- The paper introduces CHDQR, which couples regression-as-classification with adaptive, dynamic prototypes to improve prediction interval accuracy.
- It significantly reduces the exponential scaling of prototypes by locally refining density estimates in non-convex, high-density regions.
- Empirical results demonstrate CHDQR's capability to produce tight, robust coverage in both low- and high-dimensional, multimodal tasks with minimal computational overhead.
Motivation for Adaptive High-Density Quantile Regression
Quantile regression and conformalized quantile regression (CQR) are the standard methodologies for constructing prediction intervals and sets with rigorous coverage guarantees. However, convexity constraints and inflexibility in capturing highly non-convex, multimodal, or high-dimensional data distributions severely limit their effectiveness, especially in safety-critical and complex ML applications. Recent work reframing regression as classification, such as the Regression-as-Classification (RasC) approach, offers improved adaptability to non-convex structures but is inherently restricted by the curse of dimensionality and dependence on static quantization bins. Fixed-binning schemes are inadequate for dense or intricately structured data.
The paper introduces Conformalized High-Density Quantile Regression (CHDQR), a rigorous framework that extends RasC by coupling it with an adaptive, dynamically evolving set of prototypes. This dynamism allows for effective spatial partitioning and density modeling, particularly in non-convex high-density regions, and is integrated with a conformalization pipeline for valid finite-sample coverage. The proposed scheme directly addresses the principal limitations of quantile regression, RasC, and related density estimation approaches.
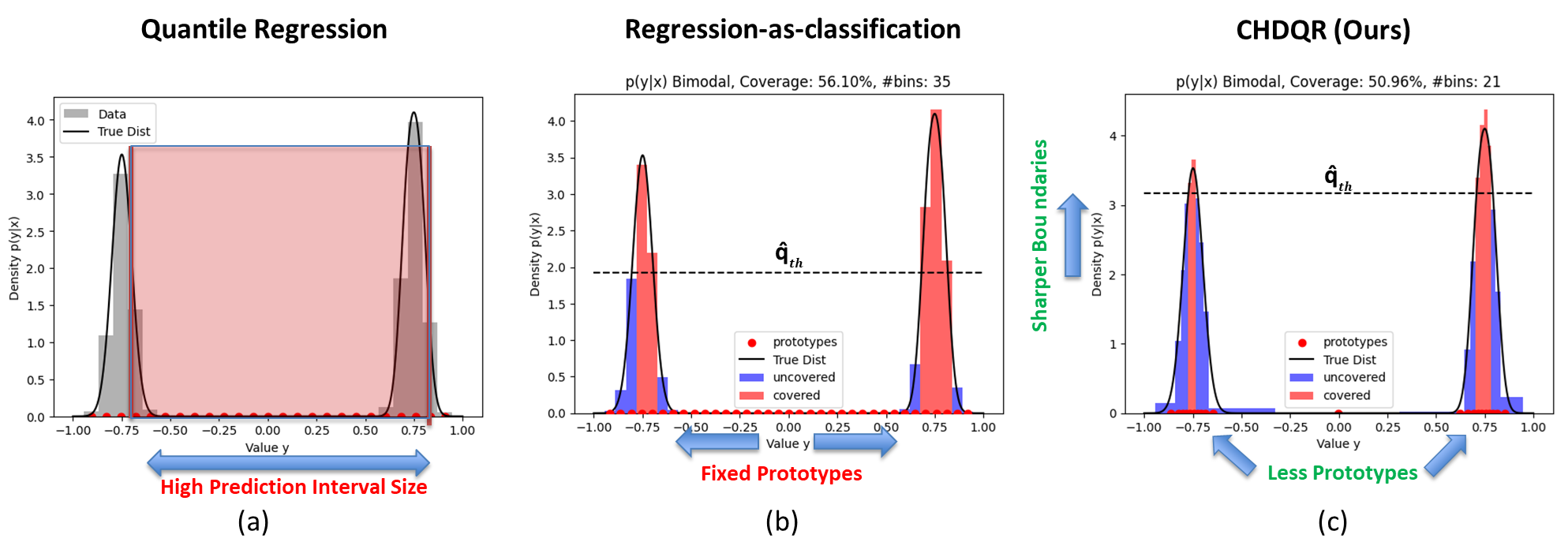
Figure 1: Comparison of (a) conventional quantile regression (broad intervals), (b) static bin RasC, and (c) CHDQR with adaptive prototype precision in high-density regions.
Methodological Foundation
The core construct of CHDQR leverages a regression-as-classification paradigm, where the output space is partitioned by a set of prototypes representing Voronoi regions. Model outputs, P^[y∈Ri∣x], are defined in terms of prototype region volume and local density, estimated via a log-density neural predictor. The probability for each region is proportional to its density and area, ensuring normalization via a softmax structure. Unlike prior approaches, CHDQR emphasizes continuous refinement of both the number and positions of prototypes, using a composite objective comprising cross-entropy, quantization error, and a prototype repulsion term to avoid degeneracy.
