- The paper presents HLFormer, a dual-branch architecture that leverages hyperbolic attention to model hierarchical semantics in untrimmed videos for improved retrieval performance.
- It combines Euclidean and Lorentz attention blocks with a Mean-Guided Adaptive Interaction Module and introduces a Partial Order Preservation loss for semantic alignment.
- Empirical evaluations on ActivityNet, TVR, and Charades benchmarks demonstrate significant improvements over state-of-the-art models with SumR gains up to 5.4%.
Introduction
Partially Relevant Video Retrieval (PRVR) is a challenging retrieval paradigm where the goal is to match untrimmed videos with text queries that describe only a subset of the video content. Unlike conventional text-to-video retrieval (T2VR), which assumes full semantic overlap between query and video, PRVR must address the partial relevance and inherent semantic hierarchy of long, untrimmed videos. The paper "HLFormer: Enhancing Partially Relevant Video Retrieval with Hyperbolic Learning" (2507.17402) introduces HLFormer, a novel framework that leverages hyperbolic geometry to more effectively model the hierarchical structure of video content and the partial entailment between text and video. This essay provides a technical analysis of HLFormer, focusing on its architectural innovations, empirical results, and implications for future research.
Motivation: Hierarchical Semantics and the Limitations of Euclidean Space
Untrimmed videos naturally exhibit a hierarchical structure, progressing from frames to segments, moments, and the entire video. In PRVR, queries often refer to specific moments, making it essential to model both fine-grained and coarse-grained semantics. Existing methods predominantly operate in Euclidean space, which is ill-suited for representing hierarchical relationships due to its flat geometry. In Euclidean space, embeddings of semantically distant moments may be close, leading to geometric distortion and suboptimal retrieval performance.
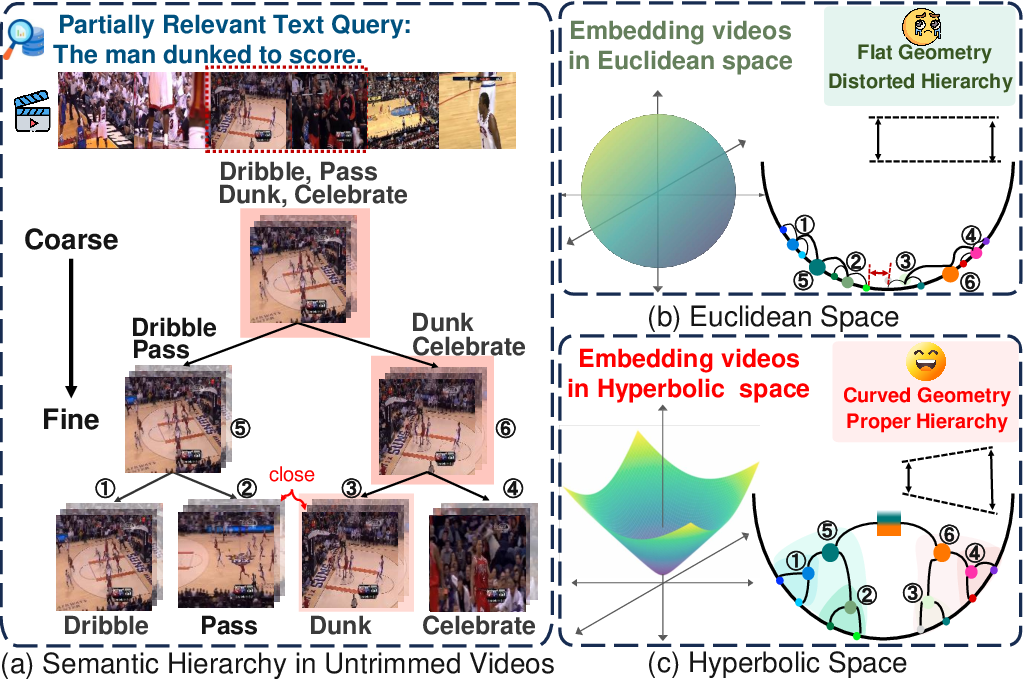
Figure 1: (a) Modeling the semantic hierarchy in untrimmed videos helps PRVR. (b) Euclidean space is less effective in modeling semantic hierarchy due to flat geometry. (c) Hyperbolic space allows larger cardinals near the edge, preserving hierarchy.
Hyperbolic space, with its negative curvature, provides exponentially expanding capacity, making it more suitable for encoding hierarchical data. HLFormer exploits this property to better capture the semantic structure of videos and the partial order between text and video.
