Spotlight on Token Perception for Multimodal Reinforcement Learning
Abstract: While Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capabilities of Large Vision-LLMs (LVLMs), most existing methods in multimodal reasoning neglect the critical role of visual perception within the RLVR optimization process. In this paper, we undertake a pioneering exploration of multimodal RLVR through the novel perspective of token perception, which measures the visual dependency of each generated token. With a granular analysis of Chain-of-Thought (CoT) processes, we uncover two key insights: first, token perception in a rollout trajectory is sparsely distributed, where only a small fraction of tokens have high visual dependency for visually-grounded reasoning; second, different trajectories exhibit significant divergence in their overall visual dependency. Based on these observations, we propose Visually-Perceptive Policy Optimization (VPPO), a novel policy gradient algorithm that explicitly leverages token perception to refine the learning signal. Specifically, VPPO achieves this through a dual mechanism: it reweights a trajectory's advantage by its overall visual dependency, and focuses policy updates exclusively on perceptually pivotal tokens. On a comprehensive suite of eight perception and reasoning benchmarks, VPPO demonstrates substantial gains over leading open-source RL-tuned models, with its effectiveness consistently validated across 7B and 32B model scales. Our findings not only establish a new token-level perceptual perspective for analyzing multimodal RLVR but also present a novel and effective optimization strategy to significantly enhance the multimodal reasoning capabilities of LVLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching vision-and-language AI models (the kind that read both pictures and text) to truly “look” at images when they think. The authors show that, in many problems, only a few key words or steps in the AI’s answer actually depend on the picture. They create a new training method, called Visually-Perceptive Policy Optimization (VPPO), that pays extra attention to those picture-dependent moments so the model learns stronger, more honest visual reasoning.
Imagine solving a geometry question with a diagram: you don’t need the picture for every single sentence you write, but a few critical steps absolutely require it. VPPO helps the AI focus on those critical steps.
Objectives and Questions
The paper keeps the goals simple:
- Find out which parts of an AI’s answer really rely on the image.
- Check whether most answers contain only a small number of these picture-dependent, “pivotal” tokens.
- Use that information to train the model better—reward the answers that genuinely use the image and update the model mainly on the tokens that needed vision.
In plain terms: “Which words are truly ‘looking’ at the image, how many are there, and how can we train the AI to care more about them?”
Methods and Approach
First, here’s the training idea they start from:
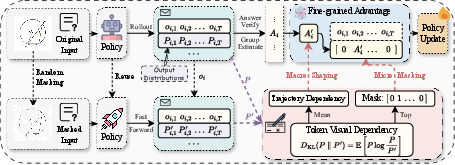
- Reinforcement Learning with Verifiable Rewards (RLVR): The model tries questions, and gets a reward (like a point) if the final answer is correct. A popular version, GRPO, computes a training signal (advantage) from a group of attempts. But in the old setup, every token in the answer gets treated the same; it doesn’t matter whether a token was image-based or not.
The paper adds a new lens: token perception.
- Token perception means “how much does the next word depend on the image?” To measure it, they compare the model’s next-word prediction with the real image versus with a perturbed image (think: blurred or masked). If the prediction changes a lot, that token depends strongly on the image. If it barely changes, that token is mostly text-only.
They make two key observations:
- Only a small fraction of tokens in an answer are truly image-dependent. Most tokens don’t need the picture.
- Entire answers (trajectories) differ: some are heavily grounded in the image, while others reach the right answer with little visual grounding (they might rely on guesses or text shortcuts).
Using these insights, they design VPPO:
- Trajectory-level Advantage Shaping (TAS): If an answer overall used the image more, boost its training signal. If it barely used the picture, reduce the signal. Think of a teacher giving extra credit to solutions that clearly used the diagram.
- Token-level Gradient Filtering (TGF): Update the model only on the top-k% most image-dependent tokens in each answer. This is like highlighting the few crucial steps that needed the picture and studying those, instead of wasting time on generic sentences.
Together, TAS and TGF make the training focus on the moments where vision truly matters.
Main Findings and Why They Matter
What they found:
- Token perception is sparse: only a few tokens per answer really depend on the image.
- Answers vary widely: some are strongly image-grounded; others are not.
What VPPO achieves:
- On eight tough benchmarks (math, geometry, logic, and mixed subjects), VPPO improves accuracy over strong open-source baselines.