The prototype set adapts through the training process with two principal mechanisms: prototypes with low assignment frequency are pruned, whereas those in high-density regions are split via noise-perturbed duplication. This dynamic adjustment produces sharp, spatially efficient covering sets, reducing quantization error and memory requirements for high-dimensional targets.
CHDQR's conformalization phase employs the nonconformity score S(ycal,xcal), which accumulates the predicted probabilities for high-density regions covering each calibration instance. Coverage calibration is then performed via the empirical quantile of these scores. At prediction time, the test point's associated density estimates and cumulative region probabilities determine the smallest, densest union of regions satisfying the (1−α) coverage threshold. This construction aligns with high-density region estimation theory and ensures finite-sample marginal validity under standard exchangeability assumptions.
Empirical Results in Low and High Dimensions
Extensive evaluation across synthetic and real-world datasets demonstrates several key findings:
- CHDQR and CHDQR-Dynamic consistently achieve the stipulated coverage rates (e.g., 0.90, 0.50, 0.10) with significantly reduced normalized prediction region width (PINAW), especially in complex, multimodal, or non-convex settings.
- In one-dimensional and toy multimodal tasks, CHDQR-Dynamic produces much tighter prediction regions by adaptively refining the set of active prototypes and focusing quantization in dense regions.
- On higher-dimensional tasks (e.g., 2D Gaussian mixtures), fixed-bin RasC and CQR become computationally infeasible (O(nd) bins required), whereas CHDQR-Dynamic matches or exceeds their coverage and region efficiency with orders of magnitude fewer prototypes.
- The method displays strong robustness to outliers—adding synthetic outliers causes only minor increases in prediction set size, owing to CHDQR’s capacity for local adaptation.
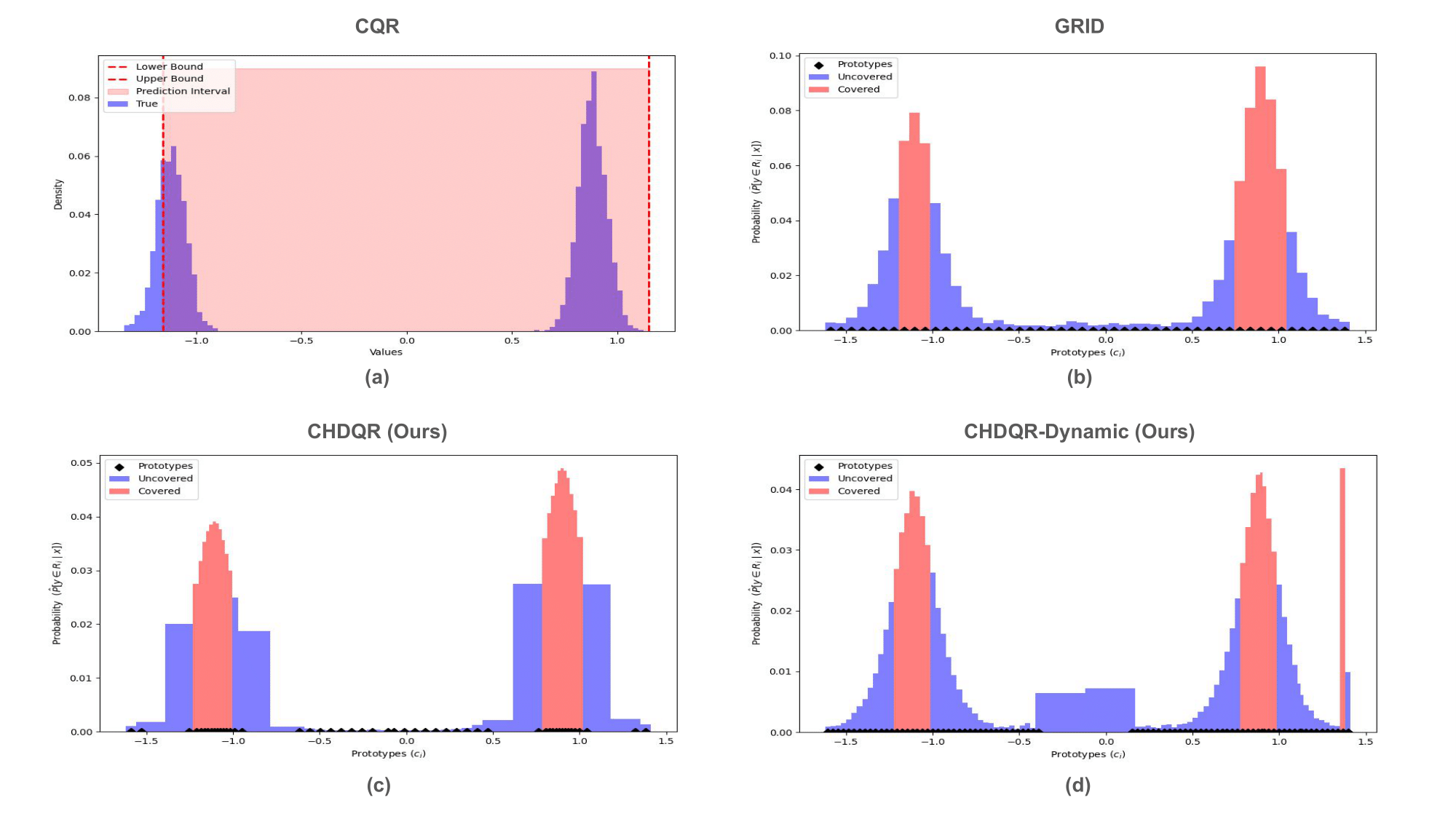
Figure 2: Visualization of CHDQR-Dynamic quantile coverage on the Uncond1d dataset, highlighting compact region prediction for dense modes.
