PHyCLIP: $\ell_1$-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning (2510.08919v1)
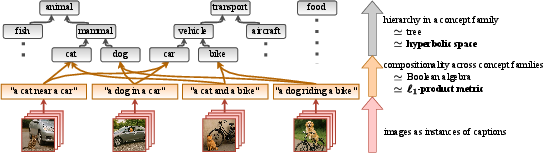
Abstract: Vision-LLMs have achieved remarkable success in multi-modal representation learning from large-scale pairs of visual scenes and linguistic descriptions. However, they still struggle to simultaneously express two distinct types of semantic structures: the hierarchy within a concept family (e.g., dog $\preceq$ mammal $\preceq$ animal) and the compositionality across different concept families (e.g., "a dog in a car" $\preceq$ dog, car). Recent works have addressed this challenge by employing hyperbolic space, which efficiently captures tree-like hierarchy, yet its suitability for representing compositionality remains unclear. To resolve this dilemma, we propose PHyCLIP, which employs an $\ell_1$-Product metric on a Cartesian product of Hyperbolic factors. With our design, intra-family hierarchies emerge within individual hyperbolic factors, and cross-family composition is captured by the $\ell_1$-product metric, analogous to a Boolean algebra. Experiments on zero-shot classification, retrieval, hierarchical classification, and compositional understanding tasks demonstrate that PHyCLIP outperforms existing single-space approaches and offers more interpretable structures in the embedding space.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for computers to understand both pictures and text at the same time. It focuses on two kinds of meaning:
- Hierarchy: how ideas fit into “is-a” families (like dog → mammal → animal).
- Compositionality: how different ideas combine (like “a dog in a car”).
The authors propose a model called PHyCLIP that represents both kinds of meaning together, so it can better understand complex descriptions and images.
Key Objectives
The paper asks three simple questions:
- How can we represent “is-a” hierarchies (like family trees of concepts) in a space that fits them well?
- How can we represent combinations of different concepts (like “dog” + “car”) in a clean, logical way?
- Can we build one system that does both at the same time and works well on real tasks?
Methods and Approach (Explained Simply)
Think of the model as a big cabinet with many drawers:
- Each drawer holds one “concept family” (for example, animals, vehicles, foods).
- Inside a drawer, ideas are organized like a family tree (dog is a kind of mammal, which is a kind of animal).
Here’s how PHyCLIP works:
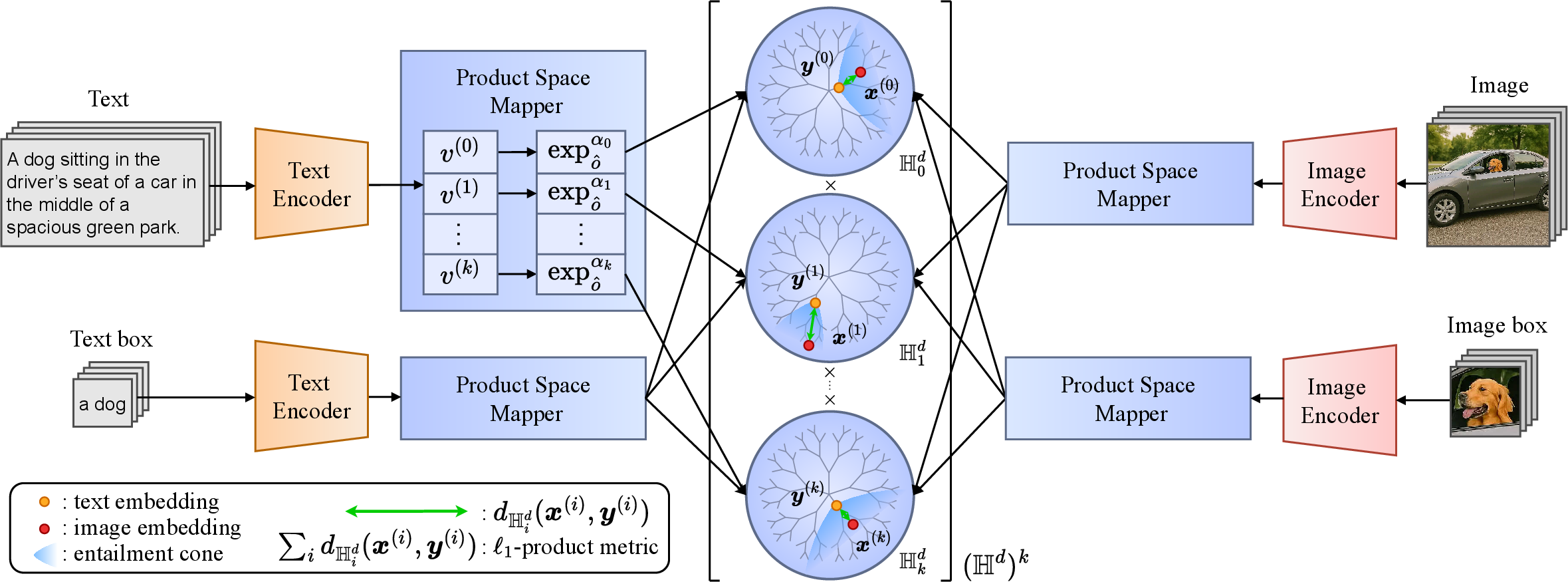
- Embeddings: The model turns images and text into points in a special space. This space is built from many smaller “hyperbolic” spaces, one per drawer. Hyperbolic space is good at representing tree-like structures, like family trees of concepts, because it has lots of room as you go “outward,” matching the way trees expand.
