- The paper introduces QuantX, a framework that applies hardware-aware post-training quantization to achieve nearly unquantized performance with a 3-bit model resolution.
- It employs a hybrid quantization approach by analyzing weight distribution differences and mitigating outlier impacts to optimize both self-attention and MLP components.
- The framework integrates hardware constraints by supporting efficient kernel usage and numeral formats, ensuring practical deployment on resource-limited devices.
QuantX: A Framework for Hardware-Aware Quantization of Generative AI Workloads
Introduction
QuantX represents a significant stride in the development of quantization frameworks specifically tailored for LLMs and VLMs, addressing the prevalent need for efficient inference on edge and mobile devices where resources are typically constrained. By focusing on post-training quantization, the work aims to achieve highly memory-efficient models without substantial degradation in performance, which is crucial for maintaining functionality in privacy-sensitive applications where local inference is mandated.
QuantX Framework
The QuantX framework introduces a series of quantization techniques informed by empirical observations of weight distribution patterns in LLMs and VLMs. These insights allow for the creation of quantization recipes that consider the probability density functions of weight matrices, the influence of critical outlier weights, and the varying impact of quantization on attention and MLP components of the models.
Understanding PDF Differences:
The framework analyzes variations in the weight distribution across different layers and modules, recognizing that such variations necessitate distinct quantization approaches for optimal model performance.
Figure 1: Normalized histograms of the weight matrix Q from different model components highlight variation in distribution.
Critical Outliers:
The study identifies that non-uniform quantization strategies may not always be superior due to the presence of outliers that induce large quantization errors. This understanding shapes the hybrid quantization strategies in QuantX.
