- The paper introduces a novel optimal transport-based informative attention method to capture key semantic content from lengthy documents.
- It employs accumulative joint entropy reduction on named entities to enhance summary informativeness and factual consistency.
- Experiments on CNNDM and XSum datasets demonstrate significant improvements in ROUGE scores and human evaluation over traditional models.
Improving Informativeness of Abstractive Text Summarization with Informative Attention
The paper "InforME: Improving Informativeness of Abstractive Text Summarization With Informative Attention Guided by Named Entity Salience" introduces an innovative approach to enhance the informativeness of Abstractive Text Summarization (ATS) by optimizing the attention mechanisms in encoder-decoder models and focusing on named entity salience.
Introduction
In the field of natural language processing, ATS is tasked with generating coherent and relevant summaries from long documents. The prevalent models often leverage Transformer-based architectures, relying heavily on cross-attention to ensure relevance between input and output sequences. Despite advancements, these systems frequently generate summaries that lack essential informational content, primarily due to their inability to effectively capture and utilize knowledge not explicitly evident in the input data. This paper proposes an optimal transport-based informative attention method, complemented by an accumulative joint entropy reduction strategy, aimed at addressing these limitations (Figure 1).
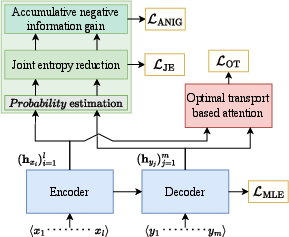
Figure 1: Illustration of an encoder-decoder with our methods, including optimal transport-based informative attention (carmine block) and accumulative joint entropy reduction (tealish block).
Methodology
The novel approach introduced employs optimal transport theory to align the semantic information between the source document and the generated summaries, treating the task as a minimization problem of transport costs between distributions. This leverages the Wasserstein distance to identify and retain most informative content from the source, aiding in generating more comprehensive summaries. The formulation involves a coupling mechanism based on bilinear transformations to align latent semantic distributions between source and summary tokens.
Accumulative Joint Entropy Reduction
This aspect of the methodology enhances the salience of named entities, crucial for summary informativeness, by employing an accumulative reduction in joint entropy. Named entities are central nodes of information in documents, and their prominent representation in latent space aids in informative content extraction. The approach involves minimizing the conditional and joint entropy across named entities to reduce uncertainty and thus increase the accuracy and relevance of generated summaries.
Experimental Evaluation
Datasets
The paper employs the CNN/Daily Mail (CNNDM) and XSum datasets, representing two distinct styles of text summarization—extractive versus abstractive. These datasets serve as a benchmark to evaluate the improvements made by the proposed methods over standard and baseline models.
Results
The proposed model outperforms several state-of-the-art approaches on the CNNDM dataset, with substantial improvements in ROUGE scores, indicating better overlap with reference summaries. For the XSum dataset, the model maintains competitive performance, showcasing its adaptability across different summarization styles. The ablation studies further reveal the individual contributions of the optimal transport and entropy reduction components.
Human and Automatic Evaluation
Automatic evaluations using ROUGE and QuestEval demonstrate improved performance, while human assessments confirm enhanced informativeness and factual consistency in the summaries. Notably, the method appears to facilitate extrinsic information mining, suggesting a newfound capability for knowledge synthesis beyond direct source content.
Discussion
The integration of optimal transport for attention refinement and entropy reduction for named entity salience introduces a significant shift in ATS paradigms, enabling models to generate more informative and factually consistent summaries. These enhancements pave the way for models that can synthesize both intrinsic and extrinsic information effectively, mimicking a more human-like approach to summary generation.
Conclusion
The research contributes to ATS by enhancing informativeness through a novel combination of optimal transport-based attention and entropy reduction on named entities. The results indicate an improved ability to capture and synthesize relevant content, providing a robust foundation for future developments in text summarization that prioritize knowledge-rich outputs. This work holds potential implications for expanding ATS capabilities to more complex and diverse datasets, with a focus on practical applicability in varied domains.