LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Abstract: Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of LLMs due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LiveOIBench, a new way to test how good LLMs are at solving tough coding problems from real Informatics Olympiads (think national and international programming competitions). The goal is to see if LLMs can beat top human contestants and to measure their coding and reasoning skills fairly and accurately.
Key Questions
To make this clear and simple, the paper asks:
- Can modern LLMs solve Olympiad-level coding problems as well as top human competitors?
- How should we test LLMs so the results are reliable (not fooled by weak tests or missing data)?
- What kinds of problems do LLMs do well on, and where do they struggle?
- How does giving a model more “thinking time” or more attempts change its performance?
How LiveOIBench Works
Here’s the approach, explained with everyday ideas:
- Collecting problems: The authors gathered 403 real competition problems from 72 Olympiads (from 2023–2025). These are challenging, carefully made puzzles with strict rules, like the ones contestants face in official events.
- Strong test cases: Each problem comes with many hidden “test cases” (on average 60 per problem). Think of test cases as secret quizzes that check if a solution really works, including tricky edge cases. Using official test sets cuts down on false positives (where a model “seems” correct but isn’t).
- Offline judging: They built a local “judge”—a program you can run without connecting to an online platform—to automatically check solutions. This makes results easy to reproduce and accessible for everyone.
- Human comparisons: The team also collected actual rankings of human contestants, and matched many to their Codeforces ratings (a common skill score in competitive programming). This lets them compare models to humans using percentiles (for example, “better than 80% of contestants”) and medal thresholds (Bronze/Silver/Gold).
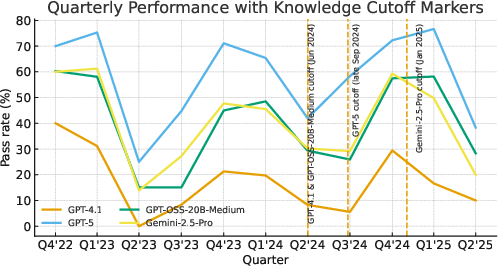
- Clean updates: They only use recent problems and plan ongoing additions straight from Olympiad websites to avoid “contamination” (models accidentally seeing the answers during training).
- Making problem text usable: Many problems were PDFs, so they converted them to clean text (markdown) and checked accuracy with tools and manual review.
Main Findings
Here are the big results and why they matter:
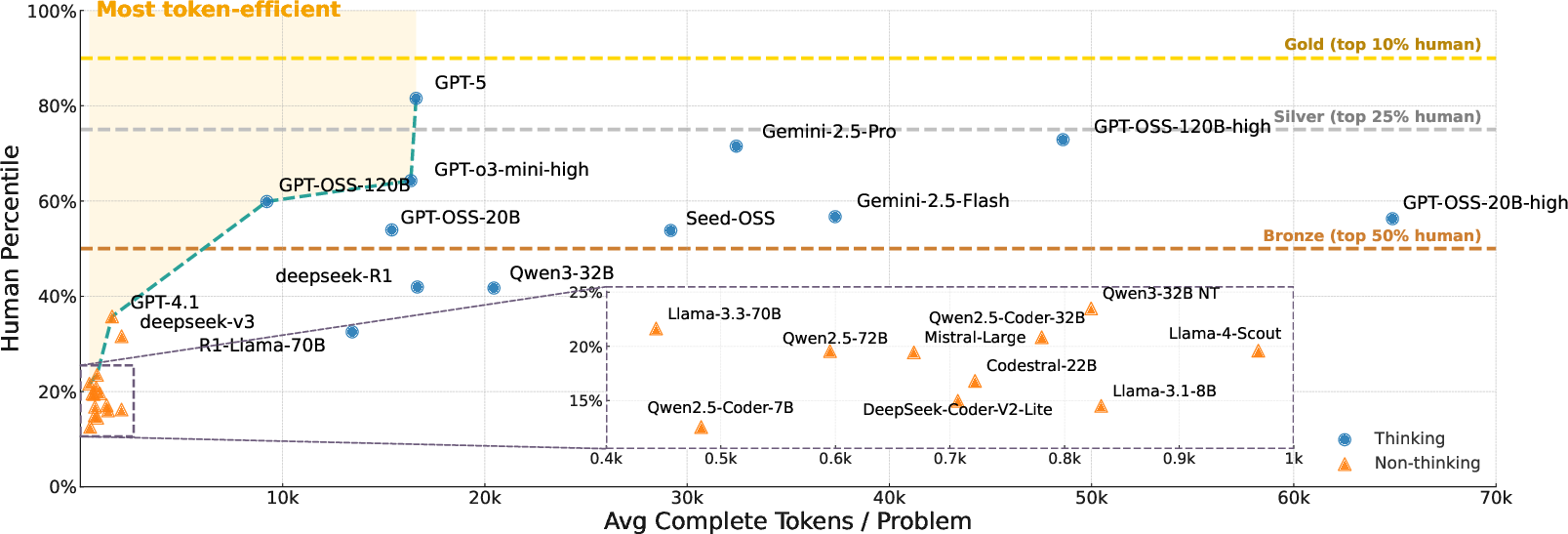
- Strong but not superhuman: The best model they tested, GPT-5, scored around the 82nd percentile—meaning it performed better than about 82% of human contestants. That’s very good, but still below top-tier “gold medal” humans, who often score above the 90th percentile.
