- The paper introduces FIPER, a framework that predicts runtime failures in generative robot policies without requiring failure data.
- It employs random network distillation to detect out-of-distribution observations and a novel action-chunk entropy score to quantify action uncertainty.
- Experimental results demonstrate FIPER's superior accuracy and lower false positives compared to state-of-the-art baselines in diverse simulation and real-world tasks.
Failure Prediction at Runtime for Generative Robot Policies: A Technical Analysis
Introduction and Motivation
Generative imitation learning (IL) policies, particularly those based on diffusion and flow matching models, have enabled robots to execute complex, long-horizon tasks by learning from multimodal demonstration data. Despite advances in generalization and robustness, these policies remain susceptible to unpredictable failures due to distribution shifts and compounding action errors, especially in unseen or dynamic environments. The inability to reliably predict such failures during runtime poses significant safety risks in human-centered and safety-critical applications.
This paper introduces FIPER (Failure Prediction at Runtime), a framework for early and accurate failure prediction in generative robot policies without requiring failure data. FIPER leverages two key signals: (i) consecutive out-of-distribution (OOD) observations detected via random network distillation in the policy’s observation embedding space (RND-OE), and (ii) persistently high uncertainty in generated actions quantified by a novel action-chunk entropy score (ACE). Both signals are calibrated using conformal prediction on a small set of successful rollouts, enabling robust, task-agnostic failure prediction.
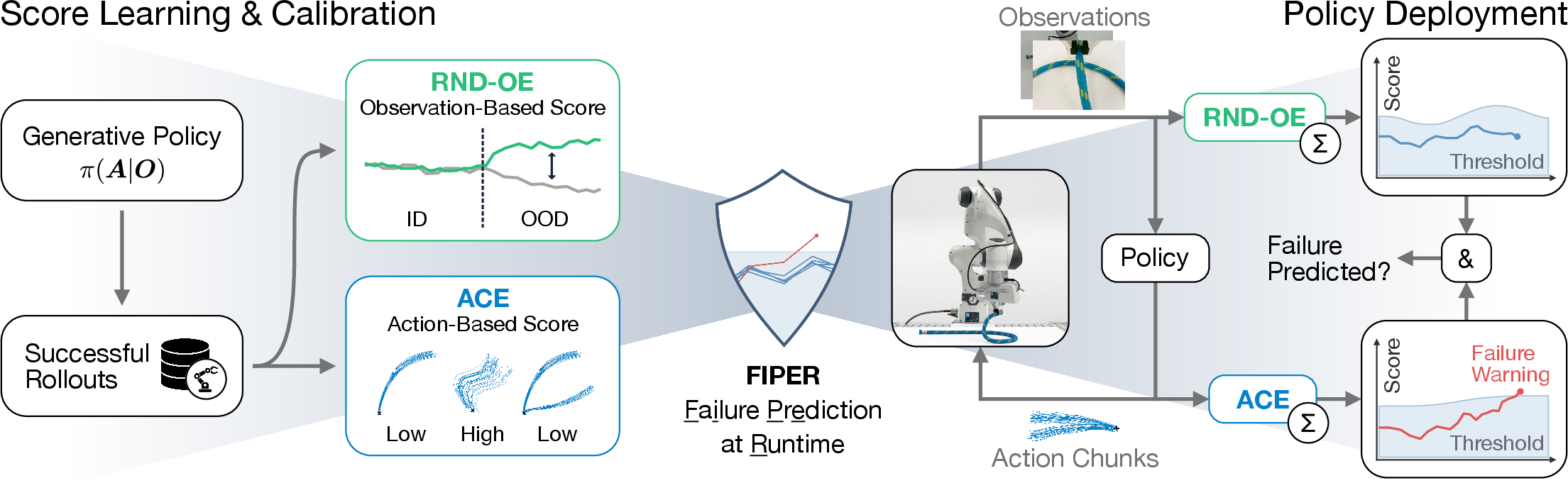
Figure 1: FIPER architecture: runtime prediction of task failures by combining RND-OE and ACE signals, calibrated on successful rollouts and aggregated over a sliding window.
