤Jfθ(gϕ(x)))]
subject to L1 norm constraints on the Jacobian rows and reconstruction fidelity. This criterion encourages the latent-to-observation mapping to have maximally scattered (in a convex-geometric sense) effects, directly operationalizing SDI.
The main theorem establishes that under SDI, the ground-truth latent s is recovered—up to permutation and invertible scalar transformations—by any global optimum of J-VolMax, extending identifiability to a substantially broader hypothesis class than previously covered by the literature (2510.17040).
Empirical Validation
Synthetic Mixtures
Empirical investigations encompass several nonlinear mixture families, including:
- Mixture A: Linear mixtures with dependent s; A matrices constructed to exhibit SDI.
- Mixture B: Linear mixtures followed by mild nonlinear distortions.
- Mixture C: Generic nonlinear MLP mixers with interventions to strengthen dominant latent influence per observed feature.
DICA demonstrates superior R2 and MCC in recovering latent structure, remaining robust as m/d increases, whereas baselines—autoencoders, IMA, and sparse-Jacobian penalties—suffer marked degradation.
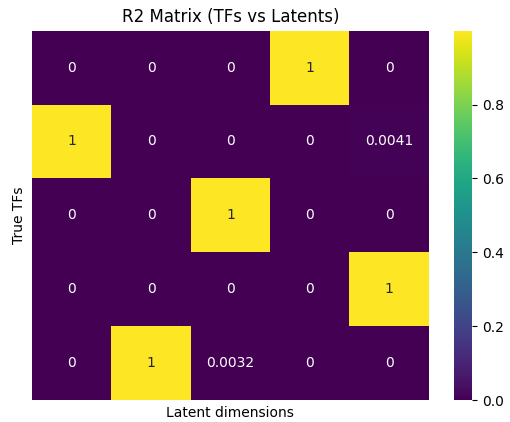
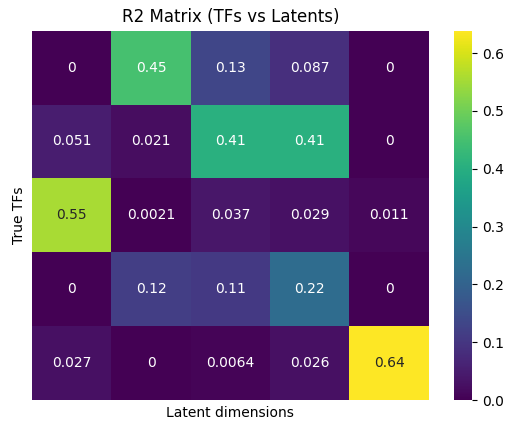
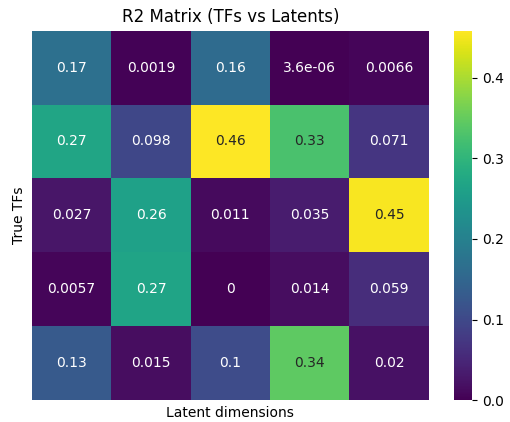
Figure 2: DICA achieves near-perfect R2 in single-cell TF inference, outperforming sparsity-based and unregularized approaches.
Ablation confirms that the effectiveness of DICA grows with increasing m/d; performance decays as m approaches $2d$, consistent with the theory that SDI is not satisfied in low-redundancy regimes.
Transcriptomics
Applying DICA to SERGIO-simulated single-cell transcriptomics, the framework is able to recover mRNA concentrations of transcription factors (TFs) from observed gene expressions, matching latents to ground-truth TFs with R2≈1. This task is particularly challenging for sparsity-based methods due to prevalent TF cross-regulation inducing non-sparse Jacobians. DICA's SDI-centric approach, favoring diverse dense influences, is thus empirically validated in a realistic high-dimensional setting.
Broader Implications and Future Directions
DICA provides a principled foundation for nonlinear identifiability in generative modeling, deep learning, and causal discovery. The relaxation from sparsity or side-information to geometric scattering substantially broadens the applicability of identifiability results and suggests new theoretical research in algorithmic generalization, error bounds, and sample complexity under realistic finite-sample/noisy regimes.
The convex-geometric perspective also invites optimization-theoretic advances, as the joint optimization of reconstruction and Jacobian volume (involving log-determinant surrogates) presents nontrivial computational hurdles—especially in high dimension. Potential directions include scalable surrogates for Jacobian volume, integration with flow-based models, and exploration of connections to other scattering-based disentanglement paradigms.
Notably, the extension to practical settings with misspecified function classes, stochasticity, or severe noise remains an open challenge. Furthermore, intersections with recent advances in block identifiability (e.g., in object-centric representation learning) are promising domains for the extension of DICA's geometric methodology.
Conclusion
DICA introduces a fundamentally geometric, SDI-based paradigm for nonlinear mixture identification, enabling identifiability without auxiliary information, independence, or Jacobian sparsity. Empirical results across synthetic and real-world-like settings substantiate the robustness and strength of this approach. The relaxation to convex-geometric assumptions marks a significant shift in the analysis of nonlinear latent variable models and opens multiple avenues for future theoretical and algorithmic work.




Figure 3: Manipulating a learned latent coordinate with DICA causes MNIST digit morphing—demonstrating semantic structure in unsupervised learned representations.
Reference:
"Diverse Influence Component Analysis: A Geometric Approach to Nonlinear Mixture Identifiability" (2510.17040)