VLM-Guided Adaptive Negative Prompting for Creative Generation
Abstract: Creative generation is the synthesis of new, surprising, and valuable samples that reflect user intent yet cannot be envisioned in advance. This task aims to extend human imagination, enabling the discovery of visual concepts that exist in the unexplored spaces between familiar domains. While text-to-image diffusion models excel at rendering photorealistic scenes that faithfully match user prompts, they still struggle to generate genuinely novel content. Existing approaches to enhance generative creativity either rely on interpolation of image features, which restricts exploration to predefined categories, or require time-intensive procedures such as embedding optimization or model fine-tuning. We propose VLM-Guided Adaptive Negative-Prompting, a training-free, inference-time method that promotes creative image generation while preserving the validity of the generated object. Our approach utilizes a vision-LLM (VLM) that analyzes intermediate outputs of the generation process and adaptively steers it away from conventional visual concepts, encouraging the emergence of novel and surprising outputs. We evaluate creativity through both novelty and validity, using statistical metrics in the CLIP embedding space. Through extensive experiments, we show consistent gains in creative novelty with negligible computational overhead. Moreover, unlike existing methods that primarily generate single objects, our approach extends to complex scenarios, such as generating coherent sets of creative objects and preserving creativity within elaborate compositional prompts. Our method integrates seamlessly into existing diffusion pipelines, offering a practical route to producing creative outputs that venture beyond the constraints of textual descriptions.






























































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about making AI image generators more truly creative. Today’s text-to-image models are great at making realistic pictures that match our prompts, but when you ask for something like “a new type of pet,” they usually give you familiar animals with small tweaks (like a blue cat or a dog with wings). The authors introduce a simple, fast way to guide these models so they invent ideas that feel genuinely new, while still making sense (for example, a new pet that doesn’t just look like a cat-dog mashup, or a creative building that still has windows and doors).
The big questions the researchers asked
The researchers wanted to know:
- How can we help image generators explore beyond the usual patterns and create original ideas, not just combinations of familiar ones?
- Can we do this without retraining the model or doing heavy, slow optimization?
- Can we keep images valid (so a “building” still functions like a building) while increasing novelty?
How their method works (in simple terms)
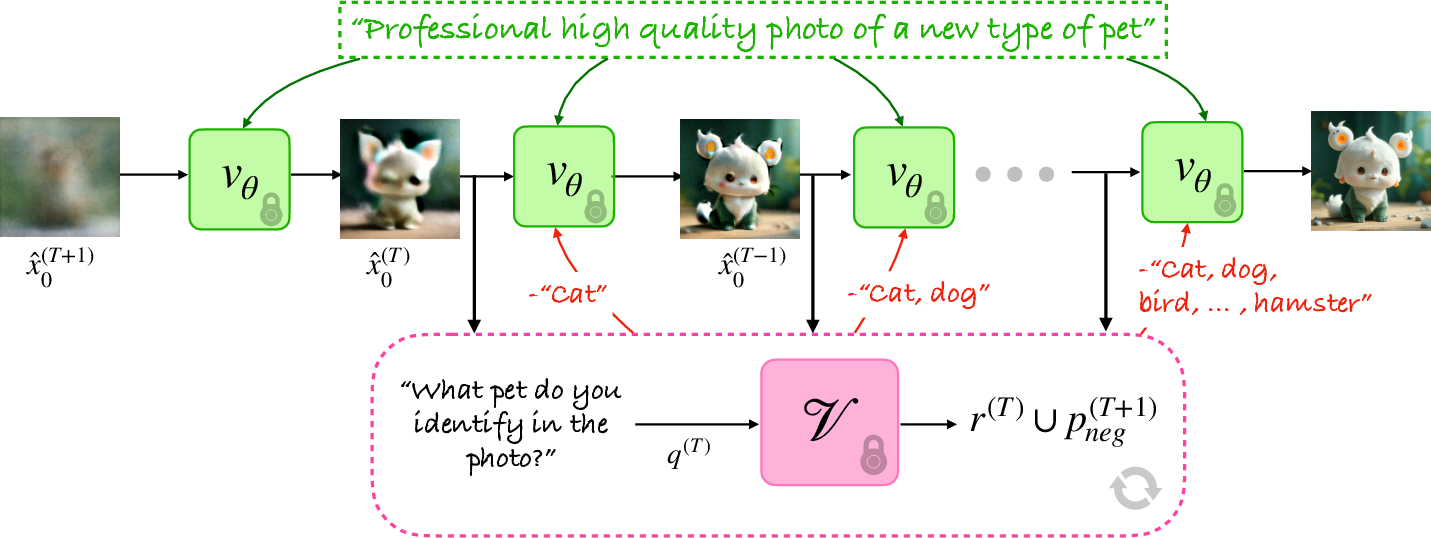
Think of the AI image generator as an artist who starts with a very blurry canvas and gradually sharpens it into a picture. The method adds a smart “coach” that watches the picture evolve and gives quick tips to steer it away from boring, typical results.