- It works at different model sizes, showing gains for both 7B and 32B models. The paper highlights average improvements of about 19.2% for the 7B model and 7.6% for the 32B model compared to baselines.
- Training is more stable and faster to improve. Focusing on key tokens reduces noise and makes learning smoother.
- Ablation studies (turning parts on/off) show each component helps, and the full VPPO (TAS + TGF) works best.
- Choosing tokens by visual dependency beats other strategies like using high-entropy tokens or random selection. In multimodal tasks, the “pivotal” tokens can be low-entropy but highly image-based—VPPO finds those better.
Why this matters:
- The model learns to truly “think with images” instead of guessing through text patterns.
- It avoids rewarding shortcuts and strengthens genuine multimodal reasoning.
Implications and Impact
This work changes how we train vision-and-LLMs:
- Instead of treating every token equally, it prioritizes the few that actually needed the picture and rewards answers that clearly use visual evidence.
- This leads to smarter, more trustworthy reasoning in tasks that mix images and text, like geometry proofs, graphs-and-questions, and science problems with diagrams.
- VPPO can plug into existing reinforcement learning systems (like GRPO or DAPO), making it practical for many labs.
- The “token perception” idea offers a new, fine-grained way to analyze and improve multimodal reasoning, likely inspiring future methods that focus training where it truly counts.
In short: VPPO teaches AI to pay attention at the right moments, making it better at solving problems that require both seeing and thinking.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is framed to be concrete and actionable for future work.
- Clarify and standardize the “non-informative” image perturbation I′:
- Precisely define how I′ is constructed (global masking, blurring, patch dropout, text erasure, random noise, etc.) and provide a principled criterion for “non-informativeness” across varied image types (diagrams, photos, OCR-heavy images).
- Benchmark the sensitivity of token dependency scores to different perturbation strategies on diverse datasets (e.g., geometric diagrams vs. natural scenes vs. text-in-image) and report robustness metrics.
- Quantify compute/latency overhead of token-level dependency estimation:
- Measure training throughput and GPU hours with VPPO vs. GRPO/DAPO, including memory footprint and wall-clock time.
- Explore efficient approximations (e.g., cached logits, lower-precision forward passes, layer-skimmed inference, attention-based proxies, image feature ablations) that preserve performance while reducing cost.
- Address potential reward hacking of the dependency metric:
- Investigate whether models can artificially inflate KL-based dependency (e.g., by overreacting to masked images or manipulating token distributions) and propose safeguards (regularization, adversarial checks, cross-perturbation consistency tests).
- Disentangle visual vs. language confounds in dependency:
- Diagnose cases where high dependency arises from language context shifts (e.g., numerical tokens triggered by prior steps) rather than truly visual cues.
- Incorporate causal interventions (image-only vs. text-only vs. mixed ablations) to verify visual grounding per token.
- Adaptive mechanisms for token filtering ratio k:
- Replace fixed k with data- or trajectory-dependent schedules (e.g., distribution-aware k, uncertainty- or margin-based k, curriculum over k).
- Study early/late training dynamics to learn or schedule k automatically to balance exploration vs. focus.
- Adaptive advantage shaping beyond min–max normalization:
- Evaluate batch-composition biases introduced by per-batch min–max scaling (e.g., narrow dependency ranges yielding unstable α).
- Investigate learned or Bayesian weighting schemes, robust scaling (e.g., quantile-based, Winsorized), and cross-batch normalization to reduce variance and bias.
- On-policy/off-policy dependency computation alignment:
- Clarify whether dependency is computed under πθ or πold during training; analyze any bias introduced when using πθ while optimizing a clipped ratio objective.
- Compare outcomes when dependency is computed with πold to maintain strict on-policy alignment.