Multi-Criterion Approach:
Beyond Frobenius norm error minimization, QuantX leverages criteria like self-attention output fidelity to guide quantization, ensuring preservation of essential model behaviors even under aggressive bit-width reductions.
Figure 2: Group-specific weight distributions and codebook mapping illustrate quantization strategies and highlight outliers.
Hardware-Aware Constraints
The recognition of hardware limitations informs the design of QuantX, ensuring practical utility of quantized models through compatible deployment strategies. The framework emphasizes adherence to real-world constraints like supported numeral formats and efficient kernel usage to avoid trade-offs that could undermine the advantages gained through quantization.
Results
Performance Outcomes:
QuantX demonstrates its capability to nearly match unquantized model performance with substantially reduced memory footprint, achieving within 6% of the original accuracy for LLMs like LlaVa-v1.6 when condensed to a 3-bit resolution.
Runtime Integration:
The incorporation of QuantX into platforms such as Llama.cpp underscores its practical applicability, showcasing improved token throughput and reduced file sizes compared to pre-existing techniques like Q40 and Q4K.
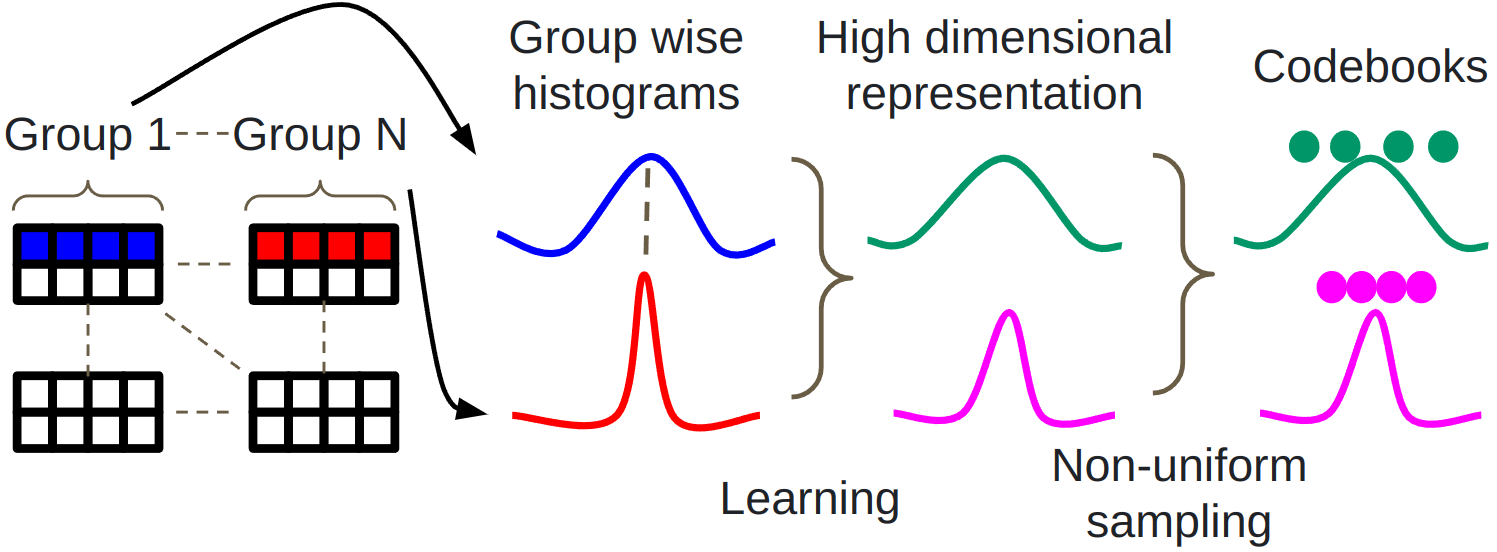
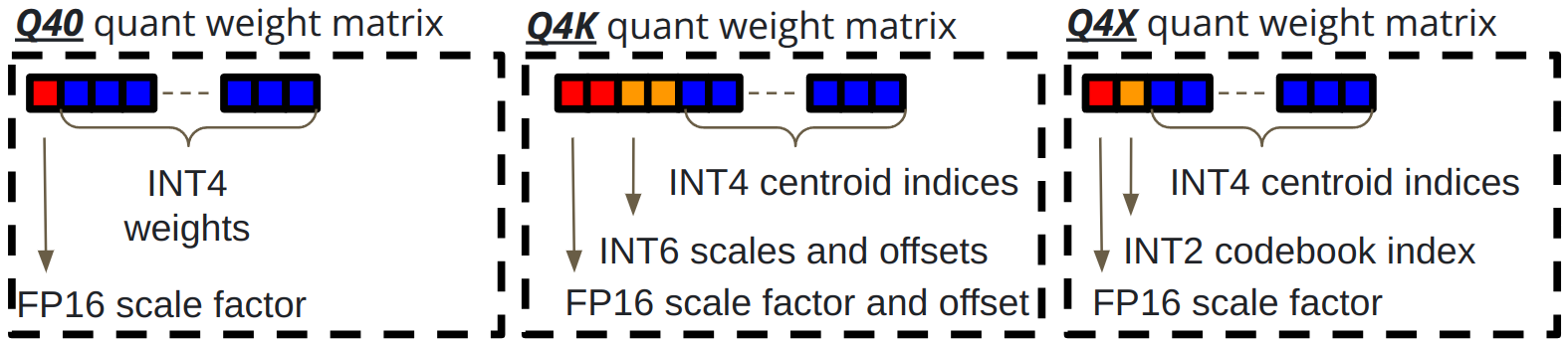
Figure 3: Functional overview of Q4X demonstrating reduction in dimensional overhead via learned histogram coding.
Conclusion
QuantX provides a framework that adeptly balances the competing demands of model fidelity, resource efficiency, and hardware compatibility, significantly enhancing the deployment of generative AI models in constrained environments. Its strategic approach to quantization leverages detailed analytical insights, guiding the design of versatile quantization techniques suitable for a variety of applications. The ongoing evolution of QuantX promises to facilitate further advancements in efficient AI model deployment, particularly as new challenges and hardware capabilities arise.