Here are the key ideas in everyday language:
- Diffusion model: This is the “artist” that turns noise into a clear image step by step.
- Vision-LLM (VLM): This is the “coach” that can look at an image and describe what’s in it using words.
- Negative prompting: This is like a “do-not-draw” list. If the coach sees the picture drifting toward a common concept (say, “cat”), it adds “cat” to the “avoid” list so the artist stops making it look like a cat.
What actually happens:
- The model begins making an image from random noise.
- At each step, the coach (a VLM) quickly checks the current, partly formed picture and identifies the most obvious concepts it sees (like “dog,” “leather jacket,” “glass building”).
- Those detected concepts get added to a growing “avoid” list (negative prompts).
- The generator uses that list right away in the next step, steering away from typical ideas and toward creative, less-explored options.
- This repeats until the final image is done.
Analogy: Imagine sculpting a statue while a helpful friend watches and says, “Careful, it’s starting to look like a standard lion again—try something different!” You listen, adjust, and the statue gradually becomes something truly new.
What did they find?
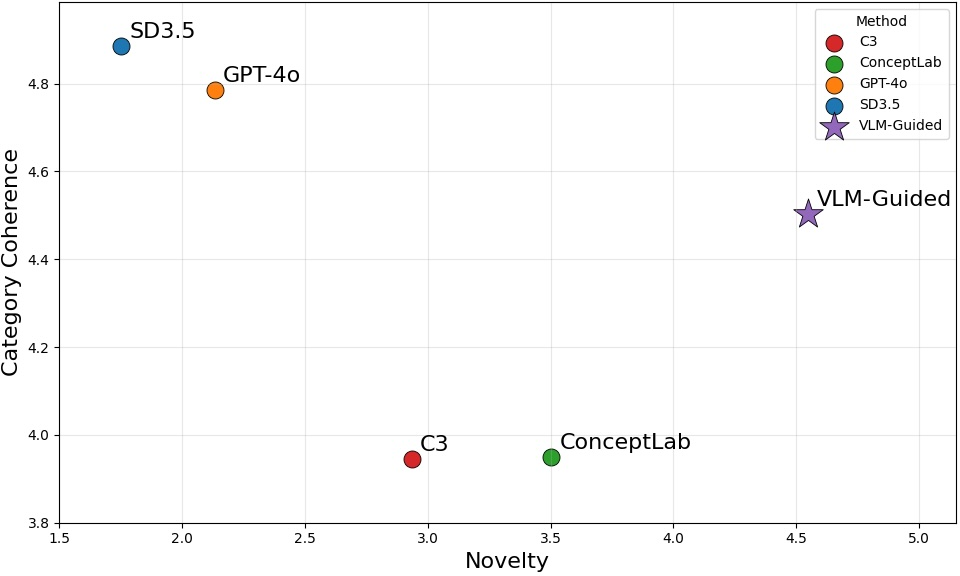
- More novelty without losing sense: Their images were judged more original than regular outputs, but they still matched the category (a “fruit” looked like a fruit, a “building” looked like a building).
- Simple prompts alone don’t work: Just adding words like “creative” or “new type of” didn’t produce truly new ideas in popular models. The guided method did.
- Fast and training-free: It works at “inference time,” meaning you don’t retrain or tweak the original model. It adds only a small amount of time to generation and fits into existing pipelines.
- Works on complex scenes and sets: It can keep creativity even in multi-part prompts (like “a creative jacket worn by someone in a café”) and can produce cohesive sets (like a creative tea set where each piece is inventive but still fits together).