- Open-source models are improving: The strongest open-weight reasoning model (GPT-OSS-120B) reached about the 60th percentile, closer to GPT-5 than earlier open models. This shows rapid progress in the open community, though a gap remains.
- “Thinking” helps a lot: Models that generate longer, more structured reasoning (“thinking models”) do much better than those that keep answers short. In other words, when a model is allowed to plan, analyze, and verify carefully, it solves more problems.
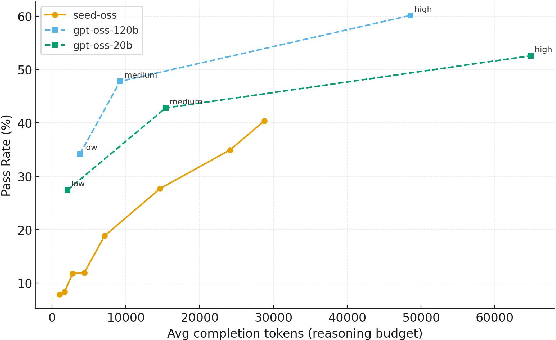
- More attempts and more time help—but not endlessly: Trying multiple solution attempts per problem increases success (like taking several shots at a goal). Giving a model more “reasoning tokens” (more internal thinking) also helps, especially for smaller models. But after a certain point, returns diminish.
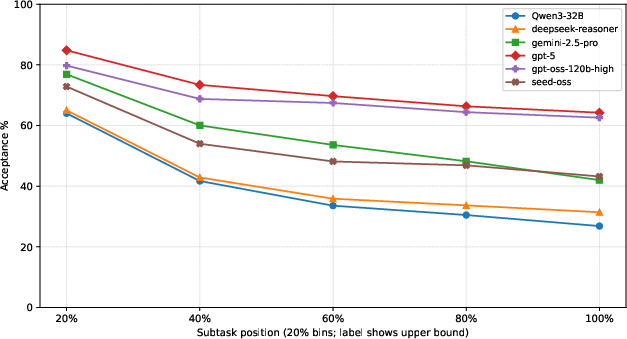
- What models do well vs. struggle with: LLMs are better at problems with standard patterns (like sorting, graph traversal, basic math, and implementation). They struggle more with dynamic programming, trees, and segment trees—these require creative insight, designing states, and layered reasoning.
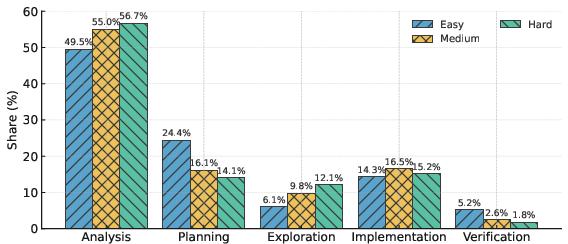
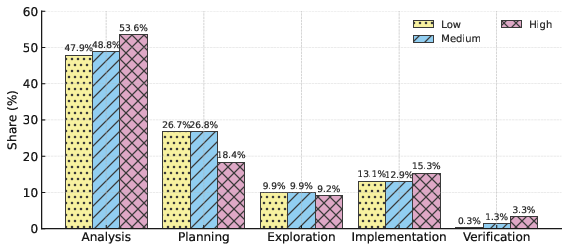
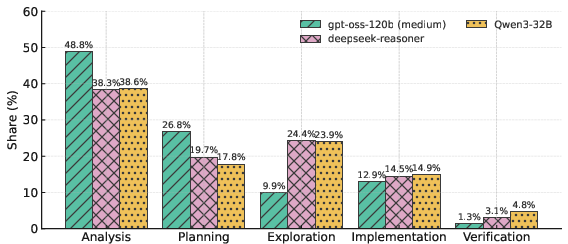
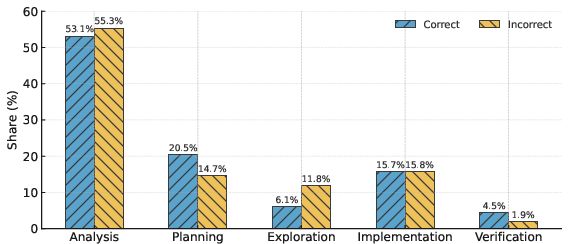
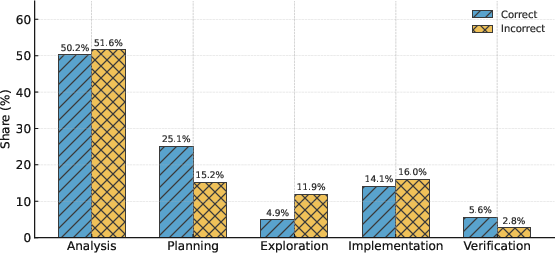
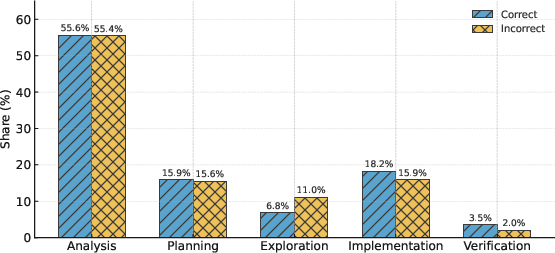
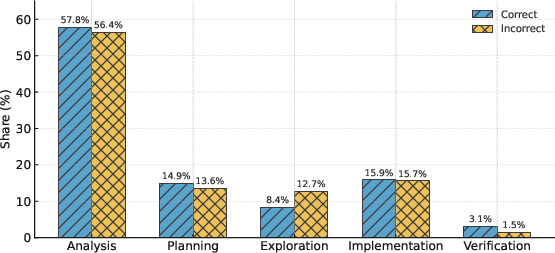
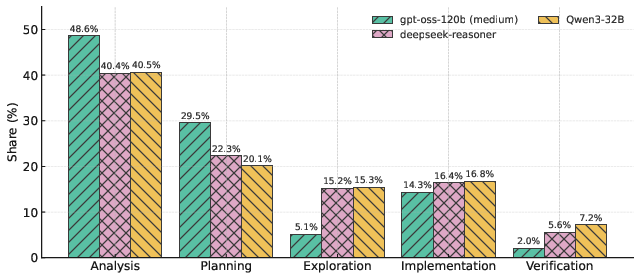
- Smart behavior matters: Stronger models spend their “thinking time” wisely. They focus on clear analysis and planning, and avoid too much aimless exploration. Correct solutions often start with solid planning and finish with verification (checking examples), instead of wandering around trying many random ideas.