Methodology
Out-of-Distribution Detection via RND-OE
FIPER employs random network distillation (RND) in the policy’s observation embedding space to detect OOD states. The RND module consists of a frozen, randomly initialized target network and a trainable predictor network, both operating on the policy’s observation embeddings. The predictor is trained to match the target’s output on in-distribution (ID) data. At runtime, the L2 distance between the predictor and target outputs serves as the RND-OE score, indicating the novelty of the current observation relative to successful rollouts.
To enhance robustness, FIPER aggregates RND-OE scores over a sliding window of recent timesteps, capturing the compounding effect of consecutive OOD observations. A calibrated threshold, computed via conformal prediction, determines when the aggregated score signals imminent failure.
Action Uncertainty via Action-Chunk Entropy (ACE)
Recognizing that multimodal demonstration data induces observation-dependent action multimodality, FIPER introduces the ACE score to quantify uncertainty in the policy’s generated actions. At each policy timestep, a batch of action chunks is sampled from the policy. The entropy of these samples is computed dimension-wise using a binning approach, and summed across the prediction horizon. This method is computationally efficient and robust to high-dimensional action spaces.
Similar to RND-OE, ACE scores are aggregated over a sliding window and compared against a calibrated threshold. High ACE values indicate persistent uncertainty in the policy’s intent, often preceding task failure.
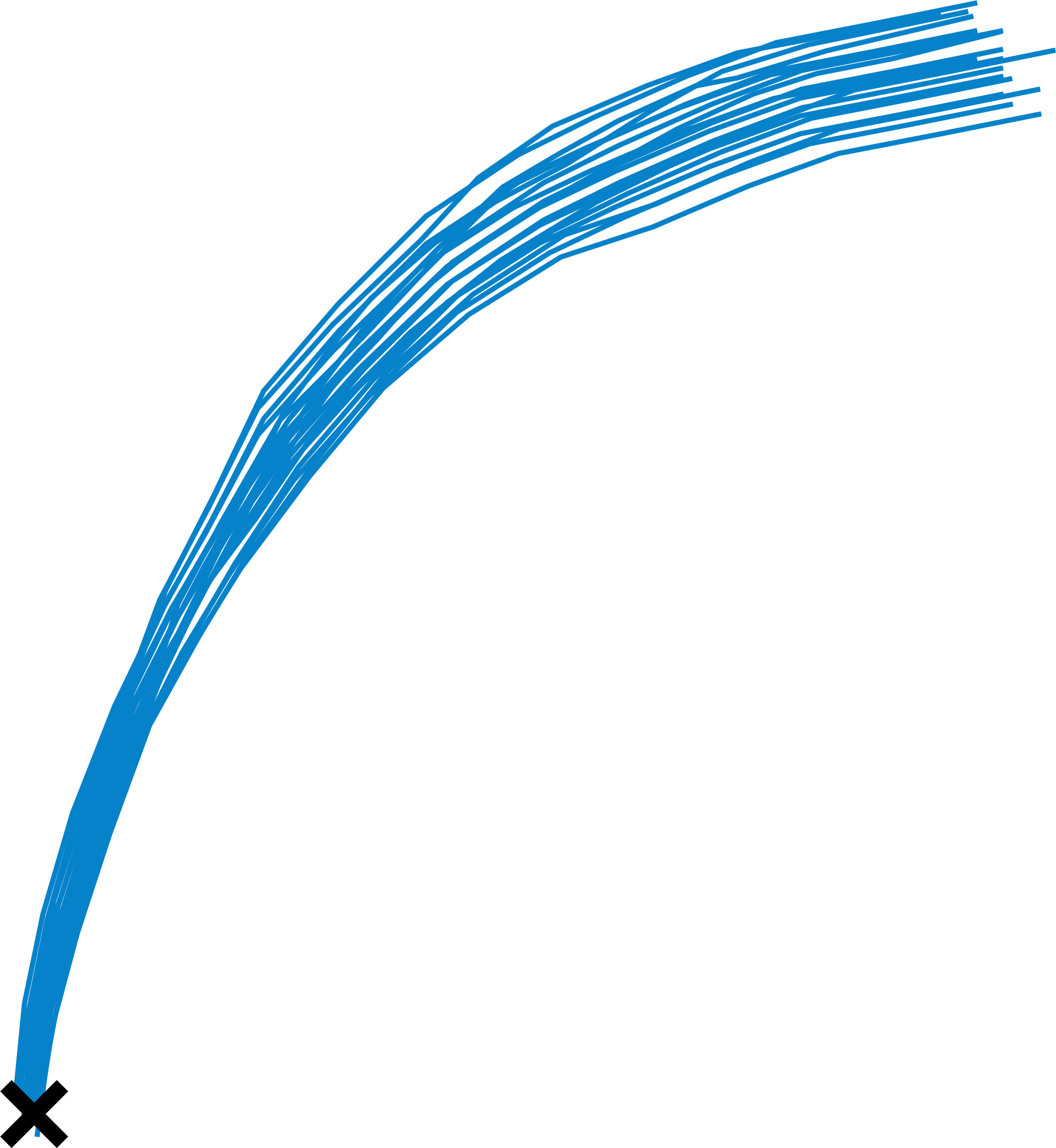



Figure 2: Low uncertainty in generated actions corresponds to sharp, unimodal action distributions, while high uncertainty reflects ambiguous or multimodal intent.
Logical Combination and Calibration
FIPER predicts failure only when both RND-OE and ACE scores exceed their respective thresholds, implementing a logical conjunction (AND) for robust discrimination between benign OOD and true