- Multiple hyperbolic factors: Instead of putting everything into one space, PHyCLIP uses many hyperbolic spaces at once (one per concept family). This helps the model keep families separate and tidy.
- L1-product metric: To compare two items (like an image and a caption), the model measures how far apart they are in each drawer and then adds those distances up. This is like checking a multi-part checklist and counting how many parts don’t match. Mathematically, this “sum of distances” is called an product metric, and it naturally behaves like logical “and” across families (dog and car).
- Entailment cones: Inside each hyperbolic drawer, the model draws a cone around a concept (like “mammal”). Points inside the cone are more specific concepts (“dog” is inside “mammal”). You can picture a cone-shaped flashlight beam: if a point falls inside the beam, it means “this is a kind of that.”
- Training with contrastive learning: The model learns by pulling matching image–text pairs closer and pushing non-matching pairs apart. It also learns to respect “is-a” relations using the cones. They train on a large dataset of image–text pairs with extra “boxes” that mark objects in the image and words in the text, which helps teach both hierarchy (what is a kind of what) and composition (what objects co-occur).
In short: PHyCLIP builds a space with many concept-family drawers (hyperbolic factors), compares things by summing differences across drawers (), and uses cone-shaped regions to encode “is-a” relations.
Main Findings and Why They Matter
The authors test PHyCLIP on several tasks without extra fine-tuning (“zero-shot”):
- Zero-shot image classification: PHyCLIP classifies images better than other popular methods (like CLIP, MERU, HyCoCLIP), especially on datasets with broad, mixed categories. This shows it learned clear concept families and hierarchies.
- Image–text retrieval: Given text, PHyCLIP is better at finding the right image (and competitive in the reverse direction). The sum-of-drawers idea helps penalize mismatches in any concept family, which makes it easier to spot wrong candidates.
- Hierarchical classification: PHyCLIP’s mistakes are “closer” to the correct answer in the concept tree (for example, guessing “mammal” instead of “reptile” when the correct answer is “dog”). This means it understands “is-a” relationships more naturally.
- Compositional understanding: On tests that specifically challenge models with combinations (like swapping objects or adding attributes), PHyCLIP is stronger overall. This supports the idea that handling composition across separate drawers makes representations cleaner and more logical.
