- The paper introduces Diffusion-Link, a diffusion model that bridges the modality gap by mapping audio embeddings into the text-embedding space.
- It employs a forward diffusion process with added Gaussian noise and a reverse denoising process via a lightweight network, achieving significant AAC improvements.
- Experimental results on AudioCaps demonstrate enhanced cosine similarity and state-of-the-art performance in zero-shot and supervised audio captioning.
Diffusion-Link: Diffusion Probabilistic Model for Bridging the Audio-Text Modality Gap
Introduction
This paper introduces "Diffusion-Link," a diffusion probabilistic model designed to mitigate the persistent modality gap between audio and text embeddings in multimodal systems. The modality gap poses a significant challenge for coupling contrastive audio-language encoders with LLMs, especially in tasks like Automatic Audio Captioning (AAC). By employing a diffusion-based mechanism, Diffusion-Link aims to map audio embeddings into the text-embedding distribution. Distinctively, this study represents the first application of diffusion-based modality bridging to AAC, signifying a novel direction beyond conventional knowledge-retrieval-centric designs.
Methodology
Diffusion-Link leverages the principles of denoising diffusion probabilistic models (DDPM) to bridge the modality gap. The model operates through two primary processes: a forward diffusion process that introduces Gaussian noise to audio and text embeddings, guiding them towards a common isotropic Gaussian state, and a reverse diffusion process that maps these noised embeddings back into the target text-embedding distribution.
The architecture comprises a lightweight network with three residual MLP blocks trained on the output embeddings from a frozen multimodal encoder. This setup contrasts with traditional generative models by specifically targeting and reducing the audio-text embedding gap using a diffusion-based process.
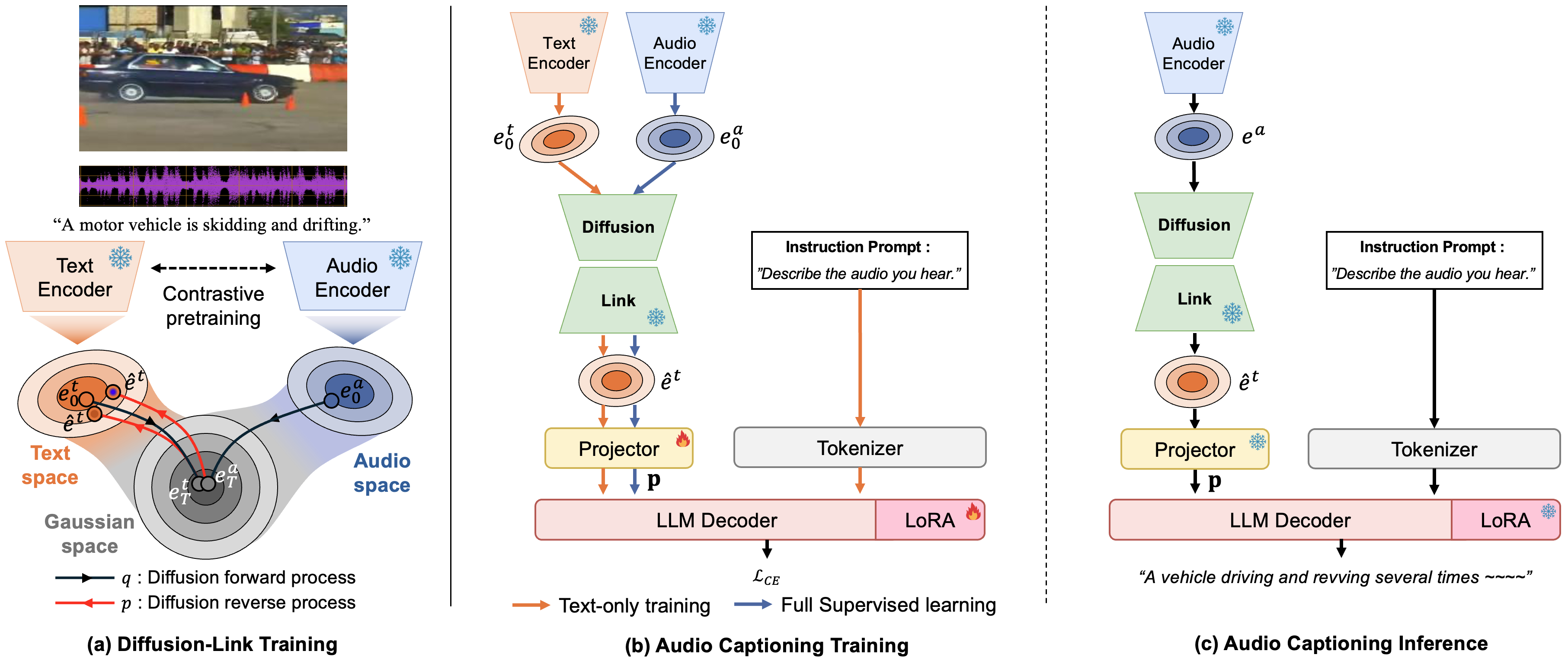
Figure 1: (a) Overview of the proposed Diffusion-Link mechanism and (b,c) illustration of our LLM-based AAC system with Diffusion-Link.
During inference, forward noise is applied at an optional forward step, utilizing a trained reverse diffusion trajectory to produce a text-like embedding. This text-like embedding is then used for downstream AAC tasks without requiring changes to the multimodal encoder, which remains frozen.
