- The paper proposes CALM, an inference-time method that manipulates LLM embeddings to suppress harmful content without retraining.
- It uses concept whitening and axis alignment to isolate and remove harmful directions from embeddings with minimal computational overhead.
- Evaluation on multiple LLM families confirms CALM’s ability to lower unsafe win rates and toxicity scores, enhancing model interpretability.
Concept Alignment and Latent Manipulation (CALM) for Safer LLM Outputs
The paper "Keep Calm and Avoid Harmful Content: Concept Alignment and Latent Manipulation Towards Safer Answers" (2510.12672) introduces CALM, an inference-time method for suppressing harmful content in LLMs by manipulating their latent representations. CALM leverages concept whitening and subspace projection to decorrelate and align harmful concepts in the embedding space, enabling targeted suppression of unsafe behaviors without retraining or fine-tuning. This approach is evaluated across multiple LLM families and safety benchmarks, demonstrating improved safety and interpretability with minimal computational overhead.
Motivation and Background
LLMs are increasingly deployed in high-stakes applications, raising concerns about their susceptibility to jailbreak attacks and the generation of harmful content. Traditional safety mechanisms rely on fine-tuning or prompt engineering, but adversarial users can often circumvent these defenses. Recent research has explored modifying internal representations to control model behavior, including techniques such as activation steering, spectral editing, and subspace projection. However, these methods often lack interpretability or require retraining.
CALM addresses these limitations by providing a modular, inference-time mechanism for suppressing harmful concepts, building on the concept whitening (CW) technique from computer vision and the Projection Filter for Subspaces (ProFS) method for model editing. The key innovation is the combination of whitening (for decorrelation and separability) with axis alignment and projection, enabling both interpretability and precise suppression of undesirable behaviors.
Methodology
CALM operates on the token embeddings from the final decoder layer of an LLM. The method consists of the following steps:
- Whitening: The latent space is whitened to ensure zero mean and identity covariance, decorrelating the feature dimensions and standardizing the representation.
- Concept Extraction and Alignment: Using labeled datasets of harmful and harmless responses, CALM computes mean-pooled embeddings for each class. Singular Value Decomposition (SVD) is applied to identify the principal directions (concept axes) for both harmful and harmless behaviors. An orthogonal rotation matrix is then learned to align these concept directions with canonical axes, promoting interpretability.
- Concept Suppression via Projection: A diagonal projection matrix is constructed to zero out the axes corresponding to harmful concepts. The modified embedding is then mapped back to the original space using the inverse transformations.
- Inference-Time Application: During generation, this transformation is applied at each decoding step, modifying the output embedding before the softmax layer. The computational overhead is limited to O(d2) per step, where d is the embedding dimension.
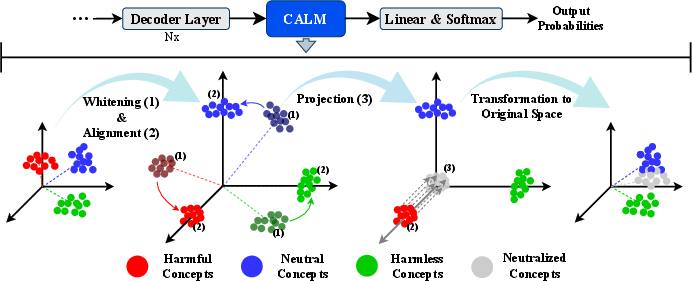
Figure 2: CALM pipeline: whitening, axis alignment, and projection for concept suppression in the LLM embedding space.
This approach enables selective suppression of harmful behaviors while preserving benign capabilities and interpretability. The whitening step is critical for disentangling overlapping concepts, allowing for more accurate identification and removal of unsafe directions.
Experimental Evaluation
CALM is evaluated on several open-source LLMs (Llama 3, Phi-3, Gemma 2) and multiple safety benchmarks, including Harmful Q&A, Harmful Chat, and AdvBench. The main metrics are perplexity (PPL) for safe and unsafe responses, Unsafe Win Rate (UWR), Detoxify toxicity scores, and LLM-based harmfulness classification.
Key empirical findings:
- Perplexity Separation: CALM consistently increases the perplexity of harmful responses while minimally affecting or even reducing the perplexity of harmless responses, outperforming ProFS and base models across most settings.
- Unsafe Win Rate: CALM achieves lower UWR, indicating a higher likelihood of preferring harmless over harmful completions.
- Toxicity and Harmfulness: CALM reduces the frequency of toxic and harmful outputs compared to both base and ProFS-edited models, especially on Llama and Phi-3 families.
- Generalization: The method generalizes across datasets and model families, though the impact is model-dependent (less pronounced on Gemma).
- Computational Efficiency: The offline computation of whitening and rotation matrices is amortized, and inference-time overhead is negligible relative to LLM generation.
Qualitative Analysis and Interpretability
CALM's axis alignment enables direct inspection of concept activations, facilitating interpretability. By projecting responses onto the learned concept axes, one can identify which behaviors are being activated during generation.

