MaP: A Unified Framework for Reliable Evaluation of Pre-training Dynamics
Abstract: Reliable evaluation is fundamental to the progress of LLMs, yet the evaluation process during pre-training is plagued by significant instability that obscures true learning dynamics. In this work, we systematically diagnose this instability, attributing it to two distinct sources: \textit{Parameter Instability} from training stochasticity and \textit{Evaluation Instability} from noisy measurement protocols. To counteract both sources of noise, we introduce \textbf{MaP}, a dual-pronged framework that synergistically integrates checkpoint \underline{M}erging \underline{a}nd the \underline{P}ass@k metric. Checkpoint merging smooths the parameter space by averaging recent model weights, while Pass@k provides a robust, low-variance statistical estimate of model capability. Extensive experiments show that MaP yields significantly smoother performance curves, reduces inter-run variance, and ensures more consistent model rankings. Ultimately, MaP provides a more reliable and faithful lens for observing LLM training dynamics, laying a crucial empirical foundation for LLM research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a big problem in training LLMs: their scores during training can jump up and down a lot, making it hard to tell if the model is actually getting better. The authors propose a simple, two-part method—called MaP—to make these evaluations steadier and more trustworthy so researchers can see true learning progress.
The main questions the paper asks
- Why do LLM scores bounce around so much during pre-training?
- Can we fix this instability so we can fairly compare training strategies and predict which models will do well later?
- What practical steps can make evaluation more reliable without changing the model’s architecture?
How the researchers approached the problem
The authors say there are two main sources of instability, and they tackle each one with a matching fix:
1) Parameter Instability (the model itself is shaky)
- Think of training as hiking through a foggy mountain path. A “checkpoint” is a snapshot of where you are. Because training involves randomness (like different data batches or noisy updates), any single snapshot can look worse or better than it truly is.
- Fix: Checkpoint Merging. Instead of judging the model using just one snapshot, they average the last few snapshots (checkpoints). This is like smoothing out the path to see the model’s “true” position. Averaging reduces random bumps and gives a more stable version of the model.
2) Evaluation Instability (the way we measure is noisy)
- For tasks like code writing or math, a single generated answer can be right or wrong just by luck, like flipping a coin. If you only check one try, the score can be overly lucky or unlucky.
- Fix: Pass@k. Instead of judging the model on one try, let it try multiple times (k attempts). If at least one attempt is correct, it “passes.” This reveals the model’s real ability more fairly, like letting someone take a few swings to hit a baseball rather than judging them on a single swing.
To put it simply, MaP combines:
- Checkpoint Merging (smoother model)
- Pass@k (smoother measurement)
Together, they reduce noise from both the model and the test.
What they did in experiments
To make sure their method works, the authors tested it on:
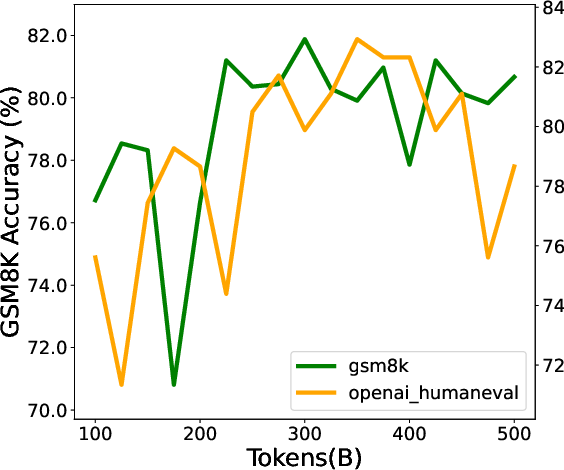
- Math and code tasks (where answers are generated, like GSM8K, MATH, HumanEval, MBPP).
- Knowledge and reading tasks (multiple-choice benchmarks like MMLU, RACE).
They tracked performance across many saved checkpoints during long training runs, and they compared:
- The usual way (single checkpoint, single answer),
- Only merging checkpoints,
- Only using Pass@k,
- Both together (MaP).
