Detect Anything via Next Point Prediction
Abstract: Object detection has long been dominated by traditional coordinate regression-based models, such as YOLO, DETR, and Grounding DINO. Although recent efforts have attempted to leverage MLLMs to tackle this task, they face challenges like low recall rate, duplicate predictions, coordinate misalignment, etc. In this work, we bridge this gap and propose Rex-Omni, a 3B-scale MLLM that achieves state-of-the-art object perception performance. On benchmarks like COCO and LVIS, Rex-Omni attains performance comparable to or exceeding regression-based models (e.g., DINO, Grounding DINO) in a zero-shot setting. This is enabled by three key designs: 1) Task Formulation: we use special tokens to represent quantized coordinates from 0 to 999, reducing the model's learning difficulty and improving token efficiency for coordinate prediction; 2) Data Engines: we construct multiple data engines to generate high-quality grounding, referring, and pointing data, providing semantically rich supervision for training; \3) Training Pipelines: we employ a two-stage training process, combining supervised fine-tuning on 22 million data with GRPO-based reinforcement post-training. This RL post-training leverages geometry-aware rewards to effectively bridge the discrete-to-continuous coordinate prediction gap, improve box accuracy, and mitigate undesirable behaviors like duplicate predictions that stem from the teacher-guided nature of the initial SFT stage. Beyond conventional detection, Rex-Omni's inherent language understanding enables versatile capabilities such as object referring, pointing, visual prompting, GUI grounding, spatial referring, OCR and key-pointing, all systematically evaluated on dedicated benchmarks. We believe that Rex-Omni paves the way for more versatile and language-aware visual perception systems.











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Rex-Omni, a smart AI model that can “find things” in images using both vision and language. Its big idea is to detect objects by predicting their next point or box on the image, instead of using traditional methods. Rex-Omni is designed to understand detailed language (like “the red apple on the left”) and then precisely mark where those objects are, all in one system.
Objectives
The paper aims to answer these simple questions:
- How can we build an AI that understands complex language and also pinpoints object locations accurately in images?
- Can a language-driven model match or beat traditional object detectors (like YOLO or DETR) on standard tests without being explicitly trained on them?
- How do we fix common problems in language-based detectors, like missing objects, repeating predictions, or slightly “off” coordinates?
Methods
To make this work, the authors combine three main ideas. Think of it like training a coachable robot to use a map, follow instructions, and learn from feedback.
Task Formulation (How the model “speaks” coordinates)
Instead of making the model guess exact pixel numbers, coordinates are turned into 1,000 special “tokens” (from 0 to 999). You can imagine the image as a grid labeled 0–999 in each direction. The model learns to output these tokens to mark:
- Points (for clicking or pointing)
- Boxes (two points make the top-left and bottom-right corners)
- Polygons (multiple points to outline shapes, like text)
- Keypoints (specific parts of an object, like eyes or joints)
Using these tokens:
- Makes learning easier (it’s like choosing from 1,000 grid positions instead of any possible pixel number).
- Speeds up predictions (fewer symbols to generate per coordinate).
Data Engines (Where the training examples come from)
Rex-Omni learns from a huge collection of images (22 million examples). The team built special “data engines” to create high-quality training pairs:
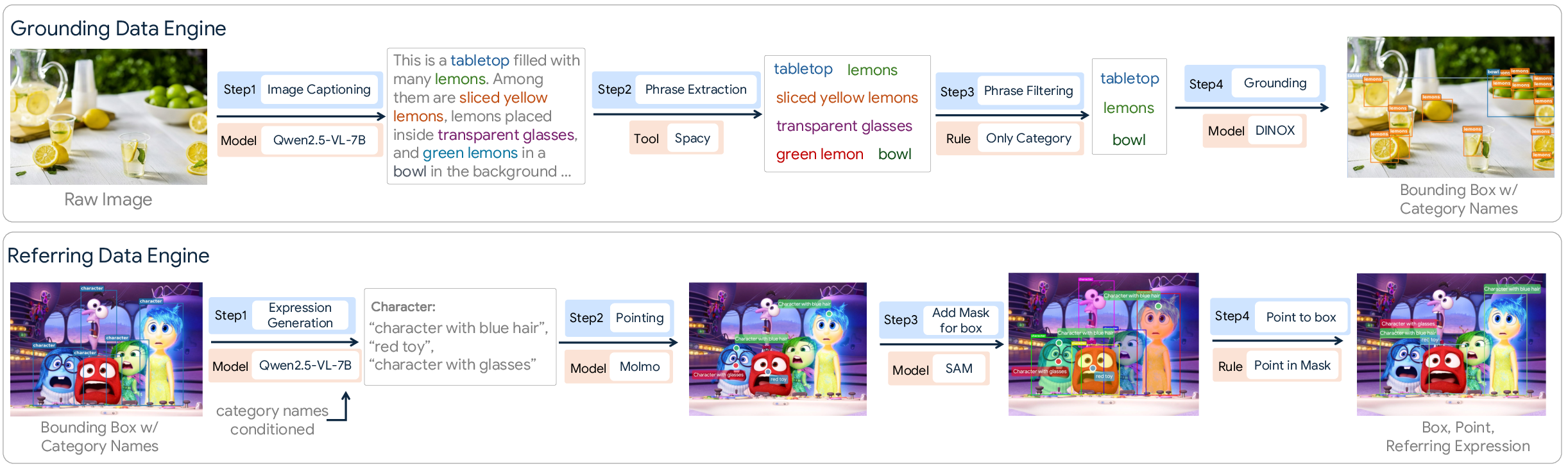
- Grounding engine: Write captions for an image, extract object phrases (like “lemon”), filter out tricky phrases (“green lemon” can cause errors), and then match phrases to boxes using a strong detector.
- Referring engine: Create natural descriptions (“the man in a yellow shirt”), predict a point for the description, and link that point to the right object box/mask.