- Error types: As models get better, they make fewer compile errors and fewer time/memory limit issues. However, runtime errors (like crashes on tricky inputs) still happen—often because more advanced, performance-optimized code is also easier to break on edge cases.
Why This Matters
LiveOIBench addresses key problems in older coding tests:
- It uses official, tough problems with strong hidden tests, making results more trustworthy.
- It compares models to real human performance, not just pass/fail counts, giving clearer context (percentiles, medals, ELO).
- It’s easy to run offline and is kept up-to-date, which helps researchers and developers track progress fairly over time.
The findings show that LLMs are getting very good at competitive programming, but still have ground to cover to consistently beat top human contestants—especially on problems that require creative, multi-step reasoning.
Final Thoughts
This benchmark gives the community a fair, challenging, and practical way to measure coding intelligence in LLMs. It suggests future models should:
- Emphasize structured analysis and planning, not just more exploration.
- Train specifically on harder algorithmic skills (like dynamic programming and tree problems).
- Balance speed with robustness, reducing runtime errors by handling edge cases more carefully.
If these improvements continue, we could see models that reliably perform at or above gold-medal human levels—and tools that help more people learn, practice, and solve complex coding problems effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research and benchmark development:
- Dataset coverage and bias
- Quantify geographic and linguistic bias introduced by selecting only English-available Olympiad problems; assess how exclusion of non-English tasks affects algorithm/topic distribution and difficulty.
- Report representativeness across the 14 Olympiads (per-contest counts, difficulty profiles, topic mix) and analyze whether certain regions/organizers dominate the dataset.