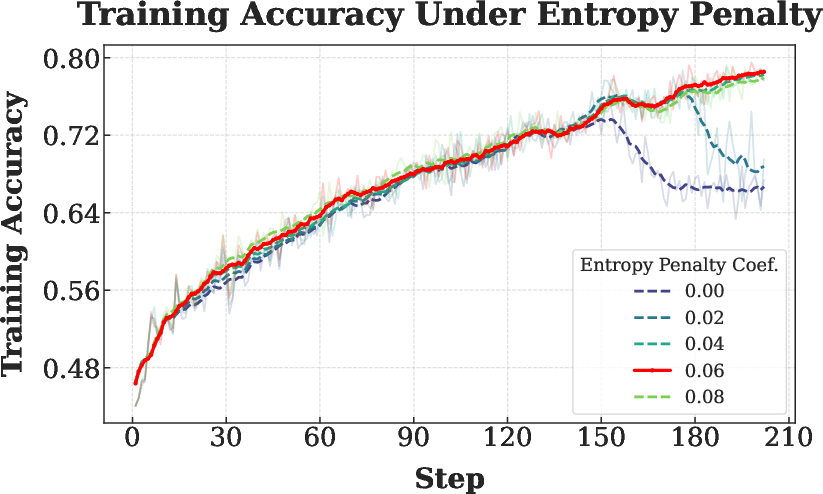
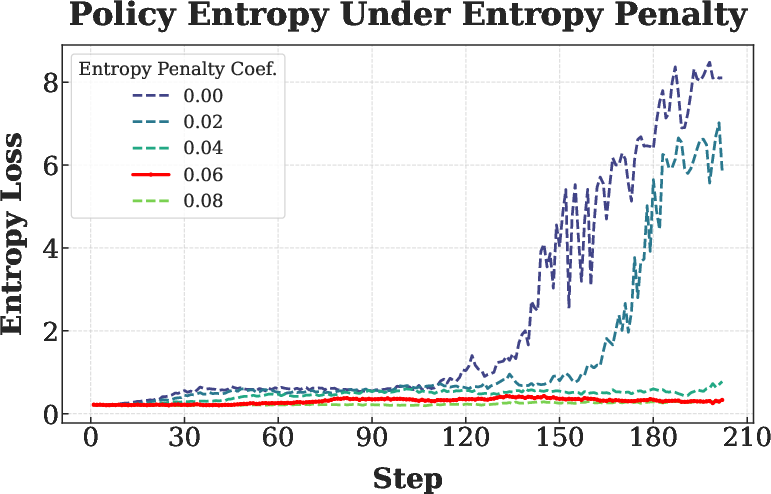
- Interaction with PPO-style clipping and entropy penalty:
- Provide a systematic ablation of clip ranges and entropy coefficients under VPPO to understand stability regions and tuning guidelines.
- Analyze whether gradient masking alters effective policy entropy and exploration, and how to compensate if needed.
- Impact on language fluency and connective tokens:
- Measure whether masking gradients for low-dependency tokens harms CoT readability, coherence, or grammaticality (e.g., via perplexity, syntactic metrics, human evaluation).
- Introduce guardrails to ensure essential connective tokens and reasoning scaffolding are not under-trained.
- Generalization across LVLM architectures and scales:
- Replicate on non-Qwen architectures (e.g., LLaVA, InternVL, Gemini-like open variants), different vision backbones, and multilingual settings to test portability.
- Assess whether dependency distributions and optimal hyperparameters (k, β) shift across models.
- Transfer to multi-image, video, and interactive tasks:
- Extend token dependency to temporal modalities and multi-view inputs (frame-wise or segment-wise dependency; sequence-level TAS).
- Explore VPPO in multi-turn and tool-augmented settings (e.g., retrieval, OCR tools), including token dependency on tool outputs.
- Integration with perception-aware intermediate rewards:
- Combine VPPO with verifiable step-level rewards (e.g., diagram recognition subgoals, geometric relation checks) to reinforce correct intermediate perception and reasoning.
- Evaluate whether TAS/TGF still help when richer, non-binary rewards are available.
- Robustness to OCR and diagram-specific artifacts:
- Test dependency estimation on images with heavy text (charts, worksheets) where masking strategies may disproportionately affect OCR signals.
- Develop perturbations that selectively disrupt visual content while preserving OCR to isolate true visual grounding.
- Rigorous theoretical guarantees:
- Strengthen the variance reduction analysis beyond “approximate” relationships by incorporating PPO clipping and masked gradients formally; provide bounds and assumptions with empirical variance measurements.
- Study convergence properties and bias/variance trade-offs under sparse gradient masks.
- Failure cases and negative transfer:
- Identify scenarios where visual information is weak or irrelevant (logic-only questions, abstract reasoning) and quantify any performance degradation caused by VPPO’s visual prioritization.
- Introduce detection or fallback mechanisms that relax VPPO in low-vision-dependency regimes.
- Batch-level dependency heterogeneity:
- Analyze how dependency distribution skew within a batch affects α scaling and gradient magnitude; propose batching strategies that stabilize TAS (e.g., stratified sampling by dependency).