- Human and metric tests: In a user study, people rated the method high on both novelty and validity. The paper also used tools like CLIP and GPT-based checks to measure originality, diversity, and correctness, and found strong performance across these measures.
Why it matters and what could happen next
This approach gives artists, designers, and hobbyists a practical way to push AI beyond “safe” ideas. It helps discover fresh shapes, patterns, and objects that aren’t just remixes of what the model has seen before, while keeping the results usable and believable.
Potential impact:
- Product and fashion design: Invent new kinds of bags, jackets, or furniture that don’t look like existing styles.
- Architecture and environmental design: Explore building forms that are surprising yet functional.
- Worldbuilding and games: Create believable yet original creatures, plants, and props.
- Broader content creation: The same guidance style could be extended to video, 3D models, or mixed media—anywhere you want originality with coherence.
In short, the paper shows a practical, plug-in way to make AI image generation more adventurous and imaginative—without breaking the rules that keep images meaningful and useful.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to enable actionable follow-up research.
- How to automatically design and select effective VLM questions per category and per timestep (question generation, rephrasing, and curricula), rather than relying on manually crafted prompts.
- Principled scheduling of VLM queries across denoising steps: when to start/stop querying, how frequently to query, and how to adapt the schedule to the evolving image state.
- Formal treatment of negative prompt accumulation: weighting, decay/forgetting, removal of stale or misguiding negatives, and conflict resolution when accumulated negatives suppress essential category-defining attributes.
- Sensitivity analysis for key hyperparameters (e.g., guidance scale
w, negative-prompt strength, number of accumulation steps, CLIP/VLM thresholds) and their joint effects on the creativity–validity trade-off. - Reliability of VLM detections on noisy intermediate predictions (early timesteps): confidence calibration, uncertainty estimation, and safeguards against misclassification-driven misguidance.
- Mechanisms to preserve validity constraints beyond generic category labels (e.g., functional requirements like “a chair must support sitting”), including automatic detection of when negative prompts begin to suppress necessary affordances.
- User-controllable “creativity dial” (continuous control) that allows specifying how far to push away from conventional concepts, and methods to predict/guarantee validity at each setting.
- Robustness across broader base models and visual domains (e.g., anime, line art, CAD renders, medical imagery, scientific diagrams), including pixel-space diffusion and rectified-flow samplers where
x0prediction may differ or be unavailable. - Scalability and systems-level performance: amortized overhead at batch scale, memory/latency on commodity GPUs, caching/sharing VLM inferences across timesteps or seeds, and performance under real-time constraints.
- Bias and safety auditing: whether adaptive negatives steer generation into stereotypical, harmful, or biased representations; procedures to detect and mitigate such outcomes across demographics and cultures.
- Evaluation dependence on CLIP/GPT: potential circularity and bias when VLMs/LLMs both guide and evaluate; need for standardized, open benchmarks and task-specific validity tests (including functional tests for objects).
- Limited category coverage in quantitative evaluation (four categories) and absence of standardized multi-object compositional metrics; need to assess complex scenes with measurable compositional validity and inter-object coherence.
- Inter-rater reliability and demographic coverage in the user study (e.g., agreement metrics, participant diversity), plus clear reporting of randomization, blinding, and selection criteria to ensure reproducibility.
- Formal understanding of how negative prompting modifies the probability flow ODE and the learned velocity field (e.g., analysis of semantic mode repulsion, trajectory geometry, and convergence properties).
- Failure mode taxonomy: cases where guidance leads to nonsensical outputs, visual artifacts, mode collapse, or repeated suppression of semantically necessary features; protocols for detection and recovery.
- Strategies for multilingual operation (prompts and VLM queries), cross-language consistency, and differences in creativity/validity across languages and writing systems.
- Quantitative assessment of text alignment under creative guidance (beyond CLIP), especially for complex, compositional prompts; methods to prevent degradation of non-“creative” prompt fidelity when the approach is applied broadly.
- Extension to time and geometry: how to adapt adaptive negative prompting to video (temporal coherence, frame-wise schedules), 3D/NeRF (geometric validity, multi-view consistency), and multimodal pipelines (text–image–audio).
- Generalization of “dominant feature” extraction from VLMs beyond object categories to materials, affordances, relations (e.g., “behind,” “holding”), and styles, including targeted suppression of conventional relational patterns.
