- The paper introduces Circuit-based Reasoning Verification (CRV), a method that diagnoses chain-of-thought reasoning errors using computational graph analysis.
- It leverages per-layer transcoders to induce sparse, interpretable activations, constructing attribution graphs that trace causal flows within model computations.
- Empirical results show CRV outperforms baselines in error detection and benefits from causal interventions that correct reasoning faults via structural fingerprints.
Circuit-Based Reasoning Verification: Structural Analysis of Chain-of-Thought Computation
Introduction and Motivation
The paper "Verifying Chain-of-Thought Reasoning via Its Computational Graph" (2510.09312) introduces Circuit-based Reasoning Verification (CRV), a white-box methodology for diagnosing and verifying the correctness of Chain-of-Thought (CoT) reasoning in LLMs by analyzing the structural properties of their computational graphs. Unlike black-box approaches that rely on output text or gray-box methods that probe raw activations, CRV leverages interpretable model modifications and attribution graph analysis to uncover mechanistic signatures of reasoning errors. The central hypothesis is that correct and incorrect reasoning steps manifest as distinct structural fingerprints in the model's latent execution trace, which can be detected and causally intervened upon.
CRV Pipeline and Model Instrumentation
CRV operates in four stages: (1) replacing standard MLP modules in the LLM with per-layer transcoders (PLTs) to induce interpretable, sparse activations; (2) constructing step-level attribution graphs that trace causal information flow between features and model components; (3) extracting structural features from these graphs; and (4) feeding these features to a diagnostic classifier to predict step correctness.
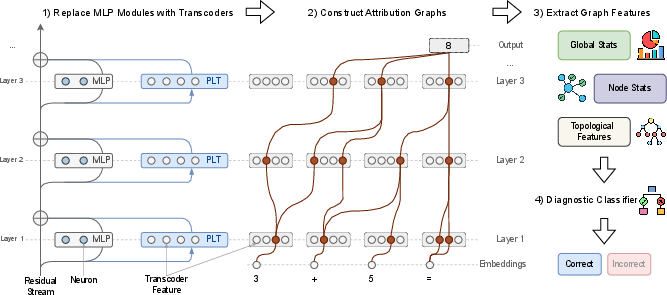
Figure 1: The CRV pipeline, illustrating model instrumentation, attribution graph construction, feature extraction, and diagnostic classification for step-level reasoning verification.
Transcoders are trained to approximate the input-output function of each MLP, enforcing a sparse, overcomplete basis for activations. This enables the attribution graph to be constructed over meaningful, interpretable features rather than dense, uninterpretable vectors. Attribution graphs are computed using a greedy path-finding algorithm, tracing high-attribution connections from output logits back through active transcoder features and input tokens.
Dataset Curation and Step-Level Annotation
CRV requires datasets with step-level correctness labels and access to the full internal state of the model during generation. The authors curate new benchmarks for synthetic Boolean and Arithmetic tasks, where ground truth is programmatically verifiable, and for GSM8K, where step correctness is annotated using a strong LLM judge (Llama 3.3 70B Instruct) and validated by human review. Only steps up to the first error in a reasoning chain are retained, ensuring unambiguous labeling and avoiding error propagation ambiguities.
Structural Feature Extraction and Diagnostic Classification
From each attribution graph, a fixed-size feature vector is extracted, capturing global graph statistics (node counts, logit entropy), node influence and activation statistics (mean/max activations, layer-wise histograms), and topological/path-based features (graph density, centrality, connectivity, shortest path lengths). These features are pruned to retain only the most influential components. A Gradient Boosting Classifier (GBC) is trained on these vectors to predict step correctness, with feature importance analysis used to identify the most predictive structural properties.
CRV is evaluated on Llama 3.1 8B Instruct across synthetic Boolean, Arithmetic, and GSM8K datasets, and compared to black-box (MaxProb, PPL, Entropy, Energy) and gray-box (CoE, CoT-Kinetics, LR Probe) baselines. CRV consistently outperforms all baselines in AUROC, AUPR, and FPR@95, with the strongest gains on structured synthetic tasks. For example, on the Arithmetic task, CRV achieves AUROC 92.47 and FPR@95 37.09%, compared to the best baseline AUROC 76.45 and FPR@95 63.33%.