- Test case release, privacy, and contamination
- Clarify the apparent contradiction between “private tests” and “publicly available” release; define what remains private versus public and how future updates remain contamination-free once released.
- Establish and evaluate a contamination-prevention protocol (e.g., hidden holdout splits, rotating sequestered testbeds, delayed releases) and implement leakage detection (e.g., editorial/code near-duplicate checks, solution string-matching to web corpora).
- Legal and ethical constraints
- Provide explicit licensing/permissions for redistributing official test cases, checkers, and statements from Olympiad organizers; address legal constraints and usage terms for academic vs. commercial use.
- Evaluation environment fidelity
- Specify supported languages, compiler versions/flags (e.g., g++ -O2/-O3, C++ standard), runtime environments, OS, and sandboxes; document how these align with original contest judges.
- Calibrate time/memory limits to official contests (hardware normalization or scaling factors) to avoid artificial TLE/MLE differences; publish calibration methodology and validation metrics.
- Clarify treatment of interactive/output-only/approximate tasks and checker-based problems; state which categories were excluded and why, and provide support plans or benchmarks for them.
- Comparability with human contestants
- Address fairness gaps: models are evaluated with best-of-8 selection and flexible compute, while humans have strict time/attempt constraints; introduce single-shot and time-bounded settings to approximate human conditions.
- Detail whether model submissions incur penalties or limits as in real contests; consider per-contest attempt caps and time budgets to improve comparability.
- Methodological transparency and reproducibility
- Release full decoding hyperparameters (temperature, top-p, stop criteria), seed control, and sampling policies across models; report sensitivity analyses and confidence intervals for aggregate metrics.
- Normalize “completion tokens per problem” across tokenizer families/providers or provide a cross-model token normalization scheme; otherwise token-efficiency comparisons may be confounded.
- Metric design and normalization
- Justify cross-contest comparability of human percentiles and medals given varying participant pools and problem counts; investigate weighting schemes or per-contest normalization to mitigate skew.
- Detail how subtask weights differ across Olympiads and whether a normalization layer is applied; study how subtask heterogeneity affects relative score and pass-rate comparability.
- Document the ELO derivation for models and sensitivity to contest mix and human pool size; validate that the adapted ELO is stable and interpretable across time and domains.
- Test adequacy and residual false positives
- Empirically measure residual false-positive rates despite “official” tests (e.g., via fuzzing, mutation-based augmentation, adversarial generators) to validate the sufficiency of released test suites.
- Quantify test coverage (input space coverage, corner-case density) per problem and correlate with observed pass@k to identify under-tested tasks.
- Contamination analysis and detection
- Move beyond time-split trends; implement automated contamination checks (e.g., editorial/code retrieval matching, hash/AST similarity to public repositories) and publish contamination findings per task/model.
- Reasoning trace analysis validity
- Report sample sizes, selection criteria, and inter-annotator reliability for reasoning-behavior labels; include human validation instead of relying solely on a model annotator to avoid circularity and bias.
- Test causal interventions derived from the analysis (e.g., structured-plan-first prompting, exploration constraints, built-in verification) to validate whether the observed correlations improve performance.
- Error analysis depth
- Substantiate the runtime-error hypothesis (due to aggressive optimizations) with code-level mining (e.g., static/dynamic analysis of pointer misuse, bounds checks, custom DS bugs); quantify error type by algorithm tag and language.
- Provide per-language error breakdowns (compilation/runtime/TLE/MLE) and tie them to environment constraints (compiler flags, memory allocators, recursion limits).
- Human contestant data linkage
- Quantify and audit error rates in Codeforces profile matching (name collisions, transliteration issues); report the fraction of unmatched contestants and potential bias in ELO/percentile comparisons.
- Language and tool use scope
- Specify whether Python or other high-level languages are allowed and how their performance is affected by stricter time limits typical of OI; study language-choice effects on pass rates and TLE/MLE.
- Evaluate tool-augmented settings (self-debug loops, compiler-feedback agents, unit-test generation, retrieval-augmented editorial fragments) to map headroom beyond single-pass code generation.
- Robustness and reliability
- Provide variance estimates across multiple evaluation runs (different seeds/samples) for each model; include confidence bands for pass@k, percentile, and ELO to assess stability.
- Investigate how results shift with different numbers of samples (k), different prompting templates, and different repair strategies; report diminishing returns points per model.
- Cross-benchmark generalization
- Measure correlation between LiveOIBench rankings and other coding/reasoning benchmarks (e.g., Codeforces live contests, SWE-Bench, CodeContests) to test external validity and domain transfer.