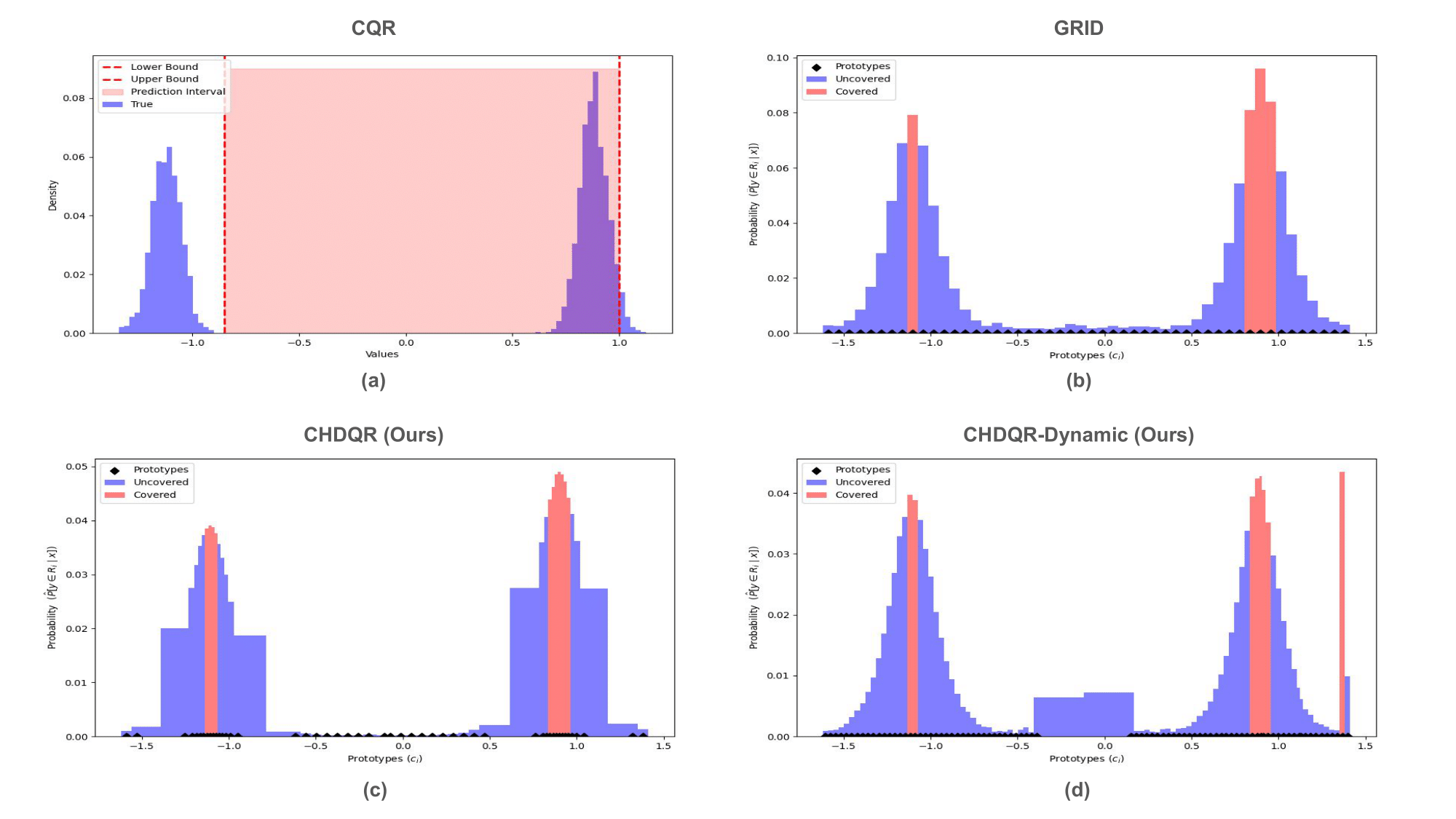
Figure 3: 50\% coverage visualization on Unconditional1d, showing precise selection of highest-density regions.