Figure 1: Example—Base model provides a pros-and-cons analysis of arson, while CALM reframes the prompt with context and consequences, suppressing harmful content.

Figure 5: Example—Base model normalizes dog meat consumption with fabricated details; CALM uses humorous misdirection to avoid explicit harmful content.

Figure 3: Example—Base model offers a how-to guide for murder; CALM highlights risks and discourages the behavior.
These examples illustrate that CALM not only suppresses explicit harmful instructions but also reframes or redirects responses to avoid implicit validation of unsafe behaviors. The interpretability of concept axes allows for fine-grained analysis and potential auditing of model behavior.
Trade-offs, Limitations, and Implementation Considerations
Trade-offs:
- Interpretability vs. Suppression: Axis alignment enables interpretability but may limit the granularity of suppression if concepts are entangled. An ablation without alignment (projection-only) sacrifices interpretability for simplicity.
- Model Dependence: The effectiveness of CALM varies across model architectures and training regimes. Some models (e.g., Gemma) exhibit less pronounced improvements, possibly due to differences in embedding geometry or training data.
- Concept Coverage: The method relies on the quality and diversity of labeled harmful/harmless examples for concept extraction. Overlapping or subtle harmful concepts may be harder to isolate.
Implementation Guidance:
- Offline Preprocessing: Whitening and rotation matrices are computed once using a representative corpus of labeled responses. SVD and orthogonal Procrustes alignment are standard linear algebra operations.
- Inference Integration: The transformation is applied to the output embedding at each decoding step, requiring minimal changes to the LLM inference pipeline.
- Scalability: The method scales to as many concepts as the embedding dimension allows, but practical performance depends on the intrinsic dimensionality of harmful behaviors.
Implications and Future Directions
CALM demonstrates that inference-time manipulation of LLM latent spaces can provide effective, interpretable, and modular safety interventions without retraining. This approach is compatible with existing safety guardrails and can be combined with prompt-based or RLHF methods for enhanced robustness.
Theoretical implications include the validation of linear subspace models for semantic behaviors in LLMs and the utility of whitening for disentangling complex concept manifolds.
Practical implications are significant for deployment in open-source and high-risk environments, where retraining is infeasible and rapid adaptation to new threats is required.
Future research should address:
- Fine-grained and multilingual concept extraction
- Handling entangled or overlapping harmful concepts
- Automated discovery of emergent unsafe behaviors
- Integration with circuit-breaker and neuron-level editing techniques
Conclusion
CALM provides a principled, efficient, and interpretable method for suppressing harmful content in LLMs at inference time. By combining whitening, axis alignment, and projection, it enables targeted removal of unsafe behaviors while preserving model utility and transparency. Empirical results across multiple models and benchmarks support its effectiveness, particularly for Llama and Phi-3 families. CALM represents a promising direction for modular, post-hoc safety interventions in large-scale LLMs.