- Safety, fairness, and bias considerations:
- Examine whether emphasizing visually salient tokens amplifies biases in images (e.g., demographic cues, stereotypes) and propose debiasing techniques within TAS/TGF.
- Evaluation beyond exact-match accuracy:
- Add step-level reasoning correctness, factual consistency, and visual grounding audits (e.g., human or automated CoT verification, attribution metrics) to understand qualitative effects of VPPO.
- Hyperparameter transferability:
- Report how k, βmin, and βmax generalize across datasets and tasks; provide tuning heuristics and sensitivity curves to facilitate reproducibility.
- Data and training budget comparability:
- Normalize training regimes against baselines (data size, epochs, compute) to ensure fair comparisons; include controlled experiments where all methods share identical budgets.
- Efficient dependency proxies:
- Investigate single-pass or differentiable proxies (e.g., attention-based image occlusion sensitivity, gradient-based attribution, mutual information estimates) that correlate with KL while being cheaper.
- Hybrid token selection strategies:
- Explore combining visual dependency with entropy, margin, or error-critical tokens to capture both perceptual and logical pivots; compare additive or multiplicative selectors.
- Open-source reproducibility details:
- Provide full training scripts, seeds, and logging to reproduce results; include ablation notebooks for perturbation strategies and dependency metrics.
- Long-term stability and continual learning:
- Study whether VPPO’s sparse updates maintain performance under continual RL or domain shift; examine catastrophic forgetting of low-dependency skills and mitigation strategies.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s open-source implementation of VPPO and its compatibility with mainstream RLVR systems (e.g., GRPO, DAPO). They leverage token-level visual dependency to improve training efficiency, robustness, and interpretability in multimodal vision–language systems.
- Software/AI platforms: Perception-aware RL fine-tuning for LVLM products
- Sector: Software, AI/ML tooling
- What it enables: Drop-in replacement for GRPO/DAPO that reweights advantages by trajectory visual dependency and filters gradients to top-k visually pivotal tokens, yielding faster convergence and higher accuracy on visually grounded tasks.
- Tools/workflows: “VPPO Trainer” component in existing RLVR pipelines; training dashboards that visualize token-level visual dependency; batch-level advantage shaping utilities.
- Assumptions/dependencies: Access to base LVLM logits, ability to run dual forward passes (original vs masked image) to compute KL-based dependency; verifiable reward design for tasks.
- Enterprise document assistants: More reliable reasoning over scans, forms, and slides
- Sector: Enterprise software, document intelligence
- What it enables: Reduced hallucinations and improved correctness on visually grounded steps in OCR-heavy workflows (e.g., invoice parsing, contract clause localization, slide Q&A).
- Tools/workflows: “Perception-grounded CoT gating” that flags outputs with low visual dependency even when answers are correct; evaluation reports showing a “visual grounding score” per response.
- Assumptions/dependencies: High-quality image preprocessing/masking; task-specific verifiers for exact-match rewards; domain adaptation to document formats.
- Chart and diagram question answering
- Sector: Finance, business intelligence, analytics
- What it enables: Better reasoning over plots, tables, KPIs, and schematic diagrams; improves trust in insights derived from visual dashboards.
- Tools/workflows: Chart-to-Insight assistants backed by VPPO-tuned LVLMs; pipeline that computes trajectory-level dependency to prefer visually grounded answers.
- Assumptions/dependencies: Data verifiers that can score numeric/logic answers; careful chart masking strategies to compute dependency without degrading semantic structure.
- Education: Math/geometry tutors that ground reasoning in the diagram
- Sector: Education, edtech
- What it enables: Step-by-step solutions with explicit reliance on diagrams (angles, arcs, isosceles properties), reducing shortcutting and enhancing pedagogical value.
- Tools/workflows: Tutor agents with “highlight pivotal tokens” overlays (e.g., values, geometric entities, logic markers like “Therefore”); teacher dashboards to assess grounding.
- Assumptions/dependencies: Verifiable problem sets; robust image masking method for dependency; privacy-safe deployment for student data.
- RPA/GUI agents: More reliable screen understanding for automation
- Sector: Software automation, RPA
- What it enables: Better perception–reasoning link when reading UI elements (labels, buttons, states) before deciding actions; reduced spurious clicks from language priors.