- Security and sandboxing
- Document sandboxing, syscall restrictions, and resource isolation for executing untrusted model code; audit for risks like file system probing, fork bombs, or side-channel exploits.
- Leaderboard governance
- Define policies for submission frequency, overfitting/benchmark gaming detection, and model versioning (API drift); consider hidden test rotations and audit trails to preserve leaderboard integrity over time.
- Token/compute efficiency
- Report standardized compute and energy cost per problem (tokens, wall-clock, GPU hours) to support fair efficiency comparisons, not just token counts; include cost–performance trade-off curves.
- Data curation pipelines
- Expand beyond the 40-task manual spot-check for PDF-to-markdown conversion; quantify residual conversion errors and their impact on misinterpretations or I/O format bugs.
- Algorithm tagging validity
- Validate the reliability of external tags (solved.ac, Luogu) for OI tasks and resolve inconsistencies; account for multi-tag problems and control for difficulty when comparing tag-specific pass rates.
- Future dataset extensions
- Plan inclusion and evaluation protocols for interactive, output-only, and approximate-checker tasks (with checker programs); these are common in Olympiads but currently under-specified or excluded.
- Calibration and abstention
- Evaluate model calibration (e.g., confidence of acceptance, abstention strategies) and contest-level risk-aware decision-making (when to skip or invest more reasoning) to emulate human test-taking strategies.
Practical Applications
Below is an overview of practical applications enabled by the paper’s benchmark, methods, and empirical insights. Each item includes the target sector(s), indicative tools/products/workflows, and feasibility notes.
Immediate Applications
The following applications can be deployed now using the released benchmark, judge, rubrics, and analyses.
- Vendor-neutral evaluation and model selection for coding LLMs
- Sector: Software, Platforms, AI/ML Ops
- What: Adopt LiveOIBench’s offline judge and human percentile/Elo metrics as a standardized gating suite for model releases, A/B tests, and procurement. Compare models on token efficiency and medal/percentile to select the most cost-effective model for coding features.
- Tools/Workflows: CI pipeline step invoking the local judge; dashboards tracking pass rate, relative score, human percentile, Elo over time.
- Dependencies/Assumptions: License/redistribution compliance for tasks; secure sandboxing of untrusted code; representative language support (e.g., C++/Python/Java).
- Regression testing and quality assurance for coding copilots/agents
- Sector: Software engineering, DevTools
- What: Nightly and pre-release regression runs against a stable subset of LiveOIBench with subtask-level scoring to catch quality regressions and “false-positive” overfitting to weak tests.
- Tools/Workflows: Pass@k sweeps, subtask-delta tracking, failure-type distribution (TLE/MLE/RE/CE) reports.
- Dependencies/Assumptions: Stable hardware budgets for repeated runs; pinning of dataset versions to ensure comparability.
- Fine-grained capability diagnostics by algorithm family
- Sector: R&D, Model training teams, EdTech
- What: Use the rich metadata (tags: DP, graphs, trees, greedy, etc.) and subtask rubrics to produce capability heatmaps, identify systematic weaknesses (e.g., dynamic programming and hierarchical invariants), and guide targeted data augmentation or instruction-tuning.
- Tools/Workflows: Tag-based analytics, curriculum selection, targeted unit generation for weak tags.
- Dependencies/Assumptions: Sufficient coverage in each tag; careful train/eval split to avoid leakage.
- Token-efficiency tuning and inference-time budget policies
- Sector: AI platform engineering, Cost optimization
- What: Operationalize findings that top models allocate tokens to structured analysis over exploration. Implement adaptive reasoning budgets (e.g., early exit on easy subtasks, expanded analysis on hard tags) to improve cost/performance.
- Tools/Workflows: Policy controllers that adjust temperature, max tokens, and sampling count by detected difficulty/tag; token-per-pass dashboards.
- Dependencies/Assumptions: Reliable difficulty estimators; consistent behavior across model versions.
- Hiring and skills benchmarking with human-referenced metrics
- Sector: Talent assessment (tech, finance, big tech), Interview platforms
- What: Use contest-like tasks with medal/percentile mapping to standardize candidate coding assessments, and compare human candidate scores to LLM baselines where appropriate.
- Tools/Workflows: A calibrated “Elo-to-level” mapping and contest bundles for interviews.
- Dependencies/Assumptions: Fairness and accessibility considerations; avoid leakage if candidates have prior exposure to specific Olympiad tasks.
