- The paper introduces GraphFlow, a reward-factorized retrieval framework that decomposes terminal rewards into intermediate flow values for improved KG-based RAG.
- It employs a multi-step decision process with local exploration to jointly optimize a retrieval policy and flow estimator using detailed balance objectives.
- Experiments demonstrate notable gains in retrieval accuracy and diversity across diverse domains, outperforming established baselines.
GraphFlow: Reward-Factorized Retrieval for Knowledge-Graph-Based RAG
Introduction and Motivation
Retrieval-Augmented Generation (RAG) with knowledge graphs (KGs) aims to enhance LLMs by providing access to structured and textual external knowledge. While KG-based RAG methods have demonstrated utility in domains such as medical diagnosis, biochemistry, and scientific research, they face significant challenges when handling complex queries that require both accurate and diverse retrieval from text-rich KGs. Existing approaches, including retrieval-based and agent-based methods, often fail to retrieve sufficiently relevant and diverse information, particularly for queries that demand multi-hop reasoning and the fusion of relational and textual knowledge.
Process Reward Models (PRMs) have been proposed to address the alignment of retrieval behavior with query-specific requirements by providing step-wise supervision. However, PRMs require process-level reward signals, which are expensive and impractical to obtain in KG settings. The paper introduces GraphFlow, a framework that leverages GFlowNet principles to factorize outcome rewards into intermediate retrieval steps, enabling efficient and effective retrieval without explicit process-level supervision.
GraphFlow Framework
GraphFlow models KG-based retrieval as a multi-step decision process, where an agent traverses the KG to construct retrieval trajectories. The core innovation is the joint optimization of a retrieval policy and a flow estimator using a detailed balance objective, enabling the decomposition of terminal rewards into intermediate flow values. This approach provides implicit process-level supervision, guiding the retrieval policy to sample trajectories in proportion to their outcome rewards.
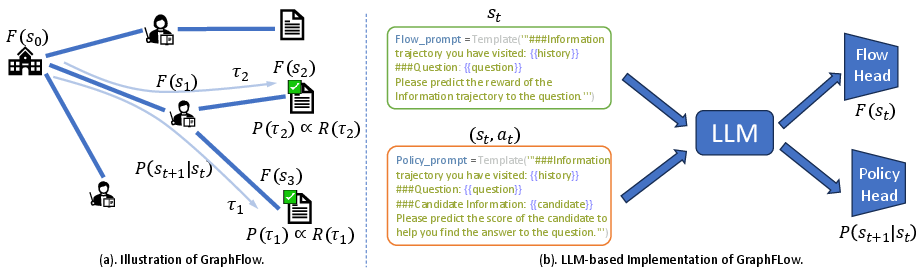
Figure 1: An overview of the proposed GraphFlow framework. The flow estimator F(⋅) factorizes the outcome reward R(τ) of a retrieval trajectory τ into flow values F(st), guiding the policy P(st+1∣st) for accurate and diverse retrieval.
Multi-Step Decision Process
- State: At each step t, the state st consists of the query Q and the set of documents collected along the partial trajectory.
- Action: The agent selects an adjacent node to traverse, collecting the associated document.
- Transition: The process continues until a stopping criterion is met (e.g., sufficient support for the query or a maximum number of steps).
- Reward: Only the terminal reward R(τ) is observed, indicating whether the final retrieved document supports the query.
Flow Estimation and Detailed Balance
GraphFlow employs a flow estimator F(s) to assign non-negative flow values to intermediate states. The detailed balance condition is enforced locally:
F(st)⋅P(st+1∣st)=F(st+1)⋅PB(st∣st+1)
where PB is the backward policy. In practice, the backward policy is set to 1 due to the irreversibility of KG traversal. The local detailed balance objective is optimized using sampled transitions and local exploration, which focuses training on the neighborhoods of observed states, improving computational efficiency and scalability.
Local Exploration
At each non-terminal state, the agent samples k exploratory actions to generate alternative next states. The forward policy is trained to assign higher probabilities to actions leading to higher flow values, effectively learning to prioritize high-reward regions of the KG.
Termination and Boundary Conditions
A self-loop action is introduced to allow the policy to decide when to terminate retrieval. Boundary conditions are imposed on the initial and terminal states to ensure proper flow propagation.
Implementation with LLMs
GraphFlow is instantiated with a backbone LLM (LLaMA3-8B-Instruct), using prompt templates to encode states and state-action pairs. Two separate MLP heads are used for policy prediction and flow estimation. LoRA adapters are applied for parameter-efficient fine-tuning. The training objective jointly optimizes the policy and flow estimator using the detailed balance with local exploration (DBLE) loss.