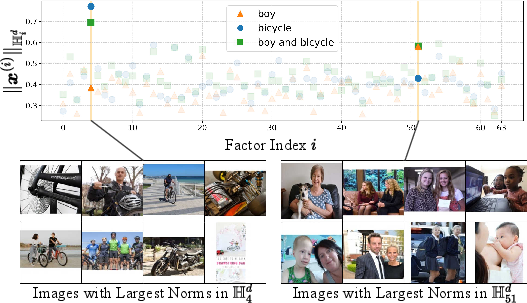
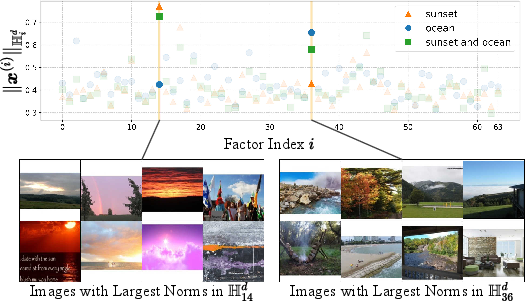
The model also produces more interpretable embeddings: when a concept is present, the corresponding drawer “lights up.” When two concepts are combined, multiple drawers activate together, just like a checklist.
Implications and Potential Impact
PHyCLIP shows that you don’t have to choose between hierarchy and composition—you can have both by:
- Using hyperbolic spaces for family-tree structure within each concept group.
- Using an sum across groups to handle combinations like “dog and car.”
This approach could improve:
- Search and recommendation (finding images or captions that match complex queries).
- Understanding fine-grained categories (like specific animals or foods) while keeping broad categories organized.
- Building more transparent AI systems, where we can see which concept families the model relied on.
Overall, PHyCLIP offers a clearer, more logical way to represent meaning in vision–LLMs, helping them understand both how ideas are nested and how they combine.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and actionable directions that emerge from the paper.
- Factor discovery and alignment: The model assumes k hyperbolic factors but does not provide a principled method to discover, align, or validate which concept families each factor represents; develop procedures (e.g., supervised alignment to WordNet/ConceptNet, clustering, sparsity constraints) to map factors to semantic families and measure alignment quality.
- Choice of k and d: No ablations or guidance on how the number of factors (k=64) and per-factor dimension (d=8) affect performance, interpretability, and compute; systematically characterize sensitivity, compute trade-offs, and scaling laws for kd under fixed training budgets.
- Identifiability and disentanglement: The paper claims interpretable “factor activation,” but provides no quantitative disentanglement metrics (e.g., Mutual Information Gap, modularity, SAP) or identifiability guarantees; formalize and measure factor disentanglement and stability across runs and datasets.
- Training without boxes: All primary results use box-level supervision; the impact of training without box annotations (or with noisy/missing boxes) is not reported; test performance and robustness in purely image–text settings and with varying annotation quality.
- Robustness to noisy auto-annotations: GRIT annotations are automatically generated and partially unavailable (14M vs documented 20.5M); quantify noise sensitivity (e.g., label flip rates, bounding box errors), and evaluate with controlled noise injection and human-annotated datasets.
- Generalization to larger pretraining corpora: Results are limited to GRIT; assess transfer when pretraining on broader corpora (e.g., LAION, CC12M, image-caption datasets), and how corpus diversity impacts factor specialization and compositional fidelity.
- Mixed-curvature design: All factors are negatively curved; examine whether certain families (e.g., colors, textures) are better modeled by Euclidean or spherical factors, and paper mixed-curvature (-product of Euclidean/Hyperbolic/Spherical) impacts.
- Metric choice (ℓ1 vs ℓ2): The ℓ1-product is motivated by Boolean/Hamming relations, but there are no comparative studies vs ℓ2-product or weighted ℓp-product metrics; conduct controlled comparisons and analyze effects on retrieval, compositional hard-negatives, and optimization stability.
- Factor weighting and relevance: Distances are averaged equally across factors; introduce and evaluate learned per-factor weights, gating, or sparsity-inducing penalties to emphasize relevant factors for a given instance and reduce interference from irrelevant ones.
- Explicit composition operators: The approach models conjunction implicitly via additive distances; define and evaluate explicit meet/join operators in the embedding space (e.g., per-factor min/max, cone intersections) for logical operations (AND/OR) and verify algebraic properties (associativity, commutativity, monotonicity).
- Beyond conjunction: The framework does not address negation, disjunction, quantification, or comparative constructs common in language; extend the model to represent and reason about negation (NOT), alternatives (OR), quantifiers (few/many), and superlatives.
