- The paper presents a taxonomy categorizing LLMs as tools, analysts, and scientists to illustrate their evolving roles in scientific discovery.
- The paper introduces iterative methodologies and benchmarks (e.g., IdeaBench, DiscoveryWorld) to assess LLM performance in hypothesis generation and data analysis.
- The findings highlight challenges in transparency, continuous self-improvement, and ethics, paving the way for future autonomous research advancements.
LLMs in Scientific Discovery: From Automation to Autonomy
This survey paper (2505.13259) examines the transformative role of LLMs in scientific discovery, focusing on their increasing autonomy and impact on research processes. It introduces a taxonomy that classifies LLMs' involvement in scientific tasks based on their level of autonomy: LLM as Tool, LLM as Analyst, and LLM as Scientist. The paper identifies challenges and future research directions, including robotic automation, self-improvement, and ethical governance.
Three Levels of LLM Autonomy
The authors propose a three-tiered taxonomy to categorize the roles of LLMs in scientific discovery based on their level of autonomy.
- LLM as Tool (Level 1): LLMs perform specific, well-defined tasks under direct human supervision, such as literature summarization or code generation.
- LLM as Analyst (Level 2): LLMs exhibit greater autonomy in processing complex information, conducting analyses, and offering insights with reduced human intervention.
- LLM as Scientist (Level 3): LLM-based systems autonomously conduct major research stages, from formulating hypotheses to interpreting results and suggesting new avenues of inquiry.
The paper argues that LLMs are progressing from Level 1 to Level 3, indicating a significant shift towards AI-driven autonomous scientific discovery.
LLMs at Level 1 function as tools, augmenting human researchers by automating discrete tasks within the scientific method.
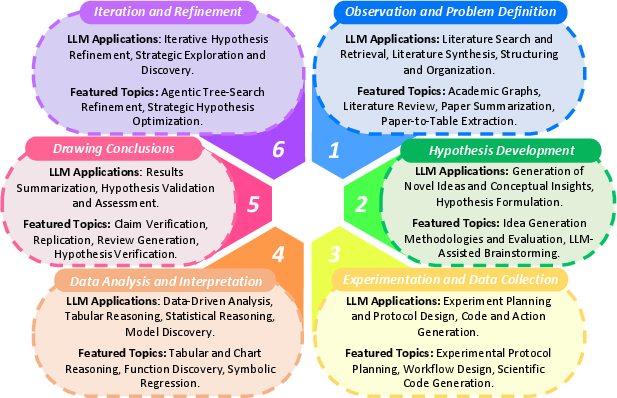
Figure 1: Stages of the scientific method with corresponding LLM applications and research topics.
These tasks include:
- Literature Review and Information Gathering: LLMs assist in literature search, retrieval, and summarization. Recent "Deep Research" products enhance literature web search, organization, and report generation.
- Idea Generation and Hypothesis Formulation: LLMs generate novel research ideas and hypotheses, with benchmarks like IdeaBench (Guo et al., 2024) evaluating their capability.
- Experiment Planning and Execution: LLMs aid in designing causal discovery experiments and generating code for AI research.
- Data Analysis and Organization: LLMs automate data organization, presentation, and analysis, including tabular and chart data processing.
- Conclusion and Hypothesis Validation: LLMs provide feedback on claims and conclusions, with research focusing on LLMs as reviewers for AI papers.
- Iteration and Refinement: LLMs iteratively refine research hypotheses using theorem provers and agent frameworks.
At Level 2, LLMs function as analysts, demonstrating greater autonomy in complex information processing and analytical reasoning. They can independently manage sequences of tasks within boundaries set by human researchers. Examples include:
- Automated Machine Learning (AutoML): LLMs are used in automated modeling of machine learning tasks, with frameworks like IMPROVE (Xue et al., 25 Feb 2025) emphasizing iterative refinement.
- Data Modeling and Analysis: LLMs assist in statistical data modeling and hypothesis validation, with benchmarks like BLADE (Gu et al., 2024) improving evaluation robustness.
- Function Discovery: LLMs enhance function discovery by leveraging prior domain knowledge and incorporating feedback from clustered memory storage.
- Natural Science Research: LLMs are applied to autonomous research workflows for natural science discovery, such as in the biomedical domain with BioResearcher (Luo et al., 2024).
- General Research: Benchmarks like DiscoveryWorld (Jansen et al., 2024) evaluate LLMs on diverse tasks from different stages of scientific discovery.
LLM as Scientist: Autonomous Research Navigation
Level 3 signifies a leap in autonomy, where LLM-based systems operate as scientists, capable of orchestrating and navigating multiple stages of the scientific discovery process with considerable independence. These systems can formulate hypotheses, plan and execute experiments, analyze data, and propose new research questions. Agent Laboratory (Schmidgall et al., 8 Jan 2025) and AI Scientist (Lu et al., 2024) are examples of systems capable of autonomously producing research outputs.
Iterative refinement involves sophisticated feedback loops that enable not just incremental improvements but also fundamental reassessments of the research trajectory. AI Scientist (v1 and v2) incorporates highly automated internal review and refinement processes. Zochi [Intology2025Zochi] integrates human expertise for macro-level guidance, where feedback can trigger complete re-evaluations of hypotheses or designs.
Challenges and Future Directions
The paper identifies several challenges and future directions for LLM-based scientific discovery:
- Fully-Autonomous Research Cycle: Developing LLM-based systems capable of engaging in a truly autonomous research cycle, discerning implications, and identifying subsequent investigations.
- Robotic Automation: Integrating LLMs with robotic systems to enable physical laboratory experiments and broaden research in fields requiring physical interaction.
- Transparency and Interpretability: Moving towards systems designed for verifiable reasoning and justifiable conclusions, ensuring the AI's internal logic aligns with scientific principles.
- Continuous Self-Improvement: Incorporating online reinforcement learning frameworks to enable systems to learn from ongoing engagement and adapt research strategies.
- Ethics and Societal Alignment: Embedding ethical constraints directly in scientific AI design frameworks, ensuring advancements serve human well-being and the common good.
Taxonomy of LLM-Based Scientific Discovery
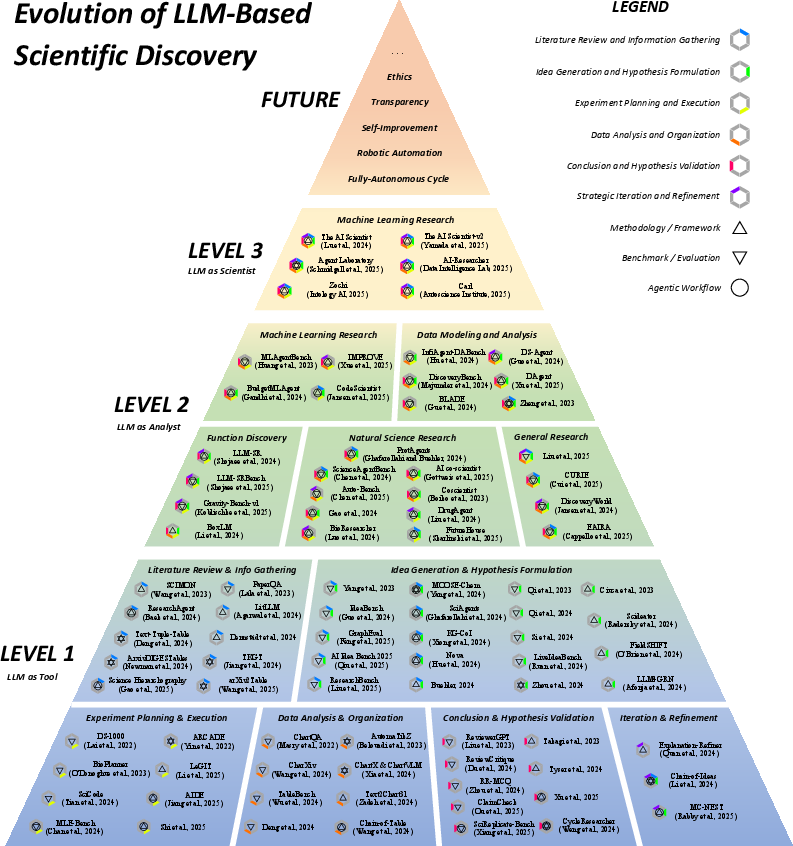
Figure 2: Taxonomy of research works in LLM-based scientific discovery with detailed categorization.
The paper consolidates 90 research works within the scope of the three levels of autonomy (Figure 2).
Conclusion
The survey concludes that LLMs are significantly impacting scientific discovery, evolving from simple automation tools to increasingly autonomous agents. Addressing the identified challenges and pursuing the outlined future directions will be crucial for realizing the full potential of AI as a transformative partner in scientific exploration.