They also used simple statistics to measure stability:
- Kendall’s tau: does the score move steadily upward over time? Higher is better.
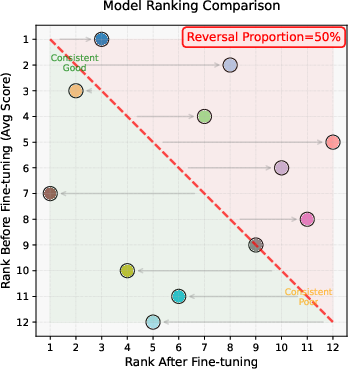
- Pairwise Ranking Reversal Rate (PRR): if you rank models during pre-training, how often does that ranking flip after fine-tuning? Lower is better.
The key results and why they matter
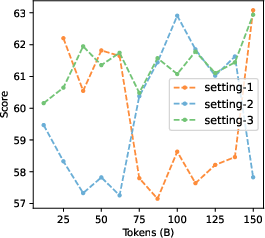
- Smoother training curves: Using checkpoint merging made performance trends less jumpy across many benchmarks. Scores became more predictable over time.
- Better consistency across runs: Merging reduced the random ups and downs between different training runs, making comparisons fairer.
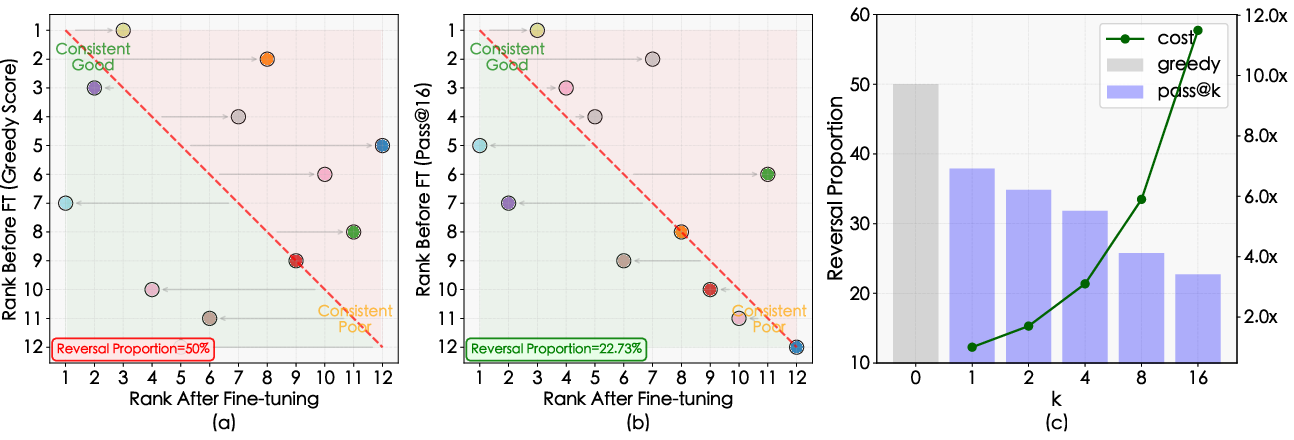
- Stronger predictions for downstream tasks: Pass@k made pre-training rankings match post-training rankings more often. For example, using many attempts (like Pass@16) dropped ranking reversals from about 50% down to about 23%.
- Best when combined: Using both merging and Pass@k together gave the most stable and reliable evaluations—more than either method alone.
Why this matters:
- Clearer ablation studies: Researchers can compare training strategies without being misled by noisy curves that cross and flip.
- Better decisions: More stable evaluations help pick the right model to fine-tune next.
- Fairer leaderboards: Scores reflect true progress, not random luck.
What this means going forward
MaP is a practical way to watch how LLMs learn without being fooled by noise. It helps the research community:
- Trust pre-training evaluations more,
- Make better choices during long training runs,
- Build a stronger foundation for future LLM development.