- Cross-factor interactions: The ℓ1 sum assumes additive independence across families; many relations (e.g., “dog riding in car”) are inherently cross-factor; introduce interaction terms (e.g., pairwise cross-factor potentials, attention across factors) and quantify gains.
- Global order structure: Entailment is enforced per factor via cones, but the paper does not formalize the resulting partial order on the full product space or provide consistency guarantees (e.g., acyclicity, transitivity) across factors; prove or test global order properties.
- Distortion lower bounds: Proposition states no isometric embedding of Boolean lattices into a single hyperbolic space, but there are no lower bounds on distortions of hyperbolic approximations; derive comparative distortion bounds against Euclidean, box, and order embeddings for compositional posets.
- Tree-to-product embedding dimension: Theorem maps product of trees to (ℍ²)k quasi-isometrically, yet the practical choice d=8 is not justified; characterize minimal per-factor dimensions needed for typical taxonomies and their impact on learned curvature and cone apertures.
- Curvature learning dynamics: Per-factor curvatures −αi are learnable but unreported; analyze learned curvature distributions, their correlation with taxonomy depth/branching, and whether curvature annealing or priors improve hierarchy capture.
- Cone parameterization and margins: The entailment cones and margin η are critical but lack ablation; paper different cone parameterizations (aperture schedules, apex constraints), margin settings, and their effect on hierarchical metrics and false entailments.
- Loss balancing: The overall objective weight γ between contrastive and entailment losses is not explored; perform ablations to understand trade-offs and how γ influences retrieval vs hierarchical classification.
- Optimization properties: The ℓ1 sum of per-factor hyperbolic distances may introduce non-smooth gradient behavior; analyze optimization stability, gradient variance, and convergence compared to ℓ2-product and single-space baselines.
- Hard-negative generalization: Compositional understanding is evaluated via hard negatives (SugarCrepe, VL-CheckList), but there is no test of systematic compositional generalization to novel, held-out combinations; design split protocols to assess zero-shot composition.
- OOD robustness: Performance gaps on EuroSAT, FGVC-Aircraft, and Country211 suggest limitations; conduct comprehensive OOD analyses (texture, remote sensing, fine-grained vehicles, geography) and paper how factorization affects OOD behavior.
- Fairness and bias: No analysis of demographic or spurious correlation biases; audit factor embeddings for biased activations and evaluate bias mitigation strategies (e.g., debiasing losses per factor).
- Compute/memory profiling: The claim “same level as HyCoCLIP” is qualitative; provide detailed training/inference FLOPs, memory consumption, wall-clock, and scalability with k and batch size, including distributed training considerations.
- Slicing-based factor assignment: The encoder outputs kd features and slices them into k segments; investigate whether learned routing (mixture-of-experts, dynamic token-to-factor assignment) improves specialization and reduces entanglement.
- Visualization and interpretability metrics: The paper mentions visualizations where factors align to families, but lacks quantitative interpretability evaluation; define and report metrics (e.g., factor purity, mutual information with taxonomy labels, activation sparsity) and release visualization tools.
- Baseline breadth: Comparisons exclude order/box embeddings explicitly adapted to VL (beyond MERU/HyCoCLIP); add baselines with state-of-the-art box embeddings, lattice-based models, and recent compositional VL approaches for stronger empirical context.
- Multilinguality: The approach is only evaluated in English; assess multilingual performance (e.g., multilingual captions) and whether factor geometry remains stable across languages.
- Downstream tasks: The method is not evaluated on zero-shot detection/segmentation or visual question answering where compositionality and hierarchy are crucial; extend experiments to these tasks and analyze factor activation patterns in instance-level reasoning.
- Reproducibility risks: GRIT partially unavailable and auto-annotated; release code, preprocessed data subsets, and trained checkpoints, and provide detailed recipes to ensure reproducibility across hardware and software stacks.