- Tools/workflows: Screen-reading agents trained with VPPO; runtime “visual-grounding score” to accept/reject an action plan.
- Assumptions/dependencies: Availability of verifiers for task success; image perturbation setup that preserves UI semantics during dependency computation.
- Dataset curation and curriculum design
- Sector: AI research and MLOps
- What it enables: Selecting and upweighting samples/trajectories with high visual dependency; filtering out text-only shortcuts; building perception-centric curricula.
- Tools/workflows: “Dependency-driven sampler” for data loaders; batch-level statistics to rebalance training; reports on dataset’s visual grounding distribution.
- Assumptions/dependencies: Compute overhead for double conditioning (I vs I’); reliable masking strategy; storage of token-level metrics.
- Model auditing and interpretability
- Sector: Compliance, AI governance
- What it enables: Token-level visual dependency as a diagnostic to verify that answers truly depend on the image; identifies spurious reasoning paths.
- Tools/workflows: Audit dashboards showing trajectory-level dependency; alarms when correct answers are achieved with low visual grounding; comparative audits across model versions.
- Assumptions/dependencies: Access to internal logits; consistent masked-image procedure; governance policies that accept dependency scores as evidence.
- Benchmarking and evaluation
- Sector: Academia, ML benchmarking
- What it enables: New “Visual Grounding Index” to complement exact-match scores; fairer model comparisons emphasizing perception-driven solutions.
- Tools/workflows: Evaluation scripts computing trajectory-level dependency histograms; per-benchmark dependency profiles; ablations on k and beta ranges.
- Assumptions/dependencies: Standardized masking protocols; task-specific verifiers; agreement on metrics among community stakeholders.
- Contact center and support analytics (non-clinical)
- Sector: Customer support, operations
- What it enables: More accurate reasoning over images users send (product photos, error screens, setup diagrams), improving resolution quality.
- Tools/workflows: VPPO-tuned assistant that highlights visually pivotal steps in an explanation; “low-grounding” flags to escalate cases.
- Assumptions/dependencies: Verifiable reward design for common support tasks; appropriate data privacy controls.
- Developer tooling: Perception-focused training monitors
- Sector: DevTools for ML
- What it enables: Real-time plots of token-level and trajectory-level dependency; automated hyperparameter sweeps for k and beta ranges to optimize training stability.
- Tools/workflows: VPPO monitoring plugin; CLI utilities to compute and export dependency distributions; integration with experiment trackers.
- Assumptions/dependencies: Logging of logits and masks; reproducible training seeds; sufficient GPU budget for dependency computation.
Long-Term Applications
These applications require additional research, scaling, domain adaptation, safety validation, and/or regulatory approval before broad deployment.
- Robotics and embodied agents
- Sector: Robotics, logistics, manufacturing
- What it enables: Agents that can read diagrams, labels, and instruction visuals to guide manipulation and assembly; perception-grounded planning under uncertainty.
- Tools/workflows: VPPO-extended RL for multimodal policies; sim-to-real pipelines measuring visual grounding during training; runtime gating on low dependency plans.
- Assumptions/dependencies: Robust visual verifiers in the physical world; reliable masked-image proxies for dependency; integration with control stacks and safety constraints.
- Clinical decision support with images (radiology, dermatology)
- Sector: Healthcare
- What it enables: Ensuring diagnostic reasoning is truly image-dependent (reducing prior-driven errors) and providing auditable visual-grounding metrics.
- Tools/workflows: “Perception audit” overlays for reports; trajectory-level gating in clinical inference; training curricula emphasizing perception.
- Assumptions/dependencies: Extensive validation, bias and safety audits; FDA/EMA approvals; domain-specific masking strategies; high-quality labeled datasets and verifiable reward design.
- Regulatory frameworks for multimodal AI
- Sector: Policy and governance
- What it enables: Standardizing visual-grounding measurements as part of compliance and transparency; mandating dependency reporting in high-stakes AI systems.
- Tools/workflows: Certification suites that include dependency metrics; conformance tests limiting low-grounding solutions; continuous monitoring requirements.
- Assumptions/dependencies: Broad stakeholder agreement on metrics; audited implementations; privacy-preserving logging of model internals.
- Finance and risk: Auditable visual analytics
- Sector: Finance, compliance
- What it enables: Regulator-acceptable reasoning over charts and disclosures with documented visual dependency; reduces liability from heuristic shortcuts.
