- The paper establishes the first non-asymptotic efficiency bounds by providing explicit finite-sample rates dependent on training size, calibration size, and miscoverage level.
- It derives explicit length deviation rates in conformalized quantile and median regression, revealing new phase transitions and practical design tradeoffs.
- Empirical validation and robustness tests confirm that even under nonlinearity and alternative optimizers, the predicted scaling laws consistently hold.
Introduction
The paper "Non-Asymptotic Analysis of Efficiency in Conformalized Regression" (2510.07093) establishes the first non-asymptotic characterizations of prediction set efficiency in split conformalized quantile and median regression, with explicit finite-sample rates capturing the role of training set size n, calibration set size m, and miscoverage level α. Prior results typically treat α as fixed and focus exclusively on the calibration set; this work delivers explicit length deviation rates of the form O(n−1/2+1/(nα2)+m−1/2+exp(−α2m)), revealing new phase transitions and design tradeoffs of practical and theoretical significance.
Conformal prediction constructs prediction sets C(x) for input x that guarantee marginal coverage P(Y∈C(X))≥1−α, given a split of the available data into a proper training set for model fitting (n samples) and a calibration set for thresholding (m samples). The efficiency, i.e., informativeness, of the resulting prediction set is its expected size (interval length in regression).
The focus is on two canonical score constructions:
- Conformalized Quantile Regression (CQR): The prediction set is the interval between estimated upper and lower quantiles, inflated by a quantile of the maximal residual over a calibration set.
- Conformalized Median Regression (CMR): The interval is centered at the estimated conditional median, with width prescribed by a calibration quantile of absolute residuals.
Both methods are analyzed under proper training via stochastic gradient descent on the (possibly regularized or robustified) pinball/absolute loss, with linear models as the main theoretical setting but extensions demonstrated empirically.
Main Theoretical Results
Rates and Explicit α-Dependence
Under mild conditions (bounded covariates, bounded and regular conditional response densities, linear quantile model well-specification), the paper proves for both CQR and CMR that the expected excess length of the prediction set over the oracle interval (the “oracle” being the ideal quantile interval at the calibration coverage) is upper bounded as:
E∣ ∣C(X)∣−∣C∗(X)∣ ∣≤O(n−1/2+α2n1+m−1/2+exp(−α2m))
This quantifies, for the first time, the joint impact of n, m, and α in the realistic split conformal setup. Notably:
- Non-asymptotic rates: The result holds for any finite n,m; previous bounds only characterized the n,m→∞ asymptotics, typically with α treated as a fixed constant.
- Explicit phase structure in α: The bounds transition between regimes depending on which terms dominate, sharply indicating when decreasing α will cause a steep efficiency loss (prediction sets growing rapidly), and clarifying the interaction between sample sizes and coverage level.
These theoretical results are succinctly visualized in the regime diagram, which shows the scaling of the bound as a function of α under various n and m relationships.
(Figure 1)
Figure 1: Upper bound orders in Theorem~\ref{thm:cqr-main} across regimes of α for n=Θ(m). Log-log scales reveal transitions from n−1/2 to 1/(nα2) scaling.
Empirical Regression and Phase Transitions
The length deviation's scaling laws are confirmed by a series of synthetic experiments. For small α and moderate-to-large n, the empirical convergence rate shifts from the parametric n−1/2 scaling to a sharper 1/(nα2), in line with the theoretical predictions.
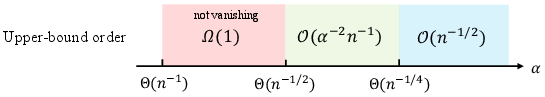
Figure 2: The length deviation of conformalized quantile regression in synthetic data experiments, showing the role of n, m, and α.
The log-log regression with respect to 1/(nα2) for small α provides an empirical slope close to the theoretical value of $1$, verifying the predicted regime of the bound.