Practical Applications
Practical, real-world applications of PHyCLIP
PHyCLIP introduces an l1-product of hyperbolic factors as the embedding space for vision–LLMs, enabling two capabilities that are difficult to reconcile in single-space models: (1) faithful encoding of intra-family hierarchies (is-a taxonomies) within each hyperbolic factor, and (2) Boolean-like compositionality across concept families via the l1 sum of per-factor distances. Empirically, PHyCLIP improves zero-shot classification, image–text retrieval, hierarchical classification (lower TIE/LCA), and compositional understanding. Below are actionable applications derived from these findings, organized by deployment horizon.
Immediate Applications
- Hierarchy-aware zero-shot classification at scale
- Sectors: software, media/DAM, retail/ecommerce, museums/archives, education
- Use cases:
- Auto-tagging and organizing large image libraries with taxonomy-aware labels (e.g., ImageNet- or WordNet-style hierarchies).
- Coarse-to-fine cataloging (e.g., “animal → mammal → dog”) with graceful degradation: when uncertain, predictions remain close in the taxonomy (lower TIE/LCA).
- Multi-granularity browsing UX that lets users navigate up/down the taxonomy.
- Tools/products/workflows:
- “Taxonomy-aware classifier” microservice that outputs both fine and ancestor labels with confidence.
- Batch re-indexing service for DAM systems to add hierarchical tags and reduce re-annotation cost.
- Dependencies/assumptions:
- Availability or construction of domain taxonomies (e.g., WordNet, product category trees).
- Model pretraining/fine-tuning on domain-relevant image–text pairs; bounding boxes further help but are not strictly mandatory.
- Cross-modal search and retrieval with compositional queries
- Sectors: media/advertising, ecommerce search, social platforms, journalism, enterprise knowledge management
- Use cases:
- Query-by-text for complex compositions (e.g., “a small red car with a dog inside”) with improved hard-negative rejection (e.g., car without dog; dog without car).
- Creative asset search (ad/brand teams) requiring multiple attribute conjunctions (object, relation, attribute).
- Tools/products/workflows:
- “PHyCLIP Search API” that supports filters over conceptual families (e.g., object, attribute, relation) and composes them via l1 distance.
- Catalog search widgets that surface which concept families drove a match (factor-level explanations).
- Dependencies/assumptions:
- Clean text metadata or captions; performance benefits are stronger on image retrieval than text retrieval (as observed).
- Domain adaptation when queries use specialized jargon.
- Safer, hierarchy-aware misclassification for downstream automation
- Sectors: content moderation, safety-critical triage, industrial QA
- Use cases:
- When misclassifications occur, they stay “close” in the taxonomy (e.g., mislabel a “corgi” as “dog,” not “car”), reducing harmful automation cascades.
- Thresholding strategies that escalate to human review when errors cross a taxonomy distance budget.
- Tools/products/workflows:
- Risk-aware classifiers that expose a “taxonomy-distance” confidence metric (TIE, LCA).
- Dependencies/assumptions:
- Calibrated decision thresholds; defined action policies based on taxonomy distance.
- Interpretable factor-level analytics and dataset debugging
- Sectors: MLOps/ML tooling, academia
- Use cases:
- Inspect which factors (concept families) activate for a prediction, aiding debugging, bias audits, and dataset curation (factor disentanglement/interpretability).
- Identify missing or imbalanced concept families in training data.
- Tools/products/workflows:
- “FactorViz” dashboard: per-factor distance/activation heatmaps for queries and predictions.
- Data balancing suggestions per concept family.
- Dependencies/assumptions:
- Emergent alignment between factors and concept families is unsupervised; light supervision or post-hoc mapping improves reliability.
- Semi-automatic annotation and taxonomy curation
- Sectors: data labeling platforms, libraries/archives, scientific repositories
- Use cases:
- Use entailment cones to suggest object-level boxes/phrases and hierarchical labels; human curators confirm/refine.
- Suggest taxonomy merges/splits by inspecting factor structures and near-neighbor cones.
- Tools/products/workflows:
- “TaxoTune” human-in-the-loop labeling UI that leverages factor-wise suggestions and hierarchical priors.
- Dependencies/assumptions:
- Availability of initial box-level data increases benefits (as in GRIT/HyCoCLIP-style training).
- Better multi-label and compositional tagging for consumer apps
- Sectors: consumer photo management, social media, note-taking
- Use cases:
- On-device or cloud photo search like “cat on sofa,” “kids in park at night,” with improved handling of conjunctions and attributes.