- Pointing engine: Convert boxes into single representative points inside the object.
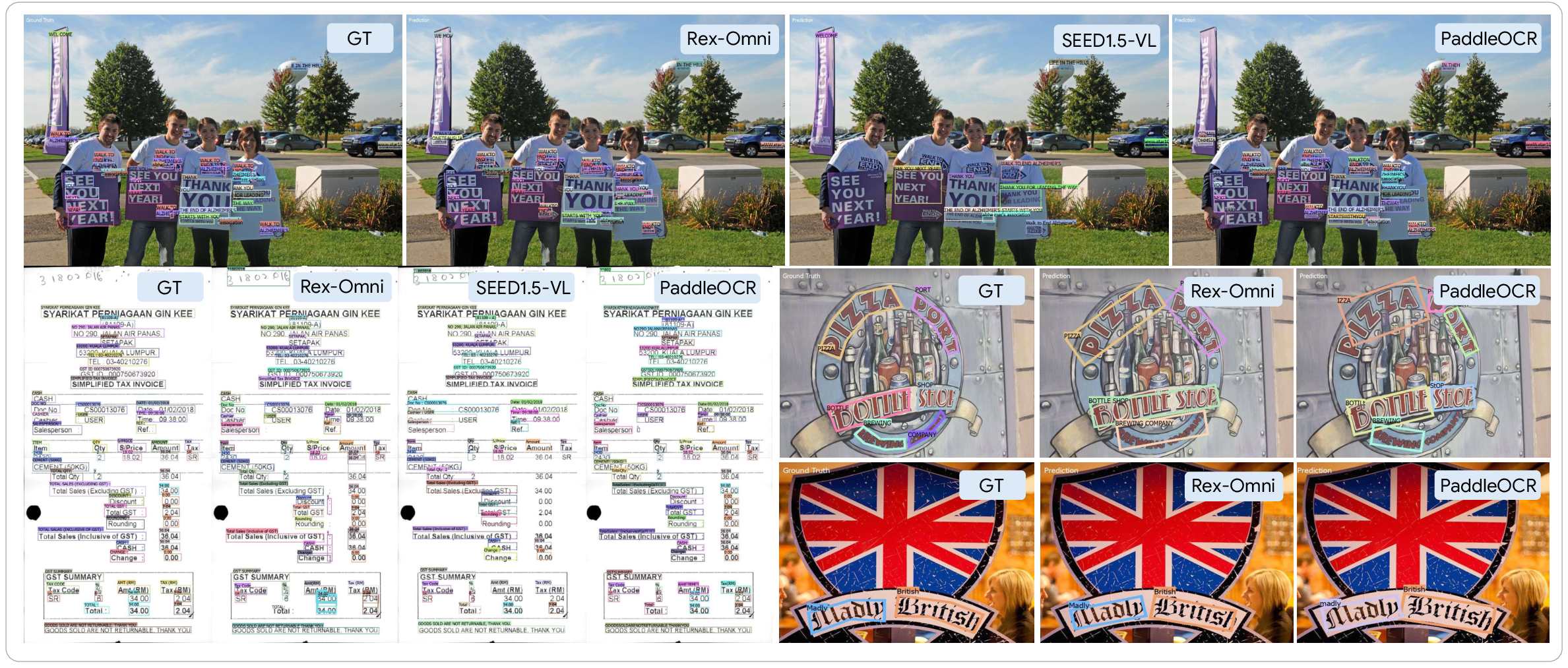
- OCR engine: Find text in images and outline it with polygons and boxes for training.
These engines give the model lots of examples to learn complex language and accurate locations.
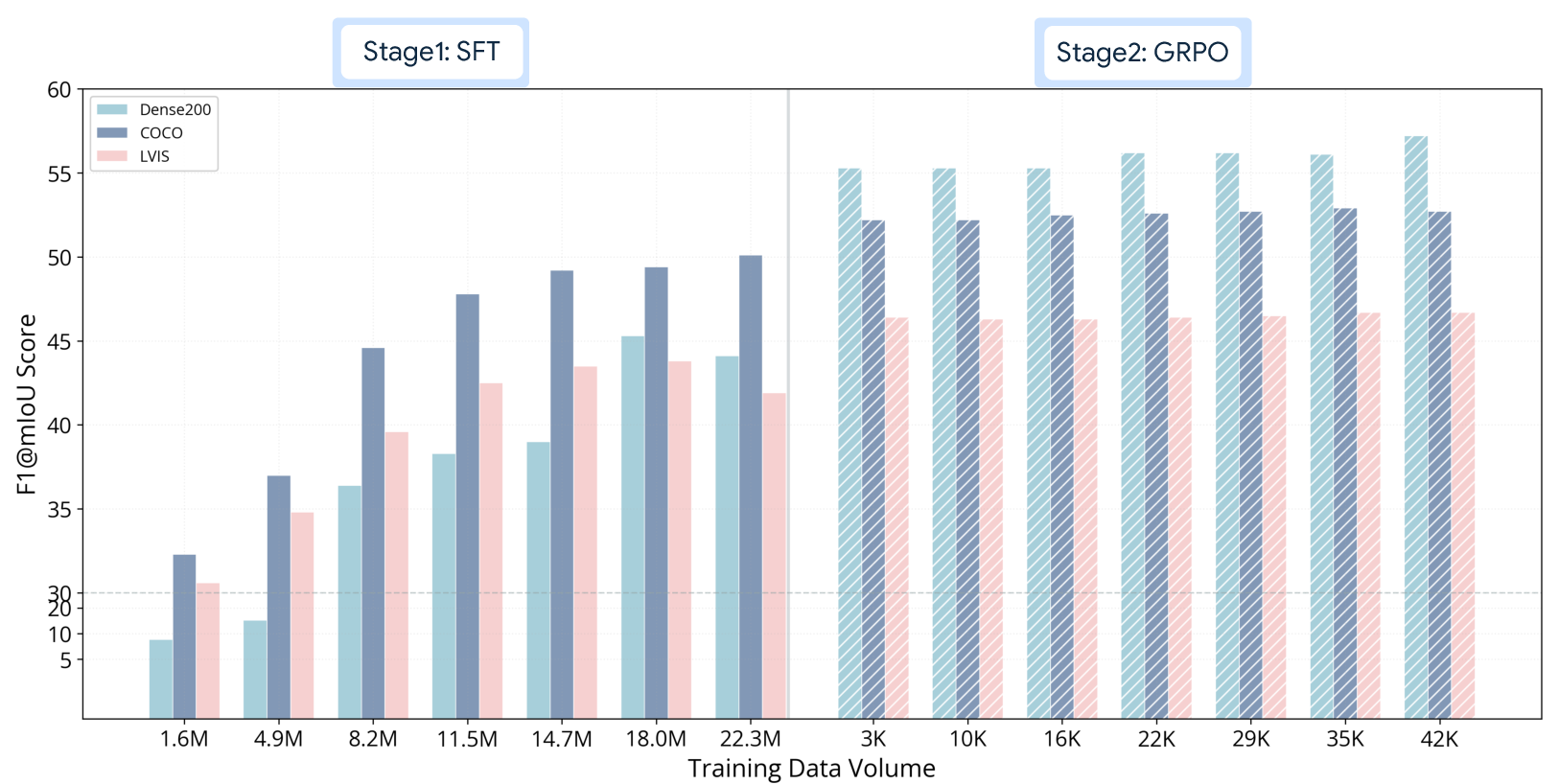
Training Pipeline (How the model learns in two stages)
Rex-Omni trains in two steps:
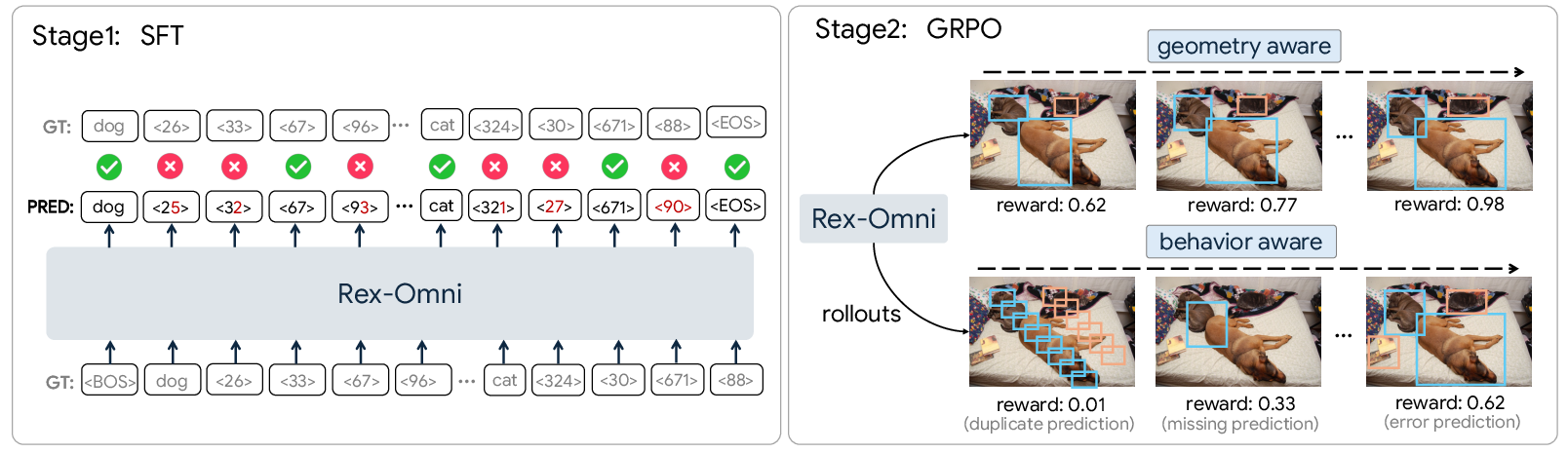
- Stage 1: Supervised Fine-Tuning (SFT) The model practices on labeled examples, learning to map coordinate tokens to real image positions. This is like a student copying from a solution sheet to learn the basics.
Problem: During SFT, the model always sees the “correct previous answer” while generating the next token (called “teacher forcing”). So at test time, when it must produce everything on its own, it can make mistakes like repeating boxes or missing objects.
- Stage 2: Reinforcement Learning (GRPO)
- High reward if predicted boxes overlap well with the true box (IoU).
- Reward if the clicked point lies inside the true object mask or box.
- Penalties for duplicates or wrong categories.
This is like giving the student a chance to solve problems alone and then grading them based on how close they are to the correct location, not just whether they typed the exact token.
Main Findings
Rex-Omni shows strong results:
- On standard object detection tests like COCO and LVIS, it matches or beats well-known detectors (e.g., Grounding DINO) without being trained directly on those datasets (“zero-shot”).
- It fixes typical language-model problems:
- Fewer missed objects (higher recall).
- Fewer duplicate boxes.
- More accurate coordinates (better localization).
- It’s versatile: the same model handles many tasks by predicting points or boxes, including object detection, referring expressions, visual prompting (find more things like this example box), GUI elements grounding (like clicking a button), spatial referring, OCR (reading text), and keypoint detection.
Why this matters: Traditional detectors are great at precise boxes but often weak at understanding complicated language. Rex-Omni brings strong language understanding together with precise detection, opening up new ways to interact with images using natural instructions.
Implications
This research suggests that the next generation of visual AI can be language-aware and still highly accurate at locating objects. By turning coordinates into simple tokens and training the model with geometry-aware feedback, Rex-Omni:
- Makes it easier for people to ask complex, natural questions about images and get precise answers.
