- The paper demonstrates that causal graphs are uniquely identifiable using data from two distinct environments, resolving ambiguities in traditional i.i.d. observational methods.
- The method exploits differences in Gaussian noise across environments and applies nonlinear ICA principles to reduce the number of required interventions.
- The proposed algorithm approximates Jacobian supports through gradient and Hessian estimations, with synthetic experiments validating its effectiveness for causal discovery.
Causal Graph Identifiability with Multiple Environments
Introduction
The paper "On the identifiability of causal graphs with multiple environments" investigates the identifiability of causal graphs using data from several environments. Causal discovery from i.i.d. observational data is generally considered an ill-posed problem, as different directed acyclic graphs (DAGs) can be indistinguishable from the data distribution. This work demonstrates that if a structural causal model (SCM) distribution and data from two environments with distinct noise statistics are available, the unique causal graph becomes identifiable. This is significant because it guarantees entire causal graph recovery with a constant number of environments and arbitrary nonlinear mechanisms, subject to the Gaussianity of the noise terms.
Theory and Methodology
The key theoretical contribution of this work is the identifiability of causal graphs using only two auxiliary environments. The environments are characterized by their noise distributions, which must differ sufficiently. This result contrasts previous interventional methods, where the number of required interventions scales logarithmically with the number of nodes in the graph.
- Nonlinear ICA and Causal Discovery: The paper explores the duality between nonlinear independent component analysis (ICA) and causal discovery. While nonlinear ICA typically requires as many environments as the number of sources to guarantee identifiability, this research shows that identifying a causal graph requires fewer environments due to its simpler structure-learning nature.
- Assumptions and Relaxations: The primary condition is the Gaussian noise assumption, but the authors propose methods to relax this. Their approach indicates that under more general assumptions, the data from two environments can still assure identifiability.
Empirical Validation
The empirical section contains synthetic experiments validating the theoretical claims. Bivariate models demonstrate that when the assumptions hold, including the distinctness of environment noise structures, causal directions can be correctly inferred.
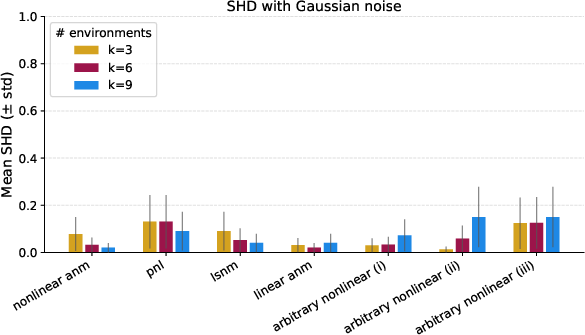
Figure 1: Average SHD (0 is best, 1 is worst) achieved by \cref{alg:jacobian_support_sketch.
Algorithm
The authors propose a practical algorithm for approximating the support of the Jacobian of the inverse mixing function from data. This algorithm involves:
- Estimating gradients and Hessians of the log-likelihood in each environment.
- Identifying the samples corresponding to the mean source vector.
- Constructing difference matrices for Hessians across environments to estimate the causal graph.
The method effectively identifies DAGs when environment noise statistics differ significantly. However, the reliance on Gaussianity and the assumption of known or easily identifiable interventional effects are potential limitations.
Practical Implications and Future Work
This research shows promise in reducing the complexity and data requirements of identifying causal relationships in observational studies. It encourages further exploration into relaxing the Gaussianity assumption and developing scalable algorithms for high-dimensional data. Future work may also focus on adapting these methods to data with unknown or partially known noise structures.
Conclusion
The study affirms that utilizing multiple environments enhances the identifiability of causal graphs. The theoretical grounding, supported by synthetic data experiments, offers a compelling advancement in causal discovery methodologies, suggesting significant applications across various scientific fields where controlled experimentation is infeasible.