- Auto-generation of richer, multi-label captions organized by families (objects, attributes, relations).
- Tools/products/workflows:
- Lightweight inference pipeline that exports factor-aligned tags and hierarchical ancestors.
- Dependencies/assumptions:
- Privacy and on-device compute constraints; distilled or quantized variants may be needed.
- Retrieval-augmented generation (RAG) with compositional grounding
- Sectors: enterprise search, customer support, creative tools
- Use cases:
- Use PHyCLIP to select visual evidence matching complex text prompts before LLM reasoning or captioning.
- Reduce hallucinations by grounding in factor-constrained retrieval results.
- Tools/products/workflows:
- Plug-in retriever for multimodal RAG pipelines; factor-aware rerankers that penalize missing/extra concept families.
- Dependencies/assumptions:
- Integration effort with existing LLM stacks; domain-specific fine-tuning recommended.
Long-Term Applications
- Unified multi-ontology, multimodal knowledge graphs
- Sectors: healthcare, scientific publishing, legal/enterprise archives, public-sector information systems
- Use cases:
- Align images, captions, and structured ontologies (e.g., SNOMED/ICD in healthcare) where intra-ontology hierarchies and cross-ontology compositions both matter.
- Support complex queries like “skin lesion of type X on anatomical region Y under device Z.”
- Tools/products/workflows:
- Ontology-bridging embeddings where each ontology maps to factors; cross-family l1 composition encodes joint constraints.
- Dependencies/assumptions:
- High-quality ontologies and labeled multimodal corpora; regulatory-grade validation and privacy compliance.
- Compositional planners and perception for robotics and AR
- Sectors: robotics, autonomous systems, AR assistants, logistics
- Use cases:
- Ground complex instructions (“place the small blue box on the lower shelf to the left of the printer”) with factor-level parsing for objects, attributes, spatial relations.
- Scene retrieval and memory in AR: quickly find views/items satisfying conjunctive constraints.
- Tools/products/workflows:
- Factor-specialist modules (perceptual MoE) tied to PHyCLIP’s factors; compositional task planners that operate over factor Boolean-like algebra.
- Dependencies/assumptions:
- Real-time constraints; integration with detection/segmentation and 3D mapping; domain adaptation for embodied settings.
- Domain-specific, hierarchical multi-label diagnosis/coding from images
- Sectors: healthcare, manufacturing QA, geospatial/remote sensing
- Use cases:
- Map imaging findings to hierarchical codes (e.g., ICD, SNOMED) with controlled error locality; compositional labels for co-occurring conditions.
- Satellite imagery tagging with hierarchical land-use classes plus attributes (season, weather, event).
- Tools/products/workflows:
- Clinically supervised PHyCLIP variants with ROI annotations; audit trails using factor-level attributions.
- Dependencies/assumptions:
- Expert-labeled data, privacy/security; rigorous clinical validation; explainability requirements.
- Controlled, attribute-compositional content generation
- Sectors: creative tools, marketing, gaming
- Use cases:
- Use factor-aware embeddings as conditioning signals to compose attributes/objects with stronger disentanglement (e.g., “isometric room + neon lighting + wooden desk + two monitors”).
- Tools/products/workflows:
- Bridge PHyCLIP embeddings into diffusion/decoder models as structured conditioning vectors; sliders per concept family.
- Dependencies/assumptions:
- Co-training or alignment with generative backbones; robustness to distribution shifts in prompts.
- Safety, governance, and explainability for multimodal AI
- Sectors: policy/regulation, platform safety, enterprise risk
- Use cases:
- Factor-level explanations showing which concept families triggered a decision (e.g., policy-violating combinations).
- Hierarchy-aware fairness audits: compare performance across ancestor/descendant categories to detect systematic biases.
- Tools/products/workflows:
- Compliance dashboards that log factor activations and taxonomy-distance metrics for each decision.
- Dependencies/assumptions:
- Standardized reporting formats; accepted practices for multimodal explainability.
- Scalable training architectures via factor specialization
- Sectors: AI infrastructure, platform ML
- Use cases:
- Mixture-of-experts or adapter banks specialized by factor/family to scale training and inference efficiently.