- Alternatives or complements to VLM guidance (e.g., unsupervised novelty detectors, out-of-distribution estimators, concept entropy maximization) that reduce reliance on VLM accuracy and cost.
- Seed-specific adaptations vs. reusability: criteria to determine when accumulated negative lists can be safely replayed across seeds, prompts, or batches without harming creativity or validity.
- Impact on high-resolution generation (e.g., 4k+) and complex pipelines (inpainting, control networks, upscalers), including whether adaptive negatives remain effective after post-processing stages.
- Transparent and reproducible release artifacts: full code, prompt lists, seeds, metrics implementations, and model configurations needed to independently replicate the claimed gains across diverse settings.
- Ethical implications of “novelty generation” (e.g., synthetic inventions visually plausible but misleading), and guidelines for responsible deployment in domains where validity has safety or regulatory implications (architecture, product design).
Practical Applications
Immediate Applications
The method enables training-free, inference-time creative generation with minimal computational overhead and integrates into existing diffusion pipelines. The following applications can be deployed now:
- Creative concept ideation for product design (fashion, furniture, consumer goods, automotive)
- Use the VLM-guided adaptive negative prompting to explore unconventional yet recognizable forms for jackets, bags, sofas, and vehicles.
- Workflow: import brief and base prompt → apply domain-specific question sets (e.g., shape, material, design) → generate diverse boards → human select and iterate.
- Tools/products: “Adaptive Negative Prompting” plugin for ComfyUI/Automatic1111; Python SDK wrapper around SDXL/SD3.5 with BLIP-2/Qwen2.5-VL.
- Assumptions/dependencies: requires a diffusion model supporting negative prompting and a competent VLM; outputs are visually valid but not functionally engineered (human review needed).
- Early-stage architecture massing and concept sketches (architecture, urban design)
- Generate unconventional building forms that still retain validity signals (windows, doors, balconies).
- Workflow: broad category prompts (e.g., “creative building”) → VLM questions targeting form/material → batch exploration → select promising massings for further CAD development.
- Assumptions/dependencies: no structural or code compliance guarantees; bridge to CAD/BIM left to downstream tools.
- Marketing and advertising asset exploration (media, creative agencies)
- Produce novel category exemplars for campaigns beyond “typical” model outputs; use contextual placement (e.g., Flux.1-dev Kontext) to integrate assets into scenes.
- Workflow: generate creative hero objects → contextual placement in lifestyle scenes → A/B testing with novelty/validity metrics.
- Assumptions/dependencies: brand safety, content moderation filters, and legal review for IP and claims are required.
- Game/film previsualization and concept art (entertainment)
- Rapidly explore novel creatures, props, and “sets of stuff” with coherent style.
- Workflow: creative category prompts (pets, instruments, tea/chess/cutlery sets) → iterative accumulation of negatives → art director curation.
- Assumptions/dependencies: resolution/stylistic control may require additional model passes; ensure IP clearance.
- E-commerce image variety for ideation and mood boards (retail, DTC brands)
- Generate unique variations (bags, garments, footwear) for trend scouting and creative direction.
- Workflow: batch generate creative variants → curate mood boards → optionally place into lifestyle scenes using Kontext.
- Assumptions/dependencies: do not misrepresent available products; clearly label conceptual imagery.
- Design education and creativity training (education)
- Teach novelty vs validity trade-offs using the method’s metrics and ablations; create assignments that explore semantic categories.
- Tools/products: classroom notebooks; “Question Set Library” for different domains; built-in “Novelty meter” (relative typicality, Vendi, GPT Novelty Score).
- Assumptions/dependencies: accessible GPU/compute; instructors curate domain-specific question sets.
- Dataset augmentation for creativity research (academia, ML research)
- Generate controlled creative datasets to benchmark novelty, diversity, and validity.
- Workflow: define target categories → run method across seeds/VLMs → compute CLIP/GPT metrics → publish dataset and scores.
- Assumptions/dependencies: licensing of generated assets, bias audits, reproducible evaluation protocols.
- Interactive brainstorming assistant for creative teams (software)
- Deploy a UI panel that surfaces the live negative prompt list, lets users adjust accumulation, and exposes a “novelty knob.”
- Tools/products: “Creative Explorer” panel for SDXL/SD3.5; REST API integrating a VLM (e.g., BLIP-2/Qwen2.5-VL).
- Assumptions/dependencies: stable VLM inference; GPU memory; question design is key to outcomes.