- Training camps and competitive programming practice portals
- Sector: Education, EdTech, STEM outreach
- What: Build practice platforms offering subtask-based partial credit, official tests, and percentile feedback relative to real contestants; add per-tag analytics to tailor study plans.
- Tools/Workflows: Learning dashboards, tag-based drills, progress tracking vs. historic human distributions.
- Dependencies/Assumptions: Content licensing; multilingual support; student privacy and safe code execution.
- Benchmarks for public disclosures and investor diligence
- Sector: Policy/Regulation, Investment analysis
- What: Include LiveOIBench results (human percentile, medal rate, Elo, token efficiency) in model cards or due-diligence reports to communicate real-world coding competence and efficiency.
- Tools/Workflows: Standardized scorecards appended to release notes and risk reports.
- Dependencies/Assumptions: Transparent, reproducible runs; clear description of sampling strategy and budgets.
- Safer offline evaluation for institutions with strict compliance
- Sector: Government, Healthcare, Finance (regulated)
- What: Run evaluations entirely offline to avoid external APIs while using expert-curated private tests that reduce false positives—suited for restricted networks.
- Tools/Workflows: Air-gapped evaluation servers; containerized sandboxes.
- Dependencies/Assumptions: Secure isolation to execute untrusted code; vetted language/toolchain versions.
- Failure-mode audits to reduce runtime and boundary-condition errors
- Sector: DevTools, Quality Engineering
- What: Use submission-status breakdowns (CE/TLE/MLE/RE/WA) to add static analysis, fuzzing, and boundary-case probes to agent workflows; train agents to internalize verification.
- Tools/Workflows: Post-generation static analysis; targeted test injection for likely failure classes (e.g., off-by-one, overflow).
- Dependencies/Assumptions: Language-specific analyzers; reliable mapping from failure types to remediation.
- Data pipeline replication for other domains with PDF-only artifacts
- Sector: Academic benchmarking, Data engineering
- What: Reuse the PDF-to-Markdown conversion + LLM verification workflow to convert problem sets/tutorials in other areas (e.g., math contests, ICPC) into benchmark-ready corpora.
- Tools/Workflows: Marker-based conversion, automated consistency checks, human spot audits.
- Dependencies/Assumptions: Source quality and formatting consistency; copyright and redistribution permissions.
- Cross-model, multi-metric leaderboards to prevent metric gaming
- Sector: Open-source communities, Evaluation hubs
- What: Publish leaderboards including medal rates, human percentile, Elo, pass rate, and relative score to discourage over-optimizing any single metric.
- Tools/Workflows: Leaderboard hosting; standardized run-scripts; periodic contamination checks.
- Dependencies/Assumptions: Community norms on reporting budgets (k-samples, tokens).
- Curriculum-building via subtasks for self-learners
- Sector: Daily life, EdTech
- What: Learners use subtask progression (constrained -> general) to scaffold mastery; the rubric offers immediate partial credit feedback.
- Tools/Workflows: Personal study plans keyed to tag difficulty; progress journals.
- Dependencies/Assumptions: Clear explanations for subtasks; availability in learner’s preferred language.
Long-Term Applications
These applications likely require further research, scaling, productization, or standardization.
- Certification standards for AI coding systems
- Sector: Policy/Regulation, Safety, Procurement
- What: Define thresholds (e.g., ≥90th human percentile on fresh Olympiad tasks) for permitting autonomous code changes in regulated environments.
- Tools/Workflows: Independent test labs; versioned, contamination-controlled test suites.
- Dependencies/Assumptions: Broad stakeholder agreement; periodic refresh to avoid overfitting.
- Adaptive reasoning controllers that balance planning vs. exploration
- Sector: AI systems, Inference optimization
- What: Train/run-time controllers that route tokens toward structured problem analysis and away from excessive pivoting; integrate planning-first decoding modes.
- Tools/Workflows: Behavior-aware decoders; token-allocation policies; feedback loops from reasoning-trace classifiers.
- Dependencies/Assumptions: Robust trace labeling; generalization across models/tasks.
- Subtask-based reinforcement learning and curriculum for hard algorithms
- Sector: Model training, Research
- What: Use subtask scoring as dense rewards to improve DP, tree, and segment tree competence; generate synthetic curricula aligned to these structures.
- Tools/Workflows: RLHF/RLAIF with subtask rewards; synthetic problem generators targeting hierarchical invariants.
- Dependencies/Assumptions: Avoiding contamination; reliable alignment between synthetic and real problem distributions.
- Diagnostic AI tutors that pinpoint algorithmic weaknesses
- Sector: EdTech, Upskilling
- What: Tutors infer specific misconceptions (e.g., recurrence design in DP) from subtask outcomes and reasoning traces, then assign interventions and micro-lessons.
