- The paper demonstrates that cross-attention naturally performs orthogonal alignment by extracting complementary, non-redundant information across domains.
- The introduction of the Gated Cross-Attention module improves recommendation accuracy and parameter efficiency through effective latent space fusion.
- Experimental findings show significant improvements in NDCG@10 and AUC scores, underscoring the method’s robustness against noisy, cross-domain data.
This paper investigates the mechanisms underlying cross-attention in cross-domain sequential recommendation (CDSR) systems, arguing that cross-attention not only facilitates residual alignment but also discovers novel orthogonal information, termed "Orthogonal Alignment." This insight emerges naturally and is linked to improved parameter scaling in recommendation models.
Introduction
Cross-domain sequential recommendation systems leverage interaction sequences across different platforms to enhance recommendation accuracy. Traditional models suffer from noisy and redundant data integration, leading to performance degradation. Cross-attention mechanisms have been widely adopted to address these challenges, facilitating the alignment and projection of representations from various domains into a unified latent space.
The conventional understanding of cross-attention focuses on residual alignment, where cross-attention predominantly refines the input by filtering irrelevant information. However, this paper introduces the concept of Orthogonal Alignment, where cross-attention naturally discovers and integrates orthogonal, non-redundant information that significantly enhances model performance without additional parameter reliance.
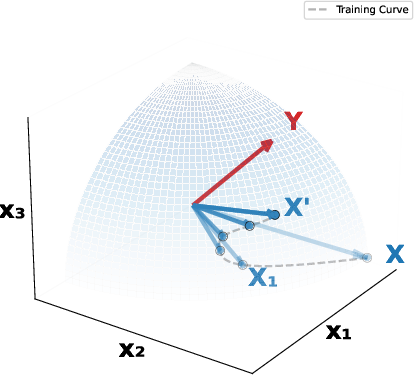
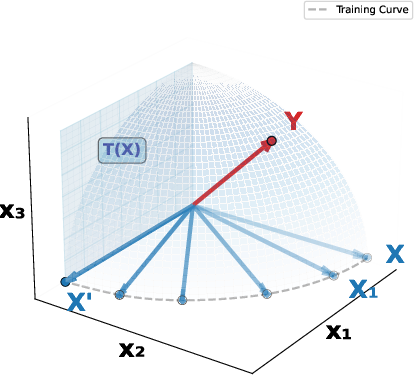
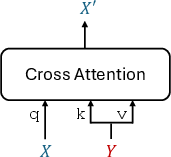
Figure 1: Residual alignment and orthogonal alignment in cross-domain recommendation models.
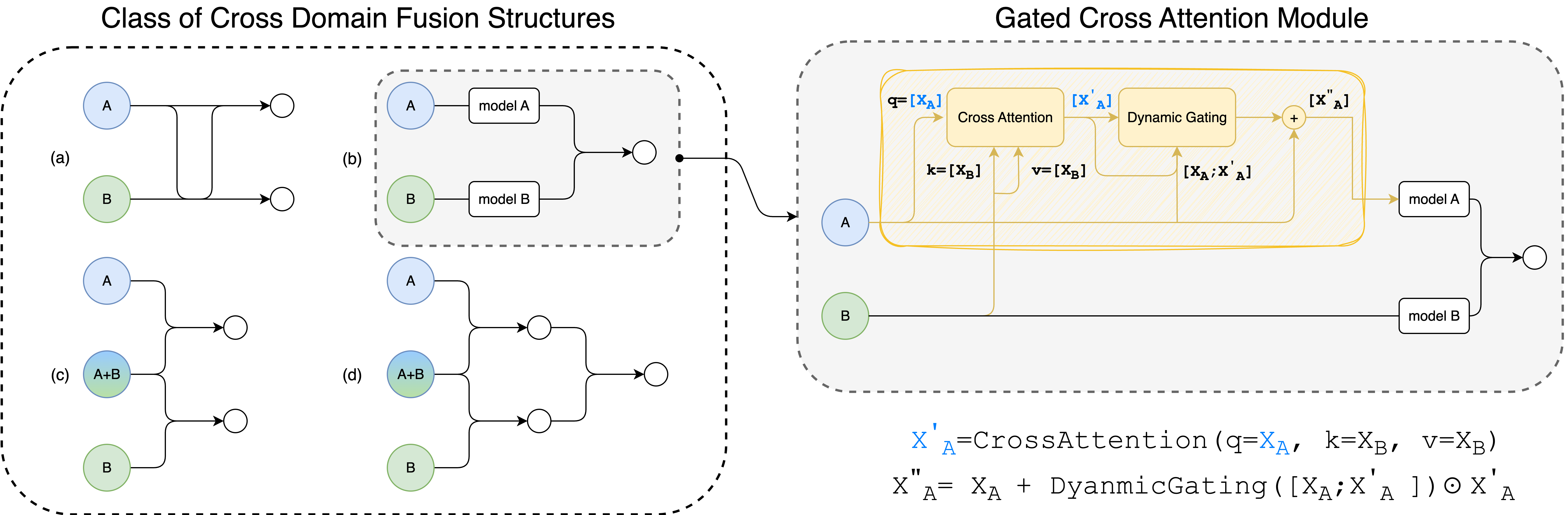
Gated Cross-Attention Module (GCA)
The core innovation presented is the Gated Cross-Attention ($\gca$) module, designed to extract complementary orthogonal information during the alignment of sequences from different domains. The $\gca$ module operates by allowing the integration of novel information uncovered during cross-attention between domain sequences, thereby improving the model's representational capacity.