The authors suggest future work could make MaP cheaper to run (for example, stopping early once a correct answer is found) or design smarter sampling methods. They also want to study why training is volatile for different model types, which could lead to training methods that are stable by design.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions the paper leaves unresolved, organized to facilitate actionable follow-up research:
- Validity of the independence assumption in checkpoint noise: The variance reduction claim for merging assumes approximately independent, zero-mean noise across recent checkpoints ( reduction by $1/N$). Consecutive checkpoints are highly correlated in practice. Quantify empirical covariance structures across steps and measure how the realized variance reduction deviates from $1/N$ under different optimizers, batch sizes, and LR schedules.
- Bias introduced by checkpoint averaging: Averaging weights may move the model to regions of parameter space that differ systematically from the “ideal” trajectory (e.g., bias toward flatter minima). Characterize any systematic bias (not just variance) introduced by merging and its downstream effect on capability and calibration.
- Applicability beyond the tested MoE and scale regimes: Results are reported for a 16.3B-parameter MoE (1.4B active) and 243M-active-parameter models. Test MaP on dense architectures, larger dense LLMs (e.g., 7B–70B), and different MoE router designs to assess generality.
- MoE-specific pitfalls in merging: Expert weights and routers can exhibit permutation symmetries and routing drift. Does averaging expert/router parameters harm specialization, load balancing, or introduce degeneracies? Evaluate merging under expert permutation alignment or router re-initialization constraints.
- Interaction with optimizer state and LR schedule: Weight-only averaging ignores optimizer moments. How does merging interact with AdamW/Adafactor states, warmup–stable–decay phases, LR restarts, and cosine vs linear schedules? Should merging windows be aligned with schedule phases?
- Adaptive selection of merge window size and saving interval: The paper varies but lacks a principled rule. Develop and test adaptive policies that set and checkpoint cadence based on online stability diagnostics (e.g., trend tests, variance estimates, or learning rate magnitude).
- Early-warning and anomaly detection risk: Smoothing may mask real regressions (e.g., data corruption, mode collapse). Design detectors that can flag genuine collapses when merged curves remain smooth (e.g., monitoring additional unsmoothed indicators like perplexity spikes or gradient norms).
- Generality of Pass@k beyond code/math: Pass@k improves stability on generative, verifiable tasks but degrades on MC tasks. What is the appropriate analogue for non-verifiable or subjective tasks (open-ended QA, safety/helpfulness, dialogue quality)? Explore “Pass@k + judge” protocols with calibrated automatic judges or human raters, and quantify judge variance.
- Decoding-hyperparameter sensitivity: Pass@k stability depends on temperature, nucleus/top-k settings, and sampling seed policy. Provide a sensitivity analysis and standardized decoding settings that ensure fair comparisons across runs and labs.
- Overestimation vs operational performance: Pass@k measures “latent potential” but may inflate scores relative to single-shot deployment (Pass@1/greedy). Establish calibration mappings between Pass@k and Pass@1 for decision-making, and define task-specific guidance for choosing k that preserves relevance to deployment constraints.
- Instance- and difficulty-adaptive sampling: The paper notes cost trade-offs but does not implement adaptive sampling. Develop sequential testing or best-arm identification schemes that allocate samples per instance based on difficulty, with early-stopping once a correct sample is found; provide unbiasedness and variance guarantees.
- Fair, compute-aware evaluation policies: Provide Pareto frontiers (stability vs compute) and concrete budgets for evaluation frequency, number of problems, n/k choices, and checkpoint saving/merging overhead, including I/O and wall-clock costs at scale.
- Statistical rigor and uncertainty quantification: Report confidence intervals, effect sizes, and significance tests for Kendall’s τ and PRR improvements; include repeated runs with multiple seeds to quantify inter-run variance reductions under MaP. Current results lack CIs and formal tests.
- Dataset and benchmark coverage: Pass@k is evaluated on a subset (GSM8K, MATH, HumanEval, MBPP). Assess robustness across more generative tasks (reasoning with verifiers, long-form QA with graders, multilingual code/math) and check for contamination/decontamination to ensure reliability.