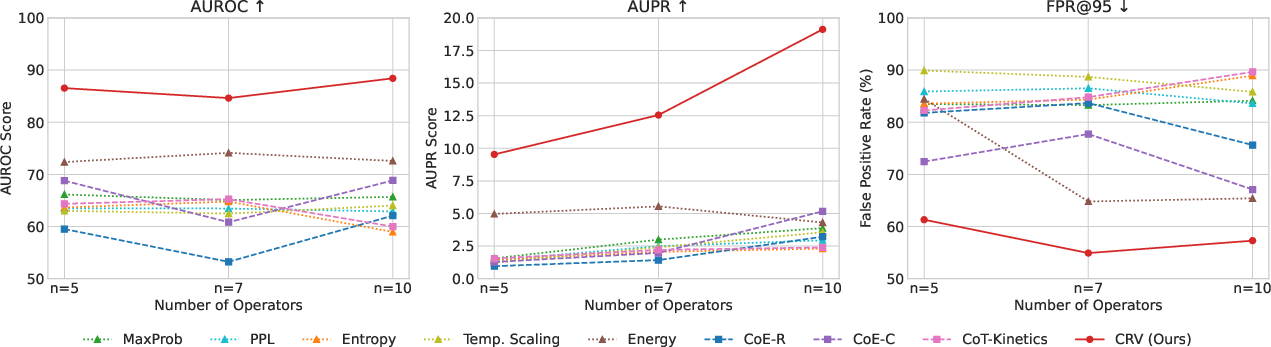
Figure 2: CRV maintains superior verification performance as arithmetic task difficulty increases, demonstrating robustness to problem complexity.
Performance is robust to increasing task difficulty (number of operators), with CRV retaining a clear advantage as complexity rises. However, cross-domain generalization is limited: error fingerprints are highly domain-specific, and CRV trained on one domain transfers poorly to others, highlighting the specificity of structural error signatures.
Mechanistic Analysis: Structural Fingerprints of Error
Ablation studies reveal that node influence and activation statistics are the most critical features for error detection, followed by global graph statistics and topological features. Visualization of feature distributions for correct vs. incorrect steps shows clear, statistically significant separation across multiple feature types.
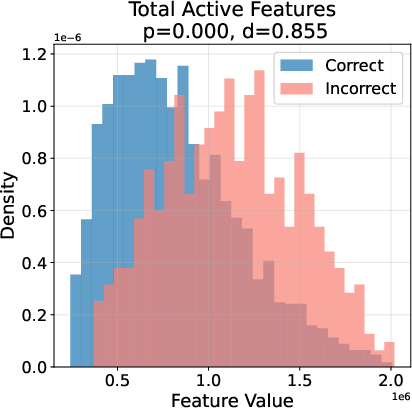
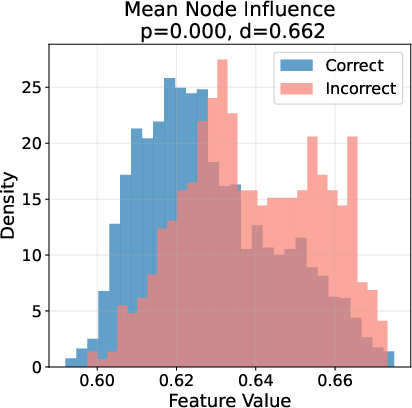
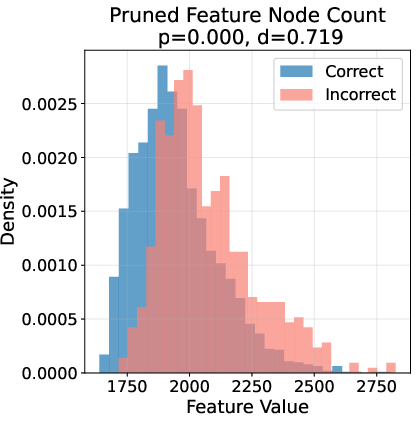
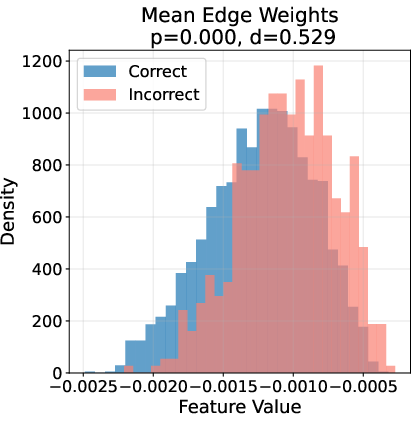
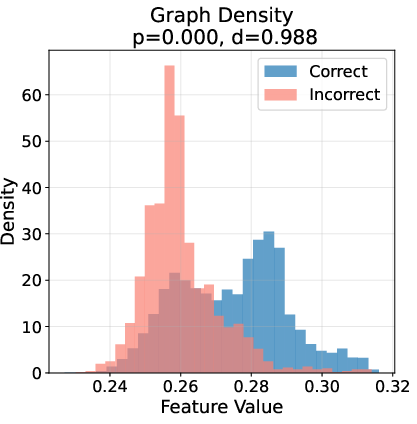
Figure 3: Topological fingerprints of error on GSM8K, showing distinct distributions of key graph features for correct (blue) vs. incorrect (red) reasoning steps.
Projection of high-dimensional feature vectors via PCA and t-SNE demonstrates that incorrect steps occupy a dense subset within the broader distribution of correct steps, with a distinct region corresponding to computational integrity accessible only to valid reasoning.
