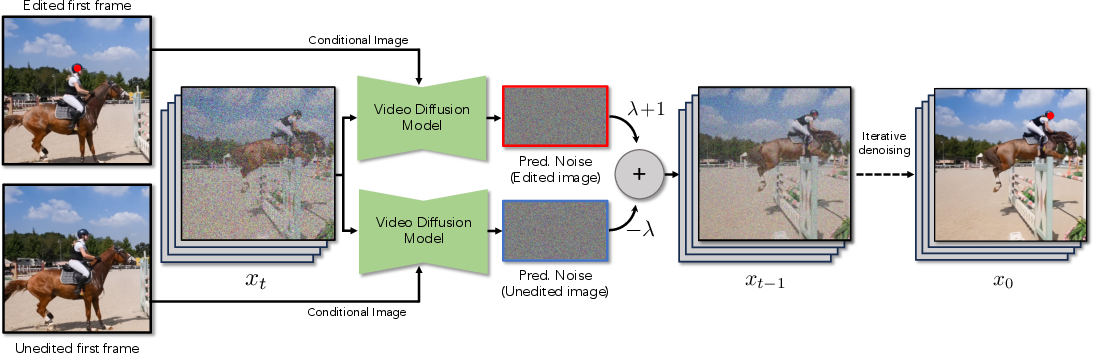
- The paper introduces a novel zero-shot tracking method using pretrained video diffusion models to propagate a colored marker through video frames.
- It leverages counterfactual modeling and negative prompting via SDEdit to ensure robust marker propagation and effective occlusion handling.
- Experimental results demonstrate competitive performance with high AJ scores and occlusion robustness, highlighting the technique's promising integration with generative models.
Point Prompting: Counterfactual Tracking with Video Diffusion Models
Introduction
This paper introduces a novel approach for zero-shot point tracking in videos by leveraging pretrained video diffusion models. The method exploits the generative capabilities of these models to propagate a visually distinctive marker (a colored dot) through video frames, enabling the estimation of a point's trajectory without any additional training. The approach is grounded in counterfactual modeling, where the input video is perturbed by marking the query point, and the model is prompted to generate future frames that maintain the marker's presence. The technique demonstrates strong performance on the TAP-Vid benchmark, outperforming previous zero-shot methods and approaching the accuracy of specialized self-supervised trackers.
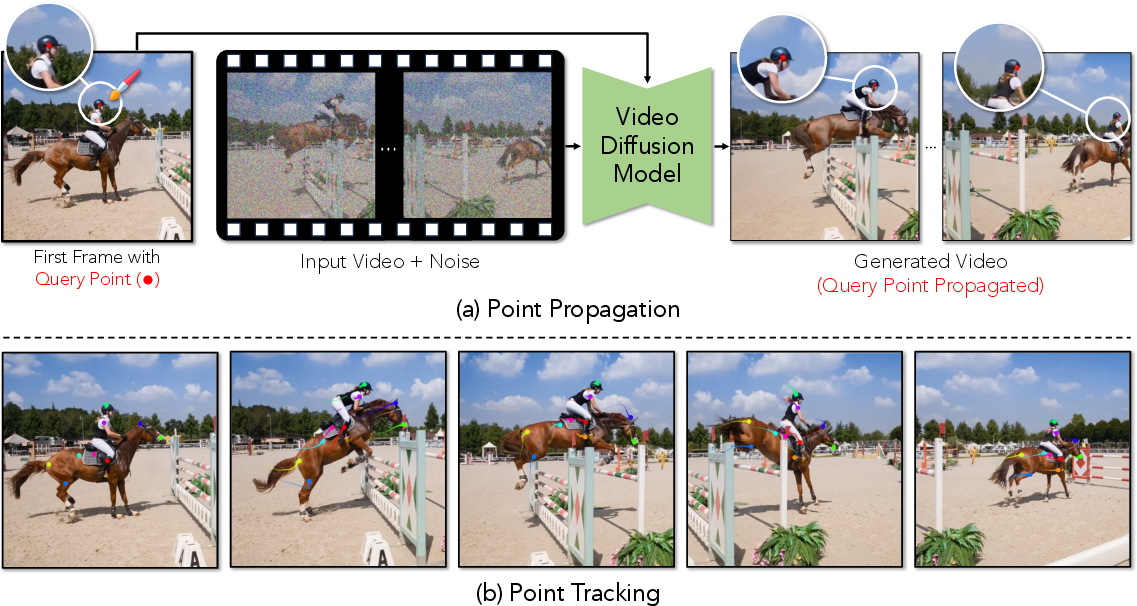
Figure 1: Prompting a diffusion model for tracking by inserting a colored dot in the first frame and propagating it through subsequent frames using SDEdit.