Experimental Evaluation
The paper provides extensive evaluation of Diffusion-Link on the AudioCaps dataset. Analysis reveals that Diffusion-Link substantially diminishes the modality gap by increasing the cosine similarity of matched audio-text pairs and decreasing it for mismatched ones, surpassing prior diffusion-based methods. A clear collective migration of audio embeddings toward the text-embedding distribution is observed, effectively illustrating the modality bridging capability of Diffusion-Link.
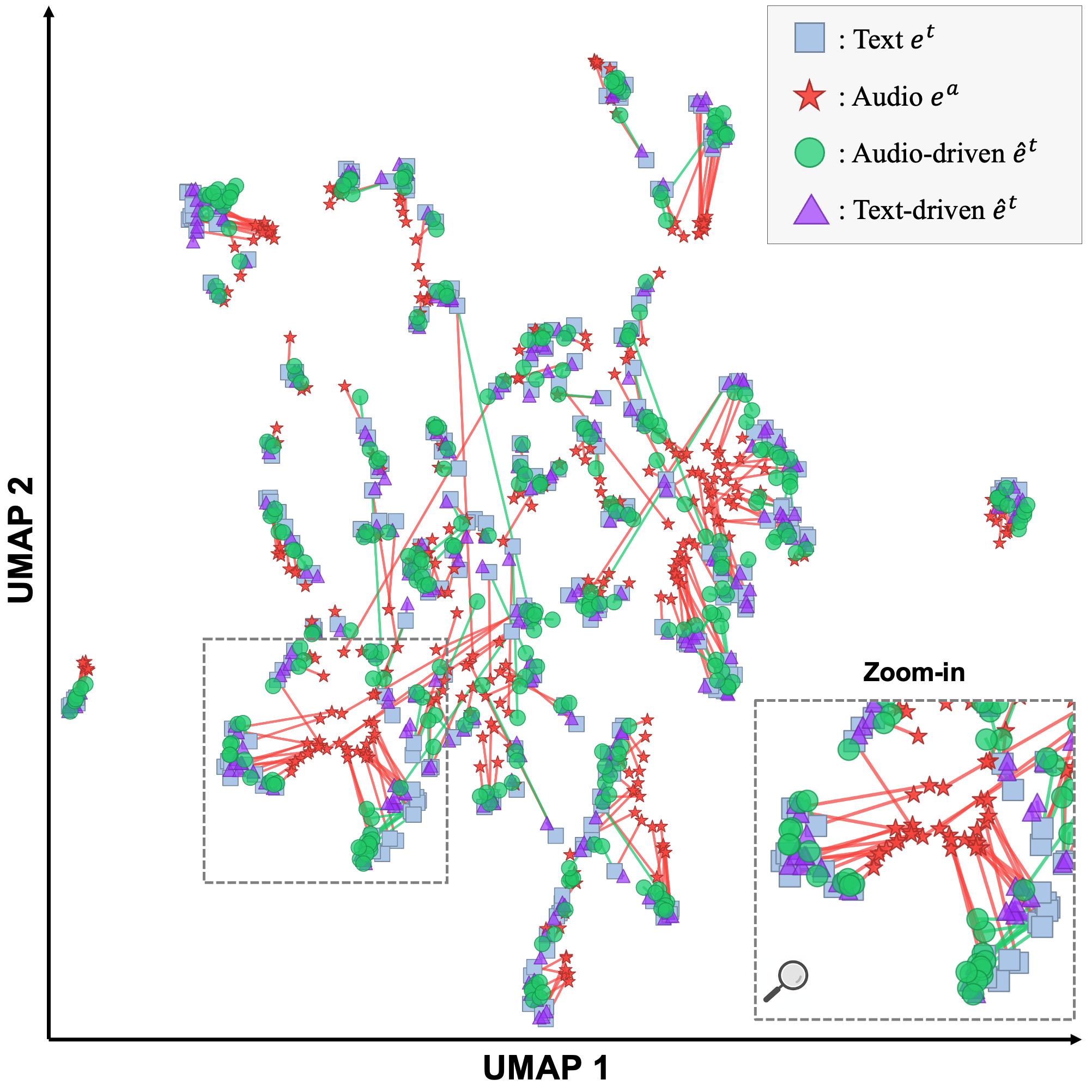
Figure 2: Visualization of embeddings on AudioCaps using UMAP. Red line means the pair of audio and text embeddings. Green line means the pair of text-like and original text embeddings.
In AAC tasks, Diffusion-Link achieved state-of-the-art performances in both zero-shot and fully supervised scenarios. When attached to a multimodal LLM baseline, it demonstrated relative improvements of up to 52.5% in zero-shot captioning and 7.5% in fully supervised captioning. This performance highlights the efficacy of the approach in reducing reliance on external knowledge, such as retrieval-augmented generation (RAG).
Implications and Future Directions
The implications of Diffusion-Link are significant for the field of multimodal systems. Not only does it present a robust method for bridging the modality gap, but it also offers a modular and efficient solution that enhances existing multimodal encoder-LLM frameworks without additional computational overhead. By focusing on modality bridging rather than external knowledge retrieval, Diffusion-Link sets a precedent for more synergistic multimodal model architectures.
Future research could extend this approach to other modalities, exploring the generalizability of diffusion-based modality bridging across different domains such as vision-language or audio-visual tasks. Additionally, further refinement of noise schedules and embedding transformations within the diffusion framework could enhance the fidelity and applicability of the generated embeddings for diverse use cases in AI.
Conclusion
Diffusion-Link establishes itself as a pivotal advancement in addressing the audio-text modality gap. Its innovative use of diffusion models provides significant improvements in AAC without external dependencies, offering a promising path for future advancements in multimodal AI systems. As diffusion-based methods gain traction, the foundational work presented in this paper will likely inspire and inform subsequent developments in the field.