- Tools/products/workflows:
- Factor-routed encoders/decoders; curriculum learning that activates factors progressively.
- Dependencies/assumptions:
- Stable factor identification; scheduling strategies to avoid collapse or over-fragmentation.
- Event mining and scenario search in autonomy and surveillance logs
- Sectors: autonomous driving, smart cities, transportation safety
- Use cases:
- Retrieve rare, compositional scenarios from petabytes of logs (e.g., “pedestrian crossing between parked cars in rain at night”).
- Tools/products/workflows:
- Factor-aware video indexing and query system leveraging l1 penalties for missing/extra elements.
- Dependencies/assumptions:
- Temporal extensions (video factors), robust attribute and relation extraction at scale.
Key assumptions and dependencies (cross-cutting)
- Data scale and annotations: The strongest gains are demonstrated with large-scale image–text data and benefit from box-level annotations (as in GRIT/HyCoCLIP). Domains without boxes may see reduced hierarchy/composition fidelity unless weak supervision or pseudo-labeling is used.
- Taxonomy availability: Hierarchical benefits rely on access to or construction of meaningful taxonomies/ontologies for the domain.
- Factor interpretability: Emergent alignment between factors and concept families is not guaranteed; light supervision or post-hoc mapping can improve reliability.
- Compute and integration: Training on tens of millions of pairs requires significant compute; productionizing requires integration with existing retrieval, classification, or RAG pipelines.
- Domain shift: Out-of-distribution domains (e.g., satellite imagery) may need targeted fine-tuning; text retrieval gains may be smaller than image retrieval without domain adaptation.
- Governance: For regulated sectors, additional validation, auditability tooling, and privacy controls are necessary before deployment.
Glossary
- Axis-aligned hyperrectangles: Rectangular regions aligned with coordinate axes in high-dimensional space, used to represent boxes in embeddings. "box embeddings use axis-aligned hyperrectangles in "
- Bag-of-words: A text representation that treats documents as unordered collections of words. "Boolean algebra, bag-of-words, and vector addition in word2vec"
- Boolean algebra: An algebraic structure with operations like conjunction, disjunction, and negation, often used to model composition. "captured by a Boolean algebra or an -product metric"
- Boolean lattice: The partially ordered set of all subsets of a concept set, ordered by inclusion. "the Boolean lattice $(2^{\mathcal{C},\subseteq)$ over all such subsets naturally represents the compositionality of atomic concepts as a non-taxonomic poset"
- Box embeddings: An embedding method that represents concepts as axis-aligned hyperrectangles (“boxes”) in Euclidean space. "box embeddings use axis-aligned hyperrectangles in "
- Cartesian product: The set of all tuples formed from multiple sets; here, used to construct multi-factor spaces. "an -Product metric on a Cartesian product of Hyperbolic factors"
- Contrastive loss: An objective that pulls paired examples closer and pushes unpaired examples apart. "We will introduce the contrastive loss $\mathcal{L}_{\text{cont}$"
- Contrastive pretraining: Training embeddings by contrasting positive pairs against negatives to enable transfer. "As exemplified by CLIP~\citep{Radford2021}, contrastive pretraining maps images and texts to embeddings"
- Disk embeddings: Representations that encode concepts as metric balls (disks/hyperballs) in a space. "disk embeddings use hyperballs~\citep{Suzuki2019}"
- Entailment cones: Geodesic cones rooted at concepts, where inclusion encodes “is-a” relations. "hyperbolic entailment cones, which encode partial orders via inclusion~\citep{Ganea2018}"
- Entailment loss: A penalty that enforces required inclusion (entailment) relations between embeddings. "We will introduce the contrastive loss $\mathcal{L}_{\text{cont}$ and entailment loss $\mathcal{L}_{\text{ent}$"
- Exponential map: A manifold operation that lifts a tangent-space vector to a point on the manifold. "each segment is lifted via the exponential map to its corresponding hyperbolic factor "
- Exterior angle: The angle used to test cone inclusion in entailment cone formulations. "for the exterior angle "