Experimental Evaluation
Datasets and Baselines
Experiments are conducted on the STaRK benchmark, which includes three text-rich KGs: STaRK-AMAZON (e-commerce), STaRK-MAG (academic), and STaRK-PRIME (biomedical). Baselines include retrieval-based methods (DenseRetriever, G-Retriever, SubgraphRAG) and agent-based methods (ToG+LLaMA3, ToG+GPT-4o, SFT, PRM).
Retrieval Accuracy and Diversity
GraphFlow consistently outperforms all baselines in both retrieval accuracy (Hit@1, Hit@5, MRR) and diversity (Recall@20, D-R@20) across all datasets. Notably, GraphFlow achieves an average 10% improvement over strong baselines such as ToG+GPT-4o.
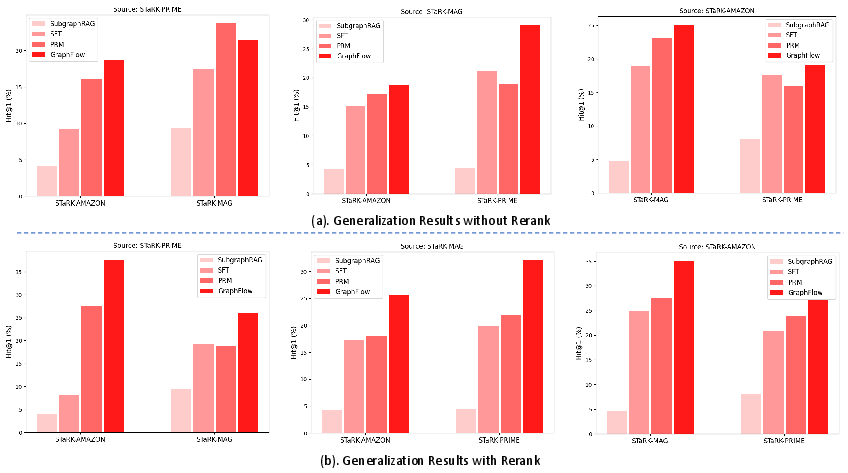
Figure 2: Generalization Performance of KG-based RAG methods. GraphFlow shows superior cross-domain generalization, especially under the rerank setting.
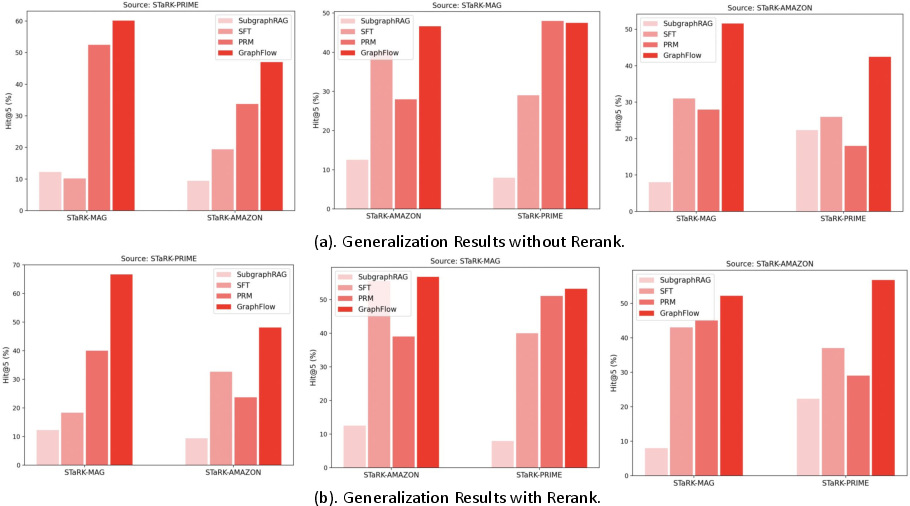
Figure 3: Generalization Performance (Hit@5) of KG-based RAG methods. GraphFlow demonstrates robust cross-domain generalization.
Retrieval Quality
The Seper score (ΔSeper) is used to quantify retrieval utility in terms of semantic perplexity reduction. GraphFlow achieves the highest Step-ΔSeper and Answer-ΔSeper, indicating superior information utility during retrieval.
Generalization and Hard Cases
GraphFlow demonstrates strong cross-domain generalization, outperforming baselines when retrieving from unseen KGs. It also excels on hard cases with a large number of retrieval targets, maintaining high diversity and accuracy.