- Unifies many vision tasks under one framework (just predict points/boxes/polygons).
- Could help in real-world applications like robotics (point to the handle), UI automation (click the “Submit” button), document understanding (find the title and tables), and assistive technology (identify objects by description).
In short, Rex-Omni shows that AI models that “talk” and “see” can become reliable detectors by learning to predict the next point—cleverly and carefully.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable.
- Coordinate quantization design: No ablation or justification for choosing 1,000 bins for relative coordinates; the impact of bin count on localization accuracy, small-object performance, dense scenes, and decoding speed remains unquantified. Evaluate adaptive binning, image-size-aware scaling, or multi-scale quantization.
- Token repurposing effects: The last 1,000 vocabulary tokens are reassigned as coordinate tokens, but the impact on language understanding, rare-token semantics, and general text tasks is not measured. Assess degradation in non-vision tasks and interactions with the original BPE/token distribution.
- De-quantization details: The paper does not specify how quantized relative tokens are mapped back to pixel coordinates across varying resolutions, aspect ratios, and cropping/scaling pipelines. Provide the exact normalization, rounding, and rescaling formulas and quantify induced geometric error.
- Confidence scoring and standard detection metrics: Outputs are unscored token sequences; comparisons emphasize F1, not mAP (AP@[IoU]), complicating parity with detector baselines. Introduce confidence tokens or score heads and report mAP to enable standard, fair comparisons.
- Output regulation and termination: The decoding protocol for deciding how many boxes/points to generate and when to stop (beyond
<box_end>) is unspecified. Investigate termination strategies, length penalties, or constrained decoding to ensure complete-but-nonredundant outputs. - Ordering and structural validity: Boxes are “sorted by x0,” but enforcement and consistency under autoregressive decoding are unclear. Add constrained decoding/grammars to ensure
x0 < x1,y0 < y1, non-self-intersecting polygons, and valid JSON for keypoints. - Duplicate and missed detections: RL post-training aims to mitigate duplicates and omissions, but a quantitative breakdown of error modes before/after RL is absent. Provide diagnostics on over-/under-generation, per-category duplication rates, and recall/precision shifts.
- RL reward dependencies and bias: Geometry-aware rewards rely on SAM masks (point-in-mask) and detector outputs (data engines), potentially propagating external model errors. Analyze sensitivity to SAM/DINO failures and compare against GT masks/boxes where available.
- GRPO configuration and scale: RL uses only ~66K samples, rollout size 8, β=0.01, trained for ~24 hours, but no ablations examine data size, rollout count, β, or reward shaping (e.g., IoU thresholds, L1/GIoU). Study stability, sample efficiency, and generalization under varied RL settings.
- Attribute-rich referring expressions: The grounding engine filters out adjective-modified phrases (e.g., “green lemon”), reducing semantic richness. This contradicts the goal of nuanced language grounding. Build clean, attribute-specific referring sets and measure performance on attributes, colors, states, and counts.
- Visual prompting category inference: The model is instructed to detect “same category” as prompted boxes without explicit labels, but no evaluation probes if the inferred category is consistent or drifts (e.g., subcategories). Create tests for category consistency under visual-only prompts.
- Small-object and thin-structure localization: Quantization to 0–999 relative bins may under-resolve very small or thin objects (e.g., wires, text glyphs). Quantify error versus object size and investigate higher-resolution grids or local refinement modules.
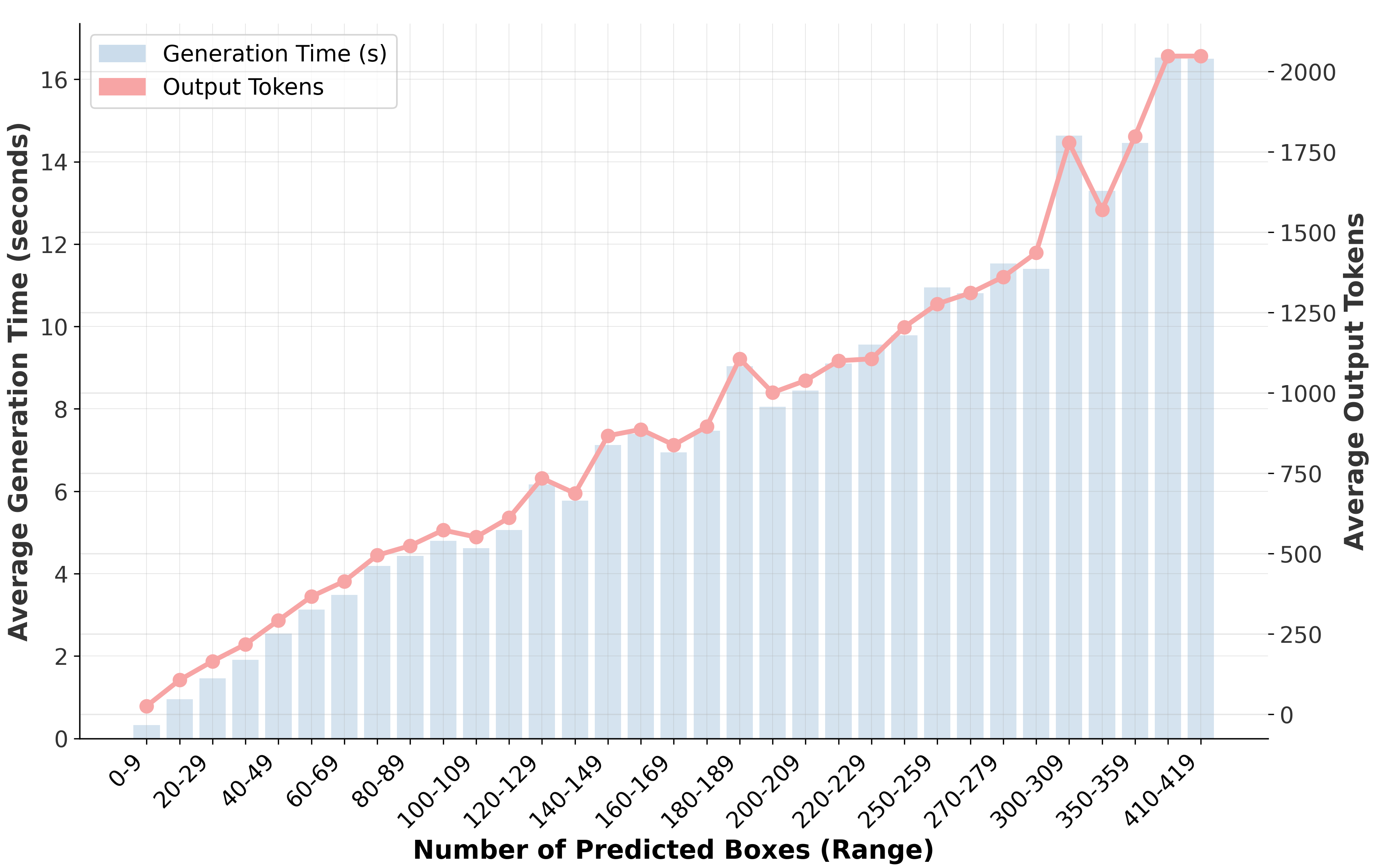
- Inference efficiency: Claims of token efficiency are not backed by latency/throughput comparisons versus detectors and other MLLMs across sparse and dense scenes. Report decode speed, GPU memory, and throughput under varied object densities.