- Geodesic conical region: A cone defined by geodesics in curved space to encode hierarchical inclusion. "we define a geodesic conical region "
- Hamming distance: A metric counting differing coordinates between binary vectors. "finite Boolean algebras with the Hamming distance embed isometrically into an space"
- Hierarchical precision: Precision computed by comparing ancestor sets in a taxonomy. "hierarchical precision "
- Hyperballs: Metric balls in hyperbolic space used in disk embeddings. "disk embeddings use hyperballs~\citep{Suzuki2019}"
- Hyperbolic embeddings: Embedding techniques that place data in hyperbolic space to capture tree-like hierarchies. "This explains the empirical success of hyperbolic embeddings for hierarchical data"
- Hyperbolic factors: Individual hyperbolic spaces that are combined to form a product space. "an -product metric space of hyperbolic factors"
- Hyperbolic geometry: Geometry with constant negative curvature suited to representing trees. "hyperbolic geometry aligns well with this growth~\citep{Bridson1999, Sarkar2011}"
- Hyperbolic space: A negatively curved space effective for hierarchical representations. "hyperbolic space, which efficiently captures tree-like hierarchy"
- Hypernymy/hyponymy: Semantic “is-a” relations between general and specific concepts. "is-a (hypernymy/hyponymy, generalization/specialization, entailment) relations form a partially ordered set (poset)"
- InfoNCE loss: A standard contrastive objective for representation learning. "we use the standard InfoNCE loss~\citep{Radford2021, Desai2023, Pal2025}"
- Is-a taxonomy: A hierarchical organization based on “is-a” relations. "We evaluate the expressivity for the is-a taxonomy via hierarchical classification"
- Jaccard similarity: A set-based similarity equal to intersection over union. "Jaccard similarity , hierarchical precision , and hierarchical recall "
- Lattice: A poset where any two elements have both a meet and a join. "A lattice is a poset in which any two nodes have both a common generalization (join) and a common specialization (meet)"
- Learnable curvature: A parameterized manifold curvature optimized during training. "we adopt the Lorentz model with a learnable curvature "
- ℓ1-product metric: A product-space metric defined as the sum of per-factor distances. "we propose PHyCLIP, which employs an -Product metric on a Cartesian product of Hyperbolic factors"
- Lorentz model: A model of hyperbolic space based on Lorentzian geometry. "we adopt the Lorentz model with a learnable curvature "
- Lowest Common Ancestor (LCA): The nearest shared ancestor of two nodes in a hierarchy. "Lowest Common Ancestor (LCA) error"
- Metric tree: A tree viewed as a metric space with shortest-path distances. "For every finite metric tree (and every infinite metric tree with known bounds for maximum degree and minimum edge length)"
- Möbius addition: A hyperbolic-space operation analogous to vector addition. "M\"obius addition in hyperbolic spaces~\citep{Ungar2008} is not aligned with standard vector addition or Boolean structures"
- Order embeddings: Encodings that represent partial orders via coordinate-wise inequalities. "Order embeddings ~\citep{Vendrov2016} assign each concept a point "
- Poset: A set with a reflexive, antisymmetric, and transitive order. "A poset is a set equipped with an order relation (which is reflexive, antisymmetric, and transitive)"
- Quasi-isometric embedding: A mapping that preserves distances up to bounded distortion. "there exists a -quasi-isometric embedding up to scaling"
- Recall at k (R@k): A retrieval metric indicating whether the target appears in the top-k results. "We report Recall at (R@)"
- Riemannian product metric: An ℓ2-based product metric on manifolds. "our space uses an -product metric rather than a Riemannian () product metric"
- Taxonomic hierarchy: A tree-like organization of concepts by type and subtype. "tree-like taxonomic hierarchies"
- Tree Induced Error (TIE): Error measured as graph distance in a taxonomy. "Tree Induced Error (TIE) is their graph distance"
- Upper orthants: Regions defined by coordinate-wise lower bounds extending to infinity. "associated upper orthants "
- WordNet: A lexical database of words and semantic relations used for hierarchical evaluation. "Large lexical resources such as WordNet provide such relations"
Collections
Sign up for free to add this paper to one or more collections.

