- The paper introduces Pervasive Context Management to decouple LLM initialization from execution, achieving up to 72.1% faster inference on static resources.
- It employs the Parsl-TaskVine framework to streamline dynamic resource allocation and reduce startup overhead in heterogeneous GPU clusters.
- The approach stabilizes inference times amid aggressive resource preemption, ensuring efficient throughput for lightweight LLM applications.
Efficient Execution of LLM Inference on GPU Clusters
The paper "Efficiently Executing High-throughput Lightweight LLM Inference Applications on Heterogeneous Opportunistic GPU Clusters with Pervasive Context Management" presents a method to effectively execute high-throughput scientific applications that integrate lightweight LLM inferences within existing HPC clusters. By decoupling LLM context initialization from inference execution, the authors aim to overcome the limitations of conventional static and opportunistic allocation models in dealing with high preemption rates and initialization costs in GPU cluster environments.
Background and Motivation
LLMs are fundamental to the advancement of scientific computing, introducing substantial workloads that include both traditional high-throughput processes and intricate LLM-based inference tasks. Conventional HPC systems, while designed for maximum performance, suffer from extended wait times due to resource contention or frequent resource preemption costs associated with LLM initialization.
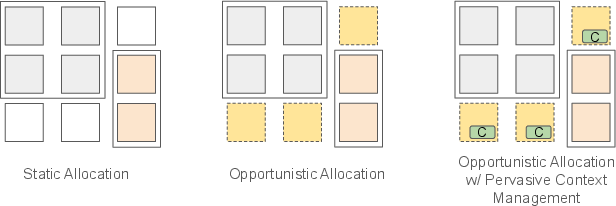
Figure 1: Different resource allocation models illustrating static allocation, opportunistic allocation, and the proposed model with Pervasive Context Management.
The static allocation model necessitates exclusive resource chunks over fixed time periods, which leads to under-utilization due to rigidity. Opportunistic allocation, while flexible, incurs high initialization costs due to the dynamic nature of resource availability, disrupting tasks upon preemption.
Pervasive Context Management
The authors introduce Pervasive Context Management as a key innovation allowing LLM contexts to persist across tasks, rendering the startup costs amortizable. Contexts are retained on GPU nodes across task executions, enabling rapid reallocation upon task preemption without the need for repeated initialization.
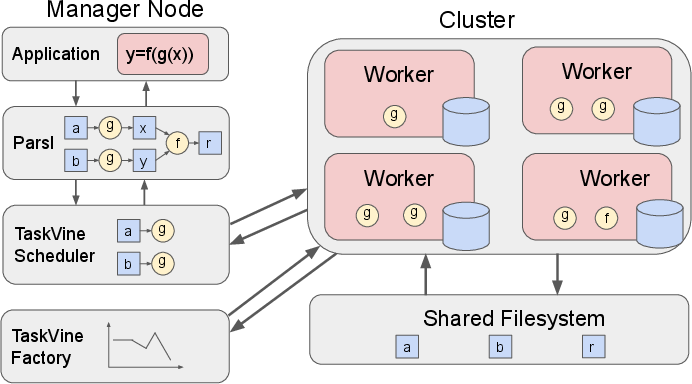
Figure 2: Overview of the Parsl-TaskVine Framework for managing tasks and resources.
Parsl-TaskVine framework functions as the backbone for the proposed optimizations, ensuring efficient scheduling and resource allocation while supporting flexible context management.
Implementation
The transformation of a typical fact verification application to a context-aware model is highlighted. The Process of breaking down inference tasks to separate context initialization from task execution results in reduced overhead and efficient handling of dynamic resources.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from parsl import python_app
def load_model(model_path):
model = AutoModel.from_pretrained(model_path).to('gpu')
return {'model': model}
@python_app
def infer_model(claims, parsl_spec):
model = load_variable_from_serverless('model')
verdicts = [model.generate(claim) for claim in claims]
return verdicts
model_path = ...
claims = ...
parsl_spec = {'context': [load_model, [model_path], {}]}
verdicts = infer_model(claims, parsl_spec).result() |
This separation ensures that context initialization occurs only once per node, significantly reducing the time spent on model loading.
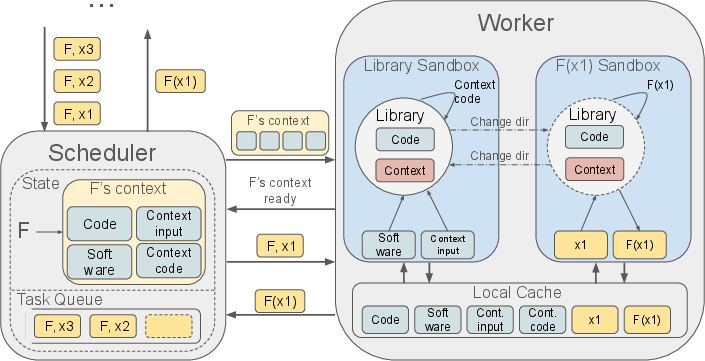
Figure 3: Overview of Pervasive Context Management that supports context retention and task acceleration.
The authors conduct thorough evaluations to demonstrate the effectiveness of Pervasive Context Management. The context-aware application executes significantly faster than its context-agnostic counterpart, with up to 72.1% reduction in execution time when deployed on static resources.
Their experiments also reveal that the approach minimizes the impact of batch size decisions, stabilizing execution time across diverse configurations and simplifying user overhead during configuration.
Moreover, when subjected to aggressive resource preemption, the context-aware application maintains a smoother goodput curve and completes more inferences, showcasing its resilience and efficiency under dynamic resource conditions.
Practical Implications
The research presented illustrates a powerful strategy for deploying LLM-based applications on heterogeneous GPU clusters efficiently. This technique enhances resource utilization and reduces the impact of resource volatility on execution time, offering substantial gains in environments with fluctuating resource availability.
The insights gained from this study can profoundly influence the design and deployment of HPC systems, positioning them to handle emergent AI workloads effectively. Future developments may focus on overcoming the current limitations, such as addressing larger-scale LLMs beyond single node capacities and optimizing the context management overhead.
Conclusion
The integration of Pervasive Context Management within existing HPC frameworks signifies a substantial shift toward efficient AI workload management on GPU clusters. By decoupling context initialization from task execution, the research ensures high throughput and adaptability in environments characterized by resource heterogeneity and rapid changes in availability. The approach establishes a blueprint for future studies aiming to optimize LLM inference tasks in HPC settings.