- Robust language understanding for perception: No systematic evaluation of complex linguistic phenomena (negation, quantifiers, compositional attributes, spatial relations like “left of,” ordinal constraints like “the second…,” or counting). Develop a standardized suite and error taxonomy for language-conditioned detection.
- Domain generalization: Training/evaluation focus on common web/vision datasets; performance in specialized domains (medical, industrial, aerial beyond FAIR-1M, indoor robotics) is unknown. Conduct cross-domain tests and report failures and adaptation strategies.
- Multilingual prompts: The system’s behavior under non-English prompts is not tested; multilingual grounding robustness and tokenization interactions are unexamined. Evaluate multilingual performance and consider multilingual data engines.
- Video and temporal grounding: The approach is image-only; extensions to video detection/tracking, temporal consistency, and exposure-bias over sequences are unaddressed. Propose temporal decoding constraints and rewards (e.g., track coherence).
- Box-category linkage: The decoding protocol for associating phrases (
PHRASE) with specific boxes/points is not detailed for multi-phrase queries (e.g., conflicting categories, overlapping regions). Clarify alignment and add mechanisms to avoid cross-category leakage. - Evaluation against alternative MLLM paradigms: The paper motivates direct coordinate prediction but lacks head-to-head ablations vs retrieval-based and external-decoder strategies under controlled data/training budgets. Provide comparative studies isolating trade-offs in accuracy, speed, and robustness.
- Data engine noise and quality: Automatically generated grounding/referring/OCR annotations likely contain non-trivial noise; the paper does not quantify error rates or downstream impact. Measure label noise, implement robust training (e.g., noise-aware losses), and report gains from cleaner subsets.
- OCR polygons and rotated text: The OCR engine reduces polygons to axis-aligned boxes, which can misrepresent rotated/curved text. Evaluate polygon fidelity and add rotated box decoding or direct mask outputs; report end-to-end OCR metrics (detection+recognition).
- Safety and misuse in GUI grounding: No discussion of safety risks (e.g., automating clicks on sensitive UI elements) or guardrails. Define safe action policies, UI element whitelists/blacklists, and evaluate failure modes.
- Scaling laws and model size: The core claims are on a 3B model; effects of scaling down (resource-constrained) or up (7B/13B) are not studied. Conduct scaling law analyses to understand returns on model size for localization vs language conditioning.
- Training image resolution policy: The vision encoder token budget (16–2560 tokens, patch size 28) is fixed, but impacts of resolution choices on quantization fidelity and small-object detection are not analyzed. Ablate input resolution, patch size, and token budget.
- Termination semantics for “None”: When a phrase has no referent, the paper mandates returning
None, but training/inference mechanisms for reliably producingNoneand avoiding hallucinations are not described. Add explicit “no-object” supervision and calibration strategies.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s model (Rex-Omni), task formulation (quantized coordinate tokens), data engines, and GRPO-based reinforcement post-training. Each item lists sectors, potential tools/workflows, and key assumptions/dependencies.
- Open-vocabulary image detection APIs
- Sectors: software, e-commerce, media, security
- What to deploy: A phrase-driven “detect anything” microservice that returns [x0, y0, x1, y1] boxes from natural-language prompts (e.g., “red helmet, forklift, spill”). Supports multi-phrase queries and visual prompts.
- Tools/workflows: REST/GraphQL inference server; SDKs for Python/JS; integration in digital asset management systems; batch pipelines for photo libraries.
- Assumptions/dependencies: Availability of Rex-Omni weights and licensing; domain shift may require light adaptation; image preprocessing must maintain consistent relative coordinate scaling (0–999 tokenization).
- Visual search and product tagging
- Sectors: retail, e-commerce, advertising
- What to deploy: Product discovery by natural language (“striped tote with leather handle”) and open-vocabulary tagging of catalog and UGC images.
- Tools/workflows: Tagging pipeline with deduplication (leveraging GRPO-tuned behavior to reduce duplicates); SKU suggestion UI using visual prompts (few provided boxes to find visually similar items).
- Assumptions/dependencies: Long-tail robustness depends on training coverage; human-in-the-loop recommended for brand-critical tags.
- Retail shelf analytics and planogram compliance
- Sectors: retail, CPG
- What to deploy: Open-set detection of facings, out-of-stock, misplaced items; visual prompting to scale to rare SKUs without retraining.