- Robustness to prompt variants and evaluation formats: Stability may depend on prompt phrasing and format (e.g., CoT vs direct). Perform prompt-ensemble evaluations and quantify whether MaP benefits persist across prompt distributions.
- Verification robustness in code/math: Weak test suites or brittle math checkers can produce false positives amplified by Pass@k. Strengthen and report verifier robustness (mutated test cases, adversarial checks, symbolic verification) and analyze how verifier quality interacts with k.
- Alternative stabilization baselines: Compare checkpoint merging to exponential moving averages (EMA), Polyak averaging, stochastic weight averaging (SWA), low-pass filtering in parameter space, and output-level ensembling/logit averaging. Establish when each method is preferable and whether combinations outperform simple averaging.
- Decomposition and measurement of “parameter stability” vs “evaluation stability”: The paper posits Overall Stability ≈ Parameter Stability × Evaluation Stability but does not operationalize separate, identifiably measured components. Define and validate separate metrics (e.g., resampling the same checkpoint for evaluation stability; re-merging across the same evaluation protocol for parameter stability).
- Scaling PRR findings beyond small models: PRR improvements (e.g., to 22.73%) are shown on 12 small models with varied strategies. Validate whether PRR gains hold for larger models and more diverse training strategies (data mixtures, curriculum, regularization).
- Real-world selection decisions: Demonstrate that using MaP during pre-training to select checkpoints or ablations leads to better final SFT/RLHF outcomes prospectively (not just retrospective correlations).
- Frequency and latency constraints: Merging last N checkpoints introduces latency and storage overhead. For near-real-time monitoring, what minimal N and sampling budgets preserve stability under strict latency and storage constraints?
- Heterogeneous-difficulty aggregation: Pass@k variance formulas assume a single latent p, but datasets have per-item heterogeneity {p_i}. Analyze bias/variance of dataset-level estimators under heterogeneity and propose weighted or stratified estimators.
- Safety, alignment, and calibration: Effects of checkpoint merging and Pass@k on safety metrics (toxicity, bias), calibration (probability estimates), and refusals are unexamined. Do MaP procedures stabilize or distort these properties?
- Multimodal and multilingual generalization: Evaluate MaP on multimodal LLMs and across languages; decoding diversity and verification quality vary substantially across modalities and languages.
- Reproducibility and openness: The paper does not specify public release of code, evaluation scripts, merged checkpoints, and exact decoding settings. Provide artifacts to enable independent verification of stability claims.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s MaP framework (checkpoint merging + Pass@k), along with the paper’s stability metrics (Kendall’s τ and PRR). Each item links to sectors and suggests tools/workflows, with key assumptions and dependencies noted.
- Reliable pre-training monitoring and gating in LLM pipelines
- Sectors: software/AI, cloud ML, MLOps
- Tools/workflows: integrate checkpoint merging (e.g., Merge@4–8 with 12.5–25B-token save intervals), add Pass@k (k≈8–16) to generative benchmarks (GSM8K, MATH, HumanEval, MBPP), and track Kendall’s τ and PRR in training dashboards (OpenCompass-compatible)
- Assumptions/dependencies: frequent checkpointing, storage capacity, sample budget for Pass@k, Pass@k applied to generative tasks (not multiple-choice)
- More trustworthy ablations and hyperparameter selection during pre-training
- Sectors: academia, industry R&D
- Tools/workflows: merge recent checkpoints before evaluation; use Pass@k to reduce sampling luck; report Kendall’s τ per benchmark to quantify monotonicity; pick learning-rate schedules or data mixes based on PRR-consistent ranks