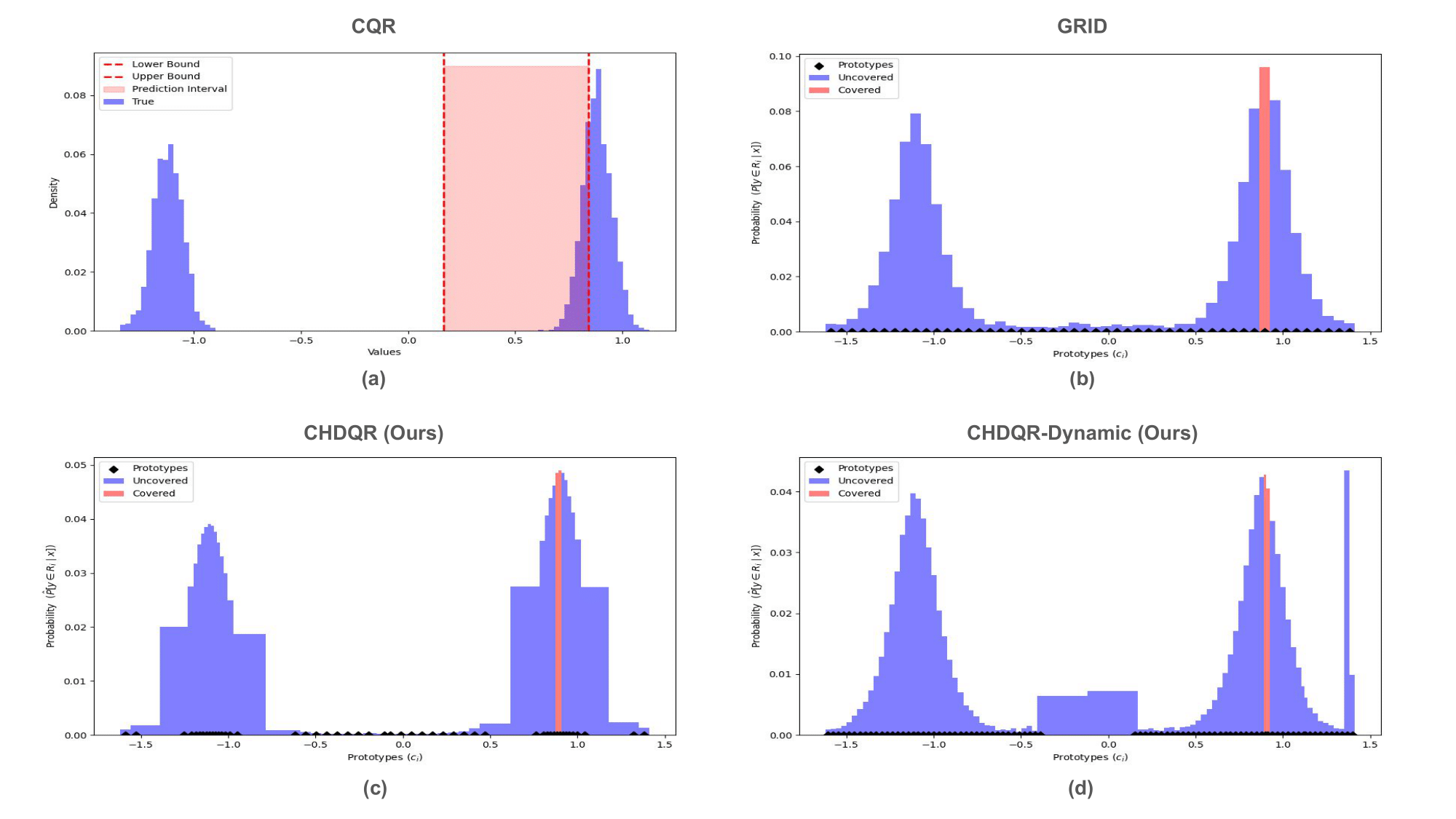
Figure 4: 10\% coverage visualization, with extremely narrow region assignment focusing strictly on modes.