- Tools/workflows: Store audit app; dashboard with trend analytics; exception alerts.
- Assumptions/dependencies: Camera placement/angles; varied packaging; may need store-specific calibration; privacy compliance for in-store capture.
- Document OCR and layout grounding
- Sectors: finance, insurance, government, healthcare admin
- What to deploy: Unified OCR + layout detection (tables, headers, stamps) with polygon/box outputs for form understanding and receipt processing.
- Tools/workflows: Document intake pipeline; form-field extraction; RPA handoff to downstream systems.
- Assumptions/dependencies: Multilingual text quality depends on training distribution; ensure resolution scaling is preserved; sensitive-data handling.
- GUI grounding for QA automation and RPA
- Sectors: software, fintech ops, enterprise IT
- What to deploy: Natural-language targeting of clickable UI elements (point-in-box reward) for robust test scripts and robotic process automation.
- Tools/workflows: Selenium/Appium plugins that take phrases (“click ‘Export as CSV’ button”) and use coordinates; screenshot-based validation.
- Assumptions/dependencies: Stable screenshot-to-device coordinate mapping; theming, localization, and dynamic DOM changes may require fallbacks.
- Accessibility assistants (vision and desktop)
- Sectors: assistive tech, consumer software
- What to deploy: Voice-driven object finding in camera feed (“point to the nearest exit sign”); screen element grounding in screenshots for non-visual navigation.
- Tools/workflows: Mobile app or desktop overlay that announces detected objects and provides pointing cues; continuous mode with low-latency inference.
- Assumptions/dependencies: On-device or near-edge inference for latency; careful UX for error recovery; privacy-by-design.
- Video analytics (frame-by-frame phrase detectors)
- Sectors: security, manufacturing, sports analytics, logistics
- What to deploy: Zero-shot phrase queries over video streams (e.g., “safety harness not worn”, “pallet jack near dock door”).
- Tools/workflows: Streaming inference nodes with batched frames; deduplication using RL-trained behavior controls; alerting and VMS integration.
- Assumptions/dependencies: Throughput scaling; temporal association across frames requires simple tracking module; camera placement and lighting variability.
- Aerial and drone imagery detection
- Sectors: logistics, agriculture, energy, public works
- What to deploy: Detect objects in aerial views (DOTA/VisDrone-like) for infrastructure inspection, crop monitoring, inventory counts.
- Tools/workflows: Drone survey pipeline; offline batch detection; GIS export.
- Assumptions/dependencies: Domain adaptation for altitude/sensor differences; georeferencing to map coordinates from image space.
- Quality inspection and keypoint-based checks
- Sectors: manufacturing, automotive
- What to deploy: Keypointing + box-based checks for alignment, presence/absence of parts, and pose consistency.
- Tools/workflows: Station cameras; pass/fail rules based on keypoint geometry; audit logs with visual overlays.
- Assumptions/dependencies: Controlled lighting; calibrated setups; handling reflective/transparent parts may need tuned prompts or few-shot visual prompts.
- Dataset labeling acceleration with automated data engines
- Sectors: academia, ML platform providers, in-house MLOps
- What to deploy: Use the paper’s grounding/referring/pointing/OCR engines (captioning + phrase extraction + filtering + open-vocab grounding + SAM association) to auto-label images at scale, then review.
- Tools/workflows: Labeling studio integration; phrase filtering to reduce ambiguity; semi-automatic referring expression generation.
- Assumptions/dependencies: Access to SAM, open-vocabulary detectors, and LLMs (Qwen2.5-VL or similar) for captioning; QA to manage noise.
- Media moderation and safety scanning
- Sectors: online platforms, content moderation
- What to deploy: Open-vocabulary detection for policy entities (e.g., weapons, drug paraphernalia) with phrase lists curated by policy teams.
- Tools/workflows: Moderation pipeline with explainability (referring phrases + boxes); audit trails.
- Assumptions/dependencies: False positives/negatives must be tuned; jurisdiction-specific policies; route edge cases to human review.
- Edge-friendly perception services
- Sectors: IoT, robotics, mobile apps
- What to deploy: 3B-parameter model for on-device or low-power edge GPUs to handle phrase-based perception locally.
- Tools/workflows: Quantized inference; streaming input; fallback to cloud for heavy workloads.
- Assumptions/dependencies: Device RAM/VRAM; acceptable accuracy-speed trade-offs; energy constraints.
Long-Term Applications
The following opportunities will benefit from additional research, scaling, evaluation, or productization. They build on the paper’s innovations (coordinate tokenization, RL with geometry-aware rewards, unified coordinate generation across tasks).
- Safety-critical perception (autonomous driving, robotics at scale)
- Sectors: automotive, warehouse robotics, last-mile delivery
- Vision: Open-vocabulary perception with natural-language conditioning for rare hazards and long-tail objects.
- Dependencies: Rigorous validation, real-time guarantees, redundancy with conventional stacks, regulatory certification, domain-specific training.
- Embodied assistants with spatial referring and affordance grounding
- Sectors: home robotics, elder care, warehouse AI
- Vision: Voice instructions like “pick up the blue mug to the left of the kettle,” using pointing/box/polygon outputs to drive grasping policies.
- Dependencies: Closed-loop control, depth sensing, grasp planners, safety constraints, continual learning to handle household diversity.
- Generalist GUI agents for end-to-end computer control
- Sectors: enterprise RPA, personal productivity
- Vision: Language-conditioned GUI grounding enabling robust agents to operate apps across OSes with minimal DOM access.
- Dependencies: Temporal memory of UI states, secure action sandboxes, recovery strategies, large-scale evaluation suites for reliability.
- AR-assisted navigation and teaching
- Sectors: education, accessibility, field services
- Vision: AR overlays that point to relevant objects or steps (“tighten the left valve”) and adapt to complex environments with language grounding.