- Assumptions/dependencies: consistent benchmark suites; controlled random seeds and data orders for fair comparisons
- Better model selection before SFT and alignment stages
- Sectors: software/AI labs, developer tools
- Tools/workflows: choose base models with Pass@k-stable pre-training ranks; set rank-reversal (PRR) gates for advancing to SFT; automate “promote/hold” decisions in orchestration pipelines
- Assumptions/dependencies: downstream tasks similar to generative pre-training probes; shared SFT protocol across candidates
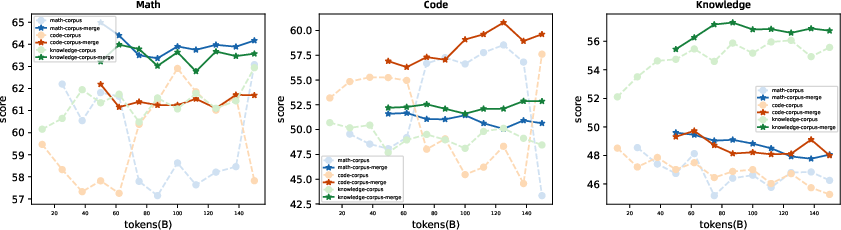
- Reduced inter-run variance for corpus and curriculum decisions
- Sectors: data engineering, education/knowledge, code intelligence
- Tools/workflows: run parallel pre-trainings on math/code/knowledge corpora; evaluate merged checkpoints to reveal consistent corpus–capability match; avoid misleading curve crossings
- Assumptions/dependencies: sufficiently granular checkpoint cadence; representative benchmarks per domain
- Cost-aware evaluation scheduling
- Sectors: cloud ML ops, finance (cost control), energy (efficiency)
- Tools/workflows: set k adaptively by benchmark difficulty; use curated subset of problems for Pass@k; early-stop per problem when a correct sample is found; track compute cost vs. stability in dashboards
- Assumptions/dependencies: problem-level correctness checks (e.g., unit tests for code, verifiers for math), difficulty estimation heuristics
- Benchmark/Leaderboard maintenance with lower variance
- Sectors: academic benchmark consortia, open-source communities
- Tools/workflows: publish Pass@k for generative tasks alongside single-pass scores; document merging protocol (window size N); report Kendall’s τ and PRR to characterize stability and predictive value
- Assumptions/dependencies: community agreement on evaluation settings; additional compute for multi-sample measurements
- Compliance, audit, and performance claims with variance quantification
- Sectors: policy, governance, regulated industries (healthcare, finance)
- Tools/workflows: attach stability metrics (τ, PRR) to model reports; define internal thresholds for acceptable variance; use merged-checkpoint evaluations to support claims of consistent performance
- Assumptions/dependencies: auditors/regulators accept variance-aware reporting; domain-specific generative benchmarks exist and have automated verifiers
- Enterprise model procurement and bake-offs (particularly for code assistants)
- Sectors: software engineering platforms, DevOps
- Tools/workflows: run Pass@k on HumanEval/MBPP with unit-test harnesses; merge checkpoints for vendor models where feasible (or request merged snapshots); select models with lower PRR risk for downstream workflows like SFT or RAG
- Assumptions/dependencies: access to test harnesses and permissive licenses; reproducible inference settings across vendors
- Training-quality control and anomaly detection
- Sectors: MLOps, data quality assurance
- Tools/workflows: monitor Kendall’s τ over time; flag sudden drops or oscillations as potential data/shuffling/optimizer anomalies; use merged-checkpoint curves to separate measurement noise from genuine regressions
- Assumptions/dependencies: consistent logging and metric collection; adequate cadence of checkpoints
- Educational use for teaching robust evaluation
- Sectors: higher education, professional upskilling
- Tools/workflows: classroom labs using small models to demonstrate parameter instability, merging, and Pass@k; assignments requiring τ/PRR reporting; OpenCompass-based reproducible notebooks
- Assumptions/dependencies: modest compute; open benchmarks; reproducible seeds
Long-Term Applications
The following opportunities require further research, scaling, standardization, or productization before broad deployment.