Methodology
Video Diffusion Model Manipulation
The core of the method is the manipulation of pretrained video diffusion models via SDEdit. The process involves:
Tracking Pipeline
The tracking pipeline consists of several stages:
- Color-Based Tracking: The marker's position is detected in each frame using color thresholding in HSV space, with a local search window centered on the previous detection.
- Occlusion Handling: If the marker is not detected, the last known position is propagated, and the search radius is expanded until the marker reappears.
- Coarse-to-Fine Refinement: Initial tracks are refined by inpainting only the regions near the predicted marker positions, correcting for spatial misalignments introduced during denoising.
- Color Rebalancing: The video's color distribution is adjusted to suppress the marker's color in the background, reducing false positives during occlusion.
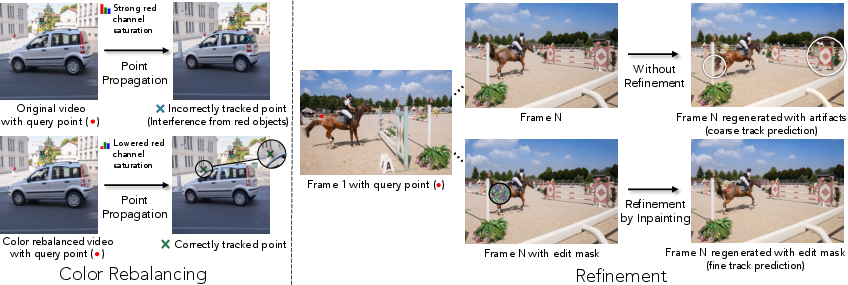
Figure 3: Tracking enhancements including color rebalancing and inpainting-based refinement for improved accuracy.
Experimental Results
Quantitative Evaluation
The method is evaluated on the TAP-Vid DAVIS and Kinetics splits using several recent video diffusion models (Wan2.1, Wan2.2, CogVideoX). Key findings include:
- Zero-Shot Superiority: The proposed approach achieves an AJ score of 42.21 on TAP-Vid DAVIS, outperforming all other zero-shot baselines and even surpassing some self-supervised methods.
- Occlusion Robustness: Occlusion accuracy (OA) is competitive with supervised trackers, indicating strong object permanence capabilities.
- Model Scaling: Larger and higher-fidelity video diffusion models (Wan2.1-14B, Wan2.2-14B) yield improved tracking performance.
- Resolution Impact: Upscaling input videos enhances tracking accuracy, with higher-resolution inputs better aligning with the model's training distribution.