The $\gca$ module can be formulated as follows:
1
2
3
4
|
def gca(X_A, X_B, ff, ca):
X_A_prime = ca(query=X_A, key=X_B, value=X_B)
gated_output = ff([X_A, X_B]) * X_A_prime
return layernorm(X_A + gated_output) |
Where:
Experimental Findings
The experimental results consistently show that $\gca$ modules substantially enhance recommendation accuracy across a variety of baseline models. The introduction of $\gca$ results in improved NDCG@10 and AUC scores across multiple domain recommendations.
Observation 2: Natural Emergence of Orthogonal Alignment
Analysis reveals a negative correlation between the cosine similarity of cross-attention inputs and outputs, underscoring the orthogonality phenomenon. The orthogonal alignment naturally emerges from the $\gca$ integration, providing robust performance improvements.
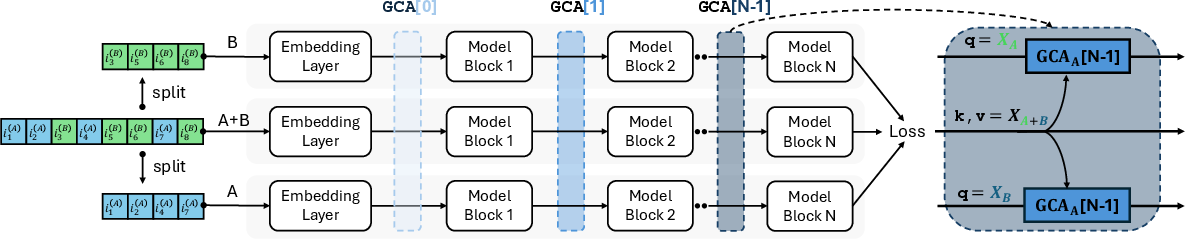
Figure 3: Placement of $\gca$ modules within baseline architectures.
Observation 3: Parameter-Efficient Model Scaling
The incorporation of $\gca$ allows for parameter-efficient scaling, outperforming parameter-matched baselines. This demonstrates that the orthogonal alignment mechanism offers a viable path to deploy large models effectively without linearly increasing parameters.
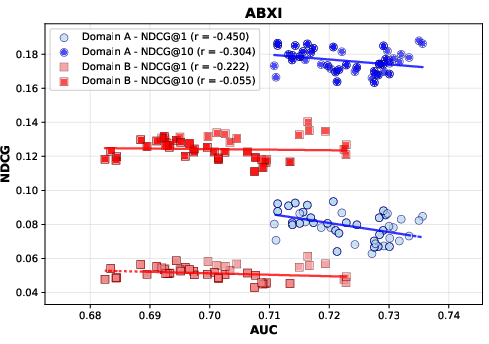
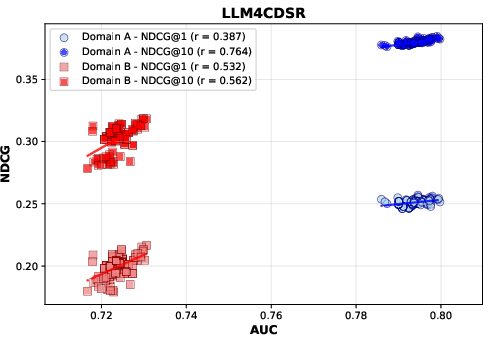
Figure 4: CDSRNP models benefit from increased representation capacity via orthogonal alignment.
Conclusion
This paper uncovers a significant insight into cross-domain sequential recommendation systems by establishing Orthogonal Alignment as a natural phenomenon within cross-attention mechanisms. The findings challenge prevailing interpretation norms and open pathways for advanced scaling strategies that maintain performance without proportionately larger models. This work prompts further exploration into orthogonal alignment across models, potentially expanding applications beyond recommendation systems into broader multi-modal and cross-domain challenges. The integration of orthogonal alignment insights into future AI models promises to unlock new dimensions of efficiency and effectiveness.