failure cases. Thresholds are calibrated using conformal prediction bands or quantiles, providing statistical guarantees on the false positive rate for successful rollouts.
Experimental Evaluation
Environments and Implementation
FIPER is evaluated across five environments: three simulation tasks (Sorting, Stacking, PushT) and two real-world tasks (Pretzel, PushChair), encompassing diverse robot embodiments, observation modalities, and failure modes. Policies are implemented using denoising diffusion (temporal U-Net backbone) and flow matching (transformer backbone), with ResNet-18 as the image encoder. ACE is computed in Cartesian end-effector space for interpretability and efficiency.
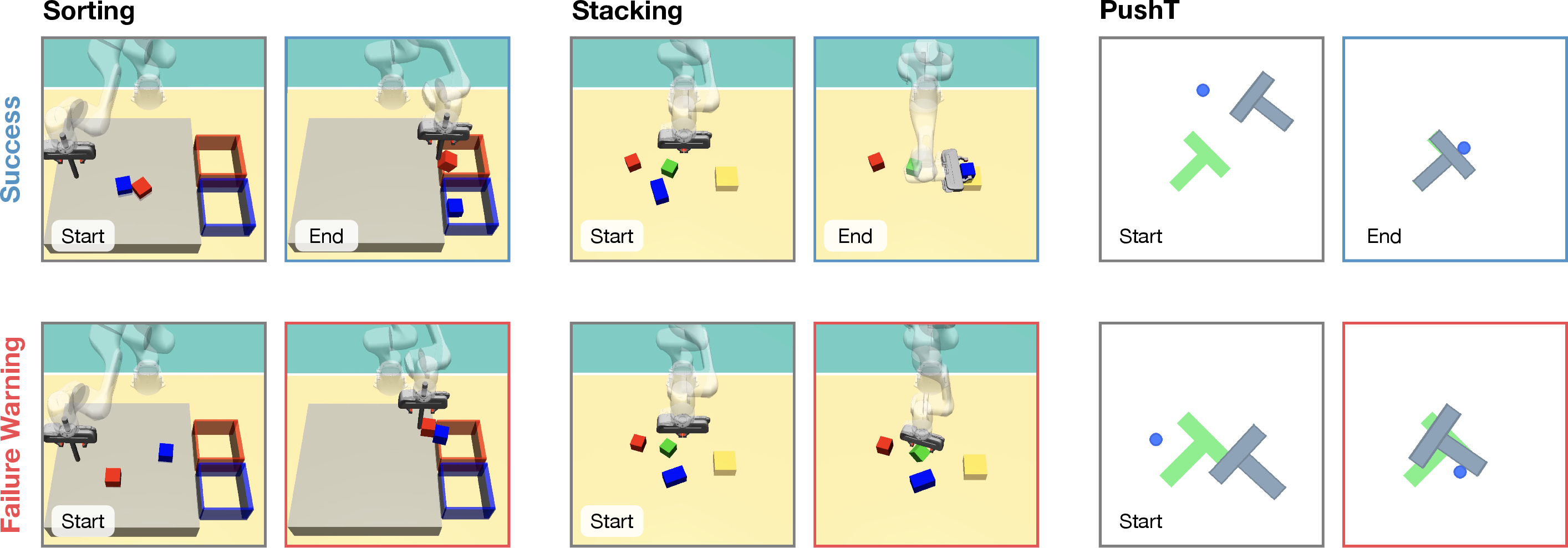
Figure 3: Simulation tasks with examples of successful and failed rollouts, illustrating the diversity of failure modes.

Figure 4: Real-world tasks with examples of successful and failed rollouts, highlighting practical deployment scenarios.
Baseline Comparison