- Tools/Workflows: Tag-aware error taxonomy; adaptive lesson planning; spaced repetition by tag.
- Dependencies/Assumptions: High-quality pedagogy; privacy and safe code execution for minors.
- Human–AI hybrid coding teams with role-specialized reasoning
- Sector: Software, Enterprise engineering
- What: Orchestrate agents that handle planning/analysis vs. implementation/verification separately, mirroring behaviors correlated with correct solutions.
- Tools/Workflows: Multi-agent schedulers; division-of-labor protocols; shared scratchpads.
- Dependencies/Assumptions: Reliable coordination costs; latency vs. quality trade-offs.
- Transfer of the LiveOI methodology to adjacent domains
- Sector: Science/Math, Formal methods, Robotics
- What: Build “Live” benchmarks with expert private tests and human percentiles for math Olympiad problems, theorem proving, or robotics planning.
- Tools/Workflows: Domain-specific judges; hardware-in-the-loop for robotics; proof checkers for math/logic.
- Dependencies/Assumptions: Access to official tests; robust offline simulators/checkers.
- Static-analysis–aware code generation to curb runtime errors
- Sector: DevTools, Security
- What: Train models (and build compilers/linters) to preempt common runtime failures observed in the benchmark (e.g., bounds, nulls, overflow) before execution.
- Tools/Workflows: Hybrid static/dynamic analyzers; code transformation passes; verification-aware decoding.
- Dependencies/Assumptions: Language/toolchain coverage; minimizing false positives.
- Token-efficiency metrics as first-class objectives in training
- Sector: Model training, Cost engineering
- What: Incorporate “percentile-per-token” or “medal-per-dollar” as training/evaluation targets to develop cost-effective reasoning models for production use.
- Tools/Workflows: Multi-objective optimization; budget-aware reward functions.
- Dependencies/Assumptions: Stable cost baselines; consistent token accounting across providers.
- National training programs and equitable access via offline judging
- Sector: Education policy, Public sector
- What: Deploy offline judges to underserved regions/schools to enable high-quality algorithmic training without internet or platform dependencies.
- Tools/Workflows: Prepackaged datasets; low-spec local servers; teacher dashboards.
- Dependencies/Assumptions: Localization; sustainable maintenance and updates.
- Continuous evaluation for AI governance and capability monitoring
- Sector: Policy/Standards, Research
- What: Use contamination-controlled, continuously updated contests to track capability trends and detect regressions or abrupt advances in coding reasoning.
- Tools/Workflows: Rolling cohorts; time-sliced scorecards; anomaly detection.
- Dependencies/Assumptions: Trusted update pipeline; transparent release notes.
- Marketplace norms for reporting multi-metric performance
- Sector: Ecosystem/Standards
- What: Encourage model cards that include medal rate, human percentile, Elo, pass@k curves, and reasoning-effort settings to prevent metric gaming.
- Tools/Workflows: Community checklists; third-party verification.
- Dependencies/Assumptions: Broad adoption by vendors and journals.
- Cross-domain “reasoning behavior” telemetry for safety and reliability
- Sector: Safety, Critical systems
- What: Generalize the behavior taxonomy (planning, analysis, exploration, verification) to monitor under/over-thinking modes in high-stakes applications (e.g., automated triage, scheduling).
- Tools/Workflows: Telemetry hooks; behavior classifiers; policy interventions.
- Dependencies/Assumptions: Privacy/compliance constraints; validated correlations with reliability.
These applications leverage LiveOIBench’s unique assets—expert-curated private tests, subtask rubrics, human percentile/Elo alignment, contamination-aware live updates, offline evaluation, and reasoning-trace insights—to improve real-world reliability, cost-efficiency, transparency, and pedagogy in coding-focused AI systems.
Glossary
- ad-hoc: A competitive programming tag for problems solved by case-specific reasoning rather than standard algorithms. "Abbreviations: IM (implementation), MA (mathematics), AH (ad-hoc), PS (prefix sum), SO (sorting), GR (greedy), GTR (graph traversal), BS (binary search), NT (number theory), GT (graph theory), DS (data structures), CB (combinatorics), DP (dynamic programming), TR (tree), ST (segment tree)."
- AetherCode: A contemporary coding benchmark used to evaluate LLMs on competitive programming tasks. "AetherCode uses LLM-generated tests and extensive human annotation with pass rate evaluation only."