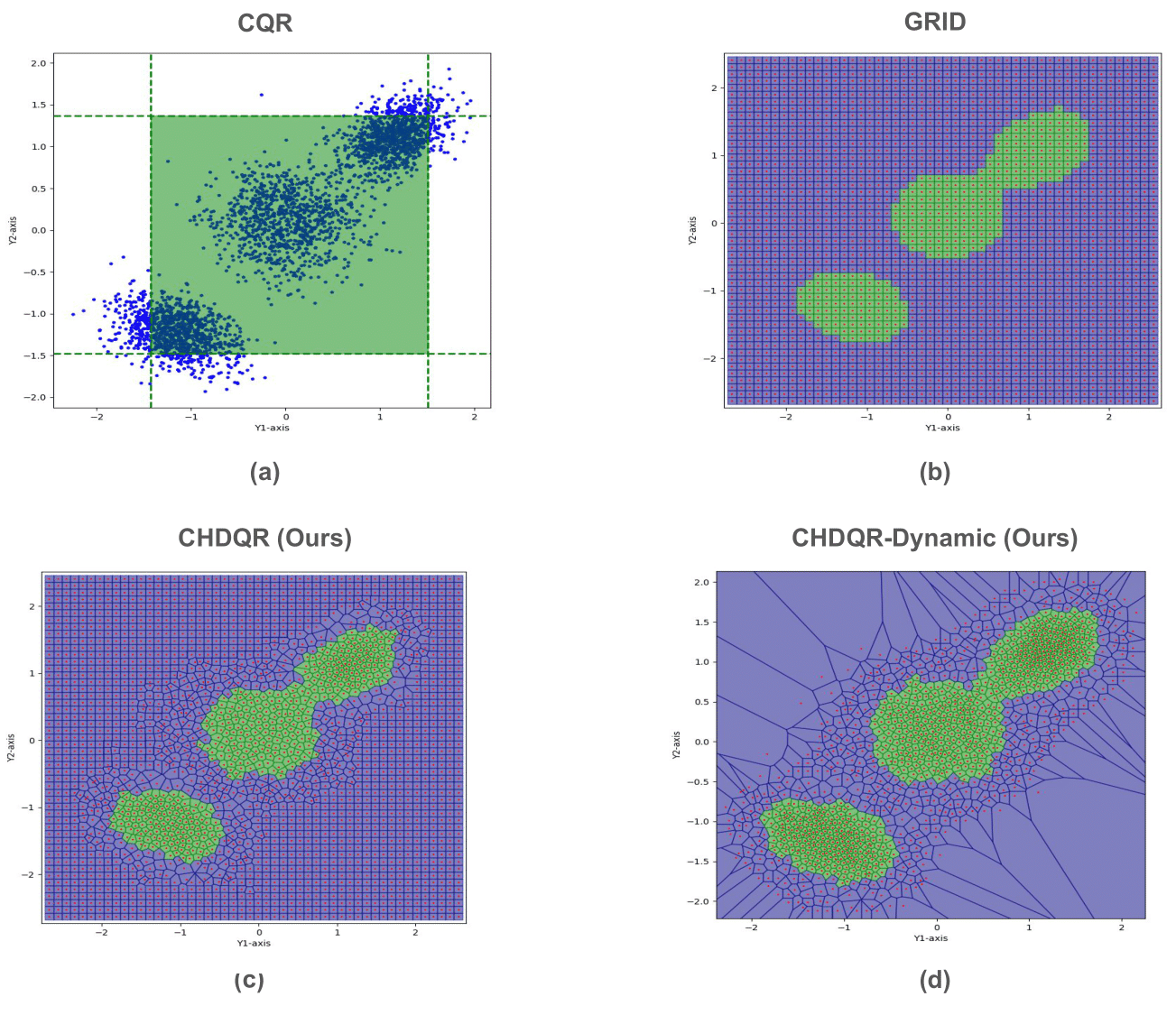
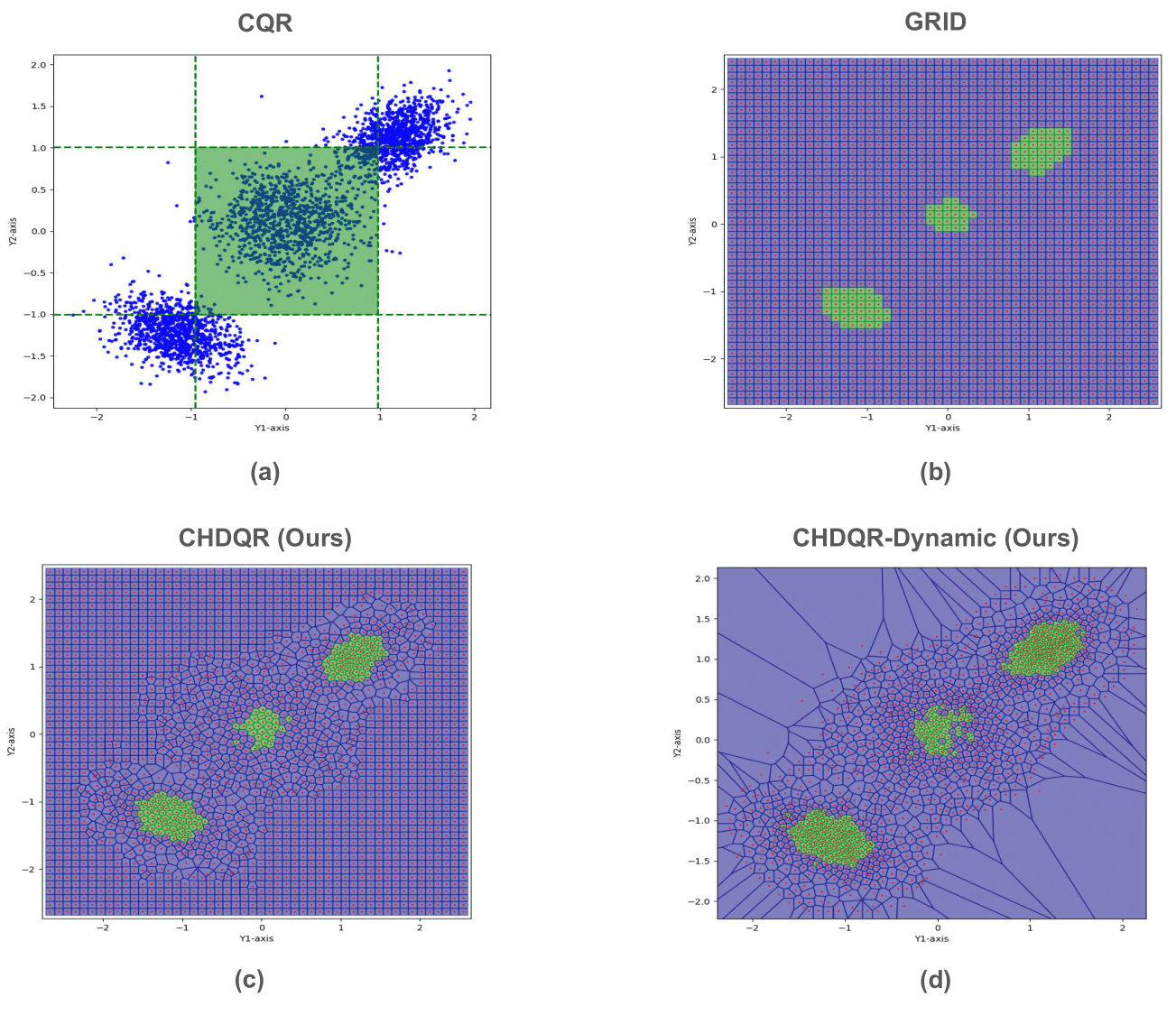
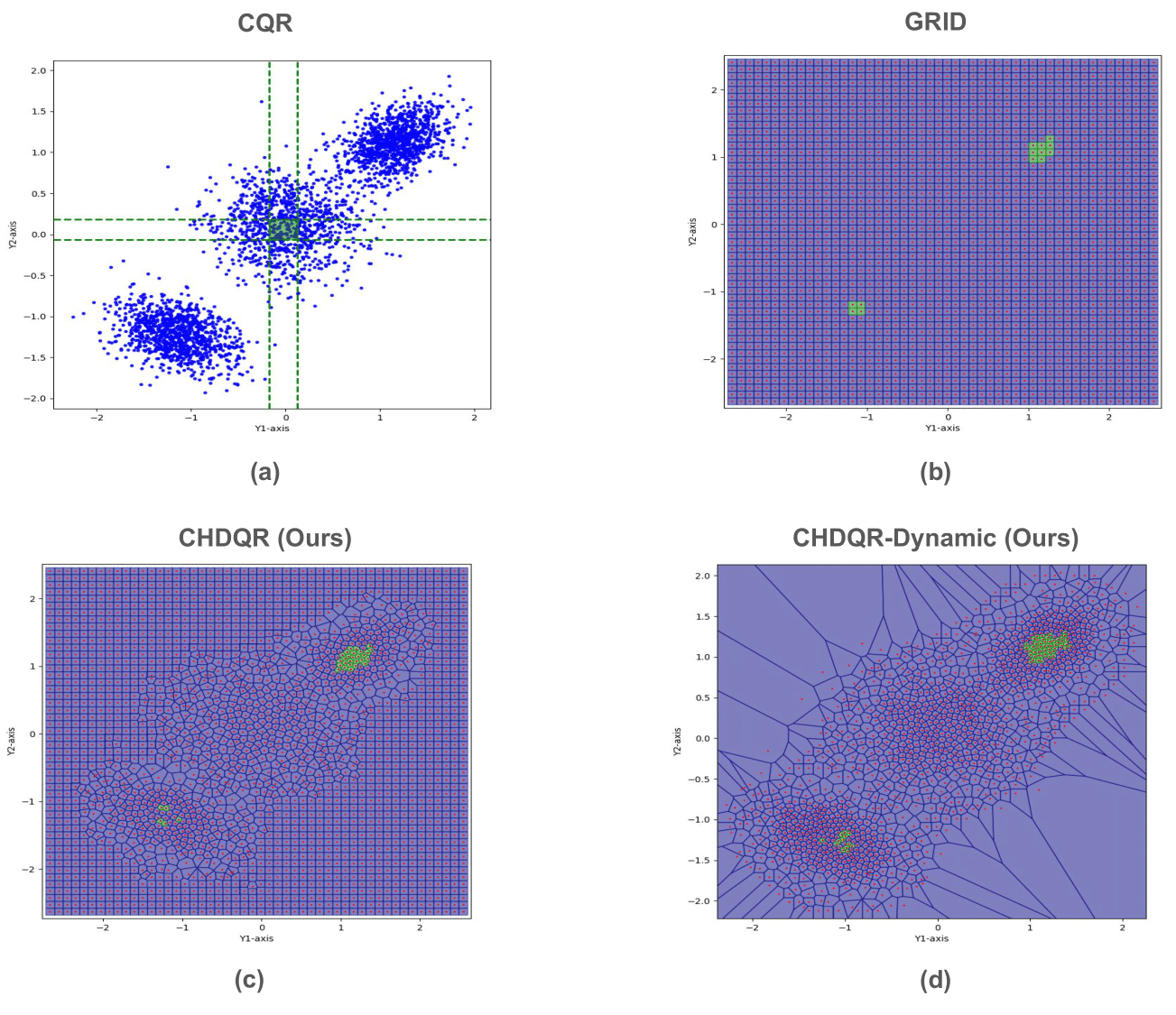
Figure 5: Visualization of 90\% coverage level quantile regions; CHDQR-Dynamic creates minimal-width intervals covering modes with less redundancy than static approaches.