FIPER is benchmarked against four state-of-the-art baselines: PCA-kmeans (clustering in embedding space), logpZO (flow matching likelihood), STAC (temporal action consistency), and RND-A (action-based RND confidence). Metrics include balanced accuracy, timestep-wise accuracy (TWA), and normalized detection time (DT).
FIPER achieves the highest TWA (0.65), accuracy (0.78), and competitive DT (0.30), outperforming all baselines in both early and accurate failure prediction. Notably, FIPER’s logical AND combination yields superior robustness to false alarms compared to OR or single-signal predictors.
Ablation and Design Analysis
Aggregating uncertainty scores over a sliding window is shown to be critical for early and robust failure prediction, outperforming both cumulative and single-timestep approaches.
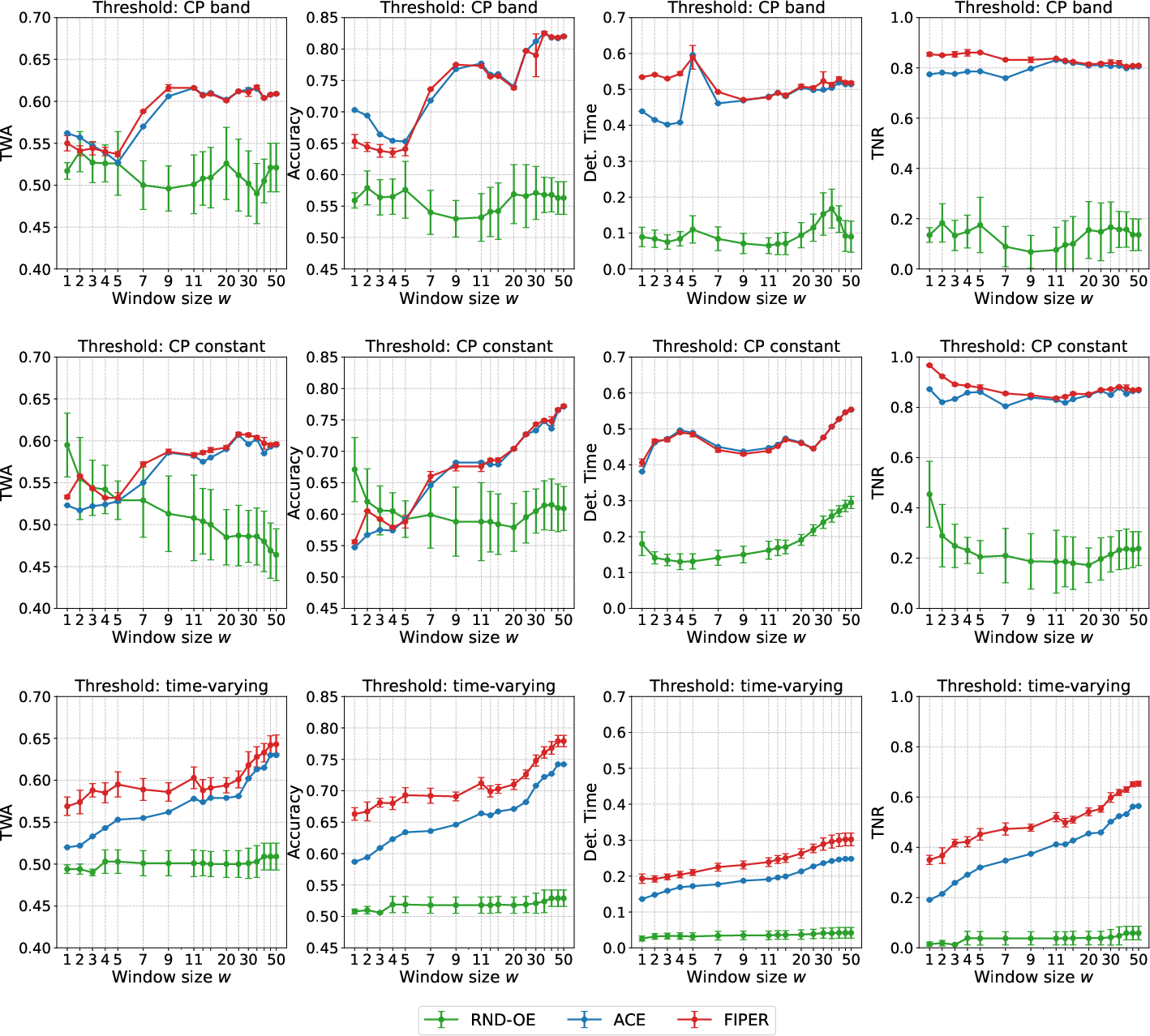
Figure 5: Impact of sliding window size w on prediction metrics for different threshold types, demonstrating the trade-off between accuracy and detection time.
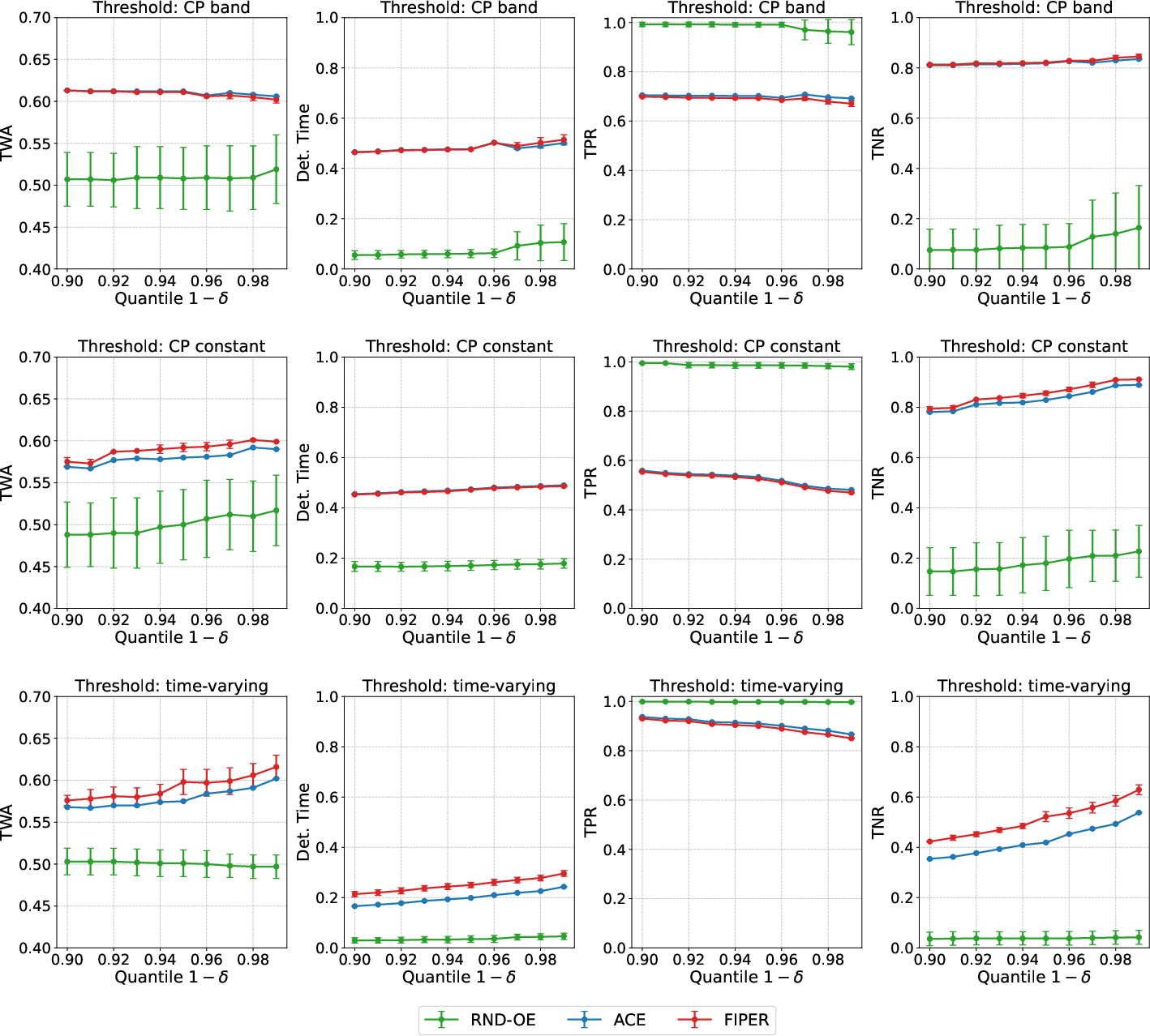