HLFormer is a dual-branch architecture that encodes video and text representations in both Euclidean and hyperbolic (Lorentz) spaces, dynamically fusing them for robust cross-modal retrieval.
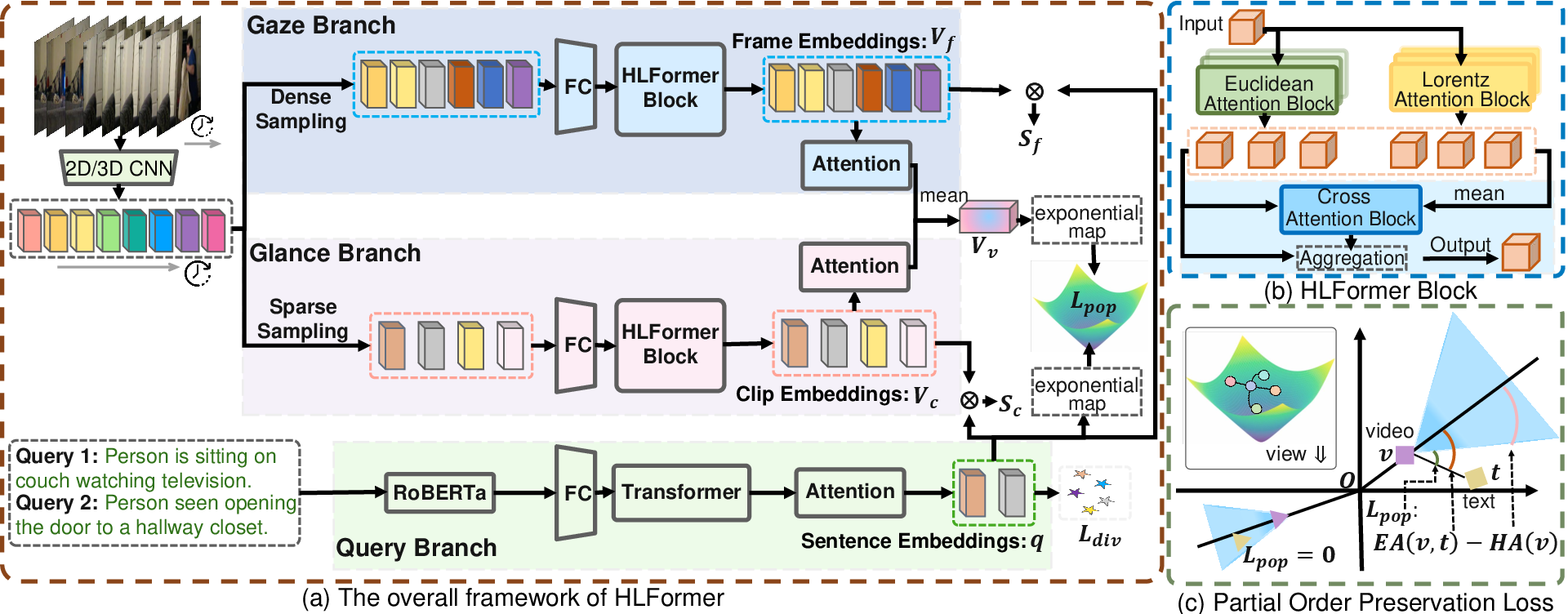
Figure 2: Overview of HLFormer. (a) Sentence embedding q is obtained via the query branch; gaze and glance branches encode the video at frame and clip levels, respectively. (b) HLFormer block combines parallel Lorentz and Euclidean attention blocks with a Mean-Guided Adaptive Interaction Module. (c) Partial Order Preservation Loss ensures text embedding t lies within the cone defined by video embedding v.
Video and Text Representation
- Text Encoding: Queries are encoded using RoBERTa, projected to a lower-dimensional space, and aggregated via attention to obtain a sentence embedding.
- Video Encoding: Two branches are used:
- Gaze Branch: Densely samples frames for fine-grained representation.
- Glance Branch: Aggregates frames into clips for coarse-grained representation.
- Both branches process features through HLFormer blocks, which include both Euclidean and Lorentz attention mechanisms.
- Euclidean Attention Block: Implements Gaussian-weighted self-attention to capture local, fine-grained interactions.
- Lorentz Attention Block: Projects features into Lorentzian hyperbolic space using exponential and logarithmic maps, then applies Lorentzian self-attention to capture hierarchical structure.
- Mean-Guided Adaptive Interaction Module (MAIM): Dynamically fuses outputs from multiple attention blocks (Euclidean and Lorentz) using global context, enabling adaptive weighting of hierarchical and local features.