- Tools/workflows: VPPO-trained analytics assistants with “grounded insight reports”; governance dashboards tracking dependency vs accuracy.
- Assumptions/dependencies: Domain-specific verifiers for financial tasks; policy acceptance of dependency metrics; strict data governance.
- Perception-aware inference-time controls
- Sector: Software, AI safety
- What it enables: Runtime mechanisms that dynamically steer generation towards higher visual dependency (e.g., re-decoding pivotal steps, escalating to tools when dependency is low).
- Tools/workflows: “Dependency-aware decoding” strategies; hybrid pipelines that invoke external vision tools at low-dependency tokens.
- Assumptions/dependencies: Fast dependency approximations without full dual-pass overhead; engineering research to stabilize inference-time interventions.
- Standardized multimodal benchmarks and metrics
- Sector: Academia, consortia
- What it enables: Community-wide adoption of trajectory-level dependency, dataset-level grounding distributions, and k/beta sensitivity analyses as standard reporting.
- Tools/workflows: Public leaderboards including grounding scores; curated benchmark splits emphasizing perception-heavy samples.
- Assumptions/dependencies: Consensus on masking protocols and dependency definitions; reproducible evaluation pipelines.
- Cross-modal generalization beyond vision
- Sector: Speech, AR/VR, multimodal interaction
- What it enables: Extending “token perception” to audio and spatial modalities (e.g., speech–text reasoning, 3D scene understanding) with modality-specific dependency metrics.
- Tools/workflows: KL-based dependency with audio perturbations or spatial occlusions; perception-aware RL for multimodal agents.
- Assumptions/dependencies: Reliable perturbation strategies for each modality; suitable verifiable rewards; base models competent in non-vision modalities.
- Energy-efficient training at scale
- Sector: AI infrastructure
- What it enables: Lower-variance gradients and sparse token updates to reduce wall-clock time and compute; better stability reduces reruns and waste.
- Tools/workflows: VPPO integrated with schedulers that optimize dual-pass overhead; adaptive k/beta tuning for cost–performance tradeoffs.
- Assumptions/dependencies: Empirical proof of net savings across diverse tasks; infrastructure support for dependency computation caching.
- Safety, fairness, and debiasing
- Sector: AI ethics and safety
- What it enables: Detecting and penalizing answers that rely on priors rather than visuals in sensitive domains; targeted retraining to improve equitable performance.
- Tools/workflows: Bias audits that correlate dependency with subgroup performance; corrective training that upweights high-dependency data for underperforming cohorts.
- Assumptions/dependencies: Rich labeled datasets; clear fairness objectives; governance oversight to interpret dependency metrics alongside outcomes.
- Consumer assistants and AR guidance
- Sector: Consumer software, education, maker/DIY communities
- What it enables: Assistants that ground step-by-step guidance in photos or AR views of manuals, devices, or experiments; reduces error-prone shortcuts.
- Tools/workflows: VPPO-tuned models embedded in AR flows; dependency-based highlights that show which visual regions mattered.
- Assumptions/dependencies: Robust on-device inference; privacy-preserving logging; scalable verifiers for consumer tasks.
Notes on feasibility and integration
- Required components: Base LVLM with accessible token probabilities; image perturbation/masking method; verifiable reward functions; RLVR runtime (GRPO/DAPO).
- Compute trade-offs: Dependency calculation requires dual conditioning (I vs I’). Savings accrue from lower-variance, sparse updates; net benefit depends on task and hardware.
- Hyperparameters: k (fraction of tokens updated) and beta range (advantage shaping) materially affect stability/accuracy; the paper’s defaults (k≈0.4, beta_min≈0.9, dynamic beta_max) are a solid starting point.
- Generalization: Effectiveness is strongest in visually grounded reasoning tasks (math, geometry, charts, logic). Domains with weak verifiers or minimal visual reliance may see smaller gains.
