- The paper introduces a novel transformer-based framework that enables multi-modal user controls for video inbetweening.
- It employs dual-branch encoding and stage-wise training strategies to ensure robust motion, depth, and content synthesis.
- Experimental results on DAVIS and UCF datasets show improved temporal consistency with lower FVD and Motion scores.
MultiCOIN: Multi-Modal Controllable Video Inbetweening
Introduction and Motivation
MultiCOIN addresses the challenge of video inbetweening—generating temporally coherent and visually plausible intermediate frames between two keyframes—by introducing a framework that supports multi-modal user controls. Traditional frame interpolation methods, including flow-based and kernel-based approaches, struggle with large or complex motions and lack fine-grained user control. Recent generative models, such as those based on diffusion, have expanded the solution space but still fall short in accommodating diverse user intents. MultiCOIN is designed to fill this gap by enabling control over motion trajectories, depth transitions, target regions, and semantic content via text prompts, all within a unified architecture.
MultiCOIN Architecture
MultiCOIN is built upon the Diffusion Transformer (DiT) backbone, leveraging its capacity for long-range spatio-temporal modeling and high-quality video synthesis. The architecture is modular, with distinct components for motion and content control, each mapped into the latent space compatible with DiT's 3D VAE.
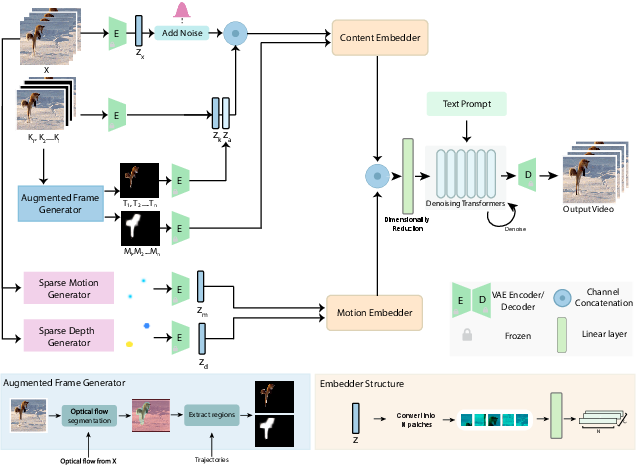
Figure 1: Overview of the MultiCOIN pipeline, illustrating the extraction and encoding of multi-modal controls and their integration into the DiT-based generative process.
Motion and Depth Control
Motion control is achieved via the Sparse Motion Generator, which extracts dense optical flow from the input video and selects high-magnitude trajectories. Depth control is handled by the Sparse Depth Generator, which computes depth maps and samples along the selected trajectories. Both modalities are converted to RGB representations to ensure compatibility with the DiT VAE, and sparse control points are expanded using Gaussian (for flow) and disk (for depth) filters to improve spatial coverage.
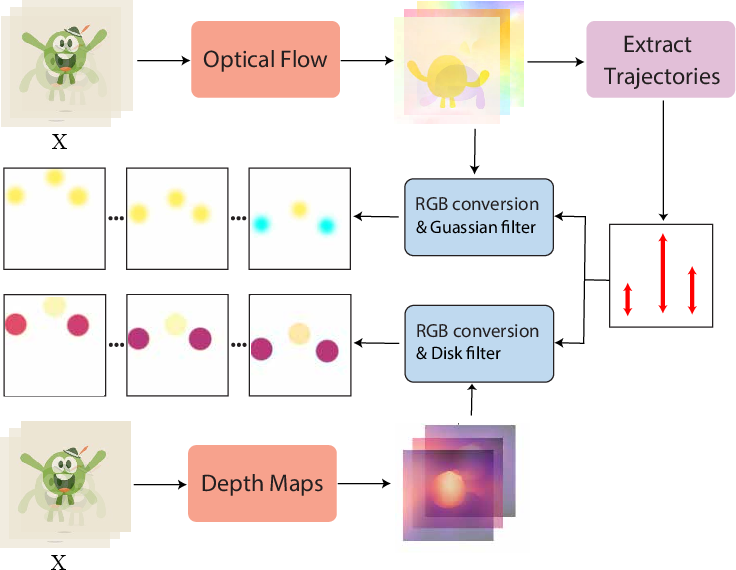
Figure 2: Sparse Motion and Depth Generator workflow, showing the extraction and expansion of motion and depth points into sparse RGB controls.
Depth anchors are introduced during inference to resolve ambiguities in single-point inputs, providing global context for relative depth interpretation.