- Standardized, variance-aware evaluation protocols for LLM certifications
- Sectors: policy/regulation, standards bodies (ISO/IEEE), safety
- Tools/products: a certification schema that mandates reportable τ/PRR, checkpoint merging specs, and Pass@k for generative tasks; conformance tests
- Assumptions/dependencies: sector-wide consensus; cross-organization reproducibility studies
- Adaptive sampling and difficulty-aware evaluation algorithms
- Sectors: software/AI research, ML tooling
- Tools/products: dynamic k selection based on per-problem confidence; early-stopping and verifier-guided sampling; approximate variance bounds at runtime
- Assumptions/dependencies: fast correctness checkers; calibrated confidence estimators; robust stopping criteria
- Training methods that inherently reduce parameter instability
- Sectors: academia, optimization research
- Tools/products: optimizers or schedules that target flatter minima; regularization or “on-the-fly” weight averaging; loss-surface-aware warmup–stable–decay strategies
- Assumptions/dependencies: theory-guided designs; validation across model scales (dense/MoE) and tasks
- AutoML for LLMs driven by stability-aware signals
- Sectors: industry ML platforms, cloud providers
- Tools/products: Bayesian optimization or bandit systems optimizing τ/PRR-weighted objectives; automated curriculum/data-mix search stabilized via merging and Pass@k
- Assumptions/dependencies: scalable orchestration; reliable, fast stability metrics; cost constraints
- Sector-specific stable evaluation suites with verifiers
- Sectors: healthcare (clinical reasoning), finance (quant/macro reasoning), robotics (task planning)
- Tools/products: domain-tailored generative benchmarks with automated correctness checks; Pass@k-aware evaluators; merged-model snapshots for consistent assessments
- Assumptions/dependencies: trusted verifiers (simulation, rules, tests); domain data sharing and governance
- Energy-efficient training governance (Green AI)
- Sectors: energy, sustainability, cloud FinOps
- Tools/products: policies to avoid overtraining or misgating by using τ/PRR thresholds; evaluation schedulers minimizing redundant sampling; carbon-aware evaluation budgets
- Assumptions/dependencies: instrumentation for energy accounting; organizational buy-in to variance-aware policies
- Procurement and contracting standards for AI vendors
- Sectors: government, enterprise IT
- Tools/products: RFP language specifying Pass@k reporting for generative tasks, merging protocols, and stability metrics; acceptance criteria based on maximum PRR thresholds
- Assumptions/dependencies: legal/contract frameworks; benchmark portability across vendors
- Cross-model reproducibility and scaling-law research augmented with stability metrics
- Sectors: academia, labs
- Tools/products: meta-analyses incorporating τ and PRR; observational scaling laws that include stability terms; open datasets of merged vs. raw trajectories
- Assumptions/dependencies: multi-institution replication; standardized logging schemas
- Productized “StableEval” suites and SaaS offerings
- Sectors: ML tooling, DevOps platforms
- Tools/products: turnkey services implementing checkpoint merging, Pass@k, verifiers, τ/PRR analytics, and cost/stability trade-off guidance; plugins for PyTorch/DeepSpeed/OpenCompass
- Assumptions/dependencies: robust APIs; integration with customer pipelines; data privacy and compute management
- Robust public leaderboards with stability disclosures
- Sectors: benchmarks, open-source communities
- Tools/products: leaderboards that display Pass@k, τ, PRR, and evaluation cost per task; warnings where Pass@k is ill-suited (e.g., multiple-choice)
- Assumptions/dependencies: curator adoption; funding for increased evaluation compute
Key assumptions and dependencies across applications
- Checkpoint merging requires regular checkpoint saves and compatible architectures; merging window size N (often 4–8) is a tunable hyperparameter.
- Pass@k is best applied to generative tasks with automated verifiers; it is ill-suited for multiple-choice evaluations due to guessing effects.
- Stability metrics (Kendall’s τ and PRR) need consistent evaluation protocols and comparable downstream processes to be meaningful predictors.
- Compute, storage, and benchmarking discipline are essential; organizations must balance k (stability) against cost/time.
- Community and regulator acceptance are prerequisites for standardization, certifications, and procurement norms.
Glossary
- Ablation study: An experiment that systematically removes or varies components to assess their effect on performance. "We conduct an ablation study during a long-term, 10T-token pre-training run."