- Consistent creative collections (homeware, fashion, accessories)
- Generate coherent sets (tea sets, cutlery, luggage) with unified creative themes while preserving functionality cues.
- Workflow: “creative [set]” prompts → use compositional questions (shape/material/style) → select cohesive sub-series.
- Assumptions/dependencies: no manufacturability guarantee; human curation to ensure usability.
- Personal content creation and mood boards (daily life, creators)
- Create unique pets, plants, outfits for social content, posters, or cosplay design references.
- Workflow: run method with consumer GPUs or cloud UIs → select favorites → optionally place into scenes (Kontext).
- Assumptions/dependencies: access to models and basic onboarding; ensure clear labeling of AI-generated content.
Long-Term Applications
Extending the method beyond 2D images and integrating functional constraints will unlock broader impact across industries and policy:
- CAD/CAE-integrated generative design (industrial design, manufacturing)
- Productized pipeline that maps 2D creative outputs to parametric CAD and checks physical constraints via simulation.
- Tools/products: “Creative-to-CAD Bridge” plugin; interoperability with Fusion 360/SolidWorks; CAE validation hook.
- Assumptions/dependencies: robust 2D→3D reconstruction; manufacturability constraints; ergonomic/safety validation.
- 3D and video creative generation (VFX, AR/VR, games)
- Extend adaptive negative prompting to 3D/temporal diffusion, enabling novel yet coherent motion and volumetric assets.
- Assumptions/dependencies: spatiotemporal diffusion models; video-capable VLMs; real-time performance optimization.
- Large-scale automated design exploration and screening (enterprise R&D)
- Platform that runs thousands of creative variants, scores novelty/validity, and schedules human-in-the-loop reviews.
- Tools/products: enterprise “Creative Discovery” service; dashboards with metric distributions and selection workflows.
- Assumptions/dependencies: compute scaling; provenance tracking; secure data handling.
- IP and novelty assessment assistive tools (legal, policy)
- “Novelty meter” to flag typical vs unexplored visual modes as a pre-screening aid for prior art searches (non-binding).
- Assumptions/dependencies: rigorous validation of metrics; human oversight; regulatory acceptance; fairness and bias safeguards.
- Standardization of creativity metrics and disclosures (policy, academia)
- Multi-stakeholder frameworks that define reportable metrics (novelty, validity, diversity), provenance logs, and labeling standards for AI-generated creative content.
- Assumptions/dependencies: consensus-building across industry, academia, and regulators; integration with content provenance standards (e.g., C2PA).
- Mass personalization pipelines (retail/e-commerce)
- Customer co-creation workflows that generate unique product appearances (e.g., bags/shoes) and route them to production.
- Assumptions/dependencies: mapping visual concepts to materials/processes; quality assurance; returns/liability management.
- Safety- and bias-aware creative steering (responsible AI)
- Integrate constraint lists and dynamic filters into the negative-prompt accumulation to avoid harmful stereotypes or unsafe forms.
- Tools/products: “Responsible Creativity” module with policy taxonomies; real-time VLM-based screening.
- Assumptions/dependencies: curated taxonomies; continuous monitoring; robust VLM robustness across demographics.
- Cross-modal scientific ideation (materials, bio design)
- Adapt the negative-prompting paradigm to domain-specific generative models (e.g., materials microstructures) to explore unseen design spaces with validity constraints.
- Assumptions/dependencies: domain generative models and validators; safety and ethics reviews; strong validity guarantees.
- Collaborative creative workspaces (workforce enablement)
- Multi-user ideation boards with versioning, question-set repositories, and novelty dashboards for design teams.
- Assumptions/dependencies: UI/UX development; access control; asset lifecycle management.
- Compliance and audit trails for AI-generated creative content (policy/compliance)
- Record VLM queries, accumulated negatives, seeds, and metrics to provide transparent provenance for audits and content governance.
- Assumptions/dependencies: standards alignment; storage policies; privacy and IP considerations.
In all cases, feasibility depends on the availability of a capable VLM, a diffusion model that supports negative prompting, effective question design, adequate compute, and human oversight to ensure functional validity, safety, and legal compliance.
Glossary
- Ablation studies: Controlled experiments that remove or modify components to test their necessity or impact. "Through extensive ablation studies, we validate our key design choices, including dynamic negative prompt accumulation and per-generation adaptation, showing superiority over alternative approaches."