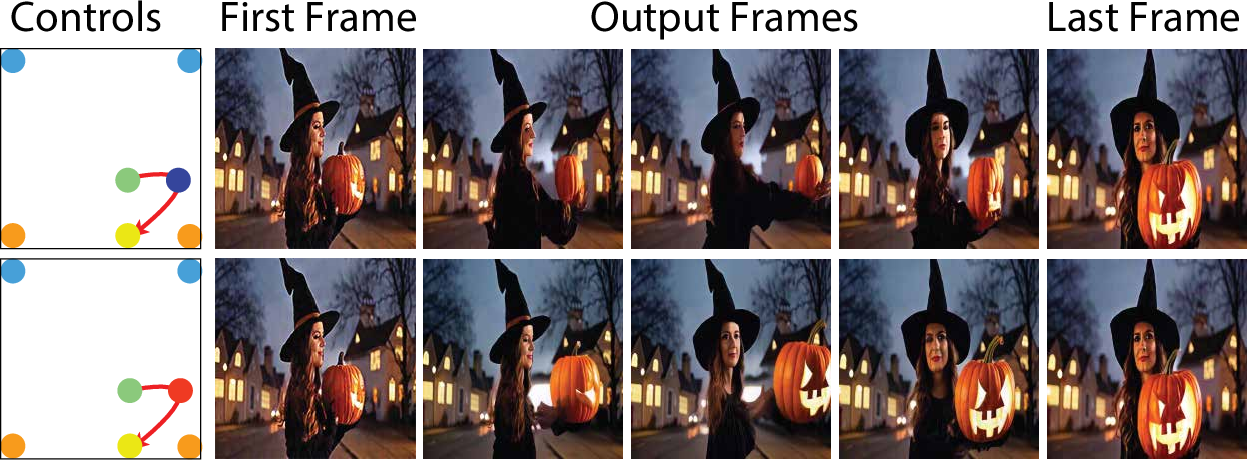
Figure 3: Example illustrating the effect of depth control on object layering along a trajectory.
Content Control via Target Regions
The Augmented Frame Generator enables regional content control by extracting regions of interest from keyframes and propagating them along motion trajectories. Binary masks are used to distinguish valid regions, and these controls are encoded separately from motion signals. This mechanism allows users to specify precise content placement and movement, reducing the need for extensive trajectory annotation.
Dual-Branch Embedding and Stage-wise Training
To harmonize the diverse control signals, MultiCOIN employs a dual-branch embedder architecture: one branch for content (keyframes, target regions, masks) and another for motion (flow, depth). Each branch encodes its respective inputs via a frozen VAE and linear patch embedding, followed by concatenation and integration into the transformer denoiser.
Stage-wise training is critical for effective learning of multi-modal controls. The model is first trained on image interpolation, then progressively introduced to dense motion/depth, sparse controls, and finally target regions. This curriculum mitigates the risk of the model ignoring sparse or high-level controls and ensures robust adherence to user intent.
Experimental Results
MultiCOIN is evaluated on DAVIS and UCF (Sports Action) datasets, with comparisons to Framer, the only baseline supporting trajectory control. Metrics include SSIM, FVD, LPIPS, and a custom "Motion" metric based on Fréchet Distance between input and output trajectories.
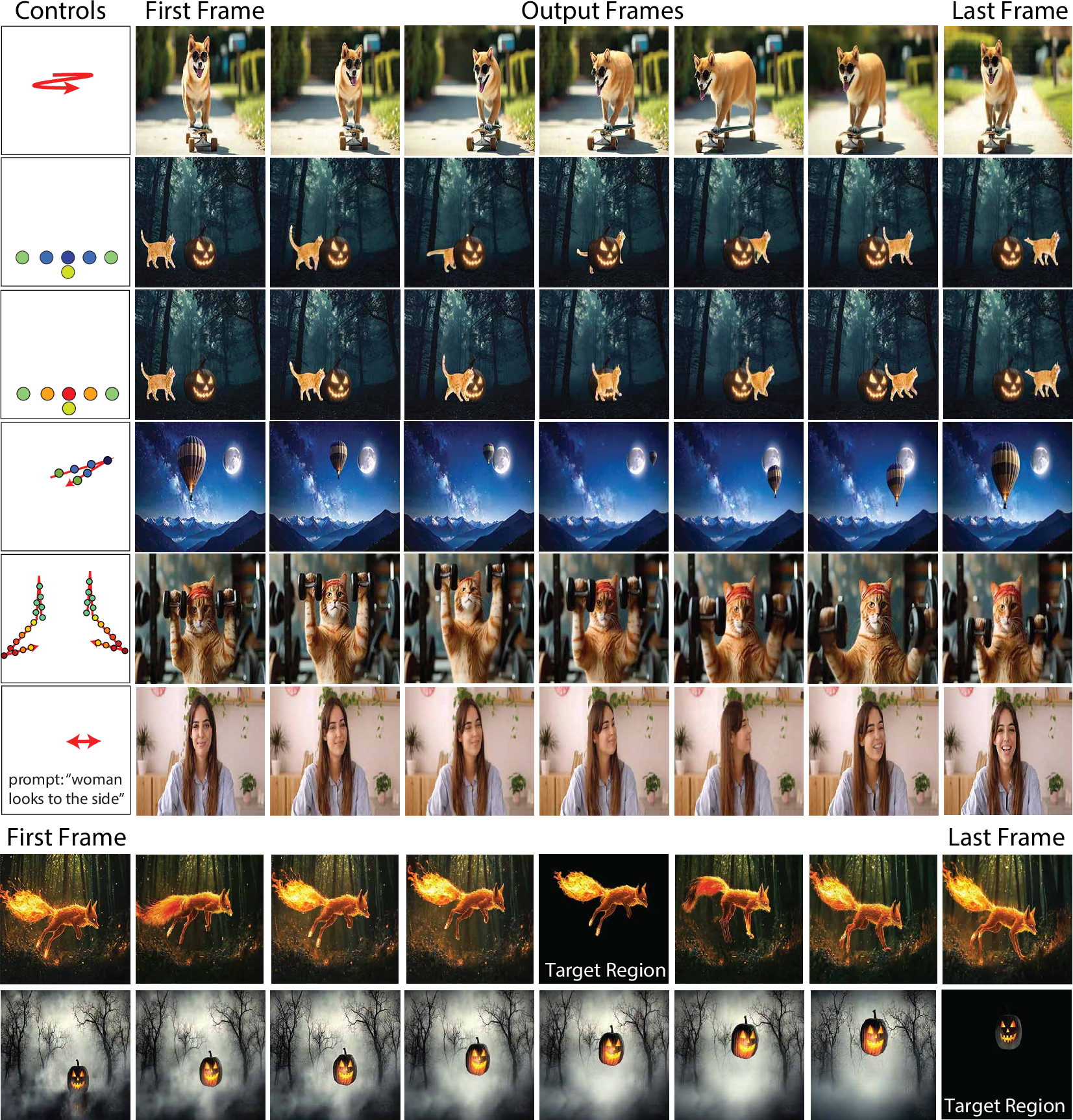
Figure 4: Qualitative results demonstrating the versatility of multi-modal controls, including trajectory, depth, target regions, and text prompts.
MultiCOIN consistently achieves lower FVD and Motion scores, indicating superior temporal consistency and trajectory adherence. LPIPS scores are competitive, and SSIM is slightly lower on DAVIS, attributed to pixel-level alignment sensitivity. Notably, MultiCOIN supports more than two input frames and can handle image deformation tasks.