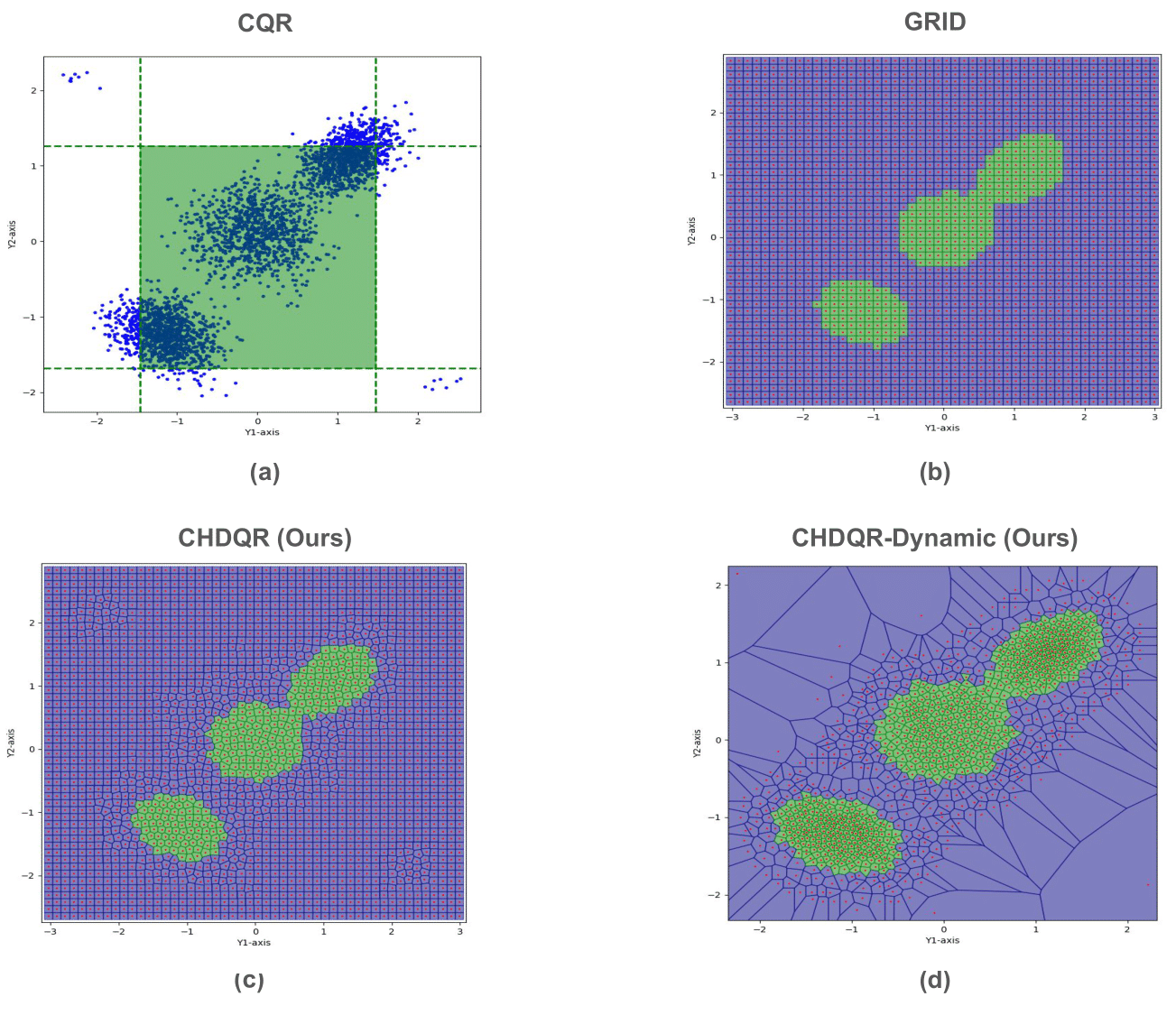
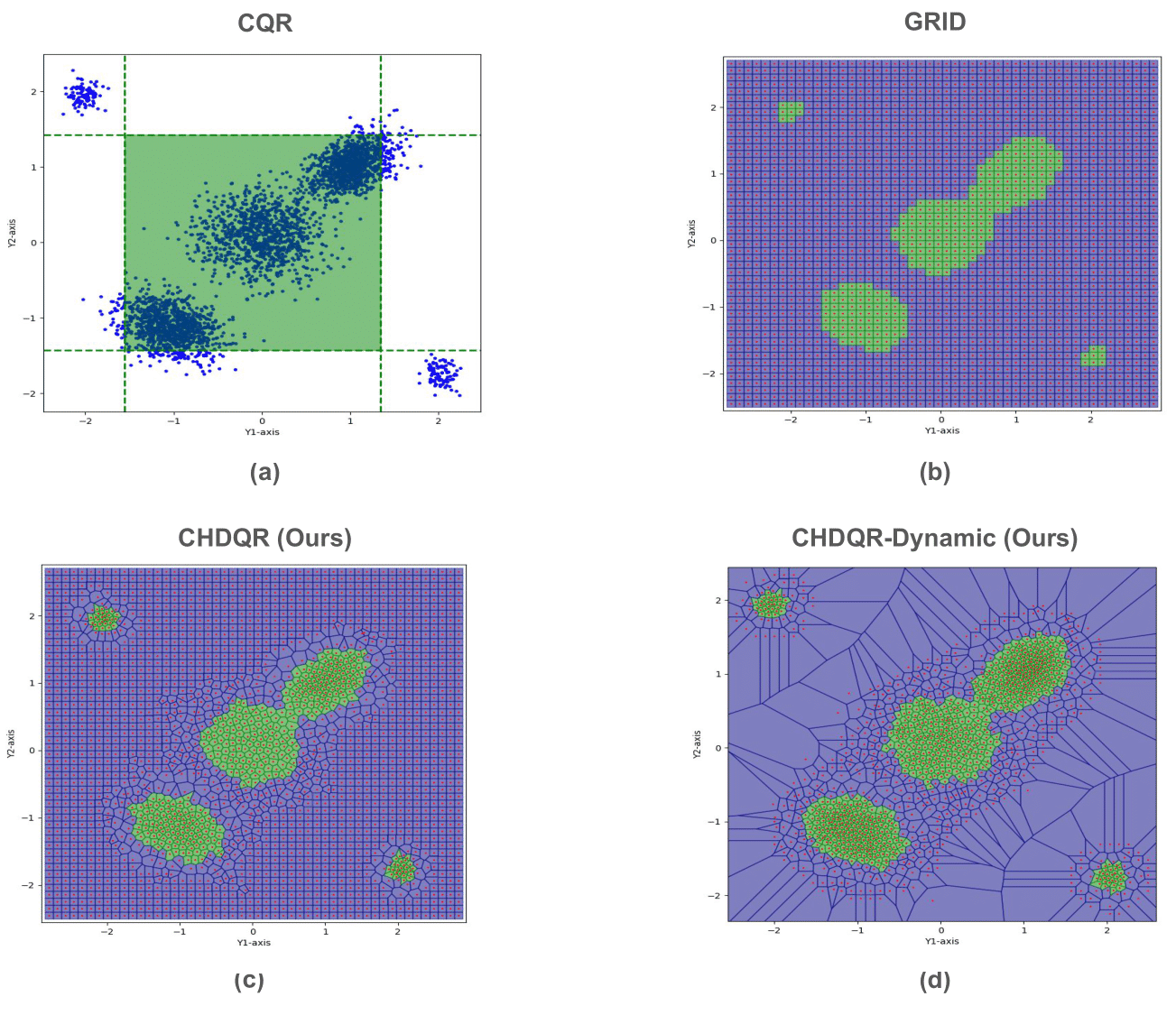
Figure 6: CHDQR-Dynamic applied on Uncond2d with 0.6\% outliers and 90\% coverage, illustrating robust adaptation and efficient region partitioning, including outlier incorporation.
Theoretical and Practical Implications
CHDQR represents a substantial development in the rigorous estimation of prediction sets:
- It breaks the exponential scaling in prototype count customary to fixed-bin methods, making high-dimensional conformal quantile regression computationally feasible.
- By dynamically allocating quantization complexity to dense data regions, it achieves coverage with smaller and sparser prototypes, optimizing both accuracy and memory footprint.
- The framework generalizes to multi-target, high-dimensional regression, circumventing the restrictiveness of convexity and grid-based binning.
From a practical standpoint, CHDQR’s ability to construct sharply delimited, data-adaptive prediction regions—coupled with provable coverage guarantees—has significant implications for decision-support systems in safety-critical domains, anomaly detection, and resource allocation under uncertainty. Its design allows flexibility for integration with modern deep learning architectures as the log-density estimator, opening further applicability to structured and unstructured data.
Limitations and Directions for Future Work
While CHDQR addresses key scalability and coverage challenges, several open problems remain:
- Voronoi tessellation and exact volume calculations currently restrict practical usage to ≤3 dimensions; relaxing the reliance on explicit area computation (e.g., via soft estimation) would permit direct extension to arbitrarily high dimensions.
- The calibration-prediction gap and local conditional coverage (beyond marginal) are not explicitly addressed.
- Sensitivity to hyperparameter choices for prototype adaptation schedules and loss weights could be mitigated with more automated or data-driven strategies.
- A generalization to structured outputs (e.g., sequences, images) will require tailored prototype geometry/metric selection.
Conclusion
CHDQR advances conformal quantile regression by fusing dynamic prototype allocation with density-based region estimation, enabling accurate, scalable, and robust construction of high-density prediction sets in diverse regression settings. Its empirical performance across coverage regimes, dimensions, and under outlier perturbation, coupled with substantial computational advantages, underscores its utility as a foundation for rigorous uncertainty quantification on complex data. Future extensions in high-dimensional region estimation and conditional guarantees are poised to enhance its theoretical and applicative scope.