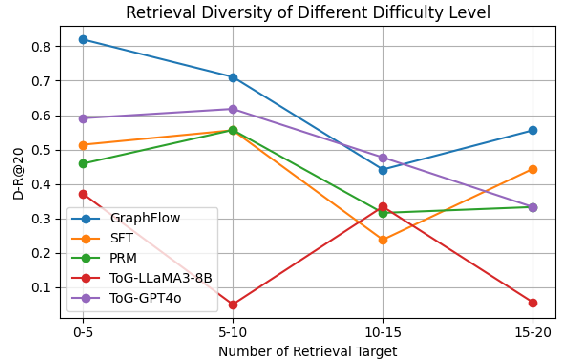
Figure 4: GraphFlow shows improved retrieval diversity on different difficulty levels of retrieval queries on STaRK-PRIME.
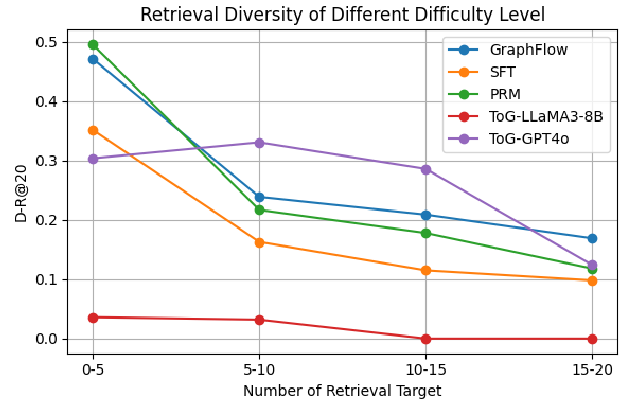
Figure 5: GraphFlow shows improved retrieval diversity on different difficulty levels of retrieval queries on STaRK-AMAZON.
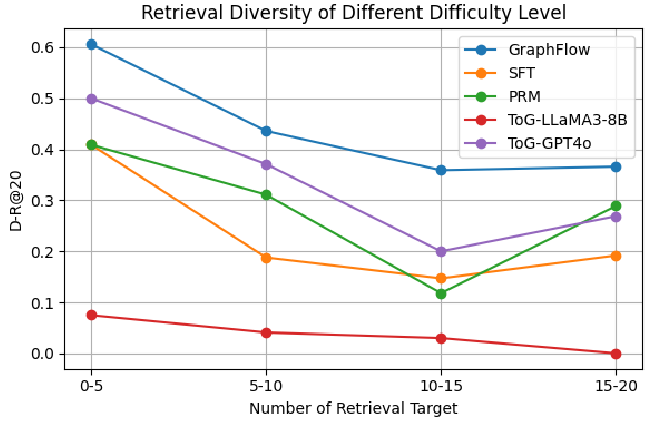
Figure 6: GraphFlow shows improved retrieval diversity on different difficulty levels of retrieval queries on STaRK-MAG.
Analysis and Implications
GraphFlow's reward-factorized approach addresses the credit assignment problem in multi-step KG retrieval without requiring process-level supervision. By leveraging GFlowNet principles and local exploration, GraphFlow achieves both high accuracy and diversity, which are critical for complex queries in real-world applications. The framework is scalable to large, text-rich KGs and generalizes well to new domains.
Theoretically, GraphFlow demonstrates that detailed balance objectives with local exploration can provide effective process supervision in structured retrieval tasks. Practically, the method is applicable to any setting where only terminal rewards are available, and process-level annotation is infeasible.
Limitations and Future Directions
While GraphFlow demonstrates strong empirical performance, its reliance on LLM-based encoders and local exploration may introduce computational overhead for extremely large KGs. The current evaluation focuses on three domains; broader validation across more diverse KGs and query types is warranted. Future work may incorporate causal reasoning, address catastrophic forgetting, and extend the framework to scientific discovery and other knowledge-intensive tasks.
Conclusion
GraphFlow introduces a principled and scalable framework for KG-based RAG, enabling accurate and diverse retrieval from text-rich KGs without explicit process-level supervision. By jointly optimizing a retrieval policy and a flow estimator via detailed balance, GraphFlow aligns retrieval behavior with query-specific knowledge requirements and demonstrates superior performance and generalization on the STaRK benchmark. The approach provides a foundation for further research in integrating generative decision-making with symbolic and textual knowledge sources.