Causal Interventions: From Diagnosis to Correction
CRV's interpretability enables targeted interventions on transcoder features. In case studies, suppressing a faulty feature or amplifying an under-active feature at the point of error causally corrects the model's reasoning path, converting an incorrect step into a correct one. This provides closed-loop evidence that the identified structural signatures are not merely correlational but causally implicated in reasoning failures.
Transcoder Training and Attribution Graph Fidelity
Transcoders are trained on a large subset of RedPajama-V2, with TopK sparsity and dead neuron revival mechanisms to ensure feature quality. Instruction-tuning of transcoders does not yield consistent improvements, suggesting that base model features are sufficient for reasoning verification. Attribution graphs computed at the final token of the current step (post-computation) provide a stronger signal of error than pre-computation traces.
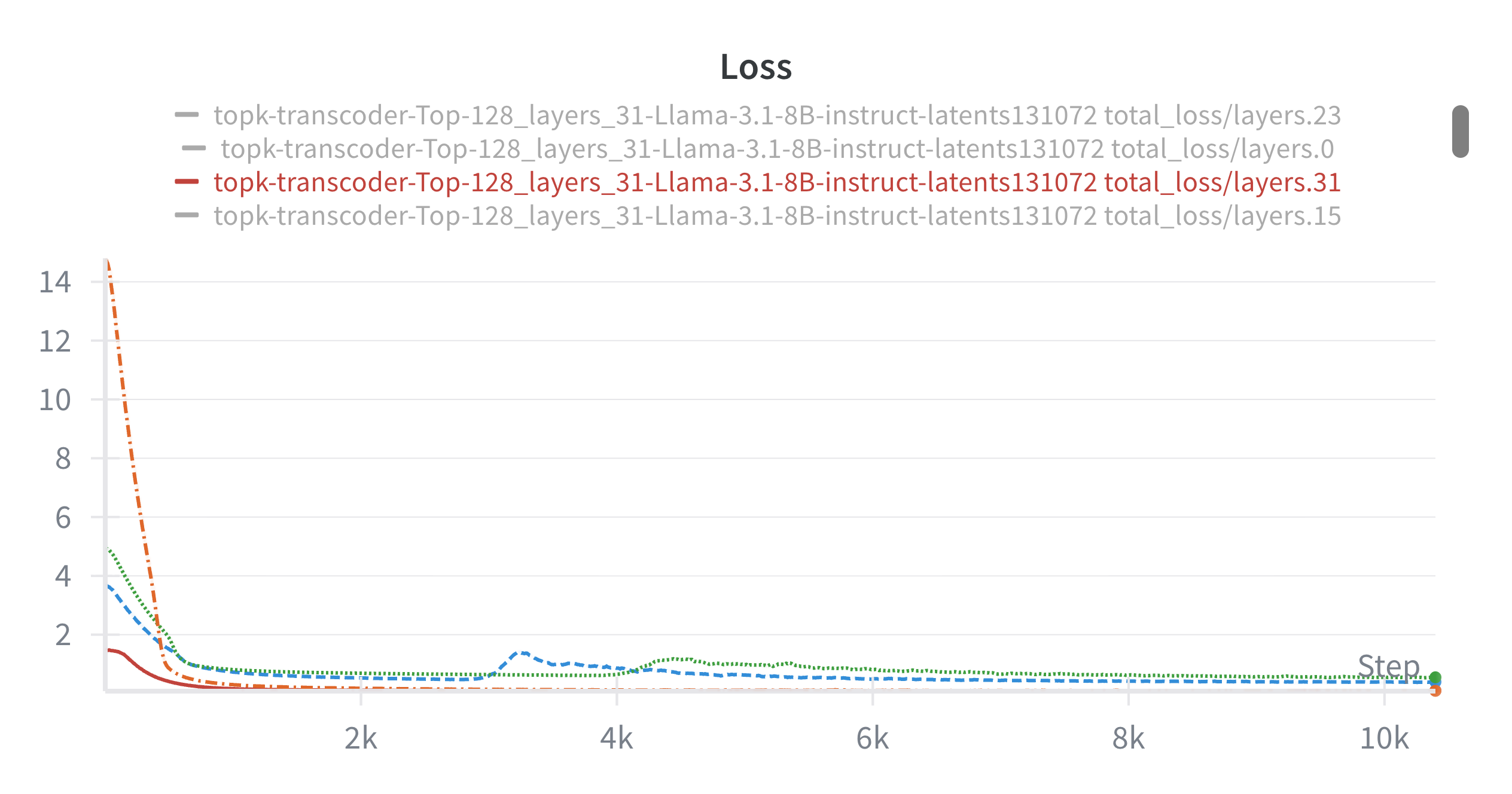
Figure 4: Transcoder training loss curves, showing efficient convergence and stable feature learning across layers.
Limitations and Future Directions
CRV is computationally intensive, requiring model modification and per-step graph analysis, making it impractical for real-time deployment. The current feature set is aggregative and does not fully exploit the semantic content of individual transcoder features, suggesting opportunities for neuro-symbolic verifiers. Error signatures are domain- and model-specific; generalization across architectures and scales remains an open question. The fidelity of interpretability tools (transcoders, attribution methods) is a limiting factor, and future improvements in these areas will enhance mechanistic analyses.
Implications and Prospects
CRV establishes the feasibility of verifying reasoning correctness via computational graph analysis, moving beyond error detection to causal understanding. The domain-specificity of error fingerprints suggests that mechanistic interpretability can uncover nuanced failure modes unique to each reasoning paradigm. The ability to causally intervene on model features opens avenues for targeted correction and neuro-symbolic integration. As interpretability tools mature and computational costs decrease, CRV-like methodologies may inform the development of robust, self-diagnosing reasoning systems and advance the scientific study of LLM computation.
Conclusion
Circuit-based Reasoning Verification demonstrates that attribution graphs of LLM reasoning steps contain rich, structural signals of correctness and error. By instrumenting models with interpretable transcoders and analyzing their computational traces, CRV enables accurate verification, mechanistic diagnosis, and causal intervention. The findings highlight the value of white-box approaches for understanding and improving LLM reasoning, and lay the groundwork for future research in mechanistic interpretability, neuro-symbolic verification, and automated model correction.