Figure 5: Comparison with Framer, highlighting reduced distortion and improved control fidelity in MultiCOIN outputs.

Figure 6: Results with more than two input frames, demonstrating flexible interpolation with and without motion input.

Figure 7: Image deformation results, showcasing the model's ability to handle non-rigid transformations.
Ablation Studies
Ablation experiments confirm the necessity of stage-wise training and dual-branch encoding. Direct training on sparse controls or using a single-branch encoder leads to degraded motion localization, depth misinterpretation, and increased artifacts.

Figure 8: Ablation results showing the impact of omitting stage-wise training and dual-branch encoding on motion fidelity and artifact prevalence.
Implications and Future Directions
MultiCOIN demonstrates that integrating multi-modal controls into a transformer-based video diffusion framework enables fine-grained, user-driven video interpolation. The dual-branch architecture and stage-wise training are essential for disentangling and harmonizing content and motion signals. The approach is extensible to other forms of control, such as semantic segmentation or object tracking, and can be adapted for longer video synthesis or animation tasks.
Challenges remain in balancing strong content conditioning with motion cues, as excessive content control can suppress trajectory adherence. Future work may explore adaptive weighting of control signals, lightweight pre-processing modules for better alignment, and integration with interactive editing interfaces.
Conclusion
MultiCOIN establishes a robust framework for multi-modal controllable video inbetweening, achieving high-quality, temporally consistent interpolations with strong adherence to user-specified controls. The modular design, dual-branch encoding, and stage-wise training collectively advance the state of controllable video synthesis. The methodology is well-positioned for further extension to more complex editing scenarios and integration with emerging generative video models.