Glossary
- Advantage: In reinforcement learning, a measure of how much better an action or trajectory performs compared to a baseline within a batch. "The advantage for a response is its normalized reward:"
- Chain-of-Thought (CoT): A prompting and reasoning technique where models generate step-by-step intermediate reasoning to reach an answer. "With a granular analysis of Chain-of-Thought (CoT) processes"
- Clipped surrogate objective: The PPO-style objective that limits the policy update by clipping probability ratios to stabilize training. "The policy is then updated to maximize a clipped surrogate objective"
- Dynamic Sampling Policy Optimization (DAPO): An RL training framework for LLMs that uses dynamic sampling and clip-higher strategies. "While modality-agnostic algorithmic advances like Dynamic Sampling Policy Optimization (DAPO) introduce effective techniques like dynamic sampling and clip-higher"
- Entropy penalty: A regularization term that encourages exploration by penalizing low-entropy (overconfident) policies. "a small entropy penalty (coefficient 0.06) is applied"
- Exact-match scoring methodology: An evaluation method that scores answers strictly by exact equality with the ground truth, avoiding subjective judgments. "we use an exact-match scoring methodology, eliminating reliance on LLM-as-a-judge systems."
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes group-wise normalized advantages to mitigate reward sparsity for sequence models. "Reinforcement learning from verifiable rewards (RLVR), particularly with online algorithms like Group Relative Policy Optimization (GRPO)"
- Kernel Density Estimation (KDE): A non-parametric method to estimate the probability density function of a random variable from samples. "and a Kernel Density Estimation (KDE) curve is overlaid"
- Kullback-Leibler (KL) divergence: A measure of how one probability distribution diverges from another, used to quantify visual dependency. "This is quantified by computing the Kullback-Leibler (KL) divergence between the policy's predictive distribution conditioned on the true image versus a perturbed version"
- LLMs: High-capacity neural networks trained on large text corpora to perform language tasks. "While LLMs have achieved powerful reasoning in text-only domains"
- Large Vision-LLMs (LVLMs): Models that jointly process visual and textual inputs to perform multimodal tasks. "Large Vision-LLMs (LVLMs)"
- Policy gradient algorithm: A class of RL methods that optimize policies by ascending gradients of expected returns. "a novel policy gradient algorithm"
- Probability ratio: The ratio of new to old policy probabilities for a token, central to PPO-style updates. "where $r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} | I, q, o_{i,<t})}{\pi_{\theta_{\text{old}(o_{i,t} | I, q, o_{i,<t})}$ is the probability ratio."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm where rewards are computed from verifiable outcomes (e.g., exact-answer checks) rather than subjective judgments. "While Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capabilities of Large Vision-LLMs (LVLMs)"
- Rollout trajectory: A full sequence of states, actions, and outputs generated by the policy during inference/training. "token perception in a rollout trajectory is sparsely distributed"
- Shaped Advantage: A reweighted advantage that incorporates trajectory-level visual dependency to prioritize perceptually grounded paths. "creating a Shaped Advantage: $\hat{A}'(\tau_i) = \alpha(\tau_i) \cdot \hat{A}_{\text{GRPO}(\tau_i)$."
- Sparse binary token gradient mask: A binary filter that passes gradients only for selected (pivotal) tokens to reduce noise and variance. "create a sparse binary token gradient mask."
- Token perception: The measure of a token’s reliance on visual input, indicating its role in visually grounded reasoning. "novel perspective of token perception, which measures the visual dependency of each generated token."
- Token-level Gradient Filtering (TGF): A VPPO mechanism that applies gradients only to the top-k% visually dependent tokens. "Ablation of Trajectory-level Advantage Shaping (TAS) and Token-level Gradient Filtering (TGF)."
- Trajectory dependency: The average visual dependency over all tokens in a trajectory, reflecting how much the path relies on visual evidence. "trajectory dependency $\bar{\mathcal{S}(\tau)$"
- Trajectory-level Advantage Shaping (TAS): A VPPO mechanism that rescales advantages based on trajectory-level visual dependency. "Trajectory-level Advantage Shaping (TAS)"
- Variance Reduction: A theoretical property showing that the VPPO gradient estimator has lower variance than the baseline. "Variance Reduction"
- Visual dependency: The quantification of how much visual input affects a token’s predictive distribution. "which measures the visual dependency of each generated token."
- Visually-grounded reasoning: Reasoning steps that are explicitly supported by visual evidence from the input image. "selectively reward the specific, pivotal moments of visually-grounded reasoning"
- Visually-Perceptive Policy Optimization (VPPO): The proposed RL algorithm that reweights trajectory advantages and filters token gradients based on visual dependency. "we propose Visually-Perceptive Policy Optimization (VPPO), a novel policy gradient algorithm that explicitly leverages token perception to refine the learning signal."
Collections
Sign up for free to add this paper to one or more collections.