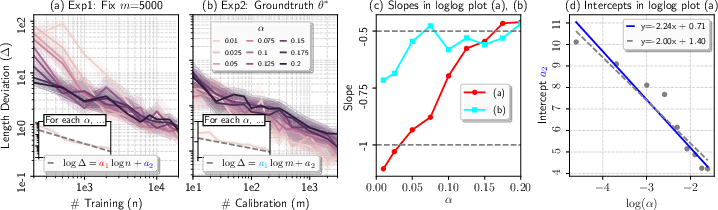
Figure 3: Log-log regression of Δ versus 1/(nα2) for small α, indicating a scaling exponent of approximately $1$.
Extensions, Robustness, and Practical Algorithms
The paper further demonstrates that the analytic framework extends to a variety of practical setups:
- Alternative Score Optimization Algorithms: The main theoretical device is an oracle inequality for the regression error under SGD, but the argument is modular: bounds for optimizers such as SGD with momentum and AdamW yield essentially identical empirical phase transitions when substituted, confirming that the statistical scaling is not sensitive to batch or adaptive first-order optimization details.
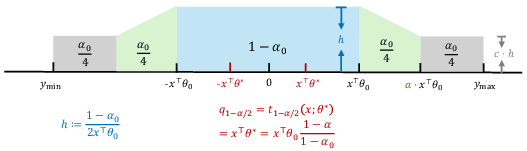
Figure 4: The length deviation for CQR trained with AdamW, confirming that the phase transition phenomenon is optimizer-agnostic.
- Misspecification and Nonlinearity: By convolving the true conditional law with a Gaussian kernel, the authors introduce controlled nonlinearity into the ground-truth quantile function. The empirical behavior of length deviation and phase transitions remains qualitatively unchanged, suggesting robustness of their theoretical predictions beyond the linear model class.
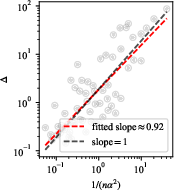
Figure 5: The length deviation under ground-truth nonlinear conditional quantile functions; the predicted scaling is preserved.
- Alternative Regularization and Losses: The results persist under ℓ1-regularized and Huber-penalized quantile regression, as expected from the modular proof structure provided the regularizer preserves the necessary control on empirical error.
- Real-World Benchmarks: The empirical results on standard regression datasets (e.g., MEPS, California Housing, cpusmall, abalone) confirm the scaling predictions and the benefit of careful data allocation between training/calibration for fixed resource budgets.
Data Allocation, Elbows, and Practical Policy
The explicit non-asymptotic analysis gives actionable guidance for practitioners:
- When the miscoverage level α is small ('tail risk' regimes), the term 1/(α2n) dominates, leading to sharp increases in prediction set size as coverage approaches certainty.
- The results dictate that for α not extremely small (specifically, α=ω(n−1/4)), splitting data into training and calibration sets of comparable size is optimal for efficiency.
- The paper empirically identifies "elbows" in interval length versus α curves, where efficiency deteriorates rapidly, providing concrete operational criteria for selecting α.
Theoretical and Methodological Implications
The theoretical constructs have implications for several paths of regression inference:
- The explicit rates reveal when the split conformal pipeline is optimal and when prediction set lengths can be made nearly oracle-efficient.
- The identification of α-regimes where efficiency degrades suggests that for extreme quantile coverage (small α), alternative approaches (e.g., combining model-based and nonparametric strategies) may be needed.
- The modular proof structure indicates that the derived results can be ported to settings with more complex estimators (e.g., deep neural networks) provided analogous regression error rates are available.
Moreover, the work clarifies limitations in practice: classical conformalized quantile regressors can only achieve oracle efficiency when the support of the conditional distribution is unimodal and contiguous; for multimodal, highly non-standard conditionals, optimal sets may not be intervals. This suggests that more flexible, possibly learned and adaptive nonconformity score functions and non-standard set constructions are a required research direction to further close the efficiency gap.
Conclusions
This paper rigorously quantifies efficiency tradeoffs in conformalized split regression, with non-asymptotic rates in n, m, and α that capture all known best practices and provide new algorithmic policy. Theoretical results and the accompanying empirical validations establish a modular, extensible foundation for the analysis and design of efficient uncertainty quantification in predictive models, and highlight emerging limitations and future challenges for research in statistical machine learning and applied AI.