- The paper introduces fractional bits quantization, progressively reducing model precision from 32 to 4 bits while maintaining high output fidelity.
- It employs curriculum-learning-inspired optimization that smooths transitions between precision levels to minimize performance degradation.
- The method achieves improved on-device deployment efficiency, evidenced by a 16% reduction in FiD scores compared to state-of-the-art techniques.
FraQAT: Quantization Aware Training with Fractional Bits
Introduction
The paper "FraQAT: Quantization Aware Training with Fractional bits" presents an innovative approach to Quantization Aware Training (QAT) by integrating fractional bits in the quantization process. The proposed method is designed to enhance the deployment efficiency of large generative models on resource-constrained devices, such as smartphones. Generative models have achieved remarkable capabilities in tasks like image synthesis and text generation, driven by increasingly large model sizes, which present significant challenges in terms of computational resources and deployment latency. Quantization is a well-established technique to address these constraints by reducing the precision of model parameters, thereby enabling more efficient computations.
Methodology
FraQAT introduces fractional bits quantization, a novel approach that combines the concepts of progressive precision reduction and exploitation of fractional bits during optimization. The core idea is to transition models from high precision (32-bits) to lower precision (4-bits) while utilizing fractional bits to maintain high quality. This approach is inspired by Curriculum Learning, wherein the complexity of the task is gradually increased during training. The methodology is structured around two main components:
- Progressive Precision Reduction: Gradually lowering model parameters' precision from 32 to 4 bits, fine-tuning each intermediate level of precision to ensure stability and retention of model quality.
- Fractional Bits Optimization: Leveraging fractional bits to smooth transitions and maintain output fidelity during training, thereby minimizing performance degradation.
The algorithm follows a schedule that moves through intermediate fractional precision levels, thus facilitating more refined optimization paths and reducing outliers, which are known to disrupt low-precision quantization processes.
Implementation
The implementation of FraQAT involves quantizing linear layers, given their substantial contribution to the parameter count in large models. The process begins with a pre-trained high precision model and follows an optimization schedule that progressively decreases precision while using knowledge distillation to guide the student model to replicate the teacher model's outputs. By empirically targeting models for deployment under W4A8 quantization, FraQAT demonstrates practicality and effectiveness on devices with low-precision hardware support, such as the Qualcomm SM8750-AB Snapdragon 8 Elite Hexagon Tensor Processor.




Figure 1: FraQAT is a Quantization aware Training (QAT) technique granting generative models high fidelity at a reduced training time.
Quantitative and Qualitative Results
The evaluation of FraQAT across several text-to-image models highlights its efficacy in preserving image quality while substantially reducing computational requirements. Notably, FraQAT achieves superior performance compared to existing QAT techniques, demonstrating 16% lower FiD scores than state-of-the-art methods.



Figure 2: FraQAT compared qualitatively with SVDQuant and vanilla QAT demonstrates closer similarities to original model outputs across examined cases.
The paper provides a comprehensive qualitative analysis, showing that FraQAT maintains high fidelity to original model outputs, as evidenced by visual comparisons where FraQAT-generated images closely resemble those from non-quantized models.
Outlier Analysis
(A detailed examination of outlier behavior reveals varying impacts across different model architectures. FraQAT employs a targeted layer optimization strategy to minimize outliers, which otherwise present significant challenges in quantization, due to restricted numeric ranges causing potential activation anomalies. This analysis helps identify optimal layers for quantization and provides strategic insights for resource allocation in mobile deployment scenarios.
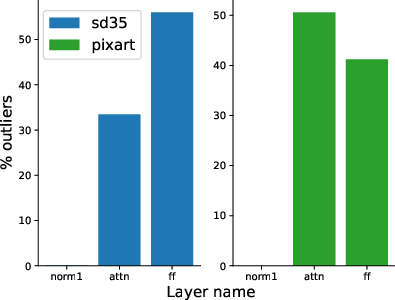
Figure 3: Outliers distribution across models highlighting layer-specific outlier emergence.
On-Device Deployment
FraQAT's deployment on mobile devices illustrates its practical applicability. Quantizing models to W4A8 precision allows seamless execution on mobile NPUs, delivering real-time inferencing capabilities with improved latency in comparison to higher precision alternatives. The deployment of a quantized model on the Samsung S25U demonstrates operational gains with no significant loss in quality.
(Figure 4)
Figure 4: On-device generation showcasing FraQAT's applied results relative to GPU executions.
Conclusion
FraQAT presents a significant advancement in Quantization Aware Training by integrating fractional bits and a progressively adjusting precision strategy, achieving a balance between efficiency and performance preservation. It offers substantial improvements in deploying large generative models on resource-constrained devices while maintaining high-quality outputs. The research opens avenues for further optimization and broader application across different model and precision types, suggesting potential enhancements through regularization and multi-precision support as areas for future exploration. Overall, FraQAT represents a robust step forward in making advanced AI accessible on edge computing platforms.