- Adaptive negative prompting: Dynamically updating a list of discouraged concepts during generation to steer away from typical outputs. "Our method generates creative concepts such as novel pets, uniquely designed jackets, and unconventional buildings by steering the generation away from conventional patterns using a VLM-Guided Adaptive Negative Prompting process."
- Adversarial examples: Outputs that satisfy quantitative constraints but fail to maintain semantic validity or functionality. "This happens because their optimization process maximizes the CLIP-space distance from negative concepts but can produce adversarial examples that satisfy mathematical constraints without maintaining semantic validity."
- Balance swap-sampling: A recombination technique that swaps elements of text embeddings to create novel blends and select results via CLIP distances. "For text-based concept pairs, \citet{Li_BASS_2024} suggested balance swap-sampling, which generates creative combinatorial objects by randomly exchanging intrinsic elements of text embeddings and selecting high-quality combinations based on CLIP distances."
- CLIP alignment: A validity metric assessing how well an image matches a text description in CLIP’s joint embedding space. "For validity, we employ CLIP alignment and GPT-4 verification."
- CLIP embedding space: The joint representation space where images and texts are embedded for similarity comparisons. "We evaluate creativity through both novelty and validity, using statistical metrics in the CLIP embedding space."
- Classifier-free guidance (CFG): A sampling technique that blends conditional and unconditional model predictions to control adherence to prompts. "For example, a known technique that attempts to navigate this tradeoff is Classifier-free guidance (CFG)."
- Closed-loop feedback mechanism: A guidance strategy that repeatedly analyzes intermediate outputs and feeds back control signals during generation. "Unlike previous approaches, our method operates entirely at inference time through a closed-loop feedback mechanism (Figure \ref{fig:overview})."
- Combinatorial creativity: Creating novelty by recombining existing concepts rather than discovering new ones. "At the lowest level, combinatorial creativity produces unexpected combinations of existing concepts, such as a hybrid creature that merges features of a bee and a giraffe."
- Compositional prompts: Detailed prompts that specify multiple constraints or components within a single description. "Moreover, unlike existing methods that primarily generate single objects, our approach extends to complex scenarios, such as generating coherent sets of creative objects and preserving creativity within elaborate compositional prompts."
- Concept blending: Combining multiple concepts (visual or textual) to synthesize new outputs. "Recent research leverages Vision-LLMs (VLMs) to guide creative generation. \citet{feng2025distributionconditional} uses VLMs to supervise distribution-conditional generation, enabling multi-class concept blending through a learnable encoder-decoder framework."
- Creative Text-to-Image (CT2I) generation: Framing creativity in T2I as optimizing text embeddings to discover novel yet valid concepts. "They formulate the Creative Text-to-Image (CT2I) generation as an optimization process of a learned textual embedding."
- Denoiser outputs: Intermediate model predictions during the denoising process, used for guidance or analysis. "our method monitors the intermediate denoiser outputs using a Vision-LLM (VLM), which identifies dominant elements (e.g., ``cat'') and accumulates them as dynamic negative prompts during the generation process."
- Denoising trajectories: The semantic paths taken by the model’s outputs through successive denoising steps. "Our analysis reveals how adaptive negative prompting guides the denoising trajectories toward unexplored semantic regions"
- Diffusion pipelines: End-to-end systems or frameworks for diffusion-based image generation. "Our method integrates seamlessly into existing diffusion pipelines, offering a practical route to producing creative outputs that venture beyond the constraints of textual descriptions."
- Diffusion sampler: The algorithmic procedure used to step through the denoising process during sampling. "we propose VLM-Guided Adaptive Negative-Prompting, a training-free method that integrates into any diffusion sampler without modifying pretrained weights or requiring curated datasets."
- Distribution-conditional generation: Conditioning generation on distributions over concepts rather than single labels or prompts. "\citet{feng2025distributionconditional} uses VLMs to supervise distribution-conditional generation, enabling multi-class concept blending through a learnable encoder-decoder framework."
- Embedding optimization: Adjusting textual or visual embeddings via optimization to meet creativity or alignment objectives. "Existing approaches to enhance generative creativity either rely on interpolation of image features, which restricts exploration to predefined categories, or require time-intensive procedures such as embedding optimization or model fine-tuning."