- Bernoulli trials: Independent binary experiments (success/failure) used to model high-variance single-output evaluations. "metrics based on a single output (e.g., greedy decoding) resemble high-variance Bernoulli trials."
- Checkpoint Merging: Averaging the weights of recent checkpoints to obtain a lower-variance model estimate and stabilize evaluation. "Checkpoint Merging improves parameter stability by averaging the weights of the last checkpoints, reducing the parameter noise variance by a factor of ."
- Concordant pairs: Pairs of observations whose ordering agrees between two variables; used in Kendall’s tau computation. "P is the number of concordant pairs, that is, pairs in which a later checkpoint achieves a higher score than an earlier one."
- Downstream performance: Model performance on tasks after pre-training, often following fine-tuning stages. "pre-training evaluation often fails to reliably predict final downstream performance."
- Element-wise average: Averaging corresponding elements of parameter vectors/matrices to form a merged model. "The parameters of the merged model, , are computed as their element-wise average:"
- Evaluation Instability: Variability in measured performance caused by fragile or noisy evaluation protocols. "Evaluation Instability: This variance is introduced by the fragility of measurement protocols."
- Generative tasks: Tasks requiring the model to produce outputs (e.g., code or math solutions) rather than select from fixed choices. "For generative tasks such as code generation or mathematical reasoning, metrics based on a single output (e.g., greedy decoding) resemble high-variance Bernoulli trials."
- Greedy decoding: Inference strategy that selects the highest-probability token at each step, yielding a single deterministic output. "metrics based on a single output (e.g., greedy decoding) resemble high-variance Bernoulli trials."
- Indicator function: A function that equals 1 if a condition is true and 0 otherwise; used to formalize rankings and counts. "and is the indicator function."
- Kendall's rank correlation coefficient (τ): A statistic measuring the monotonic association between ordered pairs, used to assess training trajectory stability. "we compute Kendall's rank correlation coefficient ()~\citep{kendall1938new} between the chronological sequence of checkpoints and their evaluation scores"
- Learning rate annealing: Gradually reducing the learning rate during training to follow a smoother trajectory and improve stability. "approximates the ideal model obtained by applying learning rate annealing along the ideal training trajectory"
- Loss landscape: The surface defined by the loss as a function of model parameters; its geometry (flat/sharp minima) affects optimization stability. "noisy or atypical regions of the loss landscape"
- Mixture-of-Experts (MoE): An architecture that routes inputs to a subset of specialized expert networks, enabling sparse activation and scalability. "Our primary model is a Mixture-of-Experts (MoE) model with 16.3B total parameters and 1.4B active parameters."
- Multiple-choice (MC) benchmarks: Evaluations with a limited set of discrete answer options, which can introduce sampling artifacts when repeatedly sampled. "Conversely, we observe a sharp decline in consistency for multiple-choice (MC) benchmarks (Knowledge)."
- Optimization stochasticity: Randomness from factors like data batching and dropout that causes variability in training trajectories and checkpoint quality. "Due to optimization stochasticity, individual checkpoints may occupy noisy or atypical regions of the loss landscape"
- Pairwise Ranking Reversal Rate (PRR): The proportion of model pairs whose relative ranking reverses between stages (e.g., pre-training vs. post-SFT). "we introduce the Pairwise Ranking Reversal Rate (PRR)."
- Pass@k: A metric estimating the probability that at least one of k generated samples is correct, reducing evaluation variance for generative tasks. "we adopt the Pass@k metric~\citep{humaneval}."
- Sharp local minimum: A narrow basin in the loss landscape where small parameter changes sharply increase loss, often yielding unstable performance. "A single checkpoint may represent a transiently suboptimal state or a sharp local minimum"
- Supervised Fine-Tuning (SFT): Post-training adaptation using labeled data to improve task-specific performance. "such as supervised fine-tuning (SFT)."
- Weight averaging: Averaging weights across multiple checkpoints or models to improve generalization and stability. "While weight averaging is known to construct versatile models"
Collections
Sign up for free to add this paper to one or more collections.