Figure 6: Effect of calibration quantile 1−δ on prediction performance, illustrating the sensitivity of TPR and TNR to threshold selection.
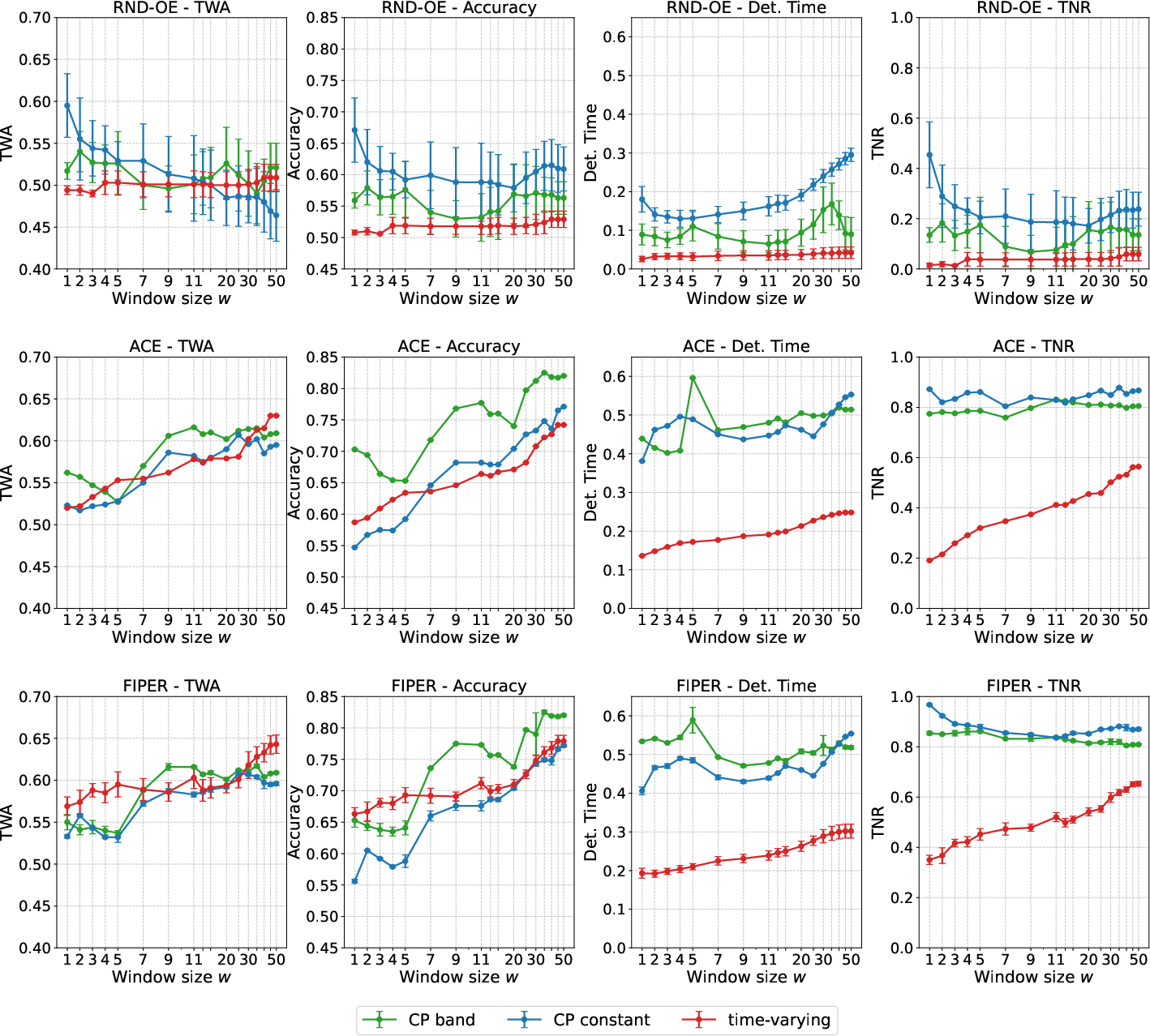
Figure 7: Comparison of threshold types (CP band, CP constant, time-varying) on prediction metrics, highlighting the benefits of time-varying thresholds for early detection.
Logical conjunction of RND-OE and ACE is empirically validated to yield higher accuracy and lower false positive rates, confirming that actual failures manifest in both observation and action uncertainty.
Theoretical Guarantees and Calibration
FIPER’s calibration via conformal prediction provides finite-sample, distribution-free guarantees on the false positive rate for successful rollouts. The framework is agnostic to specific failure modes and does not require failure data, making it suitable for deployment in safety-critical and human-centered environments.
Limitations and Future Directions
FIPER requires collection of successful rollouts and training of a separate RND-OE model, which may be nontrivial in high-dimensional or multi-modal settings. The approach is currently validated on single-task, vision-based IL policies; extension to large-scale vision-language-action models, additional modalities (e.g., touch, audio), and reinforcement learning with generative policies is a promising direction. Disentangling aleatoric and epistemic uncertainty in ACE, and incorporating richer historical context, may further improve prediction accuracy.
Conclusion
FIPER establishes a robust, interpretable, and task-agnostic framework for runtime failure prediction in generative robot policies. By combining observation-based OOD detection and action-based uncertainty quantification, calibrated via conformal prediction, FIPER achieves superior early warning performance without reliance on failure data. This work advances the safety and reliability of generative policies in real-world robotic applications and provides a foundation for future research in scalable, multimodal failure prediction.