- Exploratory creativity: Discovering novel, valid possibilities within an existing category beyond simple recombination. "Exploratory creativity goes further by discovering new possibilities within a known domain while maintaining validity, for instance, inventing an animal species with entirely new but biologically plausible traits."
- Flow matching: A generative modeling technique that trains a velocity field and samples via integrating a probability flow ODE. "Latest diffusion models, including Stable Diffusion 3.5 ~\citep{esser2024scaling} used in our experiments, employ flow matching ~\citep{lipmanflow} to generate images through iterative denoising."
- Gaussian noise: The initial random noise sample from which diffusion models start their denoising process. "To generate a creative image (e.g., ``new type of pet''), we sample Gaussian noise and perform an augmented denoising process that maintains an adaptive list of negative prompts."
- Guidance scale: The scaling factor controlling how strongly the model adheres to the conditioning signal. "where is the guidance scale."
- Inference-time: Operations performed during sampling rather than training, enabling plug-and-play methods with pre-trained models. "We propose VLM-Guided Adaptive Negative-Prompting, a training-free, inference-time method that promotes creative image generation while preserving the validity of the generated object."
- Iterative optimization: Repeated updates to parameters (e.g., embeddings) to converge on creative objectives. "ConceptLab formulates creative generation as an iterative optimization problem over a learned textual embedding"
- Learnable token: A parameterized token trained to represent a concept like creativity within embedding space. "\citet{feng2024redefining} takes a different approach and re-defines ``creativity'' as a learnable token."
- Mode coverage: The aim of modeling the full variety of a distribution, including rare or atypical samples. "This limitation reflects an inherent tension in generative modeling between mode coverage (i.e., capturing the full distribution), and mode seeking (i.e., generating high-quality typical samples)."
- Mode seeking: Prioritizing high-quality, typical samples at the potential expense of diversity and novelty. "This limitation reflects an inherent tension in generative modeling between mode coverage (i.e., capturing the full distribution), and mode seeking (i.e., generating high-quality typical samples)."
- Negative prompting: Conditioning the model to steer away from specific undesirable concepts during generation. "negative prompting, in which the model is explicitly discouraged from generating features associated with a negative prompt ."
- Per-concept optimization: Running separate optimization procedures for each concept to achieve creativity or alignment. "These VLM-guided approaches rely on per-concept optimization procedures that require multiple iterations and substantial computational resources."
- Probability flow ODE: The differential equation governing the flow of samples from noise to data under flow matching. "The denoising process follows the probability flow ODE: ."
- Prompt adherence: The degree to which generated outputs match the given textual prompt. "higher scales improve prompt adherence but generate more typical outputs."
- Question-answering VLM: A VLM used to answer queries about images and add constraints or guidance dynamically. "ConceptLab incorporates a question-answering VLM that adaptively adds new constraints to the optimization problem."
- Relative typicality: A novelty metric comparing similarity to a target category versus similarity to known subcategories. "We refer to this measure as ``relative typicality''."
- Seed-specific guidance: Tailoring guidance to the random seed’s evolving output, rather than using a static negative list. "highlighting the importance of both timing and seed-specific guidance."
- Stable Diffusion 3.5: A state-of-the-art diffusion model used as a base in experiments. "Latest diffusion models, including Stable Diffusion 3.5 ~\citep{esser2024scaling} used in our experiments, employ flow matching ~\citep{lipmanflow} to generate images through iterative denoising."
- Text encoder: The component that transforms textual prompts into conditioning embeddings for the generative model. "conditioned on text embedding derived from prompt via text encoder ."
- Text-to-image (T2I) diffusion models: Generative models that synthesize images conditioned on textual prompts using diffusion processes. "Recent advances in text-to-image (T2I) diffusion models have demonstrated strong capabilities in generating photorealistic images from natural language prompts."
- Unconditional (null) embedding: The special embedding representing no conditioning, used in CFG to balance guidance. "where denotes the unconditional (null) embedding"
- Velocity field: The learned vector field that drives the transformation of noisy samples toward clean images. "In flow matching, the model learns a velocity field conditioned on text embedding derived from prompt via text encoder ."
- Vendi score: A diversity metric used to quantify variety in generated outputs. "For the diversity we measure Vendi score and total variance."
- Vision-LLM (VLM): A model jointly processing images and text to analyze and guide generation. "We leverage a lightweight vision-LLM (VLM) to adaptively steer the generation process away from its typical predictions"
Collections
Sign up for free to add this paper to one or more collections.