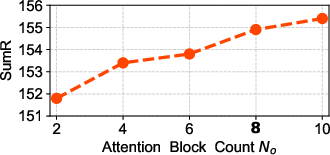
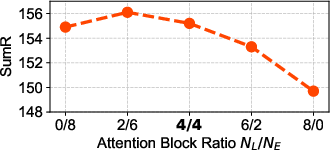
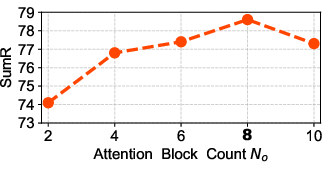
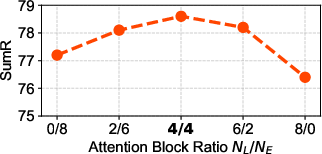
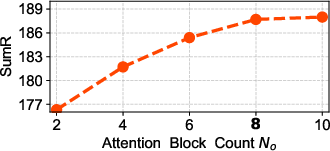
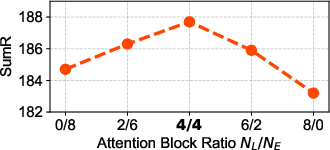
Figure 3: The influence of different attention blocks, with default settings marked in bold.
Ablation studies demonstrate that hybridizing Euclidean and Lorentz attention blocks yields superior performance compared to using either alone, confirming the complementary nature of local and hierarchical modeling.
Partial Order Preservation Loss
A key innovation is the Partial Order Preservation (POP) loss, which enforces the semantic entailment "text ≺ video" in hyperbolic space. This is achieved by defining an entailment cone for each video embedding in Lorentz space; the corresponding text embedding is penalized if it falls outside this cone. The loss is formulated as:
Lpop(v,t)=max(0,EA(v,t)−HA(v))
where EA(v,t) is the exterior angle between video and text embeddings, and HA(v) is the half-aperture of the entailment cone. This geometric constraint ensures that text queries are embedded within the semantic scope of their paired videos, preserving partial relevance.
Empirical Results
HLFormer is evaluated on three PRVR benchmarks: ActivityNet Captions, Charades-STA, and TVR. It consistently outperforms state-of-the-art baselines, including both PRVR-specific and general T2VR/VCMR models.
- On ActivityNet Captions, HLFormer achieves a SumR of 154.9, surpassing the previous best (DL-DKD) by 4.9%.
- On TVR, HLFormer achieves a SumR of 187.7, a 4.3% improvement over DL-DKD.
- On Charades-STA, HLFormer exceeds PEAN by 5.4% in SumR.
Ablation studies confirm the necessity of both multi-scale (gaze/glance) branches and the POP loss. Removing either branch or the POP loss leads to significant performance degradation.
Analysis of Hierarchical Representation
Visualization of learned embeddings using UMAP reveals that Lorentz attention leads to more discriminative and hierarchically organized clusters compared to Euclidean-only models.
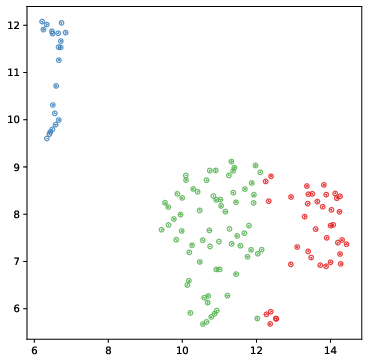
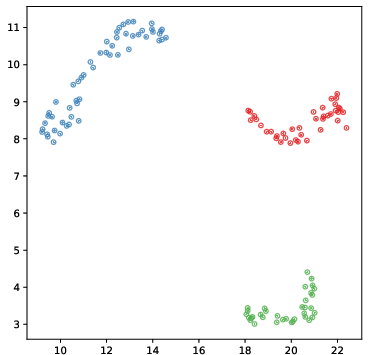
Figure 4: UMAP visualization of learned frame embeddings from a TVR video. Lorentz attention yields more distinct and compact clusters.
Further, analysis of the hyperbolic space shows that embeddings closer to the origin correspond to higher semantic hierarchy and coarser granularity, consistent with the theoretical properties of hyperbolic geometry.