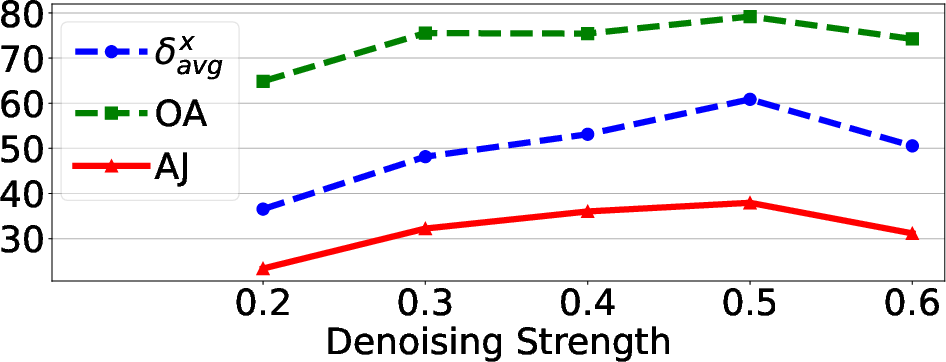
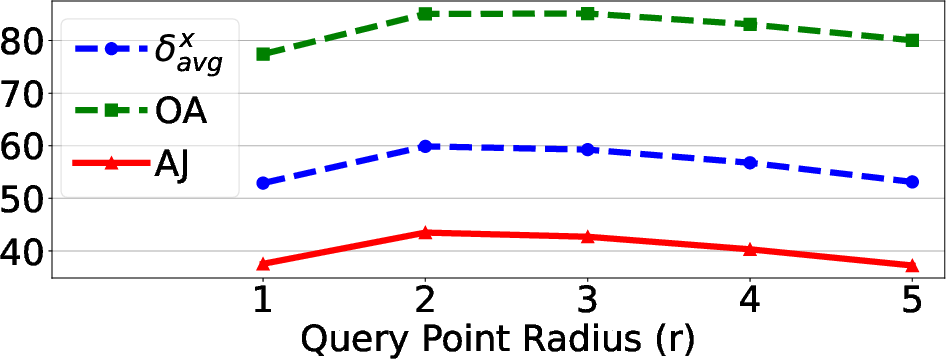
Figure 4: Ablation results showing the impact of each pipeline stage and the effect of denoising strength and search radius on tracking performance.
Qualitative Analysis
Generated videos demonstrate consistent propagation of the marker, with successful recovery after long occlusions and robust tracking across diverse scenes. Failure cases are primarily attributed to out-of-distribution inputs, ambiguous object boundaries, or insufficient texture.

Figure 5: Point propagation examples showing the marker's trajectory through occlusions and complex motion.

Figure 6: Tracking results visualized as the marker and its trajectory over time, including occlusion handling.

Figure 7: Generation failures such as stationary points, symmetry confusion, and marker disappearance.

Figure 8: Qualitative results on TAP-Vid Kubric, highlighting both successful and failed point propagation in synthetic scenes.
Implementation Details
- Computational Requirements: Generating a 50-frame video for a single query point requires 7–30 minutes on A40/L40S GPUs, depending on model size.
- Hyperparameters: Optimal performance is achieved with a denoising strength of 0.5, a search radius of 2 pixels, and a guidance weight λ=8.
- Color Detection: HSV color space is preferred for marker detection; LAB yields slightly lower accuracy.
- Pipeline Efficiency: The method is not optimized for speed but could be distilled into a more efficient model or extended to track multiple points simultaneously.
Limitations
- Per-Point Generation: Each tracked point requires a separate video generation, limiting scalability.
- Failure Modes: The model may fail to interpret the marker as attached to the object, especially in synthetic or low-texture scenes.
- Generalization: Performance drops on synthetic datasets (e.g., Kubric) due to domain mismatch with training data.
Implications and Future Directions
This work demonstrates that pretrained video diffusion models possess emergent tracking capabilities that can be elicited via visual prompting. The approach unifies generative modeling and motion analysis, suggesting that generative models can serve as a source of pretraining for tracking tasks. Future research may explore:
- Efficient Distillation: Compressing the tracking behavior into lightweight models for real-time applications.
- Multi-Point Tracking: Extending the method to simultaneously track multiple points.
- Generalization: Improving robustness to synthetic and out-of-distribution videos.
- Prompting Schemes: Developing more sophisticated visual prompts for other video understanding tasks.
Conclusion
The paper establishes that video diffusion models, when prompted with simple visual cues, can perform zero-shot point tracking with competitive accuracy. The method leverages counterfactual modeling and negative prompting to maintain marker visibility, and achieves strong results on standard benchmarks. This approach opens new avenues for adapting generative models to video analysis tasks and highlights the potential for further integration of generation and tracking in computer vision.