- Dependencies: On-device latency, stable pose tracking, user safety; strong domain prompts for tasks.
- Universal document intelligence and structured data extraction
- Sectors: finance, legal, healthcare, logistics
- Vision: Unified OCR + layout + keypoint extraction for any form/spec with natural-language instructions (e.g., “find net premium, policy ID”).
- Dependencies: Multilingual coverage, handwriting, stamps/seals; compliance, traceability; domain adaptation.
- Inventory and supply-chain automation with drones and mobile robots
- Sectors: logistics, retail, manufacturing
- Vision: Open-set counts, anomaly detection, aisle navigation, and long-tail SKU discovery without bespoke retraining.
- Dependencies: Mapping, SLAM, safety constraints, operational change management, environmental variability.
- Healthcare imaging assistance (non-diagnostic at first)
- Sectors: healthcare
- Vision: Language-driven localization of instruments, anatomy landmarks, lines/tubes in OR/ICU; later, domain-specific lesion detection.
- Dependencies: Clinical validation, safety and bias audits, FDA/CE approvals, domain-specific training and prompt engineering.
- Sustainable cities and environmental monitoring
- Sectors: public sector, NGOs, energy
- Vision: Open-vocabulary monitoring of traffic behaviors, wildlife counts, infrastructure conditions using phrase queries.
- Dependencies: Privacy safeguards, ethical use policy; domain calibration; citizen oversight and auditability.
- Federated and privacy-preserving continual learning loops
- Sectors: mobile, enterprise
- Vision: On-device inference with local fine-tuning and RL reward shaping (geometry-aware) aggregated via federated learning.
- Dependencies: Efficient on-device training, privacy guarantees, robust reward specification and drift control.
- Standardization of coordinate-token interfaces for MLLMs
- Sectors: AI tooling, model hubs
- Vision: An interoperable “coord token” spec (0–999) to enable plug-and-play perception heads across MLLMs and tools.
- Dependencies: Community consensus, benchmarks measuring discrete-to-continuous fidelity, open tooling.
- RL post-training framework for structured outputs beyond boxes
- Sectors: AI research, document AI, geospatial, CAD/BIM
- Vision: GRPO-style geometry-aware rewards for polygons, keypoints, tables, graphs, and layout trees to improve structural accuracy.
- Dependencies: Task-specific reward design, stable training recipes, unified evaluation metrics and leaderboards.
- Insurance and claims automation
- Sectors: insurance, automotive
- Vision: Damage localization, part identification, and cost estimation assistance via open-vocabulary detection and keypointing.
- Dependencies: Domain datasets, calibration to diverse vehicle models/materials; human oversight; regulatory constraints.
Notes on Cross-Cutting Assumptions and Dependencies
- Model availability and licensing: Production use assumes accessible model weights or commercial licenses for Rex-Omni (or comparable MLLMs) and any third-party components (e.g., SAM, PaddleOCR, Qwen2.5-VL).
- Performance under domain shift: Some applications will require light fine-tuning or prompt/visual-prompt adaptation for new domains, conditions, or sensor modalities.
- Resolution and coordinate scaling: Because outputs are relative coordinates quantized to 0–999, preprocessing must preserve aspect ratio and apply consistent mapping between image and UI/screen coordinates.
- Reliability and behavior control: While GRPO mitigates duplicates and misalignment, mission-critical deployments need additional safeguards (post-processing, consensus, multi-model cross-checking).
- Privacy and compliance: Applications in public spaces, healthcare, finance, and workplaces must implement privacy-by-design, secure data handling, and comply with relevant regulations.
- Human-in-the-loop: For high-stakes or brand-sensitive use cases, human review remains important, especially during early deployment phases.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper that may be unfamiliar to an undergraduate computer science student.
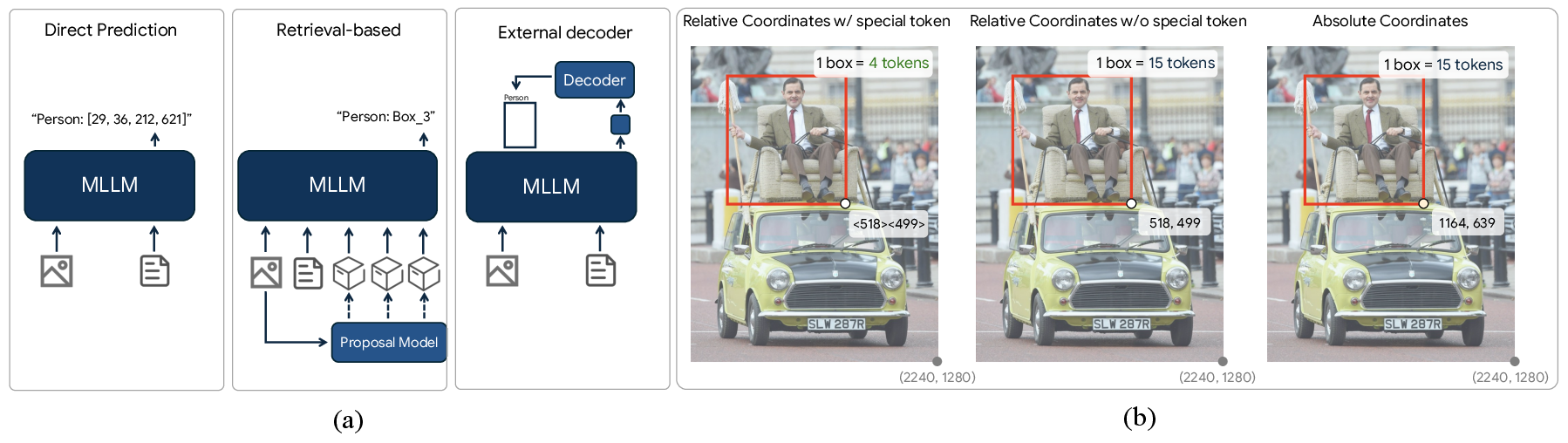
- Absolute coordinates: Coordinate values expressed in the image’s pixel space rather than normalized or relative values. "3) Absolute coordinates: This method uses absolute coordinates, where a coordinate value such as 1921 is tokenized into individual digits (1, 9, 2, 1)."
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability and generalization. "Optimization is performed using the AdamW~\cite{loshchilov2017adamw} optimizer"
- Affordance Grounding: Grounding visual elements to actionable or interactive possibilities (e.g., where to click or grasp) via points or boxes. "including object detection, object referring, visual prompting, OCR, layout grounding, GUI grounding, pointing, affordance grounding, spatial referring, and keypointing."
- Box IoU Reward: A reinforcement learning reward based on Intersection over Union (IoU) between predicted and ground-truth boxes. "Box IoU Reward. This reward is applied to tasks requiring bounding box predictions, including object detection, grounding, referring, and OCR."
- Cross-entropy loss: A classification loss that measures the difference between predicted probability distributions and true labels. "relying on cross-entropy loss for supervision."
- Dense object detection: Detection scenarios with many small or closely packed objects in an image. "such as long-tailed detection, referring expression comprehension, dense object detection, GUI grounding, and OCR."
- F1-score: The harmonic mean of precision and recall, measuring balance between them. "In a zero-shot setting (without training on COCO data), Rex-Omni demonstrates superior F1-score performance compared to traditional coordinate regression-based models"
- Generalized IoU (GIoU): An extension of IoU that considers overlap and the smallest enclosing box to better penalize misaligned predictions. "geometry-aware losses (e.g., L1, GIoU) that are directly sensitive to small geometric offsets"
- GRPO (Group Relative Preference Optimization): A reinforcement learning framework that optimizes model outputs using group-relative advantages and KL regularization. "combining supervised fine-tuning on 22 million data with GRPO-based reinforcement post-training."
- GUI Grounding: Grounding language or actions to specific graphical user interface elements via bounding boxes or points. "such as long-tailed detection, referring expression comprehension, dense object detection, GUI grounding, and OCR."
- Intersection over Union (IoU): A metric measuring the overlap ratio between predicted and ground-truth regions. "we find the predicted box \hat{b}_i that maximizes the IoU with b*_j"
- KL regularization: A penalty term using Kullback–Leibler divergence to prevent the learned policy from drifting too far from a reference model. "The GRPO objective is formulated as a clipped policy gradient with KL regularization:"
- Layout Grounding: Grounding document layout elements (e.g., tables, paragraphs) within images. "OCR, Layout Grounding, GUI Grounding"
- Long-tailed detection: Detection under class imbalance where many categories have few samples. "such as long-tailed detection, referring expression comprehension, dense object detection, GUI grounding, and OCR."
- Minimum-area enclosing rotated rectangle: The smallest-area rectangle at any rotation that fully contains a given shape or mask. "We then compute the minimum-area enclosing rotated rectangle of the mask"
- Multimodal LLM (MLLM): A LLM that jointly processes and reasons over text and visual inputs. "In contrast, multimodal LLMs (MLLMs) benefit from the strong language understanding capabilities of their underlying LLMs"
- Open-set detection: Detection that handles categories not seen during training. "while the task itself has evolved from traditional closed-set detection to open-set detection"
- Open vocabulary object detection: Detection using text embeddings to generalize across arbitrary category names. "A common approach to this problem is open vocabulary object detection"
- Point-in-Box Reward: A reinforcement learning reward that assigns credit if a predicted point lies within a target bounding box (used in GUIs). "Point-in-Box Reward. This reward is specifically designed for the GUI Grounding task"
- Point-in-Mask Reward: A reinforcement learning reward that assigns credit if a predicted point lies inside a segmentation mask. "Point-in-Mask Reward. This reward is applied to tasks where the model localizes objects via point predictions"
- Quantized coordinate representation: Mapping continuous coordinates to a fixed set of discrete tokens for generation. "We adopt a quantized coordinate representation, where each coordinate value is mapped to one of 1,000 discrete tokens"
- Relative coordinates: Coordinates expressed relative to image dimensions and binned into a fixed range. "Relative coordinates with special tokens: Coordinates are quantized to values between 0 and 999"
- Reinforcement post-training: Fine-tuning a model using reinforcement learning after supervised training to improve behavior and geometry. "GRPO-based reinforcement post-training with three geometry-aware reward functions."
- Retrieval-based Methods: Approaches where the model selects from candidate proposals rather than generating coordinates directly. "2) Retrieval-based Methods: This approach~\cite{jiang2024chatrex, ma2024groma, jiang2025rex, jiang2025referringperson} incorporates an additional proposal module."
- SAM (Segment Anything Model): A segmentation model that produces masks for various regions with minimal prompting. "We apply SAM~\cite{TransF:SAM} to generate a mask for each ground-truth bounding box in the image."
- Supervised Fine-tuning (SFT): Training a model on labeled data with teacher-forced sequences to learn basic skills. "While SFT allows the model to quickly acquire basic coordinate prediction capabilities by leveraging massive amounts of labeled data"
- Teacher forcing: A training technique where ground-truth tokens are fed as inputs, preventing exposure to the model’s own errors during training. "During SFT, the model is always conditioned on a ground-truth prefix, namely teacher forcing"
- Vision Transformer (ViT): A transformer-based architecture for images that treats patches as tokens. "Following the architecture of Qwen2.5-VL, Rex-Omni also employs a native resolution Vision Transformer as its vision encoder."
- Zero-shot setting: Evaluating a model on tasks or datasets it was not explicitly trained on. "In a zero-shot setting (without training on COCO data), Rex-Omni demonstrates superior F1-score performance"
Collections
Sign up for free to add this paper to one or more collections.