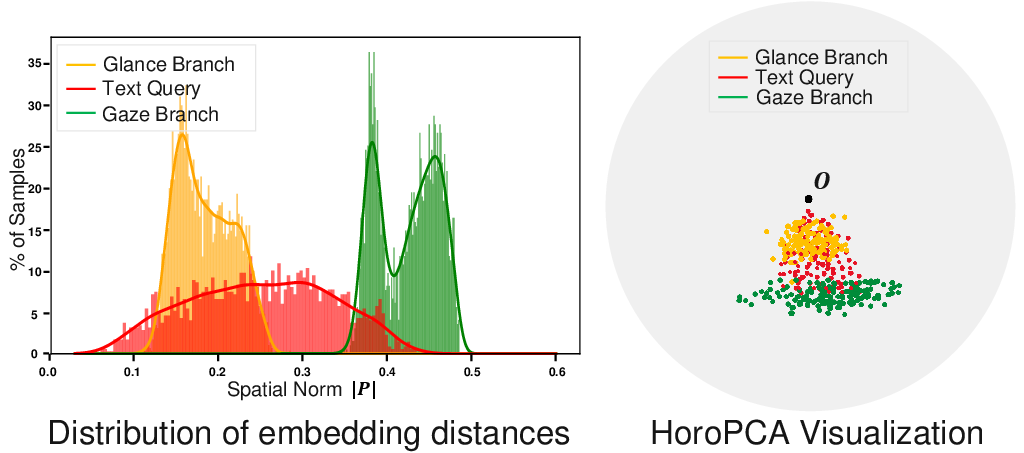
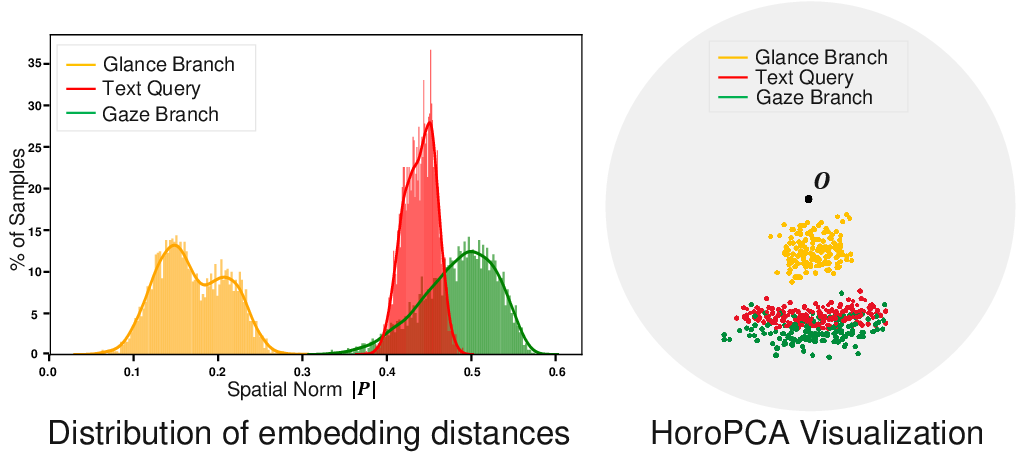
Figure 5: Visualization of the learned hyperbolic space. Proximity to the origin indicates higher semantic hierarchy and coarser granularity.
Implementation Considerations
- Computational Overhead: The Lorentz attention block introduces additional computational complexity due to the exponential/logarithmic mapping and Lorentzian operations. However, the authors report that the model can be trained efficiently on a single RTX 3080 Ti GPU.
- Numerical Stability: Careful scaling and normalization are required to prevent numerical instability in hyperbolic space, particularly for deep architectures.
- Hybrid Fusion: The MAIM module is critical for balancing the strengths of Euclidean and hyperbolic representations, and its design is lightweight yet effective.
- Generalization: The approach is robust across datasets with varying video lengths and annotation densities, indicating strong generalization.
Implications and Future Directions
HLFormer demonstrates that hyperbolic geometry provides tangible benefits for tasks involving hierarchical and partially entailed semantics, such as PRVR. The explicit modeling of partial order via geometric constraints is a principled approach that could be extended to other cross-modal retrieval and hierarchical representation learning tasks.
Potential future directions include:
- Fully Hyperbolic Architectures: Exploring end-to-end hyperbolic neural networks for all modalities.
- Uncertainty Modeling: Integrating uncertainty-aware mechanisms in hyperbolic space for more robust retrieval.
- Scalability: Optimizing hyperbolic operations for large-scale deployment and real-time retrieval.
- Generalization to Other Modalities: Applying similar geometric constraints to other multi-modal or hierarchical tasks, such as document retrieval or knowledge graph embedding.
Conclusion
HLFormer introduces a principled framework for PRVR by leveraging hyperbolic geometry to model semantic hierarchy and partial relevance. Its dual-space architecture, hybrid attention mechanisms, and partial order preservation loss collectively yield state-of-the-art performance on multiple benchmarks. The results substantiate the claim that hyperbolic learning is advantageous for hierarchical representation and cross-modal retrieval, providing a foundation for further research in geometric deep learning for structured data.