- Codeforces API: The programmatic interface for accessing Codeforces user and contest data. "Verified profiles are then queried via the Codeforces API to retrieve user ratings from 2022 to 2025."
- Codeforces Elo: An Elo-style rating adapted to competitive coding performance on Codeforces. "Elo: the Codeforces Elo rating earned by a model based on performance relative to human contestants."
- Contamination-free updates: Benchmark updates designed to avoid training-data leakage from newly added problems. "Continuous, Contamination-free Updates."
- curriculum-driven fine-tuning: A training approach that sequences tasks from easier to harder to improve reasoning skills. "future work could explore curriculum-driven fine-tuning"
- data contamination: Leakage of benchmark content into model training data that can inflate evaluation results. "minimize data contamination risks"
- evaluation judge: The automated system that compiles, runs, and scores submissions against test cases. "We develop a self-contained evaluation judge, enabling fully offline and reproducible model evaluation without relying on external APIs or online platforms, significantly enhancing accessibility and reproducibility."
- false-positive rate: The proportion of solutions that appear correct due to incomplete tests but are actually wrong. "overestimation of LLMs' performance due to high false-positive rates using incomplete test suites"
- Gold medal threshold: The performance cutoff (typically top 10%) corresponding to a gold medal in Olympiad contests. "remain below the Gold medal threshold (top $10$\% human performance)"
- hierarchical invariants: Multi-level properties that remain consistent across steps in an algorithm, often crucial in DP and tree reasoning. "hierarchical invariants, and compositional reasoning patterns"
- Human Percentile: A metric indicating the percentage of human contestants a model outperforms. "Human Percentile: \% of human contestants that a model surpasses."
- inference-time scaling: Techniques that improve model performance by expanding reasoning or sampling at inference (without retraining). "as these models continue advancing through inference-time scaling techniques"
- Informatics Olympiads: Competitive programming contests (e.g., IOI, national OIs) featuring algorithmic problems under time/memory limits. "The problems are sourced directly from $72$ official Informatics Olympiads in different regions conducted between $2023$ and $2025$."
- Olympics medal system: An evaluation framing that maps model scores to medal tiers (gold/silver/bronze) akin to Olympiad awards. "We adopt the following evaluation metrics: pass rate, relative score, human percentile, Olympics medal system, and Codeforces Elo"
- open-weight: Refers to models whose parameters are publicly available for research and deployment. "In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile"
- parallel scaling: Increasing the number of sampled solutions per problem to boost success probability. "In Figure~\ref{fig:plot1}, parallel scaling identifies maximum coding capacity but shows diminishing returns beyond a few attempts."
- Pass@k: The probability that at least one of k generated solutions passes all tests. "Parallel Scaling displays the Pass@k performance, illustrating how the success rate improves as more solutions (k) are sampled per problem."
- partial scoring: Awarding points for solving easier subtasks or subsets of constraints within a problem. "enabling precise evaluation through partial scoring."
- private test cases: Hidden, organizer-provided tests that prevent overfitting and reduce false positives. "The lack of sufficient private test cases may cause many false-positive solutions"
- reasoning budget: The allocation of tokens/steps for analysis and planning during inference. "While sequential scaling, by increasing the reasoning budget, allows smaller models to approach larger-model performance"
- reasoning tokens: Tokens expended by a model on internal analysis and planning before producing final code. "reaching this performance with fewer than 20K reasoning tokens"
- Relative Score: The percentage of total contest points a model earns relative to the maximum. "Relative Score: \% of total contest points obtained by the model."
- sequential scaling: Improving performance by giving the model more time/tokens for deeper step-by-step reasoning. "While sequential scaling, by increasing the reasoning budget, allows smaller models to approach larger-model performance"
- segment tree: A tree-based data structure supporting range queries and updates in logarithmic time. "ST (segment tree)"
- Subgoal Setting: A reasoning behavior where the model defines intermediate targets to structure the solution. "Planning (Problem Restatement and Subgoal Setting)"
- subtask rubrics: Detailed scoring guidelines tied to problem subtasks that enable fine-grained evaluation. "detailed subtask rubrics"
- token-efficiency frontier: The trade-off boundary showing maximal performance for a given number of tokens. "OpenAI models lie on the token-efficiency frontier"
- underthink: A failure mode where the model pivots excessively or reasons too shallowly, hurting correctness. "or ``underthink''"
- USACO: The USA Computing Olympiad, a prominent competitive programming contest series. "exclusively used USACO problems with pass rate as the sole evaluation metric."
Collections
Sign up for free to